dp算法 力扣978、力扣139、力扣467
目录
一、力扣978978. 最长湍流子数组 - 力扣(LeetCode)
(一)题目详情
(二)算法讲解
(三)代码
二、力扣139139. 单词拆分 - 力扣(LeetCode)
(一)题目详情
(二)算法讲解
(三)代码
三、力扣467467. 环绕字符串中唯一的子字符串 - 力扣(LeetCode)
(一)题目详情
(二)算法讲解
(三)代码
结语
一、力扣978978. 最长湍流子数组 - 力扣(LeetCode)
(一)题目详情
给定一个整数数组 arr ,返回 arr 的 最大湍流子数组的长度 。
如果比较符号在子数组中的每个相邻元素对之间翻转,则该子数组是 湍流子数组 。
更正式地来说,当 arr 的子数组 A[i], A[i+1], ..., A[j] 满足仅满足下列条件时,我们称其为湍流子数组:
若 i <= k < j :
当 k 为奇数时, A[k] > A[k+1],且
当 k 为偶数时,A[k] < A[k+1];
或 若 i <= k < j :
当 k 为偶数时,A[k] > A[k+1] ,且
当 k 为奇数时, A[k] < A[k+1]。
示例 1:
输入:arr = [9,4,2,10,7,8,8,1,9]
输出:5
解释:arr[1] > arr[2] < arr[3] > arr[4] < arr[5]
示例 2:
输入:arr = [4,8,12,16]
输出:2
示例 3:
输入:arr = [100]
输出:1
提示:
1 <= arr.length <= 4 * 104
0 <= arr[i] <= 109
(二)算法讲解
对于i位置的数字,和前一个数字具有三种比较结果:
arr[i-1] > arr[i] 、arr[i-1] < arr[i] 、arr[i-1] = arr[i].
而符合我们要求的则是当前位置比较结果和上一个位置比较结果相反(不包括等于),故创建dp表时,需要创建两个表,分别存储当前位置和前一个位置的比较偏大结果和偏小结果,即:
f[i] 表示i位置结尾时,arr[i] > arr[i-1] 的最大湍流子数组的长度;
g[i] 表示i位置结尾时,arr[i] < arr[i-1] 的最大湍流子数组的长度
可推导出状态转移方程如下:

对于初始化,由状态转移方程可以得知,无论arr[i]和arr[i-1]的大小比较如何,都有一个加1的操作,故初始化时,每个数都加上1。
对于边界处理,使用虚拟空间,使dp表多出一格,处理i-1的问题。
返回结果则是取f表和g表中的最大值 。
(三)代码
class Solution {
public int maxTurbulenceSize(int[] arr) {
//创建dp表
int n = arr.length;
int[] f = new int[n+1];
int[] g = new int[n+1];
int max = 1;
//初始化
for(int i=0;i<=n;i++){
f[i] = 1;
g[i] = 1;
}
//填表
for(int i=2;i<=n;i++){
if(arr[i-1]>arr[i-2]){
f[i] += g[i-1];
}else if(arr[i-1]运行截图:
二、力扣139139. 单词拆分 - 力扣(LeetCode)
(一)题目详情
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
提示:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s 和 wordDict[i] 仅有小写英文字母组成
wordDict 中的所有字符串 互不相同
(二)算法讲解
首先确定dp[i]代表的含义,由题意可以得知,dp[i]代表以i结尾的字符串,是否可以由字典中出现的单词拼接出来。
假设存在一个位置j,j 位置 到 i 位置是下一个单词位置,并且j 位置前面的字符串已经可以由字典中出现的单词拼接。
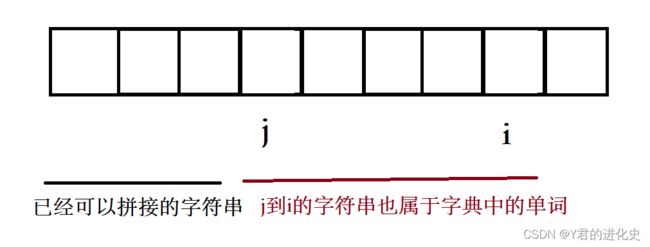

创建dp表,boolean[] dp 存储以当前位置结尾的字符串是否满足题意。
处理越界问题(j-1),我们使用虚拟空间dp表前面加一个格子,为了不影响后面的结果,需要设置dp[0] = true;
为了提高单词比较速度,我们使用哈希表将提供的单词存储起来。
返回结果则是dp表中最后一个格子的存储值。
(三)代码
class Solution {
public boolean wordBreak(String s, List wordDict) {
//1.
int n = s.length();
boolean[] dp = new boolean[n+1];
Set word = new HashSet<>();
for(String x:wordDict){
word.add(x);
}
//2.
dp[0] = true;
//3.
for(int i=1;i<=n;i++){
for(int j=i;j>=1;j--){
//如果存在
if(word.contains(s.substring(j-1,i+1-1)) && dp[j-1]){
dp[i] = true;
break;
}
}
}
//4.
return dp[n];
}
} 运行截图:
三、力扣467467. 环绕字符串中唯一的子字符串 - 力扣(LeetCode)
(一)题目详情
定义字符串 base 为一个 "abcdefghijklmnopqrstuvwxyz" 无限环绕的字符串,所以 base 看起来是这样的:
"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd....".
给你一个字符串 s ,请你统计并返回 s 中有多少 不同非空子串 也在 base 中出现。
示例 1:
输入:s = "a"
输出:1
解释:字符串 s 的子字符串 "a" 在 base 中出现。
示例 2:
输入:s = "cac"
输出:2
解释:字符串 s 有两个子字符串 ("a", "c") 在 base 中出现。
示例 3:
输入:s = "zab"
输出:6
解释:字符串 s 有六个子字符串 ("z", "a", "b", "za", "ab", and "zab") 在 base 中出现。
提示:
1 <= s.length <= 105
s 由小写英文字母组成
(二)算法讲解
分析题意可以得知:
- 给出的无限环绕的字符串,就是26个小写字母的一个无限循环,并且给出的字符串也是小写字母。
- 字符串结果是需要去重的。
先忽略条件2,考虑条件1.
首先把字符串s转换为字符数组ss,可以为计算结果节约大量的时间。
其次,创建dp表,dp[i] 表示以i位置为结尾的字符串有dp[i]个字符串满足题意。
故状态转移方程推导为:

考虑越界问题(i-1),使用将 dp[0]=1;
考虑条件2之后,字符串结果去重。
对于相同字符的不同长度字符串满足题意结果,始终是相对较长的字符串包含较小的字符串内容的,如以字符'c'结尾的两个实例:
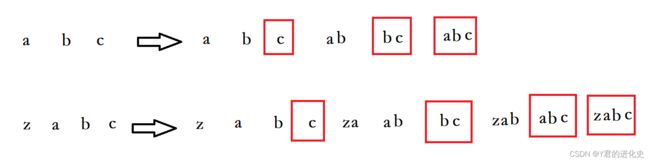 也就是说,当字符串中出现相同字符时,取长度较长的字符串并且以该字符结尾的,为该字符满足题意的最终结果。
也就是说,当字符串中出现相同字符时,取长度较长的字符串并且以该字符结尾的,为该字符满足题意的最终结果。
使用哈希表的原理,将每一个字符产生的结果存储起来。
返回结果是,哈希表的所有值的总和。
(三)代码
class Solution {
public int findSubstringInWraproundString(String s) {
//创建dp表
char[] ss = s.toCharArray();
int n = ss.length;
int[] dp = new int[n];
int sum = 0;
//初始化
dp[0] = 1;
//填表
//这里的循环对应的是dp的下标
for(int i=1;i运行截图:
结语
这篇博客如果对你有帮助,给博主一个免费的点赞以示鼓励,欢迎各位点赞评论收藏⭐,谢谢!!!