一文看懂hive中group by rollup/cube group by sets用法及区别(附案例)
一文看懂hive中group by rollup/cube group by sets用法及区别(附案例)
- GROUP BY用法
- GROUP BY ROLLUP用法
- GROUP SETS用法
- GROUP BY CUBE用法
- 总结
有的放矢,先有需求,再有解决方案,直接上案例
测试表
分数表
CREATE TABLE TEST_GROUP(
name string comment '姓名',
syear string comment '学年',
course string comment '科目',
score int comment '分数');
测试数据
INSERT OVERWRITE TABLE TEST_GROUP VALUES
('李四','2020','数学','50'),
('李四','2020','语文','40'),
('李四','2019','语文','40'),
('钱琪','2020','数学','20'),
('钱琪','2021','语文','50'),
('狗勾','2020','语文','100');
GROUP BY用法
本文的基础,group by
需求一:
查询每名同学每个学年的总分数
分析:我们需要将相同名称,相同学年的数据放入一组,然后将分数汇总相加。
sql代码
SELECT
name,syear,
SUM(score) as sumscore
FROM test_group
GROUP BY name,syear;
结果
| name | syear | sumscore |
|---|---|---|
| 李四 | 2019 | 40 |
| 李四 | 2020 | 90 |
| 狗勾 | 2020 | 100 |
| 钱琪 | 2020 | 20 |
| 钱琪 | 2021 | 50 |
可以看到,group by根据分组key(name,syear)进行分组,通过聚合函数,将其他字段进行聚合,最终得出结果
需求二
1.查找 每名同学 每个学年 每个学科 的分数
2.查找 每名同学 每个学年 的总分
3.查找 每名同学 的总分
4.查找 所有记录 的总分
ps: 查询结果一次返回
这个需求我们用group by 可不可以实现呢?
当然可以,我们拆分来看
1.查找 每名同学 每个学年 每个学科 的分数
这个比较简单
SELECT
name,syear,course,
SUM(score) as sumscore
FROM test_group
GROUP BY name,syear,course;
结果
| name | syear | course | sumscore |
|---|---|---|---|
| 李四 | 2019 | 语文 | 40 |
| 李四 | 2020 | 数学 | 50 |
| 李四 | 2020 | 语文 | 40 |
| 狗勾 | 2020 | 语文 | 100 |
| 钱琪 | 2020 | 数学 | 20 |
| 钱琪 | 2021 | 语文 | 50 |
2.查找 每名同学 每个学年 的总分
SELECT
name,syear,
SUM(score) as sumscore
FROM test_group
GROUP BY name,syear;
结果
| name | syear | sumscore |
|---|---|---|
| 李四 | 2019 | 40 |
| 李四 | 2020 | 90 |
| 狗勾 | 2020 | 100 |
| 钱琪 | 2020 | 20 |
| 钱琪 | 2021 | 50 |
3.查找 每名同学 的总分
SELECT
name,
SUM(score) as sumscore
FROM test_group
GROUP BY name;
结果
| name | sumscore |
|---|---|
| 李四 | 130 |
| 狗勾 | 100 |
| 钱琪 | 70 |
4.查找 所有记录 的总分
SELECT
SUM(score) as sumscore
FROM test_group;
当未分组时,整个表的数据为一组,可以直接使用聚合函数,返回结果为一条数据
| sumscore |
|---|
| 300 |
最后将所有数据进行汇总,通过union all关键字。
union all函数在使用时,要确保查询的字段数量及类型对应,没有的列数据我们通过 NULL as ** 进行补充
SELECT
name,syear,course,
SUM(score) AS sumscore
FROM test_group GROUP BY name,syear,course
UNION ALL
SELECT
name,syear, NULL AS course,
SUM(score) AS sumscore
FROM test_group GROUP BY name,syear
UNION ALL
SELECT
name ,NULL AS syear,NULL AS course,
SUM(score) AS sumscore
FROM test_group GROUP BY name
UNION ALL
SELECT
NULL AS name ,NULL AS syear,NULL AS course,
SUM(score) AS sumscore
FROM test_group;
结果
| name | syear | course | sumscore |
|---|---|---|---|
| 李四 | 2019 | 语文 | 40 |
| 李四 | 2020 | 数学 | 50 |
| 李四 | 2020 | 语文 | 40 |
| 狗勾 | 2020 | 语文 | 100 |
| 钱琪 | 2020 | 数学 | 20 |
| 钱琪 | 2021 | 语文 | 50 |
| 李四 | 2019 | NULL | 40 |
| 李四 | 2020 | NULL | 90 |
| 狗勾 | 2020 | NULL | 100 |
| 钱琪 | 2020 | NULL | 20 |
| 钱琪 | 2021 | NULL | 50 |
| 李四 | NULL | NULL | 130 |
| 狗勾 | NULL | NULL | 100 |
| 钱琪 | NULL | NULL | 70 |
| NULL | NULL | NULL | 300 |
这是一种解决方案
下面介绍令一种更为简便的解决方案
GROUP BY ROLLUP用法
GROUP BY 和 ROLLUP是连着用的
可以实现从右到左递减多级的统计
不明白没问题 ,继续通过案例二来了解ROLLUP
我们还需要引入一个东西GROUPING__ID(注意是两个下划线)
SELECT name,syear,course,
SUM(score) AS sumscore,GROUPING__ID
FROM test_group
GROUP BY ROLLUP(name,syear,course)
ORDER BY GROUPING__ID;
结果
| name | syear | course | sumscore | grouping__id |
|---|---|---|---|---|
| NULL | NULL | NULL | 300 | 0 |
| 狗勾 | NULL | NULL | 100 | 1 |
| 钱琪 | NULL | NULL | 70 | 1 |
| 李四 | NULL | NULL | 130 | 1 |
| 狗勾 | 2020 | NULL | 100 | 3 |
| 钱琪 | 2021 | NULL | 50 | 3 |
| 李四 | 2020 | NULL | 90 | 3 |
| 李四 | 2019 | NULL | 40 | 3 |
| 钱琪 | 2020 | NULL | 20 | 3 |
| 钱琪 | 2021 | 语文 | 50 | 7 |
| 狗勾 | 2020 | 语文 | 100 | 7 |
| 李四 | 2020 | 语文 | 40 | 7 |
| 李四 | 2020 | 数学 | 50 | 7 |
| 李四 | 2019 | 语文 | 40 | 7 |
| 钱琪 | 2020 | 数学 | 20 | 7 |
| 我们先不理GROUPING__ID,后面会讲到,下面所说的级别是想让大家便于理解,与GROUPING__ID无关(通过GROUPING__ID的大小也可区分出级别,只不过不是连续的,后边会讲到原因) | ||||
| GROUP BY ROLLUP 是逐级运算的,那级别如何划分? | ||||
| 就是group by ROLLUP(c1,c2,c3)中的分组key的顺序从左到右,且存在第0级。 | ||||
| 第0级为无分组key,即整张表为一个组,进行聚合,对应sql为 |
SELECT
NULL AS name ,NULL AS syear,NULL AS course,
SUM(score) AS sumscore
FROM test_group;
第1级为分组key是(c1),那么会根据这一级的分组key (c1) 单独进行分组聚合一次,对应sql为
SELECT
name ,NULL AS syear,NULL AS course,
SUM(score) AS sumscore
FROM test_group GROUP BY name
第2级为分组key是(c1,c2),那么会根据这一级的分组key (c1,c2) 单独进行分组聚合一次,对应sql为
SELECT
name,syear, NULL AS course,
SUM(score) AS sumscore
FROM test_group GROUP BY name,syear
以此类推,直到所有分组key参与分组。
rollup逐级分组不会产生分组key为(c1,c3)的情况(c3越级)
我们再整体看一下
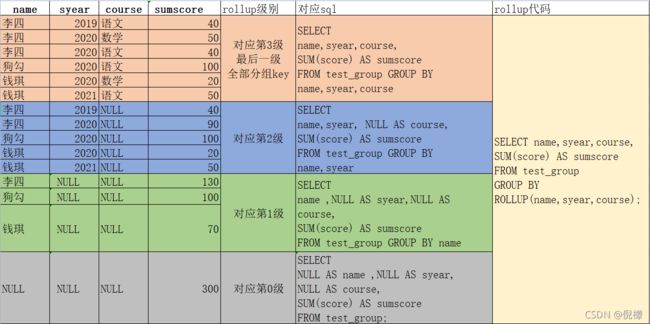
至此,ROLLUP相信大家应该明白应用场景和产生的结果。
我们在来看需求三
需求三
1.查找 每名同学 的总分
2.查找 每个学年 的总分
3.查找 每个学科 的总分
我们学会了group by 和union all的组合
直接上第一种方案的代码
SELECT
name,NULL AS syear,NULL AS course,
SUM(score) AS sumscore
FROM test_group GROUP BY name
UNION ALL
SELECT
NULL AS name,syear, NULL AS course,
SUM(score) AS sumscore
FROM test_group GROUP BY syear
UNION ALL
SELECT
NULL AS name ,NULL AS syear, course,
SUM(score) AS sumscore
FROM test_group GROUP BY course;
结果
| name | syear | course | sumscore |
|---|---|---|---|
| 李四 | NULL | NULL | 130 |
| 狗勾 | NULL | NULL | 100 |
| 钱琪 | NULL | NULL | 70 |
| NULL | 2019 | NULL | 40 |
| NULL | 2020 | NULL | 210 |
| NULL | 2021 | NULL | 50 |
| NULL | NULL | 数学 | 70 |
| NULL | NULL | 语文 | 230 |
没什么意外,接下来我们看看意外
GROUP SETS用法
GROUP SETS() 是用在group by后面的关键字,它可以将GROUPING SETS()中的每个分组key,作为一个key,进行一次分组进行查询
SELECT name,syear,course,
SUM(score) AS SUMSCORE
FROM test_group
GROUP BY name,syear,course
GROUPING SETS(name,syear,course) ;
结果
| name | syear | course | sumscore |
|---|---|---|---|
| NULL | NULL | 数学 | 70 |
| NULL | NULL | 语文 | 230 |
| NULL | 2019 | NULL | 40 |
| NULL | 2020 | NULL | 210 |
| NULL | 2021 | NULL | 50 |
| 李四 | NULL | NULL | 130 |
| 狗勾 | NULL | NULL | 100 |
| 钱琪 | NULL | NULL | 70 |
可以看到,grouping sets中,每个key作为一次分组聚合,连group by本身(原本为三个分组key聚合)都没做,统统交给grouping sets决定
注意:GROUPING SETS中的字段只能是GROUP BY中已有的
比如说group by c1,c2 grouping sets(c1,c2,c3) 这就是不正确的。
grouping sets()还有更多玩法,理论上是今天的头牌
再加上GROUPING__ID(注意是两个下划线)看看
老规矩,先上代码
SELECT name,syear,course,
SUM(score) AS SUMSCORE,
GROUPING__ID
FROM test_group
GROUP BY name,syear,course
GROUPING SETS((name,syear),name,syear,course,(name,course),(syear,course),())
order by grouping__id;
结果
| name | syear | course | sumscore | grouping__id |
|---|---|---|---|---|
| NULL | NULL | NULL | 300 | 0 |
| 狗勾 | NULL | NULL | 100 | 1 |
| 钱琪 | NULL | NULL | 70 | 1 |
| 李四 | NULL | NULL | 130 | 1 |
| NULL | 2020 | NULL | 210 | 2 |
| NULL | 2019 | NULL | 40 | 2 |
| NULL | 2021 | NULL | 50 | 2 |
| 钱琪 | 2021 | NULL | 50 | 3 |
| 钱琪 | 2020 | NULL | 20 | 3 |
| 狗勾 | 2020 | NULL | 100 | 3 |
| 李四 | 2020 | NULL | 90 | 3 |
| 李四 | 2019 | NULL | 40 | 3 |
| NULL | NULL | 语文 | 230 | 4 |
| NULL | NULL | 数学 | 70 | 4 |
| 李四 | NULL | 语文 | 80 | 5 |
| 狗勾 | NULL | 语文 | 100 | 5 |
| 钱琪 | NULL | 数学 | 20 | 5 |
| 钱琪 | NULL | 语文 | 50 | 5 |
| 李四 | NULL | 数学 | 50 | 5 |
| NULL | 2021 | 语文 | 50 | 6 |
| NULL | 2020 | 语文 | 140 | 6 |
| NULL | 2020 | 数学 | 70 | 6 |
| NULL | 2019 | 语文 | 40 | 6 |
示例:group by c1,c2,c3 grouping sets(c1,c2,c3)
通过测试可知GROUPING__ID的排序规则是按照group by 中的排序来定的,其次顺序为
0: ()
1:(c1)
2:(c2)
3:(c1,c2)
4:(c3)
5:(c1,c3)
6:(c2,c3)
7:(c1,c2,c3)
其中()为不使用group by中任何字段做为key,将数据表看成整体,grouping sets()可以使用()来进行自定义分组
通过实践,每种组合的id已注定,不受grouping sets()中先后影响,但会受group by中key的先后影响,把c1与c2调换位置,那么结果中的grouping__id也会改变。
当grouping sets 中分组key的数目扩大时,家人们可以自行测试,找到对应的grouping__id
grouping__id私以为用处很大,当你出现应用grouping sets的场景时,你可以通过grouping__id去打一个标识,毕竟代码是你写的,哪个grouping__id标识哪个枚举在case 中写死就可以了。
现在发现用grouping sets可以代替rollup。
我们继续来看需求四
需求四
在需求二的基础上
1.查找 每名同学 每个学年 每个学科 的分数
2.查找 每名同学 每个学年 的总分
3.查找 每名同学 的总分
4.查找 所有记录 的总分
5.查找 每个学年 每个学科 的分数
6.查找 每个同学 每个学科 的分数
相信家人们用group by + union all可以轻松解决,现在我们又多了一种解决方案,grouping sets
but! we want more
GROUP BY CUBE用法
cube中文翻译过来是立方体,意味着全方面的分组key它都能照顾到,在他这,众key平等,不谈阶级。
SELECT name,syear,course,
SUM(score) AS sumscore ,grouping__id
FROM test_group
GROUP BY CUBE(name,syear,course)
order by grouping__id;
结果
| name | syear | course | sumscore | grouping__id |
|---|---|---|---|---|
| NULL | NULL | NULL | 300 | 0 |
| 狗勾 | NULL | NULL | 100 | 1 |
| 李四 | NULL | NULL | 130 | 1 |
| 钱琪 | NULL | NULL | 70 | 1 |
| NULL | 2021 | NULL | 50 | 2 |
| NULL | 2019 | NULL | 40 | 2 |
| NULL | 2020 | NULL | 210 | 2 |
| 钱琪 | 2020 | NULL | 20 | 3 |
| 钱琪 | 2021 | NULL | 50 | 3 |
| 狗勾 | 2020 | NULL | 100 | 3 |
| 李四 | 2020 | NULL | 90 | 3 |
| 李四 | 2019 | NULL | 40 | 3 |
| NULL | NULL | 数学 | 70 | 4 |
| NULL | NULL | 语文 | 230 | 4 |
| 钱琪 | NULL | 语文 | 50 | 5 |
| 李四 | NULL | 语文 | 80 | 5 |
| 李四 | NULL | 数学 | 50 | 5 |
| 狗勾 | NULL | 语文 | 100 | 5 |
| 钱琪 | NULL | 数学 | 20 | 5 |
| NULL | 2020 | 语文 | 140 | 6 |
| NULL | 2020 | 数学 | 70 | 6 |
| NULL | 2021 | 语文 | 50 | 6 |
| NULL | 2019 | 语文 | 40 | 6 |
| 钱琪 | 2021 | 语文 | 50 | 7 |
| 钱琪 | 2020 | 数学 | 20 | 7 |
| 狗勾 | 2020 | 语文 | 100 | 7 |
| 李四 | 2020 | 语文 | 40 | 7 |
| 李四 | 2020 | 数学 | 50 | 7 |
| 李四 | 2019 | 语文 | 40 | 7 |
| 上面grouping sets 测试的时候没看到7,现在看到了 | ||||
| cube是将所有的分组key的排列组合都实现了一遍 |
示例:group by c1,c2,c3 grouping sets(c1,c2,c3)
grouping__id排序规则放在这也是可行的
0: ()
1:(c1)
2:(c2)
3:(c1,c2)
4:(c3)
5:(c1,c3)
6:(c2,c3)
7:(c1,c2,c3)
总结
grouping sets()的灵活性最高
group by rollup 是 grouping sets() 的部分
group by cube 是 grouping sets() 的全部组合
你说,用cube能实现需求一吗?
本文受制于本人的理解能力,如您发现纰漏,还望不吝赐教