【第一章 走进数据科学】袁博《数据挖掘:理论与算法》
目录
1 整装待发
1、数据挖掘的前提和基础:Technology Advancement
2、DRIP:Data Rich,Information Poor
2 学而不思则罔
1、学习资源
2、数据挖掘(Data Mining)是一个多学科交叉领域
3、数据挖掘(Data Mining)无所不在
3 知行合一
1、Data(数据)
2、Big Data(大数据)
3、实际应用
4 从数据到知识
1、Open Data(开放数据)
2、Data Mining(DM,数据挖掘)
3、从数据(Data)到智能(Intelligence)
4、流程
5、业界应用(商用数据分析软件)
5 分类问题(Classification)
1、什么是分类问题?
2、Classification Boundaries(分界面)
3、Overfitting(过学习)
4、Cross Validation(交叉验证)
5、Confusion Matrix(混淆矩阵)
6、Receiver Operating Characteristic(ROC曲线)
7、Cost Sensitive Learning(代价敏感分类问题)
8、Lift Analysis(评价模型实际使用中的效能)
6 聚类及其他数据挖掘问题
1、聚类(Clustering)
2、关联规则(Association Rule)
3、回归(Regression)
4、Seeing is Knowing(所见即所得)
5、Data Preprocessing(数据预处理)
7 隐私保护与并行计算
1、隐私保护(Privacy Protection)
2、云计算(Cloud Computing)
3、并行计算(Parallel Computing)
4、宏观上,数据挖掘该怎么做?
5、No Free Lunch(没有免费的午餐)
8 迷雾重重
1、Case Study
2、相关
3、Survivorship Bias(幸存者偏差)
4、解决实际问题时不能单向思维
9 单元补充
1 整装待发
1、数据挖掘的前提和基础:Technology Advancement
-
Data Storage 存储数据的能力
-
Computation capacity 处理加工数据的能力
2、DRIP:Data Rich,Information Poor
现实生活中普遍存在的“数据充沛而信息不足”的问题,原因在于对原始数据没有进行必要的处理和分析,没有发挥出其应有的价值。
2 学而不思则罔
1、学习资源
(1)经典教材:

(2) 国际会议:
- ICDM:International Conference on Data Mining
Welcome to ICDM: IEEE International Conference on Data Mining!
IEEE International Conference on Data Mining 2021 (ICDM2021) | IEEE ICDM 2021
https://ieeexplore.ieee.org/xpl/conhome/1000179/all-proceedings
- ICDE:International Conference on Data Engineering
ICDE 2022 – 38th IEEE International Conference on Data Engineering
https://ieeexplore.ieee.org/xpl/conhome/1000178/all-proceedings
- ICML:International Conference on Machine Learning
2022 Conference
- IJCAI:International Joint Conference on Artificial Intelligence
Welcome to IJCAI | IJCAI
- PAKDD:Pacific-Asia Conference on Knowledge Discovery and Data Mining
Home - Pacific Asia Conference on Knowledge Discovery and Data Mining
PAKDD 2022
Pacific-Asia Conference on Knowledge Discovery and Data Mining | SpringerLink
- SIGKDD:ACM SIGKDD Conference on Knowledge Discovery and Data Mining
SIGKDD
SIGKDD - Home
http://dbgroup.cs.tsinghua.edu.cn/wangjy/KDD4CCF.pdf
(3)期刊:
- IEEE Transactions on Neural Networks and Learning Systems
- IEEE Transactions on Knowledge and Data Engineering(TKDE)
(4)协会:
 (左)计算智能协会;(右)计算机协会
(左)计算智能协会;(右)计算机协会
(5)知名学者:

- 吴信东:ICDM创始人之一
吴信东 - 搜狗百科
吴信东 - 搜狗学术
- 周志华:南大教授
周志华 - 搜狗百科
- 韩家炜:Data Mining: Concepts and Techniques (数据挖掘:概念与技术)
——数据挖掘界公认的经典教材作者之一
韩家炜 - 搜狗百科
- 裴健:TKDE主编
裴健 - 搜狗百科
- 杨强:华为诺亚方舟实验室的创始主任,香港科技大学教授
杨强 - 搜狗百科
- Chih-Jen Lin:LibSVM软件
LIBSVM -- A Library for Support Vector Machines
支持向量机SVM工具包LIBSVM的安装和测试 - 知乎
- Philip S.Yu:清华大学数据研究院 院长
Professor Philip S. Yu's Homepage
https://scholar.google.com/citations?user=D0lL1r0AAAAJ&hl=zh-CN
- 张长水:清华大学自动化系 教授
张长水 -清华大学自动化系
(6)互联网资源:
- Google Scholar
-
Wikipedia
-
UCI Machine Learning Repository(有很多数据集)
-
The Data Platform for AI | WEKA(开源数据挖掘软件)
- MATLAB & Simulink - MathWorks(数据挖掘相关软件包,如神经网络)
-
KDnuggets: Machine Learning, Data Science, Big Data ...(数据挖掘网站,有大量关于论文、数据、工作等方面信息)
2、数据挖掘(Data Mining)是一个多学科交叉领域
- 机器学习 Machine Learning
- 模式识别 Pattern Recognition
- 统计学 Statistics
- 人工智能 Artificial Intelligence
3、数据挖掘(Data Mining)无所不在
- 商务智能 Business Intelligence(BI)
- 数据分析 Data Analytics
- 大数据 Big Data
- 决策支持 Decision Support
- 客户关系管理 Customer Relationship Management(CRM)
3 知行合一
1、Data(数据)
(1)定义:定量或定性的属性值,是最底层的表现形式,数据做一些处理后称之为信息
(2)类型:
- 连续型(如身高、体重)
- 二进制(二值型,0/1,如婚否)
(3)存储:
- 物理层:所有的数据(声音、图像、文字)在磁盘上存储的时候,都是01这样存储的(串型/顺序存储)
- 逻辑型:数据库中是一个二维表、数据仓库有立方体、星型、网络型结构等
(4)主要问题:
在实际数据分析工作中,面临的主要挑战有:
- 数据类型转换
- 数据自身的错误
2、Big Data(大数据)
(1)定义:
- Gartner:数据量大(high-volume)、产生速度快(high-velocity)、数据类型多(high-variety)
- 麦肯锡:超过传统意义上数据库、数据存储技术、数据处理技术能力的数据
(2)特点:
- 数据量 Volume:从 TB 到 ZB
- 数据类型 Variety:从结构化数据(数据)到非结构化数据(文本、声音、图像、视频)
- 数据产生的速度 Velocity:从堆(Batch)到流(Streaming)
3、实际应用
(1)公共安全:根据犯罪历史记录,把不同犯罪类型标注在地图上,同时还标注警察局的位置。通过可视化,更加直观地看到犯罪发生的规律、挖掘犯罪的模式,以达到预防犯罪、减少犯罪发生的目的
(2)医疗保健:分析人类基因组,根据基因不同把人进行分组,给不同组的人不同的药物和治疗方式(哪怕得的病相同),以达到对症下药的目的
(3)地理位置数据(Location Data):
- 城市规划:如交通信息
- 移动用户:APP或智能装备的定位
- 购物:每一个购物车上都有RFID标签,当一个人购物时,他的所有轨迹信息都被记录下来,甚至可以记录某一个顾客在某一个货架前停留的时间、只是浏览还是实际购买了。或者统计商场每一层每一个区域的人数,预防拥挤踩踏
Q:在超市环境中对客户位置轨迹进行记录和分析的主要目的有:
- 对拥挤人群进行预警
- 优化商场布局
- 个性化营销
(4)零售业:
- 精准营销(Targeted Marketing):对客户进行精准画像(目标客户),有针对性地推荐商品
- 情感分析(Sentiment Analysis):用户购物后的评论,识别其情感
(5)社交网络(Social Networks):找到其中的group、有影响力的人(关键意见领袖KOL)
(6)点球成金(MoneyBall):
- 棒球
- 数据分析技术,可以更加全面衡量地每一个球员真正的价值,用这种方法挑选球员
(7)Attractiveness Mining:非诚勿扰
- 每一个女嘉宾的信息(年龄、城市、工作信息、要不要孩子、是否跟父母一起住)
- 颜值数字化:人脸识别、模式识别——脸的形状、眼睛的大小等
- 评价指标:心动女生
- 回归(Logistic Regression)
4 从数据到知识
1、Open Data(开放数据)
数据很多时候都是在政府部门手里,很难将这些数据获取并打通,形成了所谓的“数据孤岛” 现象,每一个小岛上有一个服务器
公开数据有两个层面的含义:
- 法律上(Legally)公开:数据是允许别人访问的,而不是以抓取的方式
- 技术上(Technically)公开:数据易获取,政府部门应将数据以标准数据格式(如Excel)公开
可以下载公开数据的网址:
开放政府数据

2、Data Mining(DM,数据挖掘)
(1)定义
- 数据挖掘是一个自动的过程:从大量的(massive)、不完整的(incomplete)、有噪声的(noisy)数据中,提取有趣的(interesting)、有用的(useful)、隐含的(hidden)模式
Q:理想的数据挖掘工作成果应当:interesting、useful、hidden
- 数据挖掘不是一个全自动的过程:需要人为交互(如挑选属性、解释等),尤其是在数据的获取和预处理过程中
- 近义词:Knowledge Discovery(知识发现)
(2)数据挖掘的重要性
数据现在变得越来越多、越来越廉价,要学习与数据分析相关的技术
- 数据库
- 机器学习
- 统计学
- 可视化
(3)在商务智能(Business Intelligence,BI)领域的应用
- Decision Making(决策)
- Customer Segmentation(客户群划分)、识别风险客户(如欺诈客户)、识别VIP客户(保留,不能流失)
- 预测企业的发展或危险(提前预警)
3、从数据(Data)到智能(Intelligence)
- Data:最底层,传感器采集
- Information:数据经过处理称为信息,数据本身可能会有很多冗余或错误,信息是在数据层面之上的
- Knowledge:信息通过数据挖掘称为知识
- Decision Making:知识加上领域模型,就成为可以帮助认为进行决策的商务智能方面的模型

4、流程
(1)业界数据挖掘的流程:
通常数据是存放在不同数据源当中的(如文本文件、CRM系统、ERP系统、数据库),要把所有数据进行融合(ETL:Extraction提取、Transformation转换、Loading装载),然后装在数据仓库当中(有源数据、真实数据),再在这些数据上做分析
Q:ETL系统的主要作用包括:数据提取、数据转换、数据装载
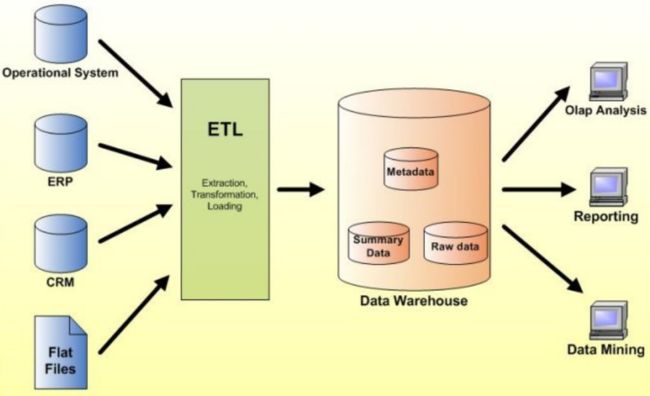 (2)抽象层面数据挖掘的流程:
(2)抽象层面数据挖掘的流程:
定义问题—采集数据—数据准备—建模(分类、预测、回归等等)—解释或评价结果(若结果准确度不够高,还要反馈回去)—实施/应用(若有问题也需要反馈)
 类似软件工程开发时的瀑布模型
类似软件工程开发时的瀑布模型
5、业界应用(商用数据分析软件)
- IBM SPSS:可视化建模工具(神经网络、决策树、时间序列分析、分类器)
- SAP Predictive Analysis 1.0:数据分析软件
- Oracle Data Miner
5 分类问题(Classification)
1、什么是分类问题?
数据挖掘中的第一类算法
(1)形式化定义:给一些训练集(有属性、标签),训练出一个模型,再来一个未知的物体,可以预测它是什么样
(2)算法:
- 决策树(Decision Trees)
- KNN(K-Nearest Neighbors)
- 神经网络(Neural Networks)
- 支持向量机(Support Vector Machines)
(3)应用:
- 医学诊断(根据体检报告预测有病还是没病、肿瘤是恶性还是良性)
- 预测客户是否会流失
2、Classification Boundaries(分界面)
分界面可以是一条直线或一条曲线,或多个曲线围成的区域,其本质就是对空间的划分,因为每一个 item 或 object 都量化成了 n 维空间的一个点
 横坐标:收入
横坐标:收入
纵坐标:存款
预测贷款风险高低
 无法用一根线区分开圆圈和三角
无法用一根线区分开圆圈和三角
3、Overfitting(过学习)
可以生成不同的分类器,对应不同的分类面
 绿色的分类器:所有点都分类正确,但没有形成一个合理的分界面
绿色的分类器:所有点都分类正确,但没有形成一个合理的分界面
黑色的分类器:有分错的,但是是 平滑的曲线,更优
并不是分类器在训练样本上的学习误差越低越好
4、Cross Validation(交叉验证)
数据是要分成两部分的
- 训练集(Training Set):生成模型
- 测试集(Test Set):校验模型
5、Confusion Matrix(混淆矩阵)
假设是两分类问题:一类叫正类(Positive),一类叫负类(Negative)
- 每一个样本本身是有自己的真实的标签的
- 模型对样本又打了一个标签
这两个标签可能是不一致的

6、Receiver Operating Characteristic(ROC曲线)
 男人、女人和身高
男人、女人和身高
横坐标为身高,两个高斯分别代表男人和女人( 通常来说男人的身高是比女人高的,但不可能用身高去绝对区别男人和女人),中间这条线代表了阈值(threshold)
- 若阈值设置的过低,则TP为100%(所有男人都被判断成男人),但FP也是100%(所有女人也都被判断成男人)
- 反之,若阈值设置的过高,则TP为0(所有男人都会被误判为女人),FP也为0(所有女人都会被正确地判断成女人)
 Random guess对应的是50%,即不考虑属性,随意乱猜的结果
Random guess对应的是50%,即不考虑属性,随意乱猜的结果
如何衡量这条曲线好还是不好?
AUC(Area Under Curve):性能指标,即曲线下的面积,上限为1,越接近于1越好
在ROC分析中,分类器的性能曲线的理想状态是:越靠上越好(AUC趋近于1)
7、Cost Sensitive Learning(代价敏感分类问题)
实际中,问题是带权重的,两种错误的代价成本是不同的,要寻找 balance 或 trade-off
如:把一个有病的人误判为没病 VS 把一个没病的人误判为有病 哪种危害更大?
Q:以下最有可能涉及代价敏感分类问题的是?
区分猫狗图片 社交网络好友推荐 手写体识别 银行信用卡评分模型
8、Lift Analysis(评价模型实际使用中的效能)
市场营销中会用到
例1:假设100个人里,真正会购买产品的只有8个人(先验是8%),如果一个一个打电话推销,比较低效。随机挑10%,8个人中的10%会被挑中
对用户进行建模,假设模型能把用户接受产品的概率计算出来并排序,把最有可能购买产品的前10%的用户放在前面,这前10%的用户里可能就包含了真正购买产品的将近40%的客户
Lift(提升度,即用了模型和不用模型的差异):40% / 10% = 4
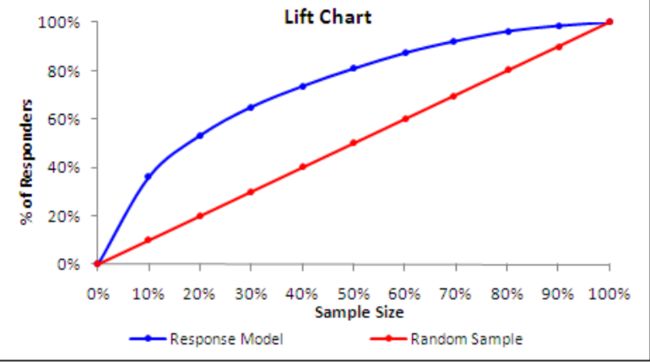
例2:Overall Response Rate = 8%,平均下来随机挑100个人,有8个人会买产品
经过打分排序,前10%的人中有29%的人都会买产品
浓缩的过程

Q:假设目标客户占人群的5%,现根据用户模型进行打分排序,取1000名潜在客户中排名前10%的客户,发现其中包含25名目标客户,问此模型在10%处的提升度是?
目标客户占人群的5%,有1000名潜在客户 ——> 目标客户有1000×5%=50人
而现在采用模型之后,发现了25名目标客户,占全体目标客户总数的一半(50%)
故提升度为 50% / 10% = 5
6 聚类及其他数据挖掘问题
1、聚类(Clustering)
(1)定义:给一堆 items(无事先人为的标签),分 group,同一个 group 里的数据是比较相似的,不同 group 之间数据差异比较大
- 分类(Classification)是Supervised Learning(有监督学习)
- 聚类(Clustering)是Unsupervised Learning(无监督学习)
Q:聚类和分类的主要区别在于:数据有无标签

(2)如何衡量两个点距离远近或是否相似?——距离度量(Distance Metrics)
- 欧氏距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
- 马氏距离(Mahalanobis Distance)
(3)算法:
- K-Means
- Sequential Leader
- Affinity Propagation
(4)应用:
- 客户划分(Market Research)
- 图像分割(Image Segmentation)
- 社交网络分析(Social Network Analysis)
例1:每个圈都代表一个group,group里的样本离得近,group之间的样本离得远

例2:层次型聚类(Hierarchical Clustering)
适用场景:不易区分两个样本的远近,取决于从哪个层面去看时
最上一层是一个一个单独的elements,两两聚类,最终聚成一个cluster

2、关联规则(Association Rule)
商店购物时,每个人都会买很多商品,形成transaction(购物小票)
购物记录形式化处理后就是一张二维表
要从中发掘哪些物品经常会被同时购买,或买了什么东西的人,会比较可能去买其他的一种或多种商品
例:{Milk,Bread} => {Butter}
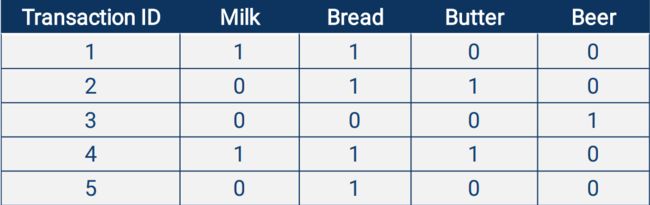 1表示购买了,0表示没有购买
1表示购买了,0表示没有购买
3、回归(Regression)

(1)线性回归不是只能拟合出直线,如多项式就会拟合出曲线。以上举的例子都是线性回归
线性是指参数与变量之间是线性的,即β乘以x是线性的,而不是最终的表达是线性的
Q:判断 — 线性回归模型由于自身局限性只能描述变量间的线性关系 错误
应是参数与变量间
(2)回归也有overfitting(过学习)的问题
 (左)模型不够强大,误差很高,数据不是线性的,不能用一根线来描述
(左)模型不够强大,误差很高,数据不是线性的,不能用一根线来描述
(中)最优
(右)误差为0,但过学习了
4、Seeing is Knowing(所见即所得)
表达高维数据或不同形式数据之间的相互关系
- 分析数据前先做可视化,再判断用什么样的算法应用在数据上建模
- 数据挖掘完成后,模型有输出,输出的结果同样可以可视化,便于解释结果
 Performance Dashboard(仪表板)
Performance Dashboard(仪表板)
可视化软件:
5、Data Preprocessing(数据预处理)
实际数据挖掘中,最麻烦、最有挑战性的部分是数据预处理的部分,数据是dirty的
(1)典型问题
- 缺失,采集不全
- 填的值不正确(如年龄填了负值)
GIGO:Garbage In Garbage Out
(2)数据质量
- 准确性 Accuracy
- 完备性 Completeness
- 一致性 Consistency
- 可解释性 Interpretability
- 可信性 Credibility
- 时效性 Timeliness
数据清洗(Cleaning):缺失值填充、修改不一致的值
数据集成(Integration):结合不同来源的数据
数据转换(Transformation):标准化、类型转换
数据约简(Reduction):特征选择(Feature Selection)、采样(Sampling)
7 隐私保护与并行计算
 以前:没有人知道你在互联网上是条狗
以前:没有人知道你在互联网上是条狗  现在:知道什么样的狗在上网、旁边有什么样的狗
现在:知道什么样的狗在上网、旁边有什么样的狗
1、隐私保护(Privacy Protection)
给用户发放调查问卷来采集数据,怎样既保护用户的隐私,又得到想要的数据呢?
Q:如何才能最有效地采集到用户可能不愿公开提供的信息? 随机问卷题目
(1)思路:收集问卷的人不知道每一个受访者的答案,但是知道所有问卷收集上来之后的比例。即:只需知道比例,不用具体到某一个人
(2)例子:

- 若问题为 “你吸过大麻吗?” ,回答为 Yes 或 No 受访者通常都会填No
- 设计两个问题:第一个问题“我吸大麻”,第二个问题“我不吸大麻”
受访者只需回答一个问题(一定概率,如概率p回答问题1,概率1-p回答问题2)。收集问卷的人并不知道特定的受访者回答的是哪个问题,是随机的 - 假设收上来的问卷中,有20%的人写了True,但并不知道是哪个问题回答True
回答True的概率 = 真正吸大麻的人 P(True)× 选择回答第一个问题的概率 + 不吸大麻 × 选择回答第二个问题的概率
变换后便得到人群中真实吸大麻的人的比例
Q:判断— 在隐私保护的问卷调查中,针对两个互补问题,用户也可用Yes/No回答,与用True/False本质上一样 错误
2、云计算(Cloud Computing)
(1)背景:用户对服务器访问的需求是随时间的变化而变化的
 (左)阴影部分:浪费
(左)阴影部分:浪费
(2)定义: 把计算(如服务器)当做一种资源,不用自己去购买大量的服务器,而是从云计算提供商那里租服务器(虚拟)
- 软硬件 ——> 服务(新模式)
- 可以随时调整,对资源的利用率高(PAYG:Pay As You Go —— 云计算的核心特征)
SAAS:Software as a Service 软件即服务
PAAS:Platform as a Service 平台即服务
IAAS:Infrastructure as a Service 基础设施即服务
3、并行计算(Parallel Computing)
(1)串行计算的思想:愚公移山
(2)并行计算:把问题进行切分,分配到不同的处理器上(例:人多力量大、众人划桨开大船)
(3)GPU(图形显示卡):3D渲染/图形图像/游戏/科学计算
- GPU作为高性能计算设备的优点:低成本、高计算密度、安装便捷
- 目前GPU依然需要与CPU协同工作,共同组成异构计算平台
4、宏观上,数据挖掘该怎么做?
数据 + 模型/算法 + 高性能计算(计算平台)----> 实现数据的价值
需要三方面的共同协作,缺一不可
Q:有效的数据挖掘工作需要高质量的数据、合适的算法模型、强悍的计算平台、丰富的领域知识的支持
5、No Free Lunch(没有免费的午餐)
- 没有最好的算法,算法的参数也没有最好的,都是因问题而不同
- 需要经验,以及不断尝试,还需要考虑很多因素,取决于目的,如需要结果有可解释性,则选择决策树(if-then规则,可解释性好)而不是神经网络(可解释性差)
- 先用简单的方法
8 迷雾重重
1、Case Study
例1:是否可以用数据挖掘的方法预测股市?
金融大数据量化交易:克服交易者本身性格上的缺陷
短期股票价格波动难以精准预测的主要原因:股票价格是诸多外部因素共同作用的结果,而这些因素(模型的输入)往往很难被事先准确衡量

例2:彩票中奖号码是随机生成的,无法预测
数据挖掘不创造规律,只发掘规律
2、相关
(1)Grouping
 X与Y之间是 负相关关系,X增大,Y减小
X与Y之间是 负相关关系,X增大,Y减小
换一个角度看问题:
把数据分个组,分为Group A和Group B,此时X和Y变为正相关了 
不能宏观的看问题,因为数据可能有内在分组的特性
(2)因果
暴力游戏销量与美国犯罪率的关系:随着暴力游戏销量的增加,美国的犯罪率是减少的
两条曲线有一定的相关性,跟它们之间的因果是很难划等号的(不能说一个导致/促进了一个)

(3)心理因素(人们内心的倾向性)
一个人的身高与他在商业上的成功有无关系?
知名企业CEO中身材高大者比例>平均水平,这是因为:身材高大者容易树立威信
3、Survivorship Bias(幸存者偏差)
轰炸机在哪里加装甲?
- 在中弹密集的地方(翅膀、尾巴) ×
- 在要害部位(油箱、发动机、驾驶舱) √
能看到这些飞机的前提是:能飞回来(虽然中弹累累),坠毁的飞机是看不到的
虽然翅膀等地方中弹密集,但是还能飞回来,说明不是致命的
看到的样本本身就是有偏差的,是能飞回来的,而不是那些受到致命伤的
 100架轰炸机中弹的分布图
100架轰炸机中弹的分布图
4、解决实际问题时不能单向思维
从相同的数据中,可能得到完全不同的结论
看问题一定要全面,从不同层次、不同角度综合考虑,不能以偏概全
例1:
横坐标:天猫上每一家店铺(都是卖格力)的营业额纵坐标:有多少个商家在卖
随着店铺数量的增加,每一家的营业额也越来越大(X与Y正相关,蓬勃发展的市场)
反过来看:在天猫上卖格力电器的店越来越少,每一家店的营业额也越来越少(夕阳产业)
为什么? ——> 缺少时间维度,不知道数据是从左往右看,还是从右往左看
例2:
天猫上卖九阳的越来越多,每一家店的营业额越来越少(市场很饱和,竞争惨烈)
反过来看:从左往右看,随着店铺数量越来越少,每一家的营业额越来越多(经过大浪淘沙,服务不好的被淘汰掉了,是一个健康稳定的市场)
为什么? ——> 缺少时间维度,不知道数据是从左往右看,还是从右往左看
例3:

- 三根木板 or 四根木板?
- 盲人摸象的错误
- 爱因斯坦?玛丽莲梦露?
9 单元补充
针对数据挖掘领域,观点正确:You cannot be too careful!(你越小心越好)
数据的被遗忘权主要指的是:我有权要求搜索引擎删除过时的和自己有关的搜索结果
数据的可携带性指的是:公民享有要求服务商提供个人数据迁移便利的权利
两个变量X和Y呈现负相关性,说明:Nothing
利用大数据分析技术进行预防犯罪:可针对群体进行防范,但不宜针对个人