基于mnist手写数字数据库识别算法matlab仿真,对比SVM,LDA以及决策树
目录
1.算法理论概述
1.1、MNIST手写数字数据库
1.2、SVM算法
1.3、LDA算法
1.4、决策树算法
2.部分核心程序
3.算法运行软件版本
4.算法运行效果图预览
5.算法完整程序工程
1.算法理论概述
基于MNIST手写数字数据库识别算法,对比SVM、LDA以及决策树。首先,我们将介绍MNIST数据库的基本信息和手写数字识别的背景,然后分别介绍SVM、LDA和决策树的基本原理和数学模型,并对比它们在手写数字识别任务中的性能。
1.1、MNIST手写数字数据库
MNIST是一种经典的手写数字数据库,包含60,000张训练图像和10,000张测试图像。每张图像的大小为28x28像素,包含一个手写数字0~9。MNIST数据集被广泛应用于手写数字识别任务中,是评估图像识别算法性能的标准数据集之一。
1.2、SVM算法
支持向量机(Support Vector Machine,SVM)是一种常用的分类算法,其基本原理是通过寻找最优分离超平面来实现数据分类。在SVM中,我们需要将输入数据映射到高维特征空间中,然后通过最大化分类间隔来寻找最优分离超平面。SVM的数学模型如下:
$$
\min_{w,b,\xi} \frac{1}{2}||w||^2 + C\sum_{i=1}^n \xi_i \
\text{s.t. } y_i(w^Tx_i+b)\geq 1 - \xi_i \
\xi_i \geq 0
$$
其中,w和b是分离超平面的参数,\xi_i是松弛变量,C是正则化参数,x_i是输入数据,y_i是数据对应的标签。
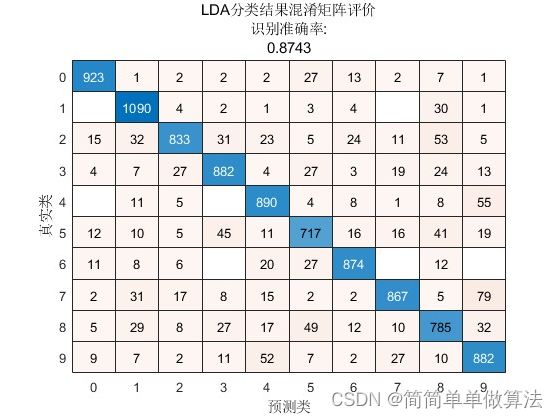
1.3、LDA算法
线性判别分析(Linear Discriminant Analysis,LDA)是一种常用的分类算法,其基本原理是通过投影将输入数据映射到低维特征空间中,然后通过最小化类内距离和最大化类间距离来实现数据分类。LDA的数学模型如下:
$$
\max_{w} \frac{w^TS_Bw}{w^TS_Ww} \
\text{s.t. } w^Tw = 1
$$
其中,S_B是类间散度矩阵,S_W是类内散度矩阵,w是投影向量。
1.4、决策树算法
决策树(Decision Tree)是一种常用的分类算法,其基本原理是通过构建一棵树形结构来实现数据分类。在决策树中,我们需要选择一个最优特征并将数据划分为不同的子节点,直到所有子节点都属于同一类别或达到预定的停止条件。决策树的数学模型可以表示为:
$$
y = f(x) = \sum_{i=1}^k c_i \cdot I(x\in R_i)
$$
其中,x是输入数据,R_i是第i个叶节点对应的数据区域,c_i是对应的类别标签,I(\cdot)是指示函数。
2.部分核心程序
...................................................................
[images, labels] = func_mnist_read('MNIST\train-images.idx3-ubyte', 'MNIST\train-labels.idx1-ubyte');
[test_images, test_labels] = func_mnist_read('MNIST\t10k-images.idx3-ubyte', 'MNIST\t10k-labels.idx1-ubyte');
% 对数据进行预处理
images = im2double(images);
[m,n,k] = size(images);
for i = 1:k
rawData(:,i) = reshape(images(:,:,i), m*n,1);
end
test_images = im2double(test_images);
[m,n,k] = size(test_images);
for i = 1:k
testData(:,i) = reshape(test_images(:,:,i), m*n,1);
end
% PCA Projection
% 对数据进行中心化处理
[m,n] = size(rawData);
mn = mean(rawData, 2);
X = rawData - repmat(mn, 1, n);
A = X/sqrt(n-1);
% 对数据进行奇异值分解,降维
[U,S,V] = svd(A,'econ');
projection_training = U(:, 1:154)'*X;
projection_training = projection_training./max(S(:));
[m, n] = size(testData);
test_avg = testData - repmat(mn, 1, n);
projection_test = U(:, 1:154)'*test_avg;
projection_test = projection_test./max(S(:));
% 将数据和标签转换成合适的格式
xtrain = projection_training;
label = labels';
%% SVM分类器训练和分类
proj_test = projection_test;
true_label = test_labels;
% 训练SVM分类器
Mdl = fitcecoc(xtrain',label);
% 对测试数据进行分类,并评估分类结果
testlabels = predict(Mdl,proj_test');
testNum = size(testlabels,1);
err = abs(testlabels - true_label);
err = err > 0;
errNum = sum(err);
sucRate = 1 - errNum/testNum
% 显示混淆矩阵
confusionchart(true_label, testlabels);
title(["SVM分类结果混淆矩阵评价",'识别准确率:',num2str(sucRate)]);
00043.算法运行软件版本
MATLAB2022a
4.算法运行效果图预览


5.算法完整程序工程
V V V