架构重构实践心得
一、前言
大多数的技术研发都对重构有所了解,而每个研发又都有自己的理解。从代码重构到架构重构,我参与了携程大型全链路重构项目,积累了一点经验心得,在此抛砖引玉和大家分享。
二、重构的定义
重构是指在不改变外部行为的情况下,改进其内部结构的软件系统更改过程。
三、重构的原因
3.1 组织架构调整
目前携程大部分业务场景都使用了微服务架构,要求服务应该封装单一的责任或单一的能力,以形成松散耦合的服务架构。
根据著名的康威定律,保证一个团队可以独立工作、快速交付变更、尽可能消除团队之间协作和协调的费力度。
所以当组织架构因为业务发展需要做相应调整时,决定了服务的架构也会需要相应的重构。
3.2 提升研发效能
重构遗留代码的目的,通常是使系统其更易于维护,减少维护系统所需的工作量,释放出研发资源处理更高价值的任务。
即使是在项目成功落地之后,仍然需要持续的系统迭代,支持新的业务需求。迭代过程引入新的缺陷也是难以避免的。
即使是最好的团队也可能会提交不成熟的代码,这往往会导致代码复杂性让系统变得难以维护,长期以往系统会越来越难以维护,影响研发效能。越来越长的开发周期,导致业务需求发布被推迟。
重构可以减少构建周期时间,改善需求交付时间。

3.3 偿还技术债
技术债是很多研发团队为了追求交互的速度,倾向于选择更简单但不太可靠的方案所付出的代价。短期内为了更快地交付做出的妥协都会在未来带来更多的工作量。
重构有助于消除开发人员积累的技术债务的数量。
3.4 应用现代化
遗留代码可能无法利用现代 DevOps 集成来加速 CI/CD。
遗留代码需要改造成无状态服务,这样可以适配云上的弹性伸缩,优化成本。
四、重构的影响面
从重构的影响面可以分为最高层次的架构重构和最低层次的代码重构。
代码重构是在修改代码后不会改变对外的行为,主要目的是提高整个软件的质量。一个重构通常是一个小任务,但是多个重构应用于代码可以显著提高其质量。
架构重构主要是将现有代码重新组织成新的层级,改变代码在逻辑层次中的组织方式。
4.1 架构重构和代码重构的比较
代码重构通常在一个开发团队内部达成一致,影响的范围容易控制和验证,风险较低。
架构重构必须要多个团队甚至是技术委员会达成一致,影响范围大,风险和成本较高。通常在做架构重构前尝试用可量化的指标来确定投入产出比,决策是否值得重构。
此外架构重构相比代码重构难度更高,对研发的专业知识要求也会更高,项目组里至少需要有一个熟悉链路上所有服务的资深研发,负责重构决策(特别是服务和服务边界处)。
五、重构计划

在开始重构编码之前,对现有系统深入分析,评估哪些部分应该被重构以及重构的优先级,有助于列出重构计划。
全链路上的大规模重构往往都是长期项目,初期制定的计划也肯定会有变化调整,特别是重构过程中会有新的业务需求进入,需要调整优先级,所以计划要分成不同的阶段性里程碑目标。
六、业务研发团队沟通
重构期间需要和负责业务需求的研发团队同步协调计划,优先对新需求部分重构,避免新功能完成后立即又成为重构任务。
例如,重构后的版本在下周就会发布运行,有些业务需求计划可以直接在新版本上实现,这样既避免了业务研发被技术债务困扰,也减少了重构项目组的工作量。
七、分层设计
分层设计即定义服务之间、模块之间的边界,是完成重构的关键,让代码之间的依赖关系变得更清晰,减少耦合性。
根据关注点分离原则,把现有的功能分类,将对应的代码移动到合适的层级和该层级对应的模块。
前提是需要理解每个类的功能是什么,当面对实现多个功能的类,必须要拆分成多个只服务于一个目的的类。
单一职责的类更具备可测试性,依赖更少的外部功能,减少测试用例里 Mock 的工作量。单一职责的类也更容易被复用,更容易维护。
大型重构项目会有许多工作要做,分层后的设计就像地图,避免研发迷失方向。
八、灰度
在分阶段重构的过程中,引入抽象层(例如面向接口编程),同一个接口有新老两套实现。抽象层的引入允许显示系统里新老版本多个实现的共存。
这种看似额外的临时兼容工作,可以带来以下好处:
-
我们在编写测试用例代码的时候,也尽量面向接口验证,这样在旧代码验证通过的案例能够运行在重构后的新代码上。
-
使用特性开关控制新老版本实现的切换,可以在不破坏原有的功能且对调用方透明的前提下逐步灰度在线上版本进行重大更改,最后新版本实现稳定后,删除老代码的实现。这种方式也能减少研发在重构时候的心智负担。
-
特性开关的引入也能够实现快速回退,控制因为新实现带来的破坏范围。但验证不能完全依赖线上业务流量(对业务有损),下文会提到重构版本在发布前的改善质量的方法。
九、改善质量
9.1 静态检查
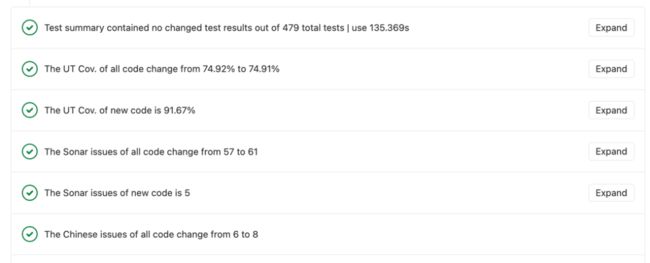
静态检查工具 Sonar
-
解决循环依赖
-
解决 Cyclomatic Complexity
-
控制每个类的方法数
-
控制每个方法的行数
-
解决 warning(删除不使用的代码,也意味着减少重构的工作量)
9.2 自动化测试
自动化测试是重构最重要的基础,它能确保系统的行为不会因为重构而改变。
在重构开始优先保证测试的覆盖率,所以我们会在重构前优先使用集成测试来验证重构结果:
-
集成测试相比单元测试覆盖率会更大,随着覆盖率越高,覆盖剩余的测试成本也会越大,例如一些异常边界场景,用单元测试覆盖的成本会更低。
-
有些单元测试往往和老系统代码耦合,没有面向接口测试,或者是一些静态类的测试。重构代码意味着单元测试需要重写,在早期重构阶段优先用集成测试覆盖验证。
设计集成测试需要减少对其他系统(尤其是和外部第三方交互)的依赖,通过一些 Mock 工具提供稳定的测试数据,让测试结果更稳定可靠,比如使用缓存保证相同的请求能拿到相同的结果,这也能帮助后续新老版本的比对回归验证。
借助 CI 持续迭代,每一次变更提交会触发自动化测试回归验证,在早期开发阶段快速暴露问题。同时也鼓励研发多次提交变更,避免一次提交包含太多的功能点,减少测试不通过排查问题的复杂度。
9.3 链路比对
在整个链路上的服务完成一次里程碑后,会做链路上的端到端的自动化测试,比对新老系统结果,验证整条链路。
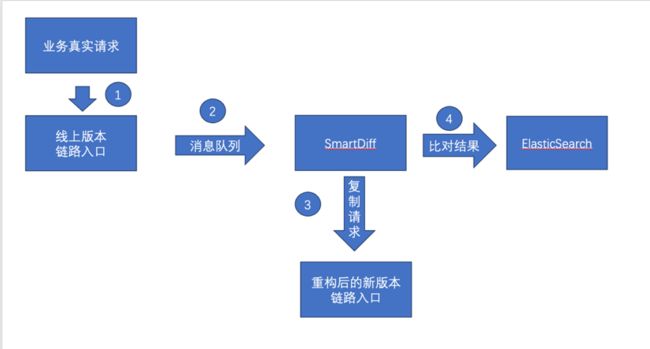
a. 线上版本链路入口在收到业务真实请求后,会把请求和响应推送到消息队列里。
b. 比对工具 SmartDiff 订阅消息队列,复制请求重构后的版本链路入口,拿到结果后和线上版本结果比对
c. SmartDiff 把比对结果写入 ES 日志,研发分析日志排查比对差异原因,修复问题。
十、可观察性
很多时候,软件架构容易被作为一个学术概念。即使是在一些成熟的研发团队,团队成员能够描述系统架构应该实现哪些重要的非业务功能需求(吞吐量、耗时、稳定性等等),但很难证明系统确实做到了这些。
尤其是系统经过长期多次迭代后,当前的架构实现是否还遵循原先的架构设计呢?如果无法验证,研发对架构也会失去信心。
所以我们需要对系统定义多个非功能性指标并将其可视化,线上持续地观察和确认是否和我们当初设计期望的指标一致。
比如读写缓存接口响应 P90 保持在 100ms 以内,假设后续为了提升缓存命中率,架构重构引入了多个缓存,P90 线 100ms 就可能会不达标。
指标可视化帮助我们快速发现新的设计带来的问题并做相应调整。这些非功能性指标就如同测试用例一样,快速发现问题、增强研发对架构重构的信心。