数分面试题-SQL常见面试题型1
目录标题
-
-
- 1、连续时间问题
-
- 1.1 最近一周内的活跃天数
- 1.2 每个用户一周内最大连续活跃天数
- 1.3 计算截至当前,每个用户已经连续签到的天数
- 2、时间间隔问题举例
- 3、sql窗口分析函数
-
- 3.1 有一个日志登陆列表,获取用户在某个页面停留时长
- 3.2 寻找至少连续出现3次的数字
- 4、什么是关系型“数据表”“数据库”
- 5、行/列转换
-
- 5.1 行转列,表1转表2--PIVOT
- 5.2 列转行,表2转表1
- 5.3 一行转多行
-
1、连续时间问题

1.1 最近一周内的活跃天数
最近一周:timestampdiff(day,time,now())<=7
group by 可以起到去重的作用
select user_id,count(1)
from
(select user_id,date from t where timestampdiff(day,time,now())<=7
group by user_id,date)
group by user_id
1.2 每个用户一周内最大连续活跃天数
思路:排序-减去-- 计数
date_sub(日期,天数)
select user_id,max(count(diff))
from
(select date ,user_id,date_sub(date,rank) as diff
from
(select date ,user_id ,row_number()over(partition by user_id order by date) as rk
from
(select date ,user_id from t group by date ,user_id)
)
)
group by user_id
时间差函数:
1,timestampdiff(second/minute/hour/day,开始日期,结束日期)
2,date_sub(日期,天数) 日期减去天数

1.3 计算截至当前,每个用户已经连续签到的天数
每一个日期都有
思路:选出最新没签到的日子,用当前时间减去该日子得到已经连续签到的次数
select user_id,timestampdiff(Day,el,now()) as contdays
from
(select user_id,max(date) el from user_attendence where is_sign_in =0 group by user_id)
2、时间间隔问题举例
1、为日期排序
· -row number() partition by 用户编号 order by 操作时间 as 日期排序
2、错位相减,求日期和排序的差值(diff)
· 用错位相减求来实现“相邻”要求
from a left join b on (a.日期排序 = b.日期排序-1)
3、sql窗口分析函数
lag:用于统计窗口内往上第n行值
lead:用于统计窗口内往下第n行值
lag 和 lead 有三个参数,第一个参数是列名,第二个参数是偏移的 offset,第三个参数是超出记录窗口时的默认值。
lag(列名,1,0) over (partition by 分组列 order by 排序列 rows between
开始位置 preceding and 结束位置 following)
3.1 有一个日志登陆列表,获取用户在某个页面停留时长
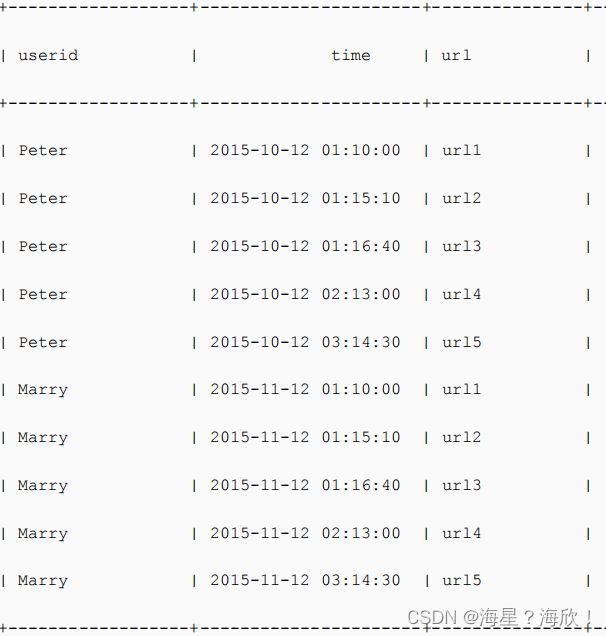
代码:
select userid,time,
unix_timestamp(lead(time,1) over(partition by userid order by time),'yyyy-MM-dd HH:mm:ss')- unix_timestamp(time,'yyyy-MM-dd HH:mm:ss') as period
,url
from user_log
3.2 寻找至少连续出现3次的数字

思路:增加两列,使用 lag 函数-把下面的数据往上错位一个,错位 2 个,判断 num 和错位的两列是否相等
select id,distinct num
from
(select id,num,
lag(num,1)over(partition by id) as lag1,
lag(num,2)over(partition by id) as lag2
from log_table
) a
where num = lag1 and lag1 = lag2
4、什么是关系型“数据表”“数据库”
数据分成结构化数据、非结构化数据,数据库又常分成关系型数据库和非关系型数据库
结构化数据:可以用excel存储的,一行行一列列数据
非结构化数据:图片、文字、语音这种没办法用 excel 存储的,一行行一列列的数据
关系型数据库:需要预先设计好存储的strcture
非关系型数据库:可以预先设计好structure进行结构化存储,也可以在数据不满足structure的情况下先行存储数据,待后来再进行格式化打标签
结构化查询语言SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统
5、行/列转换
4款产品,三个电商平台,分别以两种形式记录了某个月各产品在各个平台的销售数量
表1:

表2:

5.1 行转列,表1转表2–PIVOT
在 SQL SERVER 中,提供了专门进行行列转换的函数:PIVOT
pivot的语法:
from table_source
pivot(
聚合函数(value_column) - value_column 要转换为列值的列名
for pivot_column - pibot_column指定要转换的列
in(column_list) ----column_list自定义的目标列名
)
SELECT Product,
MAX(CASE WHEN Platform = ‘ 天猫 ’ THEN quantity ELSE 0
END) AS “ 天猫 ”,
MAX(CASE WHEN Platform = ‘ 淘宝 ’ THEN quantity ELSE 0
END) AS “ 淘宝 ”,
MAX(CASE WHEN Platform = ‘ 京东 ’ THEN quantity ELSE 0
END) AS “ 京东 ”
FROM TABLE
GROUP BY
Produc
5.2 列转行,表2转表1
方法一:UNPIVOT
UNPIVOT 的一般语法是:

FROM table_source – 表名称,即数据源
UNPIVOT(
value_column – value_column 要转换为 行值 的列名
FOR pivot_column – pivot_column 指定要转换为指定的列
IN(column_list ) – column_list 目标列名
)
SELECT *
FROM TABLE UNPIVOT (quantity FOR Platform IN (“ 天猫 ”, “ 淘
宝 ”, “ 京东 ”))
方法二:聚合函数+UNION
同理,Oracle,MySQL 也是不支持 UNPIVOT 函数的,对于这种情况我们可以通过聚合函数+UNION 的方式将数据组合起来。
5.3 一行转多行

一行转多行:
SELECT DISTINCT Product,Supplier
FROM table
LATERAL VIEW explode (split(Supplier,’,’)) as t – t 为新表别名
多行转一行:
可以使用:collect_set +concat_ws 来实现
SELECT Product,
concat_ws(’, ’, COLLECT_SET(Supplier)) Product_Supplier
FROM TABLE
GROUP BY Product