基于 Flink SQL CDC 数据处理的终极武器
文章目录
-
- 一、传统的数据同步方案与 Flink SQL CDC 解决方案
-
- 1.1 Flink SQL CDC 数据同步与原理解析
- 1.2 基于日志的 CDC 方案介绍
- 1.3 选择 Flink 作为 ETL 工具
- 二、 基于 Flink SQL CDC 的数据同步方案实践
- 2.1 CDC Streaming ETL
- 2.2 Flink-CDC实践之mysql案例
来源互联网多篇文章总结
一、传统的数据同步方案与 Flink SQL CDC 解决方案
业务系统经常会遇到需要更新数据到多个存储的需求。例如:一个订单系统刚刚开始只需要写入数据库即可完成业务使用。某天 BI 团队期望对数据库做全文索引,于是我们同时要写多一份数据到 ES 中,改造后一段时间,又有需求需要写入到 Redis 缓存中。
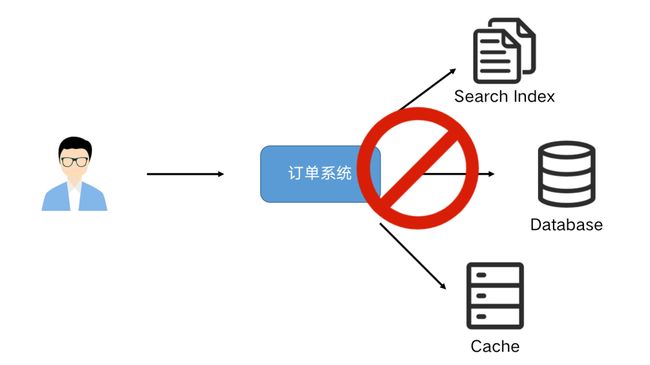
很明显这种模式是不可持续发展的,这种双写到各个数据存储系统中可能导致不可维护和扩展,数据一致性问题等,需要引入分布式事务,成本和复杂度也随之增加。
我们可以通过 CDC(Change Data Capture)工具进行解除耦合,同步到下游需要同步的存储系统,实现一份变动记录,实时处理并投递到多个目的地。通过这种方式提高系统的稳健性,也方便后续的维护。
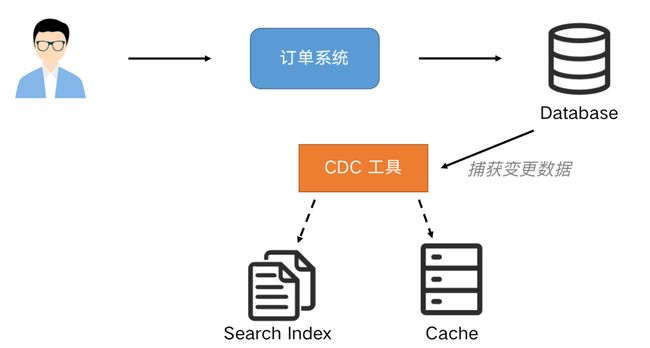
1.1 Flink SQL CDC 数据同步与原理解析
CDC 是变更数据捕获(Change Data Capture)技术的缩写,它可以将源数据库(Source)的增量变动记录,同步到一个或多个数据目的(Sink)。在同步过程中,还可以对数据进行一定的处理,例如分组(GROUP BY)、多表的关联(JOIN)等。
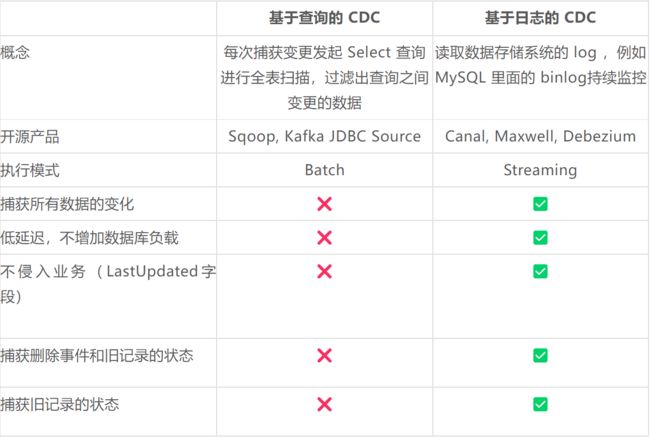
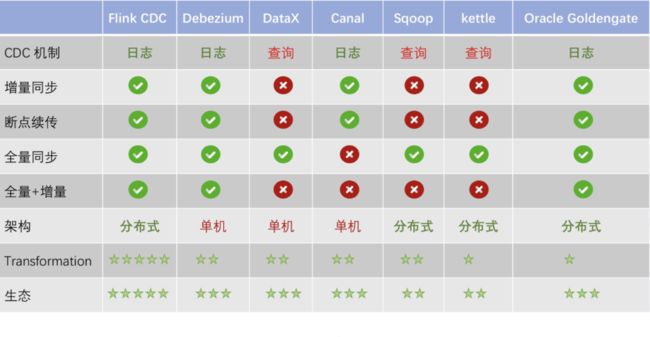
业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。
-
基于查询的 CDC
用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。这种方式优点是不涉及数据库底层特性,实现比较通用;缺点是要对业务表做改造,且实时性不高,不能确保跟踪到所有的变更记录,且持续的频繁查询对数据库的压力较大。
特点:基于批处理,不能捕获到所有数据的变化、高延迟、需要查询数据库,会增加数据库压力
-
基于日志的 CDC
可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。这种方式的优点是实时性高,可以精确捕捉上游的各种变动;缺点是部署数据库的事件接收和解析器(例如 Debezium、Canal 等),有一定的学习和运维成本,对一些冷门的数据库支持不够。综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用Debezium来实现变更数据的捕获。
特点: 基于streaming模式、能捕捉所有数据的变化、低延迟、不会增加数据库压力。
经过以上对比,我们可以发现基于日志 CDC 有以下这几种优势:
- 能够捕获所有数据的变化,捕获完整的变更记录。在异地容灾,数据备份等场景中得到广泛应用,如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失
- 每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤,拥有更高的效率和性能,具有低延迟,不增加数据库负载的优势
- 无需入侵业务,业务解耦,无需更改业务模型
- 捕获删除事件和捕获旧记录的状态,在查询 CDC 中,周期的查询无法感知中间数据是否删除
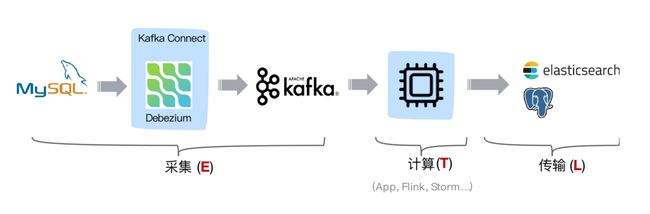
常见开源CDC方案比较
1.2 基于日志的 CDC 方案介绍
从 ETL 的角度进行分析,一般采集的都是业务库数据,这里使用 MySQL 作为需要采集的数据库,通过 Debezium 把 MySQL Binlog 进行采集后发送至 Kafka 消息队列,然后对接一些实时计算引擎或者 APP 进行消费后把数据传输入 OLAP 系统或者其他存储介质。
Flink 希望打通更多数据源,发挥完整的计算能力。我们生产中主要来源于业务日志和数据库日志,Flink 在业务日志的支持上已经非常完善,但是在数据库日志支持方面在 Flink 1.11 前还属于一片空白,这就是为什么要集成 CDC 的原因之一。
Flink SQL 内部支持了完整的 changelog 机制,所以 Flink 对接 CDC 数据只需要把CDC 数据转换成 Flink 认识的数据
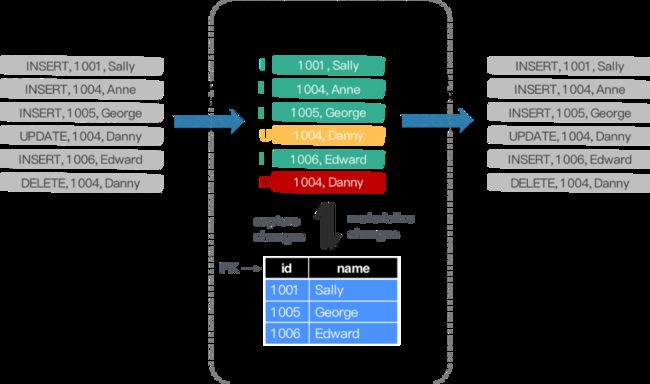
1.3 选择 Flink 作为 ETL 工具
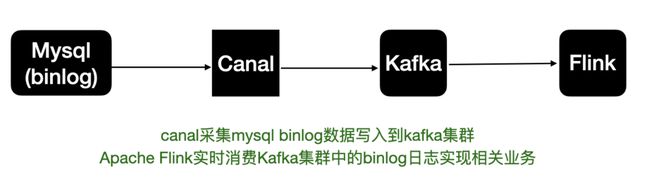
之前的mysql binlog日志处理流程,例如canal监听binlog把日志写入到kafka中。而Flink实时消费Kakfa的数据实现mysql数据的同步或其他内容等。
拆分来说整体上可以分为以下几个阶段:
- mysql开启binlog
- canal同步binlog数据写入到kafka
- flink读取kakfa中的binlog数据进行相关的业务处理。
- 整体的处理链路较长,需要用到的组件也比较多。
Apache Flink CDC可以直接从数据库获取到binlog供下游进行业务计算分析。简单来说链路如下图:
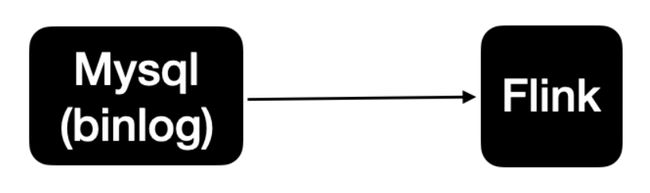
社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:
https://github.com/ververica/flink-cdc-connectors
flink-cdc-connectors 可以用来替换 Debezium+Kafka 的数据采集模块,从而实现 Flink SQL 采集+计算+传输(ETL)一体化,这样做的优点有以下:
- 开箱即用,简单易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯*
二、 基于 Flink SQL CDC 的数据同步方案实践
下面给大家带来2个关于 Flink SQL + CDC 在实际场景中使用较多的案例。在完成实验时候,你需要 Docker、MySQL、Elasticsearch 等组件,具体请参考每个案例参考文档。
2.1 CDC Streaming ETL
模拟电商公司的订单表和物流表,需要对订单数据进行统计分析,对于不同的信息需要进行关联后续形成订单的大宽表后,交给下游的业务方使用 ES 做数据分析,这个案例演示了如何只依赖 Flink 不依赖其他组件,借助 Flink 强大的计算能力实时把 Binlog 的数据流关联一次并同步至 ES 。
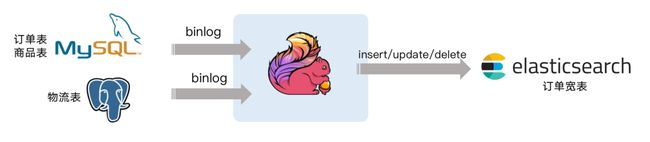
例如如下的这段 Flink SQL 代码就能完成实时同步 MySQL 中 orders 表的全量+增量数据的目的。
CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
SELECT * FROM orders
2.2 Flink-CDC实践之mysql案例
- 开启mysql binlog
查看mysql-binlog状态并开启mysql-binlog
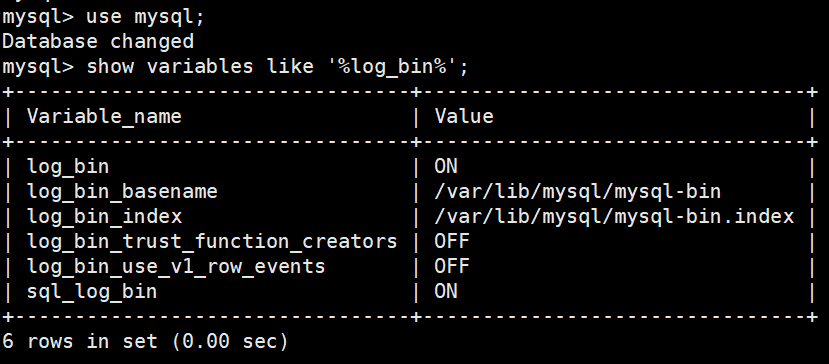
上图是开始的状态。如果没有开始,则log_bin=off,log_bin_basename和log_bin_index值为空。开启方式如下:
vim vim /etc/my.cnf
在添加以下信息:
#开启binglog
server-id=1
log-bin=/var/lib/mysql/mysql-bin
- server-id表示单个结点的id,这里由于只有一个结点,所以可以把id随机指定为一个数,这里将id设置成1。若集群中有多个结点,则id不能相同
- 第二句是指定binlog日志文件的名字为mysql-bin,以及其存储路径。
添加完成后保存退出。
重启mysql服务:
service mysqld restart
- 编写flinksql
- 源表:
create table Flink_source(id bigint, name string, age int,dt string)
with(
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.180',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test',
'table-name' = 'Flink_source'
);
可以知道,我们要去实时取Flink_source表,而这张表已经存储于mysql数据库的。
- 目标表:
create table Flink_target(id bigint primary key, name string, age int,dt string)
with(
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.1.180:3306/test',
'username'='root',
'password'='123456',
'table-name' = 'Flink_target',
'sink.buffer-flush.max-rows'='1',
'sink.buffer-flush.interval'='0'
);
可以知道,我们到实时存入目标表Flink_target,而这张表已经存储于mysql数据库。
- 插入数据
insert into Flink_target select * from Flink_source;