SQL Server笔记心得(持续更新)
SQL Server笔记
- 一、数据库基础
- 二、企业管理器
- 三、查询分析器
- 四、SQL Server 数据管理
- 五、数据基本查询
- 六、数据高级查询
- 七、连接查询
- 八、查询的实际应用
一、数据库基础
1、数据库
就是存储数据的地方
2、数据库管理系统
管理数据库及数据的计算机软件
数据库与应用程序

3、数据库技术的发展史
- 文件系统
- 使用磁盘文件夹存储数据
- 第一代数据库
- 出现了网状模型、层次模型的数据库
- 第二代数据库
- 关系型数据库和结构化查询语句
- 当前
- 关系数据库为主流,非关系型数据库大量使用
4、常见的关系型数据库
4.1、SQL Server 2012
- 针对不同用户群体不同版本
- 易用性好
- T-SQL
4.2、Oracle
- 关系-对象“型数据库
- 性能较高
- PL/SQL
4.3、Mysql
- 开源软件
- 结构简单部署方便
- 互联网应用多
4.4、PostgreSQL
- 开源、多平台、关系型数据库,功能最强大的开源数据库
- 支持事务
4.5、Sybase
- 它是基于客户/服务器体系结构的数据库
- 真正开放、高性能的数据库
4.6、DB2
- IBM厂商出品
- 支持海量数据
4.7、Access
- 简单易用
- 是 Microsoft Office的系统程序之
5、常见的非关系型数据库
5.1、Mongodb数据库
- 开源、多平台、文档型mosql数据库
- 非常主流的文档型mysql数据库,“最像关系型数据库”,定位于“灵活”的mysql据库
5.2、Redis数据库
- 开源、Linux平台、 key-value键值型Nosql数据库
- 简单稳定,非常主流的、全数据in- memory、定位于“快”的键值型nosql数据库
5.3、Memcaced数据库
- 一个开源的、高性能的、具有分布式内存对象的存系统
- 数据以key- value的方式存在
5.4、Bases数据库
- 一个分布式的、面向列的开源数据库
- 可用于海量数据存储、与 Hadoop生态圈结合、定位于“大”的列存储nosq数据库
6、Microsoft SQL Server 2012
- Microsoft SQL Server2012是微软发布的新一代数据平台产品,全面支持云技术与平台,并且能够快速构相应的解决方案实现私有云与公有云之间数据的扩展与应用的迁移
- 数据库引擎: 是用于存储、处理和保护数据的核心服务。这是本课程将详细讲解的部分。
- Reporting Services: 是一种报表平台,可用于创建和管理各种形式的报表。
- Analysis Services: 为商业智能应用程序提供了联机分析处理(OLAP和数据挖掘功能。
- Notification Services: 可以生成并向大量订阅方及时发送个性化的消息,向各种各样设备传递消息。
- Integration Services: 是一种企业数据转换和数据集成解决方案。
- 全文搜索: 可依据单词和短语对 SQL Server表中基于纯字符的数据进行全文查询。
二、企业管理器
1、文件和文件组
文件:
在 SQL Server中ー个数据库至少包含2种文件,数据库文件和事务日志文件。组成的一个数据库至少应包含一个数据库文件和一个事物日志文件。
文件组:
文件组是将多个数据库文件集合起来形成的一个整体,每个文件组有个组名与数据库文件一样,
文件组也分为主文件组( Primary FileGroup)和次文件组( Secondary File Group)。主数据库文件必须放在主文件组中,然而次数据库文件可以放在次文件组。
2、数据库文件( Database File)
- 扩展名为.mdf或.ndf
- 数据库文件是存放数据库数据和数据库对象的文件,一个数据库可以有一个或多个数据库文件
采用多个数据库文件来存储数据的优点
- 数据库文件可以不断扩充而不受操作系统文件大小的限制。
- 可以将数据库文件存储在不同的硬盘中,这样可以同时对几个硬盘做数据存取,提高了数据处理的效率。
3、事务日志文件( Transaction Log File)
- 事务日志文件是用来记录数据库更新情况的文件,扩展名为ldf,当对数据库进行操作时,都会记录在此文件中
- 注意:事务日志文件不属于任何文件组
4、分离、附加数据库
- 通过分离数据库会将数据库在本机上分离,通过分离会形成多个文件,以便使用
- 通过附加数据库将我们分离后的文件附加进数据库管理工具中。
5、SQL Server2012的数据类型
| 分类 | 备注和说明 | 数据类型 | 说明 |
|---|---|---|---|
| 二进制数据类型 | 存储非子符和文本的数据 | Image | 可用来存储图像 |
| 文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | Char | 固定长度的非 Unicode字符 |
| 文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | Var char | 可变长度非 Unicode字符 |
| 文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | Nchar | 固定长度的非 Unicode字符 |
| 文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | Nvar char | 固定长度的非 Unicode字符 |
| 文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | text | 存储长文本信息 |
| 文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | Ntext | 存储可变长度的长文本 |
| 日期和时间 | 日期和时间在单引号内输 | Datetime | 日期和时间 |
| 数字数据 | 该数据仅包含效字,包括正数、负数、以及分数 | Int Smal I int | 整数 |
| 数字数据 | 该数据仅包含效字,包括正数、负数、以及分数 | Float Real | 数字 |
| 货币数据类型 | 用于十进制货币值 | Money | |
| Bit数据类型 | 表示是/否的数据 | Bit | 存储布尔数据类型 |
char 和var char的区别
- char 存储的是 固定长度的非 Unicode字符 char 存储的是 可变长度非 Unicode字符
- 他俩的区别就在于一个固定长度,一个可变长度。他的固定长度指的是在数据库中它实际占用的位置
Nchar 字符是为了解决编码的问题、
- 如果你写的大部分内容是英文的 那么推荐使用Var char、Var char 是为了解决英文字符的
- 如果你写的大部分内容都是中文的那么推荐使用Nchar
6、数据完整性
- 数据完整性( Data Integrity)是指数据的精确性( Accuracy)和可靠性( Reliability)
- 它是应防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的
数据完整性主要体现在以下三个方面:
- 实体完整性
实体完整性指表中行的完整性。 - 域完整性
域完整性能够保证表中的数据是合法的数据。 - 引用完整性(参照完整性)
引用完整性是指某列的值必须与其他列的值匹配。

约束方法:限制数据类型、检査约束、外键约束、默认值、非空约束
建库
--建库
CREATE DATABASE test
ON PRIMARY
(
NAME='test_data',
FILENAME='D:\DATA\test_data.mdf',
SIZE=5MB,
MAXSIZE=50MB,
FILEGROWTH=10%
)LOG ON
(
NAME ='test_log',
FILENAME='D:\DATA\test_log.ldf',
SIZE=5MB,
FILEGROWTH=1MB
)
GO
三、查询分析器
使用查询分析器管理库、表
1、管理数据库语言
SQL
- 结构化查询语言({ Structured Query Language)简称SQL是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名
T-SQL
- T-SQL即 Transact-SQL,是SQL在 Microsoft SQL Server上的增强版,它是用来让应用程序与5 QL Server沟通的主要语言。T-SQL提供标准SQL的DDL和DML功能,加上延伸的函数、系统预存程序以及程序设计结构(例如 if 和while)让程序设计更有弹性
2、建库、建表
2.1、创建数据库
CREATE DATABASE 数据库名
ON [PRIMARY] ---可以省略---
(
<数据文件参数> [,...n] [<文件参数>] -----有1.文件名称 2.路径 3.初始大小 4.增长率......
)
[ LOG ON]
(
{<日志文件参数> [,...n]}
)
2.2、创建school数据库
CREATE DATABASE school --创建数据库。新建school数据库
ON PRIMARY --默认就属于PRIMARY主文件组,可省略
(
--数据文件的具体描述--
NAME='school_data', --主数据文件的逻辑名
FILENAME='D:\DATA\school_data.mdf', ---主数据文件的物理名 包含了所处的路径
SIZE=5MB, ---主数据文件的初始大小 最小5M
MAXSIZE=50MB, ---主数据文件增长的最大值
FILEGROWTH=10% ---主数据文件的增长率
---2种方式 一种百分比 一种是我们的文件大小或字节数
)LOG ON
( --日志文件的具体描述,各参数含义同上---
NAME ='school_log',
FILENAME='D:\DATA\school_log.ldf',
SIZE=5MB,
FILEGROWTH=1MB
)
GO
2.3、删除数据库
DROP DATABASE 数据库名
–删除school数据库
DROP DATABASE school
2.4、创建表
CREATE TABLE 表名
(
字段1 数据类型 属性 约束,
字段2 数据类型 属性 约束,
...
)
2.5、创建学生信息表(student)
USE school ---将当前数据库设置为school
CREATE TABLE student ----创建学生信息表
(
id int NOT NULL, --学生序号,非空
name varchar(64) NOT NULL, --学生姓名,非空
sex varchar(4) NOT NULL, --学生性别,非空
age int NOT NULL, --学生年龄,非空
clazz_id int NOT NULL, --学生班级编号,非空
stu_num varchar(64) NOT NULL, --学号,非空
)
2.6、创建信息表(student)
USE school --将当前数据库设置为school
CREATE TABLE clazz ---创建班级信息表
(
id int NOT NULL, --班级序号,非空
name varchar(64) NOT NULL, --班级名称,非空
teacher_name varchar(4) NOT NULL, --班主任名字,非空
)
2.7、删除学生信息表(student)
DROP TABLE 表名
—删除学生信息表
DROP TABLE student
3、管理约束
常见约束
- 主键约束 (primary key constraint)
- 唯一约束 (unique constraint)
- 检查约束 (check constraint)
- 默认约束 (default constraint)
- 外键约束 (foreign key constraint)
3.1、添加约束 什么时候用 在表已经存在的时候用
ALTER TABLE 表名
ADD CONSTRAINT 约束名 约束类型 具体的约束说明
3.2、为学生信息表添加约束
–为学生信息表添加主键 \为班级信息表添加主键
ALTER TABLE student \ clazz
ADD CONSTRAINT PK_id PRIMARY KEY (id)
–为学生信息表添加默认约束
ALTER TABLE student
ADD CONSTRAINT DF_sex DEFAULT('男')FOR sex
–为学生信息表添加检查约束
ALTER TABLE student
ADD CONSTRAINT CK_age CHECK(age>1)
–为学生信息表添加外键约束
ALTER TABLE student
ADD CONSTRAINT FK_clazz_id
FOREIGN KEY(clazz_id)REFERENCES clazz(id)
–为学生信息表添加惟一键
ALTER TABLE student
ADD CONSTRAINT UQ_stu_num UNIQUE(stu_num)
4、一种更简洁的添加约束方法 什么时候可以用 在新建表的时候可以用
clazz 表
USE school --将当前数据库设置为school
CREATE TABLE clazz --创建班级信息表
(
id int NOT NULL, PRIMARY KEY IDENTITY(1,1), --主键自增
name varchar(64) NOT NULL , --学生姓名 非空
teacher_name varchar(4) NOT NULL, --老师 非空
)
student表
USE school --将当前数据库设置为 students
CREATE TABLE student --创建学生信息表
(
id int NOT NULL PRIMARY KEY IDENTITY(1,1), --主键自增
name varchar(64) NOT NULL , --学生姓名 非空
sex varchar(4) NOT NULL DEFAULT('男'), --默认约束
age int NOT NULL CHECK(age>1), --检查约束
clazz_id int NOT NULL REFERENCES clazz(id), --外键约束
stu_num varchar(64) NOT NULL UNIQUE --唯一键
)
5、删除约束
ALTER TABLE 表名
DROP CONSTRAINT 约束名
–删除学生信息表的默认约束
ALTER TABLE student
DROP CONSTRAINT DF_sex
四、SQL Server 数据管理
1、T-SQL的组成
DML(数据操作语言)
- 查询、 插入、 修改和 删除数据库中的数据
- SELECT INSERT UPDATE DELETE
- DCL(数据控制语言)
- 用来控制存取许可、存取权限等
- GRANT REVOKE等
DDL(数据定义语言)
- 用来建立数据库、数据库对象和定义其列
- CREATE TABLE、 DROP TABLE等
变量说明、流程控制、功能函数
- 定义变量、判断、分支、循环结构等
- 日期函数、数学函数、字符函数、系统函数等
2、T-SQL中的比较运算符
| 运算符 | 含义 |
|---|---|
| = | 等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于或等于 |
| <= | 小于或等于 |
| <> | 不等于 |
| ! | 非 |
3、逻辑运算符
| 逻辑表达式 | 说明 | 示例 |
|---|---|---|
| AND | 逻辑与 | 1 AND 1 =1 ; 1 AND 0 =0 ; 0 AND 0 =0 ; |
| OR | 逻辑或 | 1 OR 1 =1 ; 1 OR0 =0 ; 0 OR 0 =0 ; |
| NOT | 逻辑非 | NOT 1 =0 ; NOT 0=1 ; |
4、基本
4.1、简单查询数据
语法
SELECT <列名> FROM <表名> [WHERE 条件表达式] --[] 中括号 就是可有可无
例子
SELECT * FROM clazz
4.2、插入数据
语法
INSERT [INTO] <表名> [列名]VALUES <值列表>
例子
INSERT INTO clazz (name,teacher_name )VALUES ('软件1908','张三')
–可以省略表白名后面的列名,但需要保证 VALUES 后的各项数据的顺序和表中字段顺序一致
语法
INSERT [INTO] <表名> VALUES <值列表>
例子
INSERT INTO clazz values ('软件1910','王二')
INSERT INTO clazz values ('软件1911','张三')
–如果指定了具有默认值或者允许为空的列名,在插入数据时就需要用到DEFAULT和NULL 关键字
例子
INSERT INTO clazz (name,teacher_name ) values ('软件1912',NULL)
–插入多行数据可以使用
INSERT...SELECT...UNION
例子
INSERT INTO clazz (name,teacher_name )
SELECT '软件1911','张三'UNION
SELECT '软件1912','李四'UNION
SELECT '软件1913','王五'
–插入数据(拷贝) ~拷贝数据到另外一张新的(不存在)表中
例子
SELECT * INTO clazz2 FROM clazz
注意:此种方法拷贝的新表只具备数据而不具备原表的约束
–拷贝数据到另一种已创建好的表中
例子
INSERT INTO clazz2(id,name,teacher_name)
SELECT id,name,teacher_name FROM clazz
4.3、更新数据
语法
UPDATE <表名> SET <列名=更新值> [WHERE <更新条件>]
例子
UPDATE clazz SET teacher_name='王飞'WHERE id=2
案例
----修改所有人的性别为’男’
UPDATE student SET sex='男'
----修改所有班级序号为1的所有同学的年龄及班级序号
UPDATE student SET age=20,clazz_id=2 WHERE clazz_id=1
----将年龄小于16的同学的年龄变为18岁
UPDATE student SET age=18 WHERE age<16
—将所有同学的年龄+1
UPDATE student SET age=age+1
4.4、删除数据
1.语法
DELETE FROM <表名> [WHERE 条件表达式]
例子
DELETE FROM student WHERE id=2
2.语法
TRUNCATE TABLE <表名> 后面不能加where条件
例子
TRUNCATE TABLE student
—注意:
- TRUNCATE 词句与没有条件表达式的DELETE 结果一样,但是执行速度更快,如果有自增列,此句执行之后自增将从1重新开始,
- 而DELETE则是继续按照删除之前的继续增长。
- DELETE删除之后添加数据是按照之前的序号增长 。而TRUNCATE 是从一重新开始
总结
- T-SQL的组成
- T-SQL语句提供条件表达式和运算符来筛选数据
- SELECT语句查询数据表中数据
- INSERT语句向数据表插入数据
- 利用3种方式同时插入多行数据
- 使用 UPDATE语句修改数据表中的数据
- DELETE和 TRUNCATE TABLE语句删除数据表中数据
五、数据基本查询
1、选取全部字段
- 要从一个数据库表中选取全部字段作为SELECT查询的输出字段,在SELECT子句中使用一个符号“ * ”就可以了,此时还必须用FROM字句来指定作为查询的数据源(表,视图等等)。
语法
SELECT * FROM<表名> [WHERE 条件表达式 ]
例子
SELECT * FROM clazz
2、选取部分字段
- 要从一个数据库表中选择部分字段作为SELECT查询的输出字段,可以在SELECT字句中给出包含所选取字段的一个列表,各个字段之间用逗号分隔,字段的顺序可以根据需要任意指定
语法
SELECT <列名> FROM <表名> [WHERE 条件表达式 ]
例子
SELECT id,name FROM clazz
3、设置字段别名(为查询结果的列设置别名)
- 为了方便和实际需求,可以指定更容易理解的字段名来取代原来的字段名
语法
1:原字段名 AS 字段别名>
2:字段别名=原字段名
3:原名字 新名字
例子
SELECT id as 班级序号,班级名称 =name FROM clazz
4、字段的拼接
- 如果用户需要查看“班级名称(老师名称)”这样的格式,我们可以使用“ + ”来实现
例子
SELECT name+ ‘(‘+teacher_name+’)’FROM clazz
5. ALL 关键字的使用
- 如果在SELECT 语句中没有使用任何关键字,则默认使用 ALL 关键字
例子
SELECT ALL * FROM clazz
6. DISTINCT 关键字的使用
- 在字段列表前面加上选择关键字DISTINCT,就可以消除查询结果中的重要重复
例子
SELECT DISTINCT teacher_name FROM clazz
7. TOP 关键字的使用
- 在字段列表前面加上 TOP关键字就可以查询指定条数或者百分比的数据
例子
–查询前3条的记录
SELECT TOP 3 * FROM clazz
–查询10%的记录
SELECT TOP 10 PERCENT * FROM clazz
8.对结果的筛选 WHERE 字句
- 使用条件运算符筛选记录
>, >=, =, <, <=, <>,
例子
–查询学生表中所有女生信息
SELECT *FROM student WHERE sex='女'
–查询学生表中除了 王某某 之外的所有学生信息
SELECT *FROM student WHERE name <> '王某某'
9、对范围的筛选 范围运算符
BETWEEN ... AND --在这个范围
NOT BETWEEN ... AND --不在这个范围
例子
–查询学生表中序号在10-50之间的学生信息
SELECT *FORM student WHERE id BETWEEN 10 AND 50
–查询学生表中序号不在10-50之间的学生信息
SELECT *FORM student WHERE id NOT BETWEEN 10 AND 50
10、对结果的筛选 列表运算符
- List item
- IN关键字可以选择与列表中的任意值匹配的行
例子
–查询学生表中序号是 1 3 5 6 7 12 33 35 45 48 88 的学生信息
SELECT * FROM student WHERE id IN (1,3,5,6,7,12,33,35,45,48,88)
11、对结果的筛选 逻辑运算符
- NOT
- 否定它之后所跟的任何条件
例子
–查询学生表中序号不是 1 3 5 6 7 12 33 35 45 88 的学生信息
SELECT * FROM student WHERE id NOT IN (1,3,5,6,7,12,33,35,45,48,88)
12.对结果的筛选 逻辑运算符
- AND
- 多个条件的交集
例子
–查询学生表中序号是 1 3 5 6 7 12 33 35 45 88 并且性别为女的学生信息
SELECT * FORM student
WHERE id IN (1,3,5,6,7,12,33,35,88) AND sex='女'
13.对结果的筛选 逻辑运算符
- OR
- 多个条件的并集
例子
–查询学生表中序号是 1 3 5 6 7 12 33 35 45 88 或者性别为女的学生信息表
SELECT * FORM student
WHERE id IN (1,3,5,6,7,12,33,35,88) OR sex='女'
14、对结果的筛选 空值判断符
- IS NULL
- 查询某列是空值的记录
例子
–查询学生表中学号为空的学生信息
SELECT * FORM student WHERE stu_num IS NULL
–查询班级表中教师为空的学生信息
SELECT * FORM clazz WHERE teacher_name IS NULL
- IS NOT NULL
- 查询某列不是空值的记录
–查询学生表中学号不为空的学生信息
SELECT * FORM student WHERE stu_num IS NOT NULL
–查询班级表中教师不为空的学生信息
SELECT * FORM clazz WHERE teacher_name IS NOT NULL
15、对结果的筛选 模式匹配符
- LIKE / NOT LIKE
- 模糊匹配
| 通配符 | 含义 |
|---|---|
| % | 包含零个或更多字符的任意字符串 |
| ___(下划线) | 任何单个字符 |
| [ ] | 指定范围( 列如 [a-f] )或集合( 列如 [abcdef] 或[1,3,5,7] ) 内的任何 单个字符 |
| [ ^ ] | 不在指定范围 (列如 [^a-f] )或集合 ( 列如 [^abcdef] ) 内的任何单个字符 |
- LIKE
例子
–查询学生表中学号是‘06091908’开头的学生信息
SELECT * FROM student WHERE stu_num LIKE '06091908%'
–查询学生表中学号包含‘1908’的学生信息
SELECT * FROM student WHERE stu_num LIKE '%1908%'
–查询学生表中1908 班学号是个位数的学生信息
SELECT * FROM student WHERE stu_num LIKE '060919080_'
–查询学生表中1908 班学号是个位数并且是奇数的学生信息
SELECT * FROM student WHERE stu_num LIKE '060919080 [1,3,5,7,9] '
–查询学生表中 1908 班学号是个位并且是偶数的学生信息
SELECT * FROM student WHERE stu_num LIKE '060919080 [^1,3,5,7,9] '
- NOT LIKE
–查询学生表中学号不是‘06091908’开头的学生信息
SELECT * FROM student WHERE stu_num NOT LIKE '06091908%'
–查询学生表中学号不包含‘1908’的学生信息
SELECT * FROM student WHERE stu_num NOT LIKE '%1908%'
–查询学生表中1908 班学号不是个位数的学生信息
SELECT * FROM student WHERE stu_num NOT LIKE '060919080_'
–查询学生表中1908 班学号不是个位数并且不是奇数的学生信息
SELECT * FROM student WHERE stu_num NOT LIKE '060919080 [1,3,5,7,9] '
–查询学生表中 1908 班学号不是个位并且不是偶数的学生信息
SELECT * FROM student WHERE stu_num NOT LIKE '060919080 [^1,3,5,7,9] '
16、对结果的排序
- 当用户要对查询结果进行排序时,就需要在SELECT 语句中加ORDER BY 的字句
- 排序的方法可以是升序或降序
- ASC :按照递增顺序
- DESC : 按照递减顺序
- 默认排序方向为递增顺序
- NULL 将被处理为最小值
例子
–按照序号倒序查询学生表中所有女同学
SELECT * FROM student WHERE sex = '女' ORDER BY id DESC
17、对结果的排序
- 在ORDER BY 字句中可以使用一个或多个排序要求,优先级从左到右
例子
–按照班级序号升序查询学生信息
SELECT * FROM student ORDER BY clazz_id ASC
–按照班级序号升序,名字降序查询学生信息 先满足第一个 后满足第二个
SELECT * FROM student ORDER BY clazz_id ASC ,name DESC
**18、对结果的排序 TOP **
- 用户可通过ORDER BY 字句与 TOP 搭配使用来按照排序之后查询结果中前若干行或百分比的数据
例子
–按照班级序号升序查询学生信息表前10条
SELECT TOP 10 * FROM student ORDER BY clazz_id ASC
–按照班级序号升序查询学生信息表前10%
SELECT TOP 10 PERCENT * FROM student ORDER BY clazz_id ASC
总结
- 查询的使用
- 全部字段,部分字段,设置别名,字段拼接,ALL DISTINCT TOP 关键字
- 对查询结果的筛选 WHERE 字句的使用
- 条件运算符,范围运算符,列表运算符,空值运算符,逻辑运算符,模式匹配符
- 对查询结果的排序 ORDER BY 字句的使用
- ASC(升序), DESC(降序) 排序的顺序 可以一个列,也可以多个列,优先级是从左到右
六、数据高级查询
一、常用函数的使用
1.1、对查询结果计算 SUM 函数
- SUM 函数用于统计数值型字段的总和,它只能用于数值型字段,而且NULL值将被忽略
语法
SELECT SUM (<列名>) FROM <表名> [WHERE 条件表达式]
例子
–查询 Java 考试成绩的总和
SELECT SUM ( score ) AS java 成绩总和 FROM stu_marks WHERE subject='Java'
1.2、对查询结果计算 AVG 函数
- AVG 函数用于计算一个数值型字段的平均值,该字段中的 NULL 值在计算过程中将被忽略
语法
SELECT AVG (<列名>) FROM <表名> [WHERE 条件表达式]
例子
–查询Java 考试成绩的平均分
SELECT AVG ( score ) AS java平均值 FROM stu_marks WHERE subject='Java'
1.3、对查询结果计算 MAX 函数
- MAX 函数用于返回表达式中的最大值,计算过程中遇到NULL值是予以忽略
语法
SELECT MAX (<列名>) FROM <表名> [WHERE 条件表达式]
例子
–查询Java考试成绩的最高分
SELECT MAX ( score ) AS java 最高分 FROM stu_marks WHERE subject='Java'
–查询Java考试成绩的最高分 TOP ORDER BY DESC
SELECT TOP 1 score FROM stu_marks WHERE subject='Java' ORDER BY score DESC
1.4、对查询结果计算 MIN 函数
- MAX 函数用于返回表达式中的最小值,计算过程中遇到NULL值是予以忽略
语法
SELECT MIN (<列名>) FROM <表名> [WHERE 条件表达式]
例子
–查询Java考试成绩的最低分
SELECT MIN ( score ) AS java 最低分 FROM stu_marks WHERE sub ject='Java'
–查询Java考试成绩的最低分 TOP ORDER BY ASC
SELECT TOP 1 score FROM stu_marks WHERE subject='Java' ORDER BY score ASC
1.5、对查询结果计算 COUNT 函数
- COUNT 函数用于统计查询中指定列的查询记录数
- -每个部门 男女 每个人 要用分组
语法
SELECT COUNT (<列名>) FROM <表名> [WHERE 条件表达式]
例子
–查询参加Java考试的学生数
SELECT COUNT ( * ) AS 参加Java考试的学生数 FROM stu_marks WHERE sub ject='Java'
–查询参加Java的学生数
SELECT * FROM stu_marks WHERE sub ject='Java'
2、在查询中对查询结果的分组
- GROUP BY 字句指定将结果集内的记录分为若干组来输入,每个组中记录在指定的字段中具有相同值
- 在一个查询语句中,可以使用任意多个字段对结果集内的记录进行分组,字段列表中的每个输出字段必须在 GROUP BY 字句中出现或者用在某个聚合函数中
- 使用GROUP BY 字句时,如果在 SELECT 字句中的字段列表中包含有聚合函数,则针对每个组计算出一个汇总值从而实现对查询结果的分组统计
–group by 里面如果还有条件的话 having
2.1、对查询结果的分组 GROUP BY子句
- GROUP BY 对结果进行分组统计
例子
–分别统计每个科目的平均分
SELECT subject AS 科目,AVG ( score ) AS 平均分 FROM stu_marks GROUP BY subject
–分别统计每个科目的平均分和总分
SELECT subject AS 科目,AVG ( score ) AS 平均分,SUM(score ) AS 总成绩 FROM stu_marks GROUP BY subject
- HAVING 字句用于在使用 GROUP BY 字句分组后的条件筛选
例子
–统计平均分大于61分的科目
SELECT subject AS 科目,AVG (score) AS 平均分
FROM stu_marks GROUP BY subject HAVING AVG (score)>61
注意: HAVING 可以当做WHERE 条件去看
总结
在查询中对查询结果的计算 聚合函数
- SUM函数计算字段的累计和
- AVG函数计算字段的平均值
- MAX函数计算字段的最大值
- MIN函数计算字段的最小值
- COUNT 函数统计记录行数
在查询中对查询结果的分组
- GROUP BY 字句的使用
- HAVING 字句的使用
七、连接查询
1、连接查询
什么是连接查询
- 根据两个表或者多个表的列之间的关系,从这些表中查询数据
- 实现多个表查询操作
什么时候用连接查询
- 一般用在两张及以上表的数据关联查询
都有哪些连接类型
- 内连接
- 外连接
- 交叉连接

2、内部链接查询 - 需求:查询有成绩的学生信息及其成绩信息
例子
–1.先查询出有成绩的学生序号
SELECT student_id FROM selection
–2.根据查询出的学生序号查询出学生信息
SELECT * FROM student WHERE IN (...)
–3.根据第一步查询的学生序号查询出成绩信息
SELECT * FROM selection WHERE student_id IN (...)
–4.第二步和第三步结果怎么让它显示一起?
- 内部连接查询是连接查询中最普通的一种
- 内部连接查询仅仅返回那些指定字段匹配的记录
语法
SELECR <列名> FROM <表名1>
INNER JON <表名2> ON 条件表达式
例子
–查询所有成绩的学生信息及其成绩信息
SELECT * FROM student
INNER JOIN selection ON student.id=selection.student_id
–简化査询有成绩的学生姓名、性别、年龄、学号、成绩
SELECT name, sex, age, stu_num, score FROM student
INNER JOIN selection
ON student.id = selection.student_id
–简化査询有成绩的学生序号、学生姓名、性别、年龄、学号、成绩
SELECT student.id, name, sex, age, stu_num, score FROM student
INNER JOIN selection
ON student.id = selection.student_id
3、带条件的内部连接查询
- 带条件的内部连接查询是将查询结果再次筛选
语法
SELECT <列名> FROM <表名1> INNER JON <表名2>
ON 条件表达式1 WHERE 条件表达式2
例子
–查询成绩大于等于60分的学生信息及成绩
SELECT * FROM student
INNER JOIN selection ON student.id =selection.student_id
WHERE selection.score>=60
- 带条件的内部连接查询可以使用 WHERE 字句达到同样的效果
例子
–查询成绩大于等于60分的学生信息及成绩
SELECT * FROM student , selection
WHERE student.id=selection.student_id
AND selection.score>=60
4、更复杂的内部连接查询
使用JOIN运算时,应当注意以下两点:
- 在JOIN运算中,连接两个表的指定字段必须具有相同的数据类型并且包含相同类型的数据,但字段名称不必相同。
- 如果两个连接表中包含名称相同的字段,在选取这些字段时就应当冠以表名,否则会出现错误提示信息:列名“ ****** ”不明确。
- 更复杂的内部连接查询可以查询多个表的数据
语法
SELECT <列名> FROM <表名1>INNER JOIN <表名2>
ON 条件表达式1 INNER JOIN <表名3>ON 条件表达式2...
例子
–查询学生信息,学生所在班级信息及成绩
SELECT * FROM student
INNER JOIN selection ON student.id=selection.student_id
INNER JOIN clazz ON student.clazz_id=clazz.id
–查询有成绩的学生序号、姓名、性别、班级名称、老师名称及成绩
SELECT
student.id AS 学生序号,
student.name AS 学生姓名,
sex AS 学生性别,
class.name AS 班级名称,
teachar_name AS老师名称,
score AS分数
FROM studentINNER JOIN selection
ON student.id=selection.student_id
INNER JOIN clazz ON student.clazz_id=clazz.id
–查询学生信息,学生所在班级信息及其成绩信息、科目信息
SELECT * FROM student
INNER JOIN selection ON student.id=selection.student_id
INNER JOIN clazz ON student.clazz_id=clazz.id
INNER JOIN course ON course.id=selection.course_id
–查询有成绩的学生序号、姓名、性别、班级名称、老师名称及成绩、科目
SELECT
student.id AS 学生序号,
student.name AS 学生姓名,
sex AS 学生性别,
class.name AS 班级名称,
teachar_name AS老师名称,
score AS分数,
course .name AS 科目
FROM student
INNER JOIN selection ON student.id=selection.student_id
INNER JOIN clazz ON student.clazz_id=clazz.id
INNER JOIN course ON course.id=selection.course_id
5、外部链接查询
外连接分为
- 左外连接 (LEFT JOIN / LEFT OUTER JOIN)
- 右外连接 (RIGHT JOIN / RIGHT OUTER JOIN)
- 全外连接 (FULL JOIN / FULL OUTER JOIN)
5.1、外部连接查询左连接(LEFT JOIN)
特点
- 返回左表的所有行,如果左表中行在右表中没有匹配行,否结果中右表中的列返回空值
- 里面有 NULL 以左表为主
例子
–查询所有学生信息及其班级,如果没有班级则输出NULL
SELECT * FROM student
LEFT JOIN clazz ON student.clazz_id=clazz.id
5.2、右外连接也叫右连接 (RIGHT JOIN )
- 恰与左连接相反,返回右表中的所有行,如果右表中在左表中没有匹配行,则结果中左表中的列返回空值
例子
–查询所有班级信息及其对应的学生信息,如果没有学生信息则输入NULL
SELECT * FROM student
RIGHT JOIN clazz ON student.clazz_id=clazz.id
5.3、全外连接也叫全连接 (FULL JOIN )
- 返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值
例子
–查询所有学生信息及所有班级信息,没有的以 NOLL 补充
SELECT * FROM student
FULL JOIN clazz ON student.clazz_id=clazz.id
5.4、交叉连接也叫笛卡尔积
- 不带WHERE条件字句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积,如果带WHERE,返回或显示的是匹配的行数
例子
–查询两个表的交叉连接 (笛卡尔积)
SELECT * FROM student CROSS JOIN selection
SELECT * FROM student CROSS JOIN selection WHERE student.id=2
6、集合运算
集合运算
- 并集运算–UNION / UNION ALL
- 两个集合的并集是一个包含集合A和集合B中共同元素的结合
- 交集运算–INTERSECT
- 两个集合的交集是由既属于集合A和集合B的所有元素组成的集合
- 减集运算–EXCEPT
- 两个集合的差集(A–B)是由属于A,但不属于B的元素组成的集合(顺序很重要)

6.1集合运算 并集
- 两个集合的差集(A–B)是由属于A,但不属于B的元素组成的集合(顺序很重要)
6.1.1、UNION
- 两个集合的并集是一个包含集合A和集合B中共同元素的集合
- 去除重复
例子
–查询分数大于70和学生序号为5的选课记录
**SELECT * FROM selection WHERE score > 70
UNION
SELECT * FROM selection WHERE student_id=5**
6.1.2、UNION ALL
- 两个集合的并集是一个包含集合A和集合B中共同元素的集合
- 不去除重复
例子
–查询分数大于70和学生序号为5的选课记录
SELECT * FROM selection WHERE score > 70
UNION ALL
SELECT * FROM selection WHERE student_id=5
6.2、集合运算 交集
6.2.1、INTERSECT
- 两个集合的交集是由既属于集合A 和集合B的所有元素组成的集合
例子
–查询分数大于70和学生序号为5的选课记录
SELECT * FROM selection WHERE score > 70
INTERSECT
SELECT * FROM selection WHERE student_id=5
6.3、集合运算 减集
6.3.1、EXCEPT
- 两个集合的差集(A-B)是由属于A, 但不属于B的元素组成的集合(顺序很重要)
例子
–求出分数大于70的记录和学生序号为5的记录的减集
SELECT * FROM selection WHERE score > 70
EXCEPT
SELECT * FROM selection WHERE student_id=5
总结
- 连接查询
- 内连接
- 外连接
- 左外连接 (LEFT JOIN / LEFT OUTER JOIN)
- 右外连接 (RIGHT JOIN / RIGHT OUTER JOIN)
- 全外连接 (FULL JOIN / FULL OUTER JOIN)
- 交叉连接
- 集合运算
- 并集运算–UNION / UNION ALL
- 交集运算–INTERSECT
- 减集运算—EXCEPT
八、查询的实际应用
查询语句的实际应用
- 通过新建三张表并且添加相关的数据然后根据需求使用查询语句完成所需要的结果
- 1.客户表
- 2.商品表
- 3.购物清单表
1、图片分析
1.1、首先创建一个数据库

1.2、表
-
客户表
-
商品表
-
购物明细表

1.3、表的数据 -
客户表数据
-
商品表数据

-
购物明细数据

-
购物明细表数据

2、新建数据库
2.1、建立supermarket数据库
CREATE DATABASE supermarket --创建数据库。新建supermarket 数据库
ON PRIMARY --默认就属于PRIMARY主文件组,可省略
(
--数据文件的具体描述--
NAME='supermarket_data', --主数据文件的逻辑名
FILENAME='D:\DATA\supermarket_data.mdf', ---主数据文件的物理名 包含了所处的路径
SIZE=5MB, ---主数据文件的初始大小 最小5M
MAXSIZE=50MB, ---主数据文件增长的最大值
FILEGROWTH=10% ---主数据文件的增长率
---2种方式 一种百分比 一种是我们的文件大小或字节数
)
LOG ON
(
--日志文件的具体描述,各参数含义同上---
NAME ='supermarket_log',
FILENAME='D:\DATA\supermarket_log.ldf',
SIZE=5MB,
FILEGROWTH=1MB
)
GO
3、建表
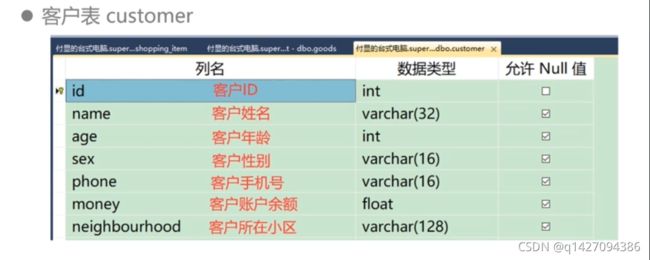
3.1、客户表
–新建客户customer表
--回到supermarket库中
use supermarket
--新建客户customer表
CREATE TABLE customer
(
id int PRIMARY KEY IDENTITY(1,1), --主键 自增 客户ID
name varchar(32), --客户姓名
age int, --客户年龄
sex varchar(16), --客户性别
phone varchar (16), --客户手机号
money float, --客户余额
neighbourhood varchar(128) --小区
)
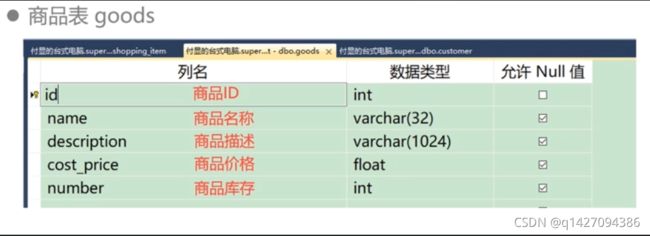
3.2、商品表
–新建商品表 goods表
--新建商品表 goods表
CREATE TABLE goods
(
id int PRIMARY KEY IDENTITY(1,1), --主键 自增 商品ID
name varchar(32), --商品名称
description varchar(1024), --商品描述
cost_price float, --成本价
number int --商品库存数量
)
go
3.3、购物明细表
–新建购物明细表shopping_item表
--新建购物明细表shopping_item表
CREATE TABLE shopping_item
(
id int PRIMARY KEY IDENTITY(1,1), --主键 自增
customer_id int NOT NULL REFERENCES customer(id), --客户ID
goods_id int NOT NULL REFERENCES goods(id), --商品ID
number int, --购买商品数量
sale_price float, --销售价格
sale_time datetime --销售时间
)
go
4、添加数据
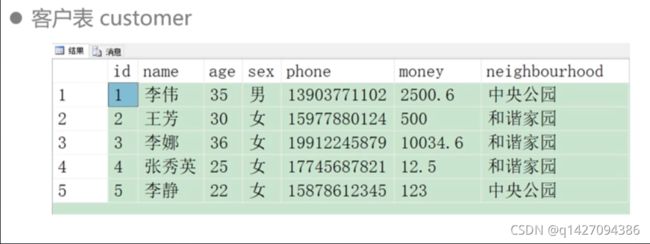
–新增客户信息
--新增客户信息
INSERT INTO customer VALUES('李伟',35,'男','13903771102',2500.6,'中央公园')
INSERT INTO customer VALUES('王芳',30,'女','15977880124',500,'和谐家园')
INSERT INTO customer VALUES('李娜',36,'女','19912245879',10034.6,'和谐家园')
INSERT INTO customer VALUES('张秀英',25,'女','17745687821',12.5,'和谐家园')
INSERT INTO customer VALUES('李静',22,'女','15878612345',123,'中央公园')
SELECT * FROM customer
–新增商品信息
--新增商品信息
INSERT INTO goods VALUES('金龙鱼食用油','这是金龙鱼食用油,使用非转基因作物加工而成,请放心食用!',42.9,200)
INSERT INTO goods VALUES('金龙鱼大米','这是金龙鱼东北大米,蟹稻共生,盘锦大米5KG',31.9,180)
INSERT INTO goods VALUES('五得利面粉','五得利,金富强高筋小麦粉,烘焙饺子粉慢头烙饼面粉多用途家庭粉5kg',24.9,200)
INSERT INTO goods VALUES('想念面条','想念面条,精制家用挂面 1.5kg,独立小包装15袋,方便取食,拉面,细挂面',19.9,1000)
INSERT INTO goods VALUES('牧原猪肉','牧原精品冷冻猪肉,精品五花肉 1kg,还送10个口罩',65,1000)
SELECT * FROM goods
–新增购物明细信息
--新增购物明细信息
--李伟 购买了 1 3 4 商品
INSERT INTO shopping_item VALUES(1,1,2,42.9,'2020-02-09 10:20:32')
INSERT INTO shopping_item VALUES(1,3,1,24.9,'2020-02-09 10:20:32')
INSERT INTO shopping_item VALUES(1,4,5,19.9,'2020-02-09 10:20:32')
--王芳 购买了 2 3 商品
INSERT INTO shopping_item VALUES(2,2,3,31.9,'2020-02-11 18:23:10')
INSERT INTO shopping_item VALUES(2,3,4,24.9,'2020-02-11 18:23:10')
--李娜 购买了 2 4 商品
INSERT INTO shopping_item VALUES(3,2,2,31.9,'2020-02-10 19:13:10')
INSERT INTO shopping_item VALUES(3,4,1,19.9,'2020-02-10 19:13:10')
--张秀英 购买了 5 商品
INSERT INTO shopping_item VALUES(4,5,5,65,'2020-02-11 16:20:22')
--李静 购买了 4 5 商品
INSERT INTO shopping_item VALUES(5,4,6,55,'2020-02-15 10:20:02')
INSERT INTO shopping_item VALUES(5,5,1,65,'2020-02-15 10:20:02')
SELECT * FROM shopping_item
5、查询的应用
–1:查询所有客户信息
–2:查询所有商品信息
–3:查询所有购物记录信息
–4:査询价格在15-50之间的客户id、商品id及价格
–5:查询商品id为4的最高销售价格
–6:查询用户都选购了哪些商品,并列出商品id
–7:查询选购了id为3的商品的平均价格、最高价格、最低价格
–8:统计每个小区的客户数量
–9:统计每个商品的选购人数及最高价格
–10:统计每个客户购买的商品数量并按照商品数量递増顺序显示结果
–11:统计购物的客户总数和所有商品的平均价格
–12:统计购物超过2种商品的客户购物平均价格和购买商品种类数
–13:查询出购物超过100元的顾客d、总价格
–14:査询选购了商品id为2的客户姓名及所在小区
–15:查询采购的商品销售价格大于50的顾客姓名、商品id,并按照商品销售价格降序排列
–16:査询"中央公园"小区客户购买"金龙鱼食用油"的客户姓名性别
–17:查询哪些客户购买过商品将这些客户信息保存在一张新表中( customer new)
–18:分别查询"中央公园"和"和谐家园"的客户姓名、性别、选购商品名称、商品销售价格
–要求:
1:并要求将两个查询结果合并成一个结果集 –
2:以小区名称、姓名、性别、选购商品名称、商品价格显示各列
--1:查询所有客户信息
SELECT * FROM customer
--2:查询所有商品信息
SELECT * FROM goods
--3:查询所有购物记录信息
SELECT * FROM shopping_item
--4:査询价格在15-50之间的客户id、商品id及价格
SELECT customer_id 客户id ,goods_id 商品id ,sale_price 价格
FROM shopping_item WHERE sale_price BETWEEN 10 AND 50
--5:查询商品id为4的最高销售价格
SELECT top 1 sale_price as 销售最高价格 FROM shopping_item
where goods_id =4 order by sale_price desc
--6:查询用户都选购了哪些商品,并列出商品id
SELECT DISTINCT goods_id as 商品ID FROM shopping_item
--7:查询选购了id为3的商品的平均价格、最高价格、最低价格
select AVG (sale_price ) as 平均价格, MAX (sale_price ) as 最高价格, MIN (sale_price ) as 最低价格 from shopping_item
where goods_id =3
--8:统计每个小区的客户数量
select neighbourhood as 小区名称, count(*) as 客户数量 from customer
group by neighbourhood
--9:统计每个商品的选购人数及最高价格
select goods_id as 商品ID, count (customer_id ) as 商品购买人数, max (sale_price ) as 商品最高价格
from shopping_item group by goods_id
--10:统计每个客户购买的商品数量并按照商品数量递増顺序显示结果
select customer_id as 客户ID , SUM (number ) AS 商品数量 from shopping_item
group by customer_id
order by SUM (number ) asc
--11:统计购物的客户总数和所有商品的平均价格
select COUNT (distinct customer_id ) as 客户总数,
sum(sale_price *number )/sum(number ) as 所有商品的平均价格
from shopping_item
--12:统计购物超过2种商品的客户购物平均价格和购买商品种类数
select customer_id as 顾客ID , sum(sale_price *number )/sum(number ) as 平均价格,count (distinct goods_id ) as 商品种类数
from shopping_item
group by customer_id
having COUNT (distinct goods_id ) >2
--13:查询出购物超过100元的顾客d、总价格
select customer_id as 顾客ID , sum(sale_price *number ) as 总价
from shopping_item
group by customer_id
having sum(sale_price *number ) >100
--14:査询选购了商品id为2的客户姓名及所在小区
select customer .name as 姓名, customer .neighbourhood as 所在小区 from shopping_item
inner join customer on shopping_item .customer_id =customer.id
where shopping_item .goods_id =2
--15:查询采购的商品销售价格大于50的顾客姓名、商品id,并按照商品销售价格降序排列
select customer .name as 客户姓名, shopping_item .goods_id as 商品ID from shopping_item
inner join customer on shopping_item .customer_id =customer .id
where sale_price >50
order by sale_price desc
--16:査询"中央公园"小区客户购买"金龙鱼食用油"的客户姓名性别以及手机号
select customer .name as 客户姓名, customer .sex as 客户性别 , customer .phone as 手机号 from shopping_item
inner join goods on shopping_item.goods_id =goods.id
inner join customer on shopping_item .customer_id =customer .id
where customer .neighbourhood ='中央公园' and goods .name='金龙鱼食用油'
--17:查询哪些客户购买过商品,将这些客户信息保存在一张新表中( customer_new)
select distinct customer .*
into customer_new
from shopping_item
inner join customer on shopping_item .customer_id =customer .id
--18:分别查询"中央公园"和"和谐家园"的客户姓名、性别、选购商品名称、商品销售价格
--要求:1:并要求将两个查询结果合并成一个结果集
-- 2:以小区名称、姓名、性别、选购商品名称、商品价格显示各列
select customer .neighbourhood as 小区名称 , customer .name as 姓名,
customer .sex as 性别, goods .name as 商品名称, shopping_item .sale_price as 商品销售价格
from shopping_item
inner join customer on shopping_item .customer_id =customer .id
inner join goods on shopping_item .goods_id =goods .id
where customer .neighbourhood ='中央公园' or customer .neighbourhood ='和谐家园'
--第二种解决方案
select customer .neighbourhood as 小区名称 , customer .name as 姓名,
customer .sex as 性别, goods .name as 商品名称, shopping_item .sale_price as 商品销售价格
from shopping_item
inner join customer on shopping_item .customer_id =customer .id
inner join goods on shopping_item .goods_id =goods .id
where customer .neighbourhood ='中央公园'
union
select customer .neighbourhood as 小区名称 , customer .name as 姓名,
customer .sex as 性别, goods .name as 商品名称, shopping_item .sale_price as 商品销售价格
from shopping_item
inner join customer on shopping_item .customer_id =customer .id
inner join goods on shopping_item .goods_id =goods .id
where customer .neighbourhood ='和谐家园'