RISC-V汇编指令
写在最前面:这一篇是UC Berkeley的CS61C的笔记,根据我自己的理解进行学习记录,其中贴的一些图片来自于课程PPT。
了解汇编之前,我们需要先了解为什么需要汇编?以下是我的理解:
机器执行的命令都是些二进制的机器码,我们需要对机器进行编程需要记住这些机器码,这是对于程序员很不友好的,所以前人就用一些汇编指令取替代这些机器码,代码写完之后再使用编译器生成这些机器码,所以汇编是为了简化编程而创造出来的。
汇编代码一般使用.S结尾,表示source file;汇编翻译出的机器码用.o结尾,表示machine code object file;链接器链接生成的结果以.out结尾表示是最后的生成结果。
文中的
rd是register destination的缩写,意为目标寄存器;rs是register source的缩写,意为源寄存器。
1 算数运算与逻辑运算指令
| Num | Arithmetic / logic | mean | e.g. |
|---|---|---|---|
| 1 | add |
加法运算指令 | add rd, rs1, rs2 |
| 2 | sub |
减法运算指令 | sub rd, rs1, rs2 |
| 3 | and |
与运算指令 | and rd, rs1, rs2 |
| 4 | or |
或运算指令 | or rd, rs1, rs2 |
| 5 | xor |
异或运算指令 | xor rd, rs1, rs2 |
| 6 | sll |
shift left logical 逻辑左移运算指令 | sll rd, rs1, rs2 |
| 7 | srl |
shift right logical 逻辑右移运算指令 | srl rd, rs1, rs2 |
| 8 | sra |
shift right arithmetic 算数右移运算指令 | sra rd, rs1, rs2 |
这是一组是运算指令,1-2是算数运算指令,3-8是逻辑运算指令。
算数运算指令比较简单,这里以加法运算指令为例:
a = b + c;
add rd, rs1, rs2
->
# a = rd, b = rs1, c = rs2
add rd, rs1, rs2的意义就是将寄存器rs1的值加上寄存器rs2的值,最后存储到目标寄存器rd中。减法运算指令同理。
接下来看逻辑运算指令:
以逻辑左移指令为例:
sll x11, x12, x13 # x11 = x12 << x3
以上指令的意义是将x12左移x13位,存储到x11当中;右移运算符srl使用方式相同。
sra算数移位运算符指的是移位后,空出的bit用符号位填充:
1111 1111 1111 1111 1111 1111 1110 0111 = -25
srai x10, x10, 4
1111 1111 1111 1111 1111 1111 1111 1110 = -2
这里要注意,算数移位运算并不等于直接除以2。
首先要注意的是RISC-V中是没有NOT指令的
2 immediate
| Num | Immediate | mean | e.g. |
|---|---|---|---|
| 1 | addi |
加法运算指令 | addi rd, rs1, imm |
| 2 | andi |
与运算指令 | andi rd, rs1, imm |
| 3 | ori |
或运算指令 | ori rd, rs1, imm |
| 4 | xori |
异或运算指令 | xori rd, rs1, imm |
| 5 | slli |
shift left logical 逻辑左移运算指令 | slli rd, rs1, imm |
| 6 | srli |
shift right logical 逻辑右移运算指令 | srli rd, rs1, imm |
| 7 | srai |
shift right arithmetic 逻辑右移运算指令 | srai rd, rs1, imm |
这一组指令可以看作是第一节的扩展,第一节中的指令是将两个寄存器中的值做运算,这一节中的指令同样是做算数运算或者是逻辑运算,不同的是这一组指令用于常数计算。
为什么要单独出一组常数计算的指令呢?这是因为常数相加非常常见,如果从内存加载一个常数,可能会消耗更多的时间,用更多的寄存器,直接用一组专用的指令可能会让执行速度变得更快。
以addi为例:
a = b + 10;
addi rd, rs1, 10
->
# a = rd, b = rs1
addi rd, rs1, imm的意义就是将寄存器rs1的值加上常数imm,最后存储到目标寄存器rd中。
如果遇到a = b汇编应该怎么写呢?a = b可以看作是a = b + 0,但是这里我们不用addi,而是用add:
addi rd, rs1, x0
这里的x0表示寄存器,该寄存器接地,保存的值始终为0。
接下来有一点要注意,这一组指令中并没有看到有subi,当我们要用到立即数减法时,编译器会帮我们转化为负数,再使用加法,这样做可以简化ALU单元的设计:
a = b - 9;
addi rd, rs1, -9
3 Load/Store
| Num | Load/Store | mean | e.g. |
|---|---|---|---|
| 1 | lw |
load word 加载四字节指令 | lw x10, 12(x15) |
| 2 | sw |
store word 存储四字节指令 | |
| 3 | lb |
load byte 加载一字节指令 | |
| 4 | sb |
load byte 存储一字节指令 | |
| 5 | lbu |
load byte unsigned 加载一字节无符号数 |
我们调用汇编指令add sub来做运算,但是运算所要的数据还在内存当中,我们要如何将这些数据从内存加载到寄存器呢?运算完成后如何将数据重新写到内存呢?这就是这组组汇编指令的所能完成的事情。
lw用于从某个地址加载数据,sw用于将数据存储到某个地址。接下来举例看看lw sw应该如何使用:
int A[100];
g = h + A[3];
->
lw x10, 12(x15) # x15表示数组A的地址
add x11, x12, x10 # g = g + A[3]
我们首先要拿到数组A的地址,然后根据偏移量(以byte为单位)获取到需要读取的地址(这里要读取A[3],需要向后偏移12bytes),调用lw指令加载数据,最后完成计算。
如果我们要把计算得到的结果存储在A[10]中,要如何处理呢?
sw x11, 40(x15)
计算目标地址与基地址的偏移量,接着调用sw就好了。
使用lw sw时我们需要知道,每次读取或者写入都是以四字节为单位,32bit数刚好对应32bit寄存器,因此符号位在读取、写入过程中可以保留。
RISC-V还提供了加载、存储一个字节的指令lb wb,每次读取和写入都是一个字节,使用方法和lw sw类似。但是这里就会有问题了,当把一字节的数据从内存拷贝到寄存器时,这一字节的数据只占用了寄存器的8bit,那其他24bit(3byte)怎么办呢?都填0吗,有符号位要怎么办?
这里的做法是将符号位上的数填充到前面的3bytes里,这被称为符号扩展。
但是我们并不是每次都要做符号扩展,比如加载一个无符号数据就不需要扩展,所以还有一个指令lbu,用这个指令做加载就不会执行符号扩展,直接用0填充其他的三个字节。要注意,是没有sbu 的,这是因为从寄存器存储一字节到内存时,这一字节的最高位本身就是符号位了。
4 Branch
| Num | Branching/Jumps | mean | e.g. |
|---|---|---|---|
| 1 | beq |
branch if equal 等于 | beq rs1, rs2, L1 |
| 2 | bne |
branch if not equal 不等于 | |
| 3 | bge |
branch if greater than or equal 大于等于 | |
| 4 | blt |
branch if less than 小于 | |
| 5 | bgeu |
bge的unsigned版本 |
|
| 6 | bltu |
blt的unsigned版本 |
|
| 7 | j(伪指令) |
jump 跳转 | j label |
这一组是分支指令,上面的1-6是条件分支指令,需要通过比对值来控制代码执行流程,这一组指令的最后一个参数是跳转标签(Label);7-9是非条件分支指令,执行到这些命令时总是会跳转。接下来一起看看例子:
如果我们要判断两个值是相等然后再去执行对应操作,我们应该使用什么指令呢?
if (i == j)
f = g + h;
->
bne x13, x14, Exit
add x10, x11, x12
Exit:
可以看到我们用的时bne,bne x13, x14, Exit的意思是如果不相等则跳转到Exit。为什么不用beq,而是要用一个相反的指令呢?我们尝试写一下:
beq x13, x14, Branch
j Exit
Branch:
add x10, x11, x12
Exit:
从上面我们可以看到,如果条件不成立,跳过add指令会麻烦许多,所以判断时用相反的指令会更加简洁。
接下来再看一个if-else的例子:
if (i == j)
f = g + h;
else
f = g - h;
->
bne x13, x14, Else
add x10, x11, x12
j Exit
Else:
sub x10, x11, x12
Exit:
这里有一点要注意,不能忘了退出指令;另外是没有ble 的,如果需要判断小于等于可以通过是否大于来判断。
接下来的例子更复杂一点,我们如何使用条件分支指令实现for / while 循环呢?
int A[20];
int sum = 0;
for (int i = 0; i < 20; i++)
sum += A[i];
->
add x9, x8, x0 # x9=&A[0]
add x10, x0, x0 # sum
add x11, x0, x0 # i
addi x13, x0, 20 #
Loop:
beq x11, x13, Done
lw x12, 0(x9) # A[i]
add x10, x10, x12 # sum += A[i]
addi x9, x9, 4 # &A[i+1]
addi x11, x11, 1 # i++
j Loop
Done:
5 Pseudo-instructions
伪指令指的是一些常用汇编指令的替代,例如:
mv rd, rs = addi rd, rs, 0
li rd, 13 = addi rd, x0, 13
nop = addi x0, x0, 0
ret = jr ra
j = jal x0, Label
6 Function Call
这一组指令用于支持函数调用,了解指令前,先来了解程序是如何执行的。
我们的汇编代码经过编译器翻译后会生成二进制的目标文件,目标文件中的数据就是一条一条的指令。程序执行时会将这些指令一条一条加载到内存中对应的程序区,所以这些指令也是有对应的地址的。CPU中有一个特殊的寄存器Program Counter(PC)程序计数器,里面存储的是下一条指令的地址,一条程序执行完成,PC会更新其保存的地址(默认是增加4字节来指向下一条指令,因为RISC-V中的所有指令都是32bits)。PC中的地址更新时也会有其他情况比如说上面的j指令,或者这一节将会了解的函数调用相关指令,PC的地址将会更新到指定内存地址。
6.1 相关指令

函数调用中的一些约定:
- 函数调用过程中使用a0-a7
(x10-x17)(argument register)这8个寄存器来传递参数,其中两个a0-a1用于返回参数; - 寄存器
x1是ra(return address register)用于回到控制原点,即回到函数调用的地方; - s0-s1
(x8-x9),s2-s11(x18-x27)(saved register)保存寄存器
| Num | function call | mean | e.g. |
|---|---|---|---|
| 1 | jr |
jump register 跳转到寄存器 | jr ra |
| 1 | jal |
jump and link 跳转并链接 | jal rd, Label |
| 2 | jalr |
jump and link register 跳转并链接 | jalr rd, rs, imm |
jump and link表示:跳转到某个地址,并且函数调用的下一条指令的地址保存到ra;
我们先来看一个函数执行的汇编代码示例:
...
sum(a, b);
...
int sum(int x, int y) {
return x + y;
}
->
#address (decimal)
1000 mv a0, s0 # x = a
1004 mv a1, s1 # y = b
1008 addi ra, zero, 1016 # ra = 1016
1012 j sum
1016 ...
...
2000 sum: add a0, a0, a1
2004 jr ra
从上面的例子我们可以发现,函数体在内存中的地址和主程序可能会离得比较远,函数执行时有如下步骤:
- 拷贝参数
- 保存函数执行完成后的地址到
ra - 跳转到函数并执行
- 执行完成后跳转到
ra
这里用到一条新的指令jr,跳转到某个寄存器。为什么这边不用j来跳转呢?因为j跳转需要很多标签,如果函数返回要加标签,那么可能到处都是这些标签了。
每次使用jr跳转时,需要在函数执行前将控制点记录到ra中,这可能会有些许麻烦,RISC-V为我们提供了jal指令来帮助我们做保存返回地址的工作,示例如下:
1008 addi ra, zero, 1016 # ra = 1016
1012 j sum
->
1008 jal sum
由于返回函数调用点非常常用,所以用ret这个伪指令代替jr ra。
jal命令如果我们不需要返回地址则将他保存到x0:jal x0, Label,并且用伪指令j来替代。
6.2 关于函数调用的一些知识
6.1节中我们初步了解了函数调用,接下来我们再通过一些示例来理解函数调用。我们先总结下CPU进行函数调用时需要经历的6个步骤:
- 将参数放到函数可以获取到的地方(寄存器);
- 将控制点交给函数(
jal); - 获取函数需要的存储资源;
- 执行函数;
- 将函数返回值放到调用者可以获取的地方,释放本地存储;
- 将控制点还给调用者(
ret)。
这里有一个问题:当CPU进行函数调用时,寄存器会被用来存储函数中的变量,原来寄存器中的值存应该如何存储呢?函数调用结束时这些值应该如何恢复呢?
存储这些值需要一块内存,函数调用前将存储寄存器中旧的值存到内存中,函数调用结束后从内存中恢复这些值并且删除掉他们。
这块内存被设计为栈结构(stack: last in first out (LIFO)),为了找到这块内存,需要有一个寄存器指向这块地址,这个寄存器x2被称为栈指针(sp: stack pointer)。
约定栈指针从高地址到低地址增长:push动作减小栈指针的值,pop增加栈指针的值。
接下来要了解栈帧(stack frame)的概念,每一次函数调用所用到的内存块被称为栈帧,栈帧里包含有返回指令的地址,传入参数的值,以及一些本地变量的值。

在嵌套函数调用中,我们常称调用函数伪CalleR,称被调用函数为CalleE。当被调用函数执行时,调用函数需要知道哪些寄存器的值被改变了,哪些寄存器的值没有被改变。为了减少从内存存储或者加载数据的次数,寄存器被分成两类:
- 在函数调用期间值可以保留的寄存器:
Caller只能依赖这些没有修改的寄存器,例如sp、gp、tp; - 函数调用期间值不能保留的寄存器:例如参数寄存器a0-a7,ra,临时寄存器(temporary)t0-t6。
以下是寄存器列表,我们不需要非常了解每个寄存器的作用,但是需要了解寄存器中的值由谁来保存: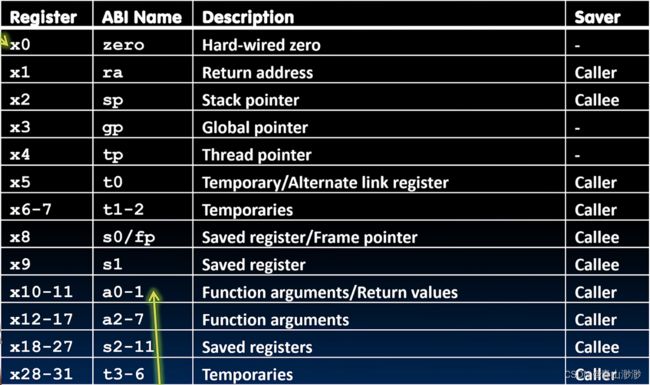
接下来看一个嵌套调用的例子:
int sumSquare(int x, int y) {
return mult(x, x) + y;
}
->
sumSquare:
addi sp, sp, -8 # 先给stack开辟空间
sw ra, 4(sp) # 存储 sumSquare ra(return address)
sw a1, 0(sp) # 存储 y 到栈帧
mv a1, a0 # 创建 mult 函数参数到寄存器 a0
jal mult # 调用 mult 函数
lw a1, 0(sp) # 保存 mult 返回值到栈帧
add a0, a0, a1 # 完成加法计算
lw ra, 4(sp) # 获取 ra
addi sp, sp, 8 # 恢复栈指针
jr ra # 返回 sumSquare 调用中
mult:
...
我们的程序在运行时,变量会存在于三种内存空间中:
- static:只会被声明一次的变量,其生命周期一直到程序终止
- heap:通过动态内存分配(malloc)声明的变量
- stack:程序执行期间所用到的空间,寄存器可以存储值到这块空间中
接下来了解下内存布局:RV32 和 RV64、RV128的内存布局不一样,这里了解RV32的内存布局:
- 栈空间起始于高位地址,并且向下增长,栈空间必须进行16-bytes对齐
- test segment在内存的最底部
- 静态数据段在文本段上面,有一个global pointer(
gp)指向静态区 - 堆空间在静态区上面,从低地址向高地址增长
