《TCP IP网络编程》第十章
第 10 章 多进程服务器端
10.1 进程概念及应用
并发服务端的实现方法:
通过改进服务端,使其同时向所有发起请求的客户端提供服务,以提高平均满意度。而且,网络程序中数据通信时间比 CPU 运算时间占比更大,因此,向多个客户端提供服务是一种有效的利用 CPU 的方式。接下来讨论同时向多个客户端提供服务的并发服务器端。下面列出的是具有代表性的并发服务端的实现模型和方法:
- 多进程服务器:通过创建多个进程提供服务
- 多路复用服务器:通过捆绑并统一管理 I/O 对象提供服务
- 多线程服务器:通过生成与客户端等量的线程提供服务
第一种方法:多进程服务器
理解进程:
进程的定义如下:
占用内存空间的正在运行的程序。
假如你下载了一个游戏到电脑上,此时的游戏不是进程,而是程序。只有当游戏被加载到主内存并进入运行状态,这是才可称为进程。
进程 ID:
无论进程是如何创建的,所有的进程都会被操作系统分配一个 ID。此 ID 被称为「进程ID」,其值为大于 2 的整数。1 要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户无法得到 ID 值为 1 。接下来输入以下命令来观察在 Linux 中运行的进程:
ps au
通过上面的命令可查看当前运行的所有进程。需要注意的是,该命令同时列出了 PID(进程ID)。参数 a 和 u列出了所有进程的详细信息。
通过调用 fork 函数创建进程:
创建进程的方式很多,此处只介绍用于创建多进程服务端的 fork 函数:
#include
pid_t fork(void);
// 成功时返回进程ID,失败时返回 -1 fork 函数将创建调用的进程副本。也就是说,并非根据完全不同的程序创建进程,而是复制正在运行的、调用 fork 函数的进程。另外,两个进程都执行 fork 函数调用后的语句(准确的说是在 fork 函数返回后)。但因为是通过同一个进程、复制相同的内存空间,之后的程序流要根据 fork 函数的返回值加以区分。即利用 fork 函数的如下特点区分程序执行流程。
- 父进程:fork 函数返回子进程 ID
- 子进程:fork 函数返回 0
此处,「父进程」(Parent Process)指原进程,即调用 fork 函数的主体,而「子进程」(Child Process)是通过父进程调用 fork 函数复制出的进程。接下来是调用 fork 函数后的程序运行流程。如图所示:
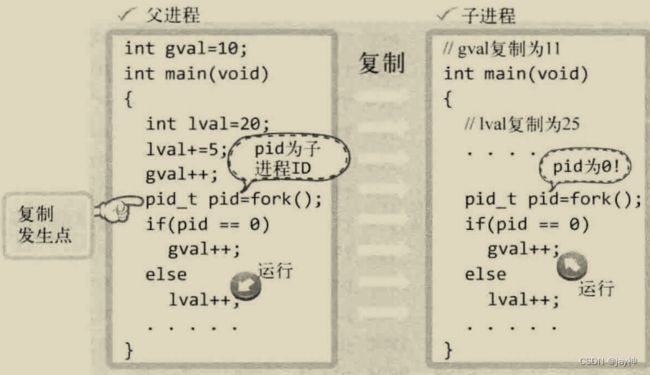
从图中可以看出,父进程调用 fork 函数的同时复制出子进程,并分别得到 fork 函数的返回值。但复制前,父进程将全局变量 gval 增加到 11,将局部变量 lval 的值增加到 25,因此在这种状态下完成进程复制。复制完成后根据 fork 函数的返回类型区分父子进程。父进程的 lval 的值增加 1 ,但这不会影响子进程的 lval 值。同样子进程将 gval 的值增加 1 也不会影响到父进程的 gval 。因为 fork 函数调用后分成了完全不同的进程,只是二者共享同一段代码而已。接下来给出一个例子:
#include
#include
int gval = 10;
int main(int argc, char *argv[])
{
pid_t pid;
int lval = 20;
gval++, lval += 5;
pid = fork();
if (pid == 0)
gval += 2, lval += 2;
else
gval -= 2, lval -= 2;
if (pid == 0)
printf("Child Proc: [%d,%d] \n", gval, lval);
else
printf("Parent Proc: [%d,%d] \n", gval, lval);
return 0;
} 运行结果:
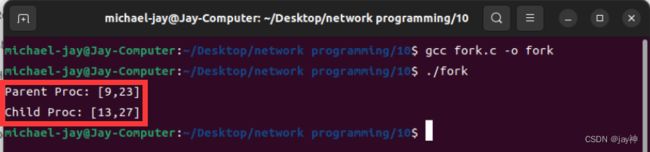
可以看出,当执行了 fork 函数之后,此后就相当于有了两个程序在执行代码,对于父进程来说,fork 函数返回的是子进程的ID,对于子进程来说,fork 函数返回 0。所以这两个变量,父进程进行了 +2 操作 ,而子进程进行了 -2 操作。
10.2 进程和僵尸进程
文件操作中,关闭文件和打开文件同等重要。同样,进程销毁和进程创建也同等重要。如果未认真对待进程销毁,他们将变成僵尸进程。
僵尸(Zombie)进程:
进程的工作完成后(执行完 main 函数中的程序后)应被销毁,但有时这些进程将变成僵尸进程,占用系统中的重要资源。这种状态下的进程称作「僵尸进程」,这也是给系统带来负担的原因之一。
僵尸进程是当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。如果父进程先退出 ,子进程被init接管,子进程退出后init会回收其占用的相关资源
产生僵尸进程的原因:
为了防止僵尸进程产生,先解释产生僵尸进程的原因。利用如下两个示例展示调用 fork 函数产生子进程的终止方式。
- 传递参数并调用 exit() 函数
- main 函数中执行 return 语句并返回值
向 exit 函数传递的参数值和 main 函数的 return 语句返回的值都会传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态下的进程就是僵尸进程。也就是说将子进程变成僵尸进程的正是操作系统。既然如此,僵尸进程何时被销毁呢?
应该向创建子进程的父进程传递子进程的 exit 参数值或 return 语句的返回值。
如何向父进程传递这些值呢?操作系统不会主动把这些值传递给父进程。只有父进程主动发起请求(函数调用)的时候,操作系统才会传递该值。换言之,如果父进程未主动要求获得子进程结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸进程状态。接下来的示例是创建僵尸进程:
#include
#include
int main(int argc, char *argv[])
{
pid_t pid = fork();
if (pid == 0)
{
puts("Hi, I am a child Process");
}
else
{
printf("Child Process ID: %d \n", pid);
sleep(30);
}
if (pid == 0)
puts("End child proess");
else
puts("End parent process");
return 0;
} 运行结果:
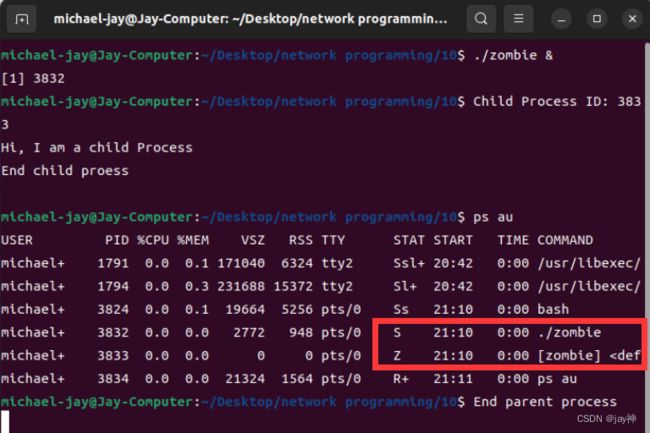
通过 ps au 命令可以看出,子进程仍然存在,并没有被销毁,僵尸进程在这里显示为 Z+.30秒后,红框里面的两个进程会同时被销毁。