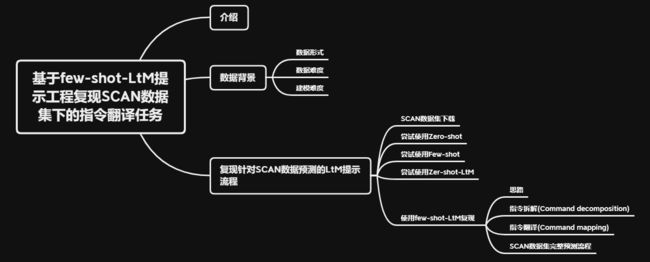
大模型开发(九):基于Few-Shot-LtM提示工程复现SCAN数据集下的指令翻译任务
全文共9000余字,预计阅读时间约30~50分钟 | 满满干货(附复现代码),建议收藏!
本文目标:复现论文:《LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS》, 并提出改进策略,采用LtM提示方法在text-davinci-003模型上完成对SCAN数据集准确率高达99.7%的预测,实现一个基于大模型的完整建模流程。
代码下载链接
一、介绍
对大语言模型(LLMs)来说,组合泛化能力是最重要的涌现能力之一,也是模型能够理解复杂语义、进行准确推理的底层能力。所以验证提示工程效果最有效的方式就是观察该方法是否能高效提升模型组合泛化能力。
在这篇文章中,大模型开发(八):基于思维链(CoT)的进阶提示工程,通过一系列的实践和结合相关论文的结论,基本印证了:EAST-TO-MOST PROMPTING(LtM提示法)是截至目前围绕模型推理能力提升的最为有效的提示学习方法。
所以本文就复现论文:《LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS》, 并提出改进策略,采用LtM提示方法在text-davinci-003模型上完成对SCAN数据集准确率高达99.7%的预测,实现一个基于大模型的完整建模流程。
二、数据背景
SCAN数据集,由纽约大学和Facebook于2018年提出,该数据集包含2万条基于隐藏语义关系的指令及对应的翻译动作序列,是目前公认的用于测试深度学习算法组合泛化能力的基准数据集,该数据集建模难度极大,目前最前沿的深度学习算法都无法进行非常精准的预测,在大模型诞生之前,人们甚至需要单独围绕这个数据集提出全新的深度学习架构,才能完成较高进度的预测。
2.1 数据形式
该数据集是一系列的指令和对应的行为序列组成的纯文本数据集,指令在数据集中以IN的形式进行申明,是一串描述动作序列的英文句子,例如"walk twice and jump twice";行为序列是以OUT的形式进行申明,是指令所指代的一系列精准步骤,例如““WALK”, “WALK”, “JUMP”, “JUMP””,总共包含2万条样本(2万个IN-OUT对),对比传统的结构化数据集,IN相当于是特征,OUT相当于是标签。数据集基本结构如下:

2.2 数据难度
这个数据集存在一定的“黑箱”性质,比如“walk twice and jump twice”可以很明显的看出来指代[”WALK", “WALK”, “JUMP”, “JUMP”],但有些命令和行为之间的关系却不是很好理解,例如上图中的最后一个命令:“walk opposite left twice and run”,为何指代[”TURN_LEFT",“TURN_LEFT”,“WALK”,“TURN_LEFT”,“TURN_LEFT”,“WALK”,“RUN”]并不能通过自然语言的语法规则进行理解。
根据官方的解释是:这套数据集是根据一套隐藏的语法规则创建的指令和行为数据集,指令和动作在现实中并没有特殊的含义,但它们模拟了一种常见的问题:理解和执行一系列指令。这种问题在很多实际应用中都会遇到,例如:编程(理解并执行一系列代码指令)、机器人导航(理解并执行一系列的导航指令),甚至是日常生活中的任务(如烹饪、装配家具等,需要理解并执行一系列步骤)。
据此不难理解,SCAN这个人工数据集创建的目的,就是为了测试模型能否找到这个隐藏的语法规则,并根据IN准确的预测OUT,预测准确率越高,说明模型对这个隐藏语法规则学习的越准确,模型性能越强。
从专业的角度来说,SCAN数据集就是一个用于评估模型在理解和执行指令上的组合泛化能力的基准数据集。
2.3 建模难度
SCAN数据集是目前建模难度非常大的数据集,主要原因由以下两点:
一、SCAN数据集数据集的主要特点是其指令和相应的行动序列的生成,是完全基于某种预定义的、结构化的语法规则。这意味着模型不能仅依赖于表面层次的统计规律或者局部的模式匹配来进行预测,必须理解和掌握数据的底层结构和规则。
二、从模型本身的角度来说,深度学习模型、特别是序列到序列的模型,通常依赖于大量的数据和计算资源来学习和泛化复杂的模式,而SCAN数据集则需要模型具备强大的组合泛化能力,即只通过少量数据集的训练,就需要理解没有直接见过的组合指令并执行正确的行动序列。例如,虽然模型可能在训练中见过"jump"和"twice"这两个单词,但是如果没有直接见过"jump twice"这个组合,那么模型可能就无法正确地理解和执行这个指令。
因此截至目前,传统的深度学习方法、哪怕是最先进的深度学习模型也难以在该数据集上达到高水平的性能。
但这样的一个业内难题,却能够被大语言模型“轻易”的解决。根据《LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS》论文中的描述,根据**基于合理的LtM提示学习,"code-davinci-002"模型只需要输入14条训练样本,就能够对SCAN数据集做到几乎100%的准确预测(准确率为99.7%)****
三、复现针对SCAN数据预测的LtM提示流程
3.1 SCAN数据集下载
SCAN数据集目前托管在Hugging Face上,所以使用Hugging Face的datasets库进行在线下载和导入,代码如下:
# !pip install datasets
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("scan", "simple")
# 打印数据集信息
print(dataset)
dataset已经被划分为训练集和测试集两个数据集,其中训练集总共包含16728条数据,而测试集总共包含4182条数据
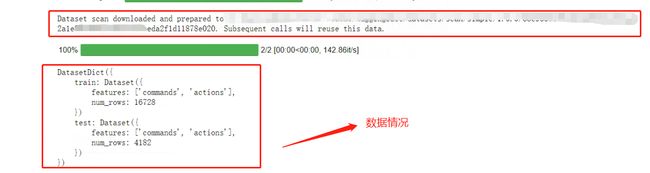
看一下数据形式:
scan_train = dataset["train"]
scan_train.to_pandas()
输出如下:

3.2 尝试使用Zero-shot
挑选几条相对简单的数据:

代码如下:
# 挑选三条比较简单的数据
Command1 = 'look thrice after jump'
Action1 = 'JUMP LOOK LOOK LOOK'
Command2 = 'run left and walk'
Action2 = 'TURN LEFT RUN WALK'
Command3 = 'look opposite right'
Action3 = 'TURN RIGHT TURN RIGHT LOOK'
# 使用text-davinci-003模型预测
response_Zero_shot = openai.Completion.create(
model="text-davinci-003",
prompt=Command1,
max_tokens=1000,
)
response_Zero_shot["choices"][0]["text"].strip()
结果如下:
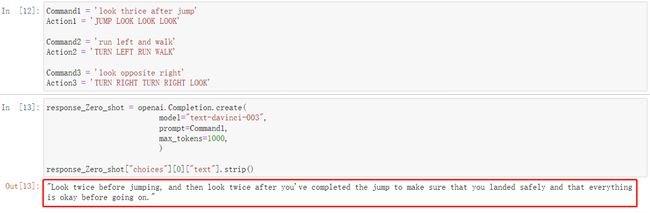
从结果上,模型完全无法给出答案,进一步给它点提示试试:
Command1 = 'look thrice after jump'
Action1 = 'JUMP LOOK LOOK LOOK'
response_Zero_shot = openai.Completion.create(
model="text-davinci-003",
prompt= "%s should be translated as" % Command1,
max_tokens=1000,
)
response_Zero_shot["choices"][0]["text"].strip()
看下结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lp4eFCsk-1689927541835)(https://snowball100.oss-cn-beijing.aliyuncs.com/images/202307211615039.png)]
模型将其翻译为了西班牙语,还是一样没什么效果。
3.3 尝试使用Few-shot
以第一、二条数据作为few-shot,围绕第三条数据进行预测,代码如下:
few_shot_prompt = 'Q: "%s", A: "%s", Q: "%s", A: "%s", Q: "%s", A: ' % (Command1, Action1, Command2, Action2, Command3)
response_Few_shot = openai.Completion.create(
model="text-davinci-003",
prompt=few_shot_prompt,
max_tokens=1000,
)
response_Few_shot["choices"][0]["text"].strip()
看下结果:

简单的以问题+答案组成的few-shot,比Zero-shot靠谱点。根据原论文的描述,few-shot提示方法在SCAN数据集上的准确率不到17%,依旧很低。
3.4 尝试使用Zer-shot-LtM
论文中给出的最佳方法就是进行一种基于Few-shot的LtM提示工程,在大模型开发(八):基于思维链(CoT)的进阶提示工程中提到的LtM是一种Zer-shot-LtM方法。
其基本流程是这样的:
所以根据"to solve…,we need to first solve"提示模板来进行问题拆解,代码如下:
Zero_shot_LtM_prompt = "In order to translate '%s', we need to first solve" % Command1
response_Zero_shot_LtM = openai.Completion.create(
model="text-davinci-003",
prompt=Zero_shot_LtM_prompt,
max_tokens=1000,
)
response_Zero_shot_LtM["choices"][0]["text"].strip()
看下结果:
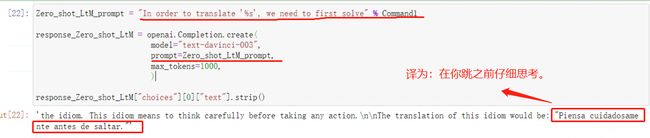
在Zero-shot-LtM提示指令下,模型仍然无法精准理解问题,其实这个效果也可以理解,对于SCAN数据集中的指令翻译问题,本身指令翻译的规则就不是自然语言规则,模型也从未学习过相关规则,在Zero-shot下,模型拆解的问题也几乎不会有助于最终的指令翻译任务,拆解的子问题是毫无意义的。
3.5 使用few-shot-LtM复现
3.5.1 思路
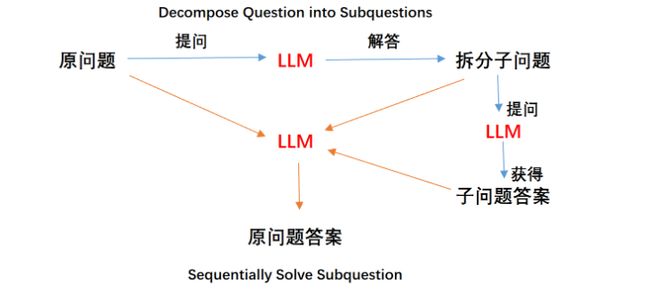
论文中提出了一种Few-shot-LtM提示工程流程来解决该问题,这种Few-shot-LtM提示流程在原有流程上进行了以下两方面改进:
1、首先通过**引入Few-shot来引导模型进行有价值的中间问题拆解并进行回答。**但是,通过自然语言描述的拆分问题的方法很多,同时也没有标准答案。因此,这方面的Few-shot的设计就需要建模人员大量的工作经验+大量的尝试,来寻找到最佳的Few-shot拆分示例。
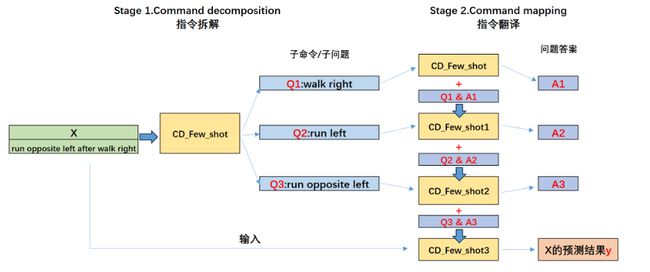
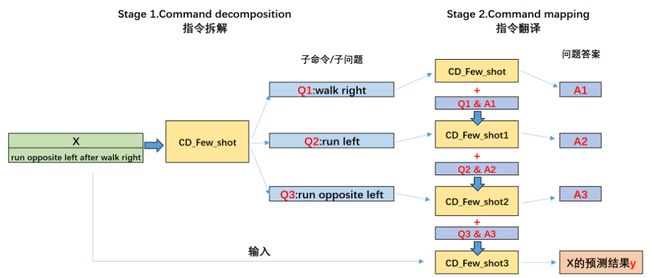
2、进行第1个过程的同时,在Few-shot的示例中,尝试引导模型进行多步分解进而提升模型进行翻译的准确率。即Decompose Question into Subquestions环节,多步拆分多个子问题回答,即可以尝试围绕某个拆解之后的子问题进一步拆分子问题,进而提升子问题的回答准确率,例如假设将一个问题拆分成三个子问题,则LtM提示回答的基本过程如下:
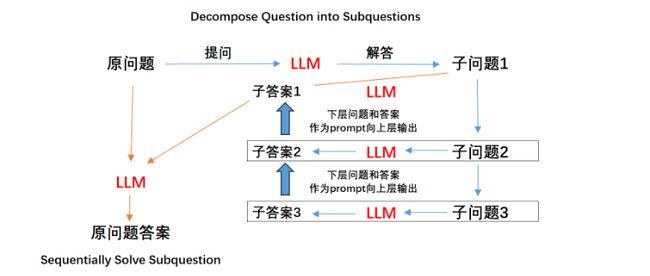
Few-shot实际上是两个部分,既需要利用Few-shot告诉模型应该如何拆解问题,同时也需要通过Few-shot来告诉模型应该如何进行问题的回答。
在论文中,将Few-shot-LtM提示的两个阶段进行重新命名,第一阶段Decompose Questions into Subquestions被重新命名为Command decomposition,即命令分解,也就是问题拆解,第二个阶段Sequentially Solve Subquestion则重新命名为Command mapping,即指令翻译。本质也就是依次翻译拆解的指令以及原始指令。
了解上述思想后,来尝试复现论文是如何在SCAN数据集上进行Few-shot-LtM提示工程的。
3.5.2 指令拆解(Command decomposition)
第一步,采用Few-shot的方法围绕命令进行拆解。Few-shot中的提示示例是人工手动编写,每个示例都是借助"__ can be solved by:__"提示模板进行提问,进而引导模型对Commands进行问题拆解。
说白了就是为了解读长的指令,要首先解读那些与之相关的短指令。论文挑选了几个指令并进行拆解,拆解过程如下:
CD_Few_shot = 'Q: “look opposite right thrice after walk” \
A: “look opposite right thrice” can be solved by: “look opposite right”, “look opposite right \
thrice”. “walk” can be solved by “walk”. So, “look opposite right thrice after walk” can be \
solved by: “walk”, “look opposite right”, “look opposite right thrice”. \
Q: “look around right thrice and walk” \
A: “look around right thrice” can be solved by: “look right”, “look around right”, “look around \
right thrice”. “walk” can be solved by “walk”. So, “look around right thrice and walk” can be \
solved by: “look right”, “look around right”, “look around right thrice”, “walk”. \
'
通过这组提示示例告诉模型应该如何进行指令拆解、即告诉模型指令拆解的基本规范,例如“look opposite right thrice after walk”可以被拆解为“walk”, “look opposite right”, “look opposite right thrice”这三个短的指令,而“look around right thrice and walk”,则可以被拆解为“look right”, “look around right”, “look around right thrice”, “walk”。
一般情况Few-shot规则是Q表示问题,A表示答案,例如Command:“look opposite right thrice after walk”对应的Action为“I_WALK I_TURN_RIGHT I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_TURN_RIGHT I_LOOK”,代码如下:
df = scan_train.to_pandas()
# 精确查找 "commands" 列中为 "look opposite right thrice after walk" 的行
matching_rows = df[df["commands"] == "look opposite right thrice after walk"]
# 取出与这个命令对应的 "actions" 值
actions = matching_rows["actions"].values
print(actions)
# # 如果有多个匹配,这将返回一个包含所有匹配行的 "actions" 值的数组。
# # 如果你只想要第一个匹配,你可以使用以下代码:
# first_action = actions[0] if len(actions) > 0 else None
# print(first_action)

所以此时提示示例应该为:
'Q: “look opposite right thrice after walk” \
A: “I_WALK I_TURN_RIGHT I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_TURN_RIGHT I_LOOK”. \
Q: “look around right thrice and walk” \
A: “I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_LOOK \
I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_LOOK I_TURN_RIGHT \
I_LOOK I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_LOOK I_TURN_RIGHT I_LOOK I_TURN_RIGHT \
I_LOOK I_TURN_RIGHT I_LOOK I_WALK”. \
'
但LtM提示流程的不同之处就在于设置了多个阶段进行分段提示,其中:
第一个阶段的提示结果只是为了创建中间结果——即分解子问题(命令拆解),因此Few-shot-LtM第一个阶段的提示示例也就是展示如何进行指令拆解。这个中间结果并没有标准答案,因此如何拆解基本就是人工尝试+经验的总结。对于大语言模型来说,不同的提示模板、语言风格、甚至是不同提示示例,都会对模型造成不同的引导,这种引导是极为灵活且具有创造力的。为了获得一个更好的最终结果,中间环节的Few-shot或许要经历千百次的尝试。
很多时候Few-shot就可以看成是训练集,大语言模型的建模过程和机器学习类似,都是在训练集上进行训练,然后在新的数据集上验证效果。
围绕数据集进行拆解,以第二条数据集为例,commands是做模型输入X,对应的actions是为模型输出y,代码如下:
X = scan_train[1]['commands']
y = scan_train[1]['actions']
prompt_CD = CD_Few_shot + 'Q:“%s” A:' % X
prompt_CD
带入模型:
response_CD = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CD,
temperature=0.5,
max_tokens=1000
)
response_CD["choices"][0]["text"].strip()
看下结果:

很明显能看出来,原始指令’run opposite left after walk right’被拆分成了“walk right”, “run left”, “run opposite left”三个短指令。
Few-shot的提示过程也可以看成是让模型举一反三的过程,尽管训练数据中没有’run opposite left after walk right’这个指令拆解的方法,但通过Few-shot,模型学会了其底层拆解命令的逻辑,因此也顺利完成了对这个新指令的拆解。
模型将X拆分成三个子命令,就相当于是将一个原始问题拆分成了三个问题,并且需要注意的是,这三个问题是有先后顺序的,相当于是“walk right”是最底层的子问题、“run left”是上一层的子问题,“run opposite left”则是第一层子问题。后续在解决这些子问题的时候,是按照由下往上的顺序依次进行解决,并且每一个子问题的解决都需要将下一层子问题的问题+答案作为Few-shot(最底层的子问题除外)
3.5.3 指令翻译(Command mapping)
在围绕原问题(原命令)拆分除了多个子问题(短命令)之后,接下来就需要依次解答(翻译)这一系列的子问题。
这个阶段总共有两部分工作,其一是通过Few-shot教会模型短命令的翻译方法,其二则是在翻译原始指令时,需要先翻译短指令,然后将短指令的问题和答案都作为prompt的一部分,带入到原指令的翻译过程中。其中,第二部分工作也就是LtM提示方法的根本流程——将子问题的问题+答案作为原问题提示内容的一部分,从而让模型更好的解决原问题。
看下原论文中给出的部分短指令翻译,代码如下:
CM_Few_shot = 'Q: “jump left” \
A: The output of “jump left” concatenates: the output of “turn left”, the output of “jump”. “turn \
left” outputs “TURN LEFT”. “jump” outputs “JUMP”. So concatenating the output of “turn \
left” and the output of “jump” leads to “TURN LEFT” + “JUMP”. So the output of “jump left” \
is “TURN LEFT” + “JUMP”. \
Q: “run and look twice” \
A: The output of “run and look twice” concatenates: the output of “run”, the output of “look \
twice”. “run” outputs “RUN”. “look twice” outputs “LOOK” * 2. So concatenating the output of \ \
“run” and the output of “look twice” leads to “RUN” + “LOOK” * 2. So the output of “run and \
look twice” is “RUN” + “LOOK” * 2. \
Q: “walk opposite left” \
A: The output of “walk opposite left” concatenates: the output of “turn opposite left”, the output of \
“walk”. “turn opposite left” outputs “TURN LEFT” * 2. “walk” outputs “WALK”. So concatenating the \
output of “turn opposite left” and the output of “walk” leads to “TURN LEFT” * 2 + “WALK”. So the \
output of “walk opposite left” is “TURN LEFT” * 2 + “WALK” '
这些提示就是通过两阶段的逻辑引导,将一些相对较短的指令翻译成了最终行为序列。
借助这些翻译的示例,对测试数据X完成Command mapping过程,具体过程如下:
- 翻译第一个子命令walk right
prompt_CM_1 = CM_Few_shot + 'Q:“walk right” A:'
response_CM_1 = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CM_1,
temperature=0.5,
max_tokens=1000
)
response_CM_1["choices"][0]["text"].strip()
看下结果:
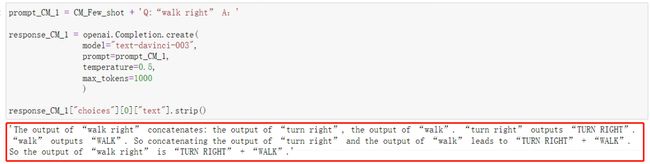
该结果就是第一个子命令的翻译得到结果。
- 翻译第二个子命令run left
在翻译第二个子命令时,将第一个子命令时的问答结果作为Few-shot的一个示例
prompt_CM_2 = prompt_CM_1 + response_CM_1["choices"][0]["text"].strip() + 'Q:“run left” A:'
response_CM_2 = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CM_2,
temperature=0.5,
max_tokens=1000
)
response_CM_2["choices"][0]["text"].strip()
结果如下:

- 翻译第三个子命令run opposite left
第三个子命令的翻译,则需要同时将此前两个子命令的问答都加入Few-shot中,然后再进行提问,代码如下:
prompt_CM_3 = prompt_CM_2 + response_CM_2["choices"][0]["text"].strip() + 'Q:“run opposite left” A:'
response_CM_3 = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CM_3,
temperature=0.5,
max_tokens=1000
)
response_CM_3["choices"][0]["text"].strip()
结果如下:
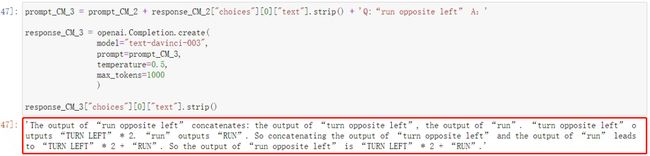
- 提问原始问题,流程如下
在获得了每个子命令的问答结果之后,接下来,将每个子命令的问答结果都拼接到Few-shot中,并对模型提问原始问题,流程如下:
prompt_CM = prompt_CM_3 + response_CM_3["choices"][0]["text"].strip() + 'Q:“%s” A:' % X
response_CM = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CM,
temperature=0.5,
max_tokens=1000
)
response_CM["choices"][0]["text"].strip()
结果如下:
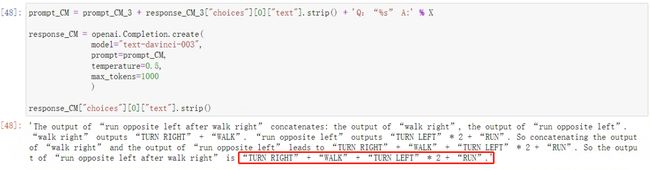
获得原始问题的答案为“TURN RIGHT” + “WALK” + “TURN LEFT” * 2 + “RUN”,该*回答和该条指令的真实标签y一致。
- 获取结果
将response_CM[“choices”][0][“text”].strip()对象转化为y格式,函数代码如下:
import re
def transform_expression(s):
# Regular expression pattern
pattern = r'is “.*'
# Find the match
match = re.search(pattern, s)
s = match.group()[3: -1].replace('“', '"').replace('”', '"')
# Step 1: Handle multiplications
pattern = r'"([^"]+)" \* (\d+)'
matches = re.findall(pattern, s)
for match in matches:
replacement = ' '.join([f'"{match[0]}"'] * int(match[1]))
s = s.replace(f'"{match[0]}" * {match[1]}', replacement)
# Step 2: Replace spaces within quotes with underscores
pattern = r'"([^"]+)"'
matches = re.findall(pattern, s)
for match in matches:
replacement = match.replace(' ', '_')
s = s.replace(f'"{match}"', f'"{replacement}"')
# Step 3: Add 'I_' prefix within quotes
pattern = r'"([^"]+)"'
matches = re.findall(pattern, s)
for match in matches:
replacement = 'I_' + match
s = s.replace(f'"{match}"', f'"{replacement}"')
# Step 4: Remove quotes
s = s.replace('"', '')
s = s.replace(' +', '')
return s
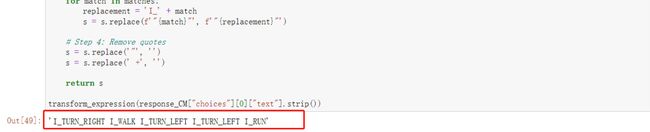
transform_expression(response_CM["choices"][0]["text"].strip())
输出如下:
上述完成了一次完整的基于复杂语义问题的LtM提示工程流程,并顺利获得准确答案。Few-shot-LtM提示流程非常复杂,以下是X到y翻译过程总结:
四、SCAN数据集完整预测流程
在了解了Few-shot-LtM的基本流程之后,实现一个更加自动化的Few-shot-LtM过程,并在完整的SCAN数据集上建模。
- Step 1:提取数据流
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("scan", "simple")
scan_test = dataset["test"]
scan_train = dataset["train"]
- Step 2:提示示例补充
根据原论文的描述,为了更好的完成完整数据集的预测,第一阶段命令拆解需要设置8组问答示例,第二阶段命令映射则需要设置14组问答示例
CD_Few_shot = 'Q: “look right after look twice” \
A: “look right after look twice” can be solved by: “look right”, “look twice”. \
Q: “jump opposite right thrice and walk” \
A: “jump opposite right thrice” can be solved by: “jump opposite right”, “jump opposite right thrice”. \
“walk” can be solved by: “walk”. So, “jump opposite right thrice and walk” can be solved by: “jump \
opposite right”, “jump opposite right thrice”, “walk”. \
Q: “run left twice and run right” \
A: “run left twice” can be solved by: “run left”, “run left twice”. “run right” can be solved by “run right”. \
So, “run left twice and run right” can.be solved by: “run left”, “run left twice”, “run right”. \
Q: “run opposite right” \
A: “run opposite right” can be solved by “run opposite right”. \
Q: “look opposite right thrice after walk” \
A: “look opposite right thrice” can be solved by: “look opposite right”, “look opposite right thrice”. \
“walk” can be solved by “walk”. So, “look opposite right thrice after walk” can be solved by: “look \
opposite right”, “look opposite right thrice”, “walk”. \
Q: “jump around right” \
A: “jump around right” can be solved by: “jump right”, “jump around right”. So, “jump around right” \
can be solved by: “jump right”, “jump around right”. \
Q: “look around right thrice and walk” \
A: “look around right thrice” can be solved by: “look right”, “look around right”, “look around right \
thrice”. “walk” can be solved by “walk”. So, “look around right thrice and walk” can be solved by: \
“look right”, “look around right”, “look around right thrice”, “walk”. \
Q: “turn right after run right thrice” \
A: “turn right” can be solved by: “turn right”. “run right thrice” can be solved by: “run right”, “run \
right thrice”. So, “turn right after run right thrice” can be solved by: “turn right”, “run right”, “run right \
thrice”. \
'
CM_Few_shot = 'Q: “turn left” \
A: “turn left” outputs “TURN LEFT”. \
Q: “turn right” \
A: “turn right” outputs “TURN RIGHT”. \
Q: “jump left” \
A: The output of “jump left” concatenates: the output of “turn left”, the output of “jump”. “turn left” \
outputs “TURN LEFT”. “jump” outputs “JUMP”. So concatenating the output of “turn left” and the output of “jump” leads to “TURN LEFT” + “JUMP”. So the output of “jump left” is “TURN LEFT” + “JUMP”. \
Q: “run right” \
A: The output of “run right” concatenates: the output of “turn right”, the output of “run”. “turn right” \
outputs “TURN RIGHT”. “run” outputs “RUN”. So concatenating the output of “turn right” and the \
output of “run” leads to “TURN RIGHT” + “RUN”. So the output of “run right” is “TURN RIGHT” + \
“RUN”. \
Q: “look twice” \
A: The output of “look twice” concatenates: the output of “look”, the output of “look”. “look” outputs \
“LOOK”. So repeating the output of “look” two times leads to “LOOK” * 2. So the output of “look \
twice” is “LOOK” * 2. \
Q: “run and look twice” \
A: The output of “run and look twice” concatenates: the output of “run”, the output of “look twice”. \
“run” outputs “RUN”. “look twice” outputs “LOOK” * 2. So concatenating the output of “run” and the \
output of “look twice” leads to “RUN” + “LOOK” * 2. So the output of “run and look twice” is “RUN” + \
“LOOK” * 2. \
Q: “jump right thrice” \
A: The output of “jump right thrice” concatenates: the output of “jump right”, the output of “jump \
right”, the output of “jump right”. “jump right” outputs “TURN RIGHT” + “JUMP”. So repeating the \
output of “jump right” three times leads to (“TURN RIGHT” + “JUMP”) * 3. So the output of “jump \
right thrice” is (“TURN RIGHT” + “JUMP”) * 3. \
Q: “walk after run” \
A: The output of “walk after run” concatenates: the output of “run”, the output of “walk”. “run” outputs \
“RUN”. “walk” outputs “WALK”. So concatenating the output of “run” and the output of “walk” leads to \
“RUN” + “WALK”. So the output of “walk after run” is “RUN” + “WALK”. \
Q: “turn opposite left” \
A: The output of “turn opposite left” concatenates: the output of “turn left”, the output of “turn left”. \
“turn left” outputs “TURN LEFT”. So repeating the output of “turn left” twice leads to “TURN LEFT” * \
2. So the output of “turn opposite left” is “TURN LEFT” * 2. \
Q: “turn around left” \
A: The output of “turn around left” concatenates: the output of “turn left”, the output of “turn left”, the \
output of “turn left”, the output of “turn left”. “turn left” outputs “TURN LEFT”. So repeating the output \
of “turn left” four times leads to “TURN LEFT” * 4. So the output of “turn around left” is “TURN LEFT” \
* 4. \
Q: “turn opposite right” \
A: The output of “turn opposite right” concatenates: the output of “turn right”, the output of “turn \
right”. “turn right” outputs “TURN RIGHT”. So repeating the output of “turn right” twice leads to \
“TURN RIGHT” * 2. So the output of “turn opposite right” is “TURN RIGHT” * 2. \
Q: “turn around right” \
A: The output of “turn around right” concatenates: the output of “turn right”, the output of “turn right”, \
the output of “turn right”, the output of “turn right”. “turn right” outputs “TURN RIGHT”. So repeating \
the output of “turn right” four times leads to “TURN RIGHT” * 4. So the output of “turn around right” \
is “TURN RIGHT” * 4. \
Q: “walk opposite left” \
A: The output of “walk opposite left” concatenates: the output of “turn opposite left”, the output of \
“walk”. “turn opposite left” outputs “TURN LEFT” * 2. “walk” outputs “WALK”. So concatenating the \
output of “turn opposite left” and the output of “walk” leads to “TURN LEFT” * 2 + “WALK”. So the \
output of “walk opposite left” is “TURN LEFT” * 2 + “WALK”. \
Q: “walk around left” \
A: The output of “walk around left” concatenates: the output of “walk left”, the output of “walk left”, \
the output of “walk left”, the output of “walk left”. “walk left” outputs “TURN LEFT” + “WALK”. So \
repeating the output of “walk around left” four times leads to (“TURN LEFT” + “WALK”) * 4. So the \
output of “walk around left” is (“TURN LEFT” + “WALK”) * 4. \
'
- Step 3:第一阶段的提示工程
做命令拆解,代码如下:
def extract_phrases(text):
# 查找最后一个 "solved by:" 后面的所有内容
last_solved_by = text.rsplit("solved by:", 1)[-1]
# 使用正则表达式提取引号中的短语
phrases = re.findall(r'“([^”]*)”', last_solved_by)
return phrases
测试一下函数:
response_CD["choices"][0]["text"].strip()
CD_result = extract_phrases(response_CD["choices"][0]["text"].strip())
CD_result

- Step 4: 第二阶段提示工程
from tqdm import tqdm
CM_Few_shot_temp = CM_Few_shot
sub_qs = CD_result
for qs in tqdm(sub_qs):
CM_Few_shot_temp += 'Q:“%s” A:' % qs
response_CM = openai.Completion.create(
model="text-davinci-003",
prompt=CM_Few_shot_temp,
temperature=0.5,
max_tokens=1000,
)
CM_Few_shot_temp += response_CM["choices"][0]["text"].strip()
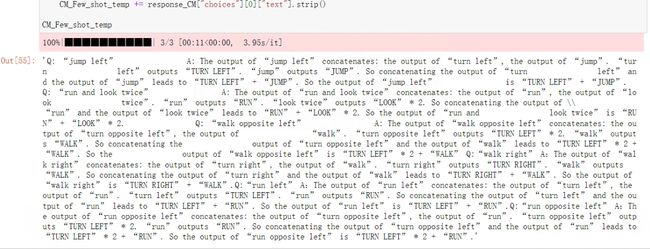
CM_Few_shot_temp
看下结果:
- Step 5:对原始问题提问并获取最终结果,代码如下:
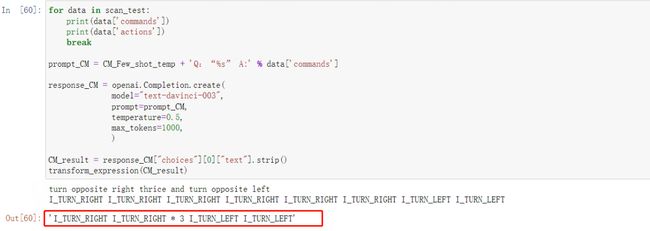
for data in scan_test:
print(data['commands'])
print(data['actions'])
break
prompt_CM = CM_Few_shot_temp + 'Q:“%s” A:' % data['commands']
response_CM = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CM,
temperature=0.5,
max_tokens=1000,
)
CM_result = response_CM["choices"][0]["text"].strip()
transform_expression(CM_result)
看下最终结果:
- Step 6:完整函数封装
CD_Few_shot = 'Q: “look right after look twice” \
A: “look right after look twice” can be solved by: “look right”, “look twice”. \
Q: “jump opposite right thrice and walk” \
A: “jump opposite right thrice” can be solved by: “jump opposite right”, “jump opposite right thrice”. \
“walk” can be solved by: “walk”. So, “jump opposite right thrice and walk” can be solved by: “jump \
opposite right”, “jump opposite right thrice”, “walk”. \
Q: “run left twice and run right” \
A: “run left twice” can be solved by: “run left”, “run left twice”. “run right” can be solved by “run right”. \
So, “run left twice and run right” can.be solved by: “run left”, “run left twice”, “run right”. \
Q: “run opposite right” \
A: “run opposite right” can be solved by “run opposite right”. \
Q: “look opposite right thrice after walk” \
A: “look opposite right thrice” can be solved by: “look opposite right”, “look opposite right thrice”. \
“walk” can be solved by “walk”. So, “look opposite right thrice after walk” can be solved by: “look \
opposite right”, “look opposite right thrice”, “walk”. \
Q: “jump around right” \
A: “jump around right” can be solved by: “jump right”, “jump around right”. So, “jump around right” \
can be solved by: “jump right”, “jump around right”. \
Q: “look around right thrice and walk” \
A: “look around right thrice” can be solved by: “look right”, “look around right”, “look around right \
thrice”. “walk” can be solved by “walk”. So, “look around right thrice and walk” can be solved by: \
“look right”, “look around right”, “look around right thrice”, “walk”. \
Q: “turn right after run right thrice” \
A: “turn right” can be solved by: “turn right”. “run right thrice” can be solved by: “run right”, “run \
right thrice”. So, “turn right after run right thrice” can be solved by: “turn right”, “run right”, “run right \
thrice”. \
'
CM_Few_shot = 'Q: “turn left” \
A: “turn left” outputs “TURN LEFT”. \
Q: “turn right” \
A: “turn right” outputs “TURN RIGHT”. \
Q: “jump left” \
A: The output of “jump left” concatenates: the output of “turn left”, the output of “jump”. “turn left” \
outputs “TURN LEFT”. “jump” outputs “JUMP”. So concatenating the output of “turn left” and the output of “jump” leads to “TURN LEFT” + “JUMP”. So the output of “jump left” is “TURN LEFT” + “JUMP”. \
Q: “run right” \
A: The output of “run right” concatenates: the output of “turn right”, the output of “run”. “turn right” \
outputs “TURN RIGHT”. “run” outputs “RUN”. So concatenating the output of “turn right” and the \
output of “run” leads to “TURN RIGHT” + “RUN”. So the output of “run right” is “TURN RIGHT” + \
“RUN”. \
Q: “look twice” \
A: The output of “look twice” concatenates: the output of “look”, the output of “look”. “look” outputs \
“LOOK”. So repeating the output of “look” two times leads to “LOOK” * 2. So the output of “look \
twice” is “LOOK” * 2. \
Q: “run and look twice” \
A: The output of “run and look twice” concatenates: the output of “run”, the output of “look twice”. \
“run” outputs “RUN”. “look twice” outputs “LOOK” * 2. So concatenating the output of “run” and the \
output of “look twice” leads to “RUN” + “LOOK” * 2. So the output of “run and look twice” is “RUN” + \
“LOOK” * 2. \
Q: “jump right thrice” \
A: The output of “jump right thrice” concatenates: the output of “jump right”, the output of “jump \
right”, the output of “jump right”. “jump right” outputs “TURN RIGHT” + “JUMP”. So repeating the \
output of “jump right” three times leads to (“TURN RIGHT” + “JUMP”) * 3. So the output of “jump \
right thrice” is (“TURN RIGHT” + “JUMP”) * 3. \
Q: “walk after run” \
A: The output of “walk after run” concatenates: the output of “run”, the output of “walk”. “run” outputs \
“RUN”. “walk” outputs “WALK”. So concatenating the output of “run” and the output of “walk” leads to \
“RUN” + “WALK”. So the output of “walk after run” is “RUN” + “WALK”. \
Q: “turn opposite left” \
A: The output of “turn opposite left” concatenates: the output of “turn left”, the output of “turn left”. \
“turn left” outputs “TURN LEFT”. So repeating the output of “turn left” twice leads to “TURN LEFT” * \
2. So the output of “turn opposite left” is “TURN LEFT” * 2. \
Q: “turn around left” \
A: The output of “turn around left” concatenates: the output of “turn left”, the output of “turn left”, the \
output of “turn left”, the output of “turn left”. “turn left” outputs “TURN LEFT”. So repeating the output \
of “turn left” four times leads to “TURN LEFT” * 4. So the output of “turn around left” is “TURN LEFT” \
* 4. \
Q: “turn opposite right” \
A: The output of “turn opposite right” concatenates: the output of “turn right”, the output of “turn \
right”. “turn right” outputs “TURN RIGHT”. So repeating the output of “turn right” twice leads to \
“TURN RIGHT” * 2. So the output of “turn opposite right” is “TURN RIGHT” * 2. \
Q: “turn around right” \
A: The output of “turn around right” concatenates: the output of “turn right”, the output of “turn right”, \
the output of “turn right”, the output of “turn right”. “turn right” outputs “TURN RIGHT”. So repeating \
the output of “turn right” four times leads to “TURN RIGHT” * 4. So the output of “turn around right” \
is “TURN RIGHT” * 4. \
Q: “walk opposite left” \
A: The output of “walk opposite left” concatenates: the output of “turn opposite left”, the output of \
“walk”. “turn opposite left” outputs “TURN LEFT” * 2. “walk” outputs “WALK”. So concatenating the \
output of “turn opposite left” and the output of “walk” leads to “TURN LEFT” * 2 + “WALK”. So the \
output of “walk opposite left” is “TURN LEFT” * 2 + “WALK”. \
Q: “walk around left” \
A: The output of “walk around left” concatenates: the output of “walk left”, the output of “walk left”, \
the output of “walk left”, the output of “walk left”. “walk left” outputs “TURN LEFT” + “WALK”. So \
repeating the output of “walk around left” four times leads to (“TURN LEFT” + “WALK”) * 4. So the \
output of “walk around left” is (“TURN LEFT” + “WALK”) * 4. \
'
# 定义辅助函数,分别用于进行子问题的提取和最终问题结果的翻译
def extract_phrases(text):
# 查找最后一个 "solved by:" 后面的所有内容
last_solved_by = text.rsplit("solved by:", 1)[-1]
# 使用正则表达式提取引号中的短语
phrases = re.findall(r'“([^”]*)”', last_solved_by)
return phrases
import re
def transform_expression(s):
# Regular expression pattern
pattern = r'is “.*'
# Find the match
match = re.search(pattern, s)
s = match.group()[3: -1].replace('“', '"').replace('”', '"')
# Step 1: Handle multiplications
pattern = r'"([^"]+)" \* (\d+)'
matches = re.findall(pattern, s)
for match in matches:
replacement = ' '.join([f'"{match[0]}"'] * int(match[1]))
s = s.replace(f'"{match[0]}" * {match[1]}', replacement)
# Step 2: Replace spaces within quotes with underscores
pattern = r'"([^"]+)"'
matches = re.findall(pattern, s)
for match in matches:
replacement = match.replace(' ', '_')
s = s.replace(f'"{match}"', f'"{replacement}"')
# Step 3: Add 'I_' prefix within quotes
pattern = r'"([^"]+)"'
matches = re.findall(pattern, s)
for match in matches:
replacement = 'I_' + match
s = s.replace(f'"{match}"', f'"{replacement}"')
# Step 4: Remove quotes
s = s.replace('"', '')
s = s.replace(' +', '')
return s
# 是每条数据的预测过程
def SCAN_predict(dataSet=scan_test, model="text-davinci-003", CD_Few_shot=CD_Few_shot, CM_Few_shot=CM_Few_shot):
# 转化为dataframe
data_frame = dataSet.to_pandas()
# 最后一列标记为unkown
data_frame['actions_predict'] = 'unkown'
# 在字典中循环
for i,data in enumerate(dataSet):
# 阶段一:拆解命令
prompt_CD = CD_Few_shot + 'Q:“%s” A:' % data['commands']
response_CD = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CD,
temperature=0.5,
max_tokens=1000
)
# 拆解命令结果
CD_result = extract_phrases(response_CD["choices"][0]["text"].strip())
# 阶段二:短命令翻译
CM_Few_shot_temp = CM_Few_shot
sub_qs = CD_result
for qs in sub_qs:
CM_Few_shot_temp += 'Q:“%s” A:' % qs
response_CM = openai.Completion.create(
model="text-davinci-003",
prompt=CM_Few_shot_temp,
temperature=0.5,
max_tokens=1000,
)
CM_Few_shot_temp += response_CM["choices"][0]["text"].strip()
# 对原始问题提问
prompt_CM = CM_Few_shot_temp + 'Q:“%s” A:' % data['commands']
response_CM = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_CM,
temperature=0.5,
max_tokens=1000,
)
# 将结果保存在dataframe的对应位置
data_frame['actions_predict'][i] = transform_expression(CM_result)
return data_frame
# 验证实际预测效果,谨慎运行,可能会造成大量的费用
data_frame = SCAN_predict(dataSet=scan_test)
输出如下:
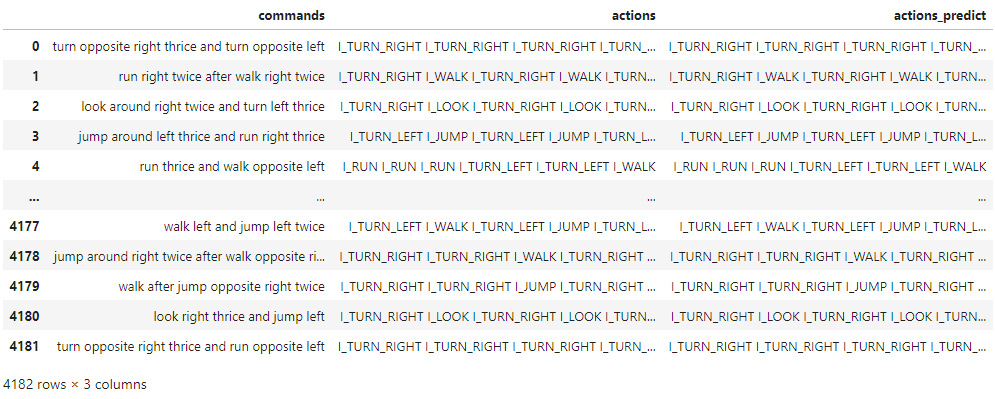
(data_frame['actions'] == data_frame['actions_predict']).sum() / data_frame.shape[0]
输出为1.0,在completion模型text-davinci-003预测下,SCAN数据集的预测准确率能够达到100%。
五、总结
Few-shot-LtM提示流程进行总结:
类似SCAN指令翻译这种复杂问题,很多时候Zero-shot都是无法解决的,对于更强的Few-shot来说,它的提示示例像是一个数据集中的训练数据,实际提示流程,就相当于是先让大模型学习训练数据来总结规律技巧,然后再进一步应用于新数据集上的预测。
和机器学习直接在完整数据集上随机划分训练集和测试集不同的是,Few-shot往往不需要太多数据(受限于模型的上下文限制,也无法输入太多数据),但需要合理的挑选问答示例,并详细的展示由问到答的推理过程,才能够更好的给与模型启发。
**在实际执行过程中,往往是先确定提示流程、再编写Few-shot。**提示工程流程是提示工程方法最高度的抽象,这方面创新难度较大,一般来说都是按照既有的提示框架进行完善和补充,就目前来看,LtM提示框架是最有效的提示框架。
在编写Few-shot的过程中,则是先从少部分数据中进行测试,刚开始编写和测试中间环节的问题和Few-shot会非常困难,往往都需要丰富的技术经验和一定的技术灵感。就本次复现实验来说,在基于对英文语义充分理解的情况下,核心工作是以介词为界进行短命令处理,而第二个阶段的Few-shot则是先从不包含介词的短语入手进行指令翻译,然后尝试围绕带入介词的短语进行翻译,当模型能够理解部分介词+动词+副词的组合含义后,即可将其推广至更为一般的情况。
从这个过程不难看出,大语言模型(LLMs)具备非常强的“迁移学习”能力,对于类似SCAN数据集这种学习难度非常大的任务,模型仍然可以在只带入非常少的数据的情况下完成底层推理规则的学习,由此也确实能看出大语言模型恐怖的涌现能力。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!