面试常问八股文之java篇
JAVA篇
1、为什么重写equals方法的时候要重写hashCode方法?
为了不违背“相同对象必须要有相同hash值"的约定,对于基本数据类型==比较的是数值是否相等,对于引用类型数据==比较的是对象地址是否同等,在object中equal方法也是默认比较两个对象地址是否相同。但是String类中重写了equals方法比较的是两个对象的内容,假如我们创建了两个内容相同的对象,那么按我们平常的理解它应该是同一个对象且hash值相同,此时需要重写equal方法保证内容相同的两个对象是同一个对象重写hashCode方法保证内容相同的两个对象的哈希值相同,不然默认使用object中的equals比较地址则认为不是同一个对象。
Object类中equals方法源码:
public boolean equals(Object obj){
return (this==obj);
}2、什么是哈希冲突?解决哈希冲突有哪些方法?
哈希冲突是:当两个不同的数(哈希值)经过哈希函数计算后得到了同一个结果,即他们会被映射到哈希表的同一个位置时,即称为发生了哈希冲突,简单来说就是哈希函数算出来的地址被别的元素占用了。
解决哈希冲突的方法有:
1、开放定址法:我们在遇到哈希冲突时,去寻找一个新的空闲的哈希地址。
(1)线性探测法
当我们的所需要存放值的位置被占了,我们就往后面一直加1并对m取模直到存在一个空余的地址供我们存放值,取模是为了保证找到的位置在0~m-1的有效空间之中。
公式:h(x)=(Hash(x)+i)mod (Hashtable.length);(i会逐渐递增加1)
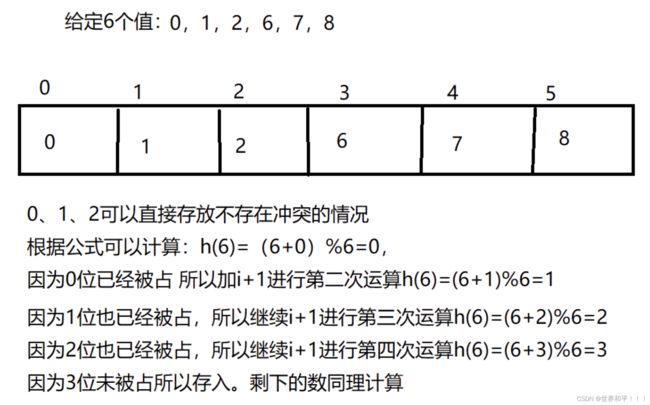
(2)平方探测法(二次探测)
当我们的所需要存放值的位置被占了,会前后寻找而不是单独方向的寻找。公式:h(x)=(Hash(x) +i)mod (Hashtable.length);(i依次为+(i^2)和-(i^2))
2、再哈希法:同时构造多个不同的哈希函数,等发生哈希冲突时就使用第二个、第三个……等其他的哈希函数计算地址,直到不发生冲突为止。虽然不易发生聚集,但是增加了计算时间。
3、链地址法:将所有哈希地址相同的记录都链接在同一链表中。
4、建立公共溢出区:将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中。
3、接口和抽象类的区别

4、Java 中的继承和 C++ 有什么不同
C++ 中可以实现多继承,而 Java 只能实现单继承。
5、Java 中有哪些数据结构?用过 HashMap 吗,说一下 HashMap 底层实现
数据结构有数组、链表、栈、队列、堆、树、Map 等。
HashMap 在 JDK1.7 之前采用数组加链表的形式实现,在 1.8 之后使用了红黑树:通过底层数组存储对象节点,采用链地址法,把新增对象节点连接在当前地址的节点下面,且规定当链表长度大于 8 时,将链表转换成红黑树结构。(详细讲解可以看其他博客或源码)
6、Java 中用的是值传递还是引用传递?
首先来解释一下什么是引用传递,什么是值传递。
- 引用传递(pass by reference)是指在调用方法时将实际参数的地址直接传递到方法中,那么在方法中对参数所进行的修改,将影响到实际参数。
- 值传递(pass by value)是指在调用方法时将实际参数拷贝一份传递到方法中,这样在方法中如果对参数进行修改,将不会影响到实际参数。
在java中当参数是基本类型使用的是值传递当参数是引用类型时使用引用传递。当传的是基本类型时,传的是值的拷贝,对拷贝变量的修改不影响原变量;当传的是引用类型时,传的是引用地址的拷贝,但是拷贝的地址和真实地址指向的都是同一个真实数据,因此可以修改原变量中的值;(但是同为引用类型的String比较特殊)当传的是String类型时,虽然拷贝的也是引用地址,指向的是同一个数据,但是String的值不能被修改(Sting 是final修饰的char[]),给String赋值是重新new了一个String对象,改变的是新对象的值,因此无法修改原变量中的值。
例如:
//基本数据类型:
public void test() {
int a = 1;
change(a);
System.out.println("a的值:" + a);
}
private void change(int a) {
a = a + 1;
}
// 输出a的值:1//引用数据类型
public void test() {
User user = new User();
user.setAge(18);
change(user);
System.out.println("年龄:" + user.getAge());
}
private void change(User user) {
user.setAge(19);
}
// 输出年龄:19//引用数据类型:
public void test() {
User user = new User();
user.setAge(18);
change(user);
System.out.println("年龄:" + user.getAge());
}
private void change(User user) {
user = new User();
user.setAge(19);
}
// 输出年龄:18//String类型:
public void test() {
String str = "hello";
change(str);
System.out.println(str);
}
private void change(String str) {
str = "world";
}
//输出值:hello7、static和final关键字
1、static变量
static变量也称为静态变量,静态变量和非静态变量的区别:
- 静态变量被所有对象共享,在内存中只有一个副本,在类初次加载的时候才会初始化
- 非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响
2、static方法
静态方法可以直接通过类名调用,任何的实例也都可以调用,因此静态方法中不能用this和super关键字,不能直接访问所属类的实例变量和实例方法(就是不带static的成员变量和成员成员方法),只能访问所属类的静态成员变量和成员方法。因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
3、static代码块
static代码块也叫静态代码块,是在类中独立于类成员的static语句块,可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果static代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。利用静态代码块可以对一些static变量进行赋值。
4、final关键字
final代表的是最终、不可改变的意思,可以被用来修饰类、变量和成员方法。final修饰一个类时,这个类会成为最终类,不可被继承。final修饰成员方法时,这个成员方法不能被重写。final修饰成员变量,只能被赋值一次且不可变,且必须是在这个成员变量所在的类对象创建之前被赋值。
- 对于基本类型,不可变说的是变量当中的数据不可改变
- 对于引用类型,不可变说的是变量当中的地址值不可改变,但是内容可以变改变(即地址所指向的对象)
5、static和final一块用表示什么
static final用来修饰成员变量和成员方法,可简单理解为“全局常量”! 对于变量,表示一旦给值就不可修改,并且通过类名可以访问。 对于方法,表示不可被重写,并且可以通过类名直接访问。
8、面向过程和面向对象有什么区别?
面向过程是一种以过程为中心的编程思想,在处理某件事的时候,以正在进行什么为主要目标,分步骤完成目标。而面向对象的思想是将事物抽象为对象,赋予其属性和方法,通过每个对象执行自己的方法来完成目标。面向过程效率更高,而面向对象耦合低(易复用),扩展性强,易维护。
9、final、finally、finalize 的区别?
- final 用于修饰属性、类、方法,修饰的变量一旦赋值后,不能被重新赋值。被 final 修饰的实例变量必须显式指定初始值。
- finally 用于异常处理,只能⽤在 try/catch 中,finally 后的代码总会被执行。
- finalize 是 java.lang.Object 类中的⽅法,每⼀个对象都会继承这个方法,再垃圾回收机制执行的时候会被调用,允许回收未被使用的内存垃圾。
10、throw和throws的区别
- throw用于方法内部,抛出的是异常对象,而throws用在方法声明中
- throw只能用于抛出一种异常,而throws可以抛出多个异常
- throw代表动作,表示抛出一个异常的动作; throws代表一种状态,代表方法可能有异常抛出
- throws抛出异常时,它的上级(调用者)也要申明抛出异常或者捕获,不然编译报错。而throw的话,可以不申明或不捕获(这是非常不负责任的方式)但编译器不会报错
11、什么是序列化?什么是反序列化?
- 序列化其实就是将对象转化成字节序列格式,使其可储存可传输。
- 反序列化就是将字节序列格式转换成对象,是序列化的补集。
12、深拷贝和浅拷贝
浅拷贝:浅拷贝是会将对象的每个属性进行依次复制,但是当对象的属性值是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
深拷贝:深拷贝和浅拷贝是针对复杂数据类型(对象及数组)来说的,浅拷贝只拷贝一层,而深拷贝是层层拷贝。
深拷贝复制变量值,对于非基本类型的变量,则递归至基本类型变量后,再复制。 深拷贝后的对象与原来的对象是完全隔离的,互不影响,对一个对象的修改并不会影响另一个对象。
13、什么是不可变类
不可变类是指实例的属性不能被修改的类。一个不可变类的实例对象从被创建出来,它的成员变量就不能被修改。Java 平台的类库中包含许多的不可变类,比如 String、基本类型的包装类等。不可变类比一般的更加安全。
14、为什么 Java 中 String 是不可变类?
- String 类中包含 char 数组 value、整形的 offset 和 count 三个属性,这三个属性都是 private 的,且没有提供方法修改数值,因此在初始化后无法从外部改变
- String 类中的这三个属性都是被 final 修饰的,无法从内部进行改变
-
方法区有一块特殊存储区域 String Pool,当创建 String 时,如果在 String Pool 中找到相同的字符串值,则会返回一个已存在 String 的引用而不会新建一个对象。假设 String 是可变的,则会导致其他引用这个字符串值的 String 的值发生变化
15、API 和 SPI 的区别
API 和 SPI 都是制定接口传输数据。API 是由实现方负责定义和实现,调用方只负责调用的 API。而 SPI 是指由调用方制定的接口,这个接口由实现方针对接口进行不同的实现,再由调用方选择实现方。例如在 JDBC 连接数据库时,针对不同的数据库需要不同的驱动实现,JDBC 提供了驱动接口,由不同的实现方进行实现了这些不同的驱动,然后我们就可以在 JDK 中引入这些实现了的驱动包进行使用。
16、进程和线程的区别
- 一个进程可以包含至少一个线程,一般来说也就是主线程,而一个线程只能属于一个进程
- 进程拥有独立的内存,而线程没有独立的资源空间, 只是暂时存储在计数器,寄存器,栈中,同一个进程间的线程可以共享资源
- 将代码放入到代码区之后,进程产生,但还没执行,我们所说的执行一般是是主线程main函数开始执行
- 进程对资源的保护要求高,而线程要求不高
- 进程是处理器这一层面的抽象,而线程是进程的基础上进一步并发的抽象
- 一个进程下,一个线程的挂掉,会导致整个进程的挂掉,而进程之间不会相互影响
- 同一个进程下,当某个线程使用进程的共享资源时,其他线程必须等待该线程结束
- 我们可以打个比方:进程相当于某一个大型项目,世界上可能有人同时在做这个项目,有其独特的方式;而线程就相当于这个项目下的一些程序员,多个程序员去完成这一个项目肯定要比一个人完成快的多,也就是能在同一时间操作
17、权限修饰符

18、抽象类的特点
- 抽象类和抽象方法必须使用obstract关键字修饰
- 抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类
-
抽象类不能实例化,抽象类如何实例化呢?参照多态的方式,通过子类对象实例化,这叫抽象类多态
-
抽象类的子类,要么重写抽象类中所有的抽象方法,要么是抽象类
19、常见的异常类有哪些写
- NullPointerException空指针异常
- ClassNotFoundException指定类不存在
- NumberFormatException字符串转换为数字异常
- indexOutOfBoundsException数组下标越界异常
- ClassCastException数据类型转换异常
- FileNotFoundException文件未找到异常
- NoSuchMethodException方法不存在异常
- IOException IO异常
- SocketException Socket异常
20、简述tcp和udp的区别
- tcp面向连接,udp面向非连接即发送数据前不需要建立连接
- tcp提供可靠的服务(数据传输),udp无法保证
- tcp面向字节流,udp面向报文
- tcp数据传输慢,udp数据传输快
21、说一下你熟悉的设计模式
- 单例模式:保证被创建一次,节省系统开销
- 工厂模式(简单工厂、抽象工厂):解耦代码
- 观察者模式:定义了对象之间的一对多的依赖,这样一来,当一个对象改变时它的所有的依赖者都会收到通知并自动更新
- 外观模式:提供一个统一的接口,用来访问子系统中的一群接口,外观定义了一个高层的接口,让子系统更容易使用
- 模板方式模式:定义了一个算法的骨架,而将一些步骤延迟到子类中,模板方法使得子类可以在不改变算法结构的情况下,重新定义算法的步骤
- 状态模式:允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类