算法与数据结构(二十一)前缀和数组&差分数组
前缀和技巧适用于快速、频繁地计算一个索引区间内的元素之和。
1. 一维数组中的前缀和
先看一道例题,力扣第 303 题「区域和检索 - 数组不可变」,让你计算数组区间内元素的和,这是一道标准的前缀和问题:
题目要求你实现这样一个类:
class NumArray {
public NumArray(int[] nums) {}
/* 查询闭区间 [left, right] 的累加和 */
public int sumRange(int left, int right) {}
}
sumRange 函数需要计算并返回一个索引区间之内的元素和,没学过前缀和的人可能写出如下代码:
class NumArray {
private int[] nums;
public NumArray(int[] nums) {
this.nums = nums;
}
public int sumRange(int left, int right) {
int res = 0;
for (int i = left; i <= right; i++) {
res += nums[i];
}
return res;
}
}
这样,可以达到效果,但是效率很差,因为 sumRange 方法会被频繁调用,而它的时间复杂度是 O(N),其中 N 代表 nums 数组的长度。
这道题的最优解法是使用前缀和技巧,将 sumRange 函数的时间复杂度降为 O(1),说白了就是不要在 sumRange 里面用 for 循环,咋整?
直接看代码实现:
class NumArray {
// 前缀和数组
private int[] preSum;
/* 输入一个数组,构造前缀和 */
public NumArray(int[] nums) {
// preSum[0] = 0,便于计算累加和
preSum = new int[nums.length + 1];
// 计算 nums 的累加和
for (int i = 1; i < preSum.length; i++) {
preSum[i] = preSum[i - 1] + nums[i - 1];
}
}
/* 查询闭区间 [left, right] 的累加和 */
public int sumRange(int left, int right) {
return preSum[right + 1] - preSum[left];
}
}
核心思路是我们 new 一个新的数组 preSum 出来,preSum[i] 记录 nums[0…i-1] 的累加和,看图 10 = 3 + 5 + 2:
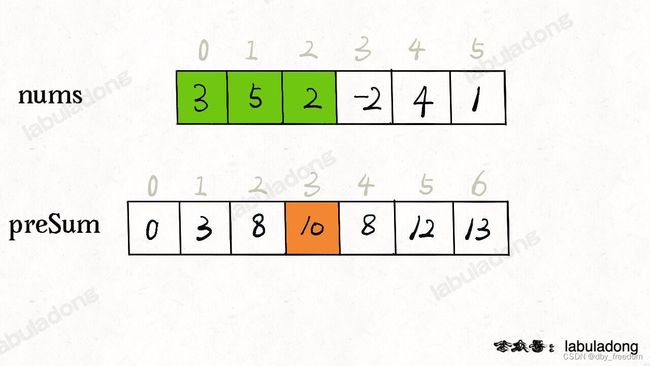
看这个 preSum 数组,如果我想求索引区间 [1, 4] 内的所有元素之和,就可以通过 preSum[5] - preSum[1] 得出。
这样,sumRange 函数仅仅需要做一次减法运算,避免了每次进行 for 循环调用,最坏时间复杂度为常数 O(1)。
这个技巧在生活中运用也挺广泛的,比方说,你们班上有若干同学,每个同学有一个期末考试的成绩(满分 100 分),那么请你实现一个 API,输入任意一个分数段,返回有多少同学的成绩在这个分数段内。
那么,你可以先通过计数排序的方式计算每个分数具体有多少个同学,然后利用前缀和技巧来实现分数段查询的 API:
int[] scores; // 存储着所有同学的分数
// 试卷满分 100 分
int[] count = new int[100 + 1]
// 记录每个分数有几个同学
for (int score : scores)
count[score]++
// 构造前缀和
for (int i = 1; i < count.length; i++)
count[i] = count[i] + count[i-1];
// 利用 count 这个前缀和数组进行分数段查询
接下来,我们看一看前缀和思路在二维数组中如何运用。
1.1 算法实践
二维矩阵中的前缀和
这是力扣第 304 题「二维区域和检索 - 矩阵不可变」,其实和上一题类似,上一题是让你计算子数组的元素之和,这道题让你计算二维矩阵中子矩阵的元素之和:
比如说输入的 matrix 如下图:
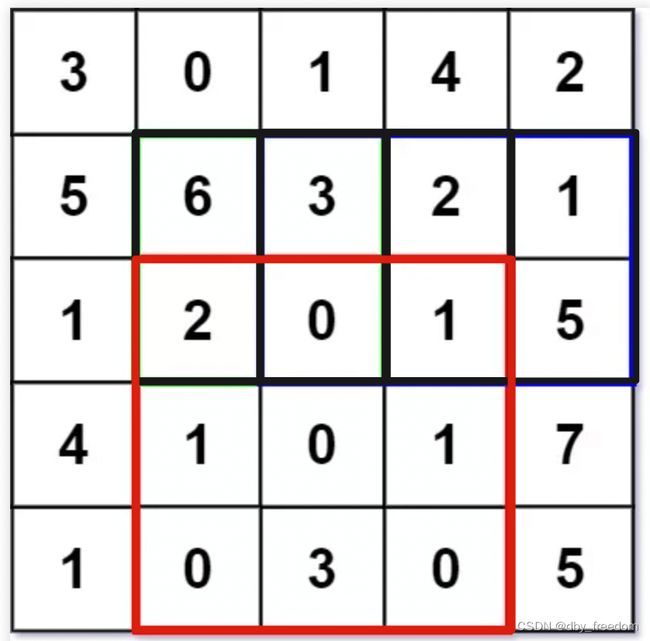
按照题目要求,矩阵左上角为坐标原点 (0, 0),那么 sumRegion([2,1,4,3]) 就是图中红色的子矩阵,你需要返回该子矩阵的元素和 8。
当然,你可以用一个嵌套 for 循环去遍历这个矩阵,但这样的话 sumRegion 函数的时间复杂度就高了,你算法的格局就低了。
注意任意子矩阵的元素和可以转化成它周边几个大矩阵的元素和的运算:
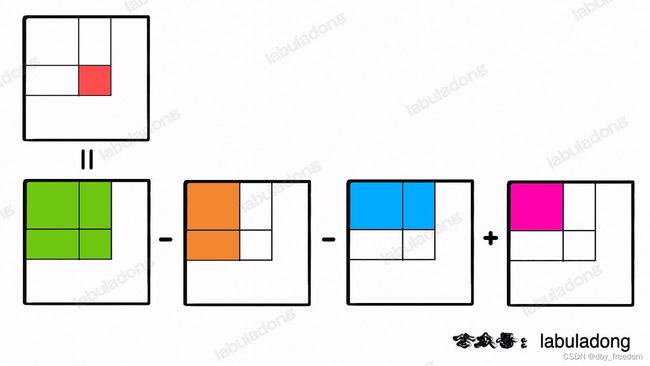
而这四个大矩阵有一个共同的特点,就是左上角都是 (0, 0) 原点。
那么做这道题更好的思路和一维数组中的前缀和是非常类似的,我们可以维护一个二维 preSum 数组,专门记录以原点为顶点的矩阵的元素之和,就可以用几次加减运算算出任何一个子矩阵的元素和:
class NumMatrix {
// 定义:preSum[i][j] 记录 matrix 中子矩阵 [0, 0, i-1, j-1] 的元素和
private int[][] preSum;
public NumMatrix(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
if (m == 0 || n == 0) return;
// 构造前缀和矩阵
preSum = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 计算每个矩阵 [0, 0, i, j] 的元素和
preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
}
}
}
// 计算子矩阵 [x1, y1, x2, y2] 的元素和
public int sumRegion(int x1, int y1, int x2, int y2) {
// 目标矩阵之和由四个相邻矩阵运算获得
return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
}
}
这样,sumRegion 函数的时间复杂度也用前缀和技巧优化到了 O(1),这是典型的「空间换时间」思路。
前缀和技巧就讲到这里,应该说这个算法技巧是会者不难难者不会,实际运用中还是要多培养自己的思维灵活性,做到一眼看出题目是一个前缀和问题。
除了本文举例的基本用法,前缀和数组经常和其他数据结构或算法技巧相结合,我会在 前缀和技巧高频习题 中举例讲解。
1.2 前缀和数组总结
- 前缀和数组适用场景:原始数组不会被修改的情况下,频繁查询某个区间的累加和;
- 前缀和数组优势:前缀和数组是典型的空间换时间的解决方案,将 前缀和 进行便利存储(O(n) 时空复杂度),然后 O(1) 时间复杂度得到最终数组区间和;
2. 差分数组
本文讲一个和前缀和思想非常类似的算法技巧「差分数组」,差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减。
比如说,我给你输入一个数组 nums,然后又要求给区间 nums[2…6] 全部加 1,再给 nums[3…9] 全部减 3,再给 nums[0…4] 全部加 2,再给…
一通操作猛如虎,然后问你,最后 nums 数组的值是什么?
常规的思路很容易,你让我给区间 nums[i…j] 加上 val,那我就一个 for 循环给它们都加上呗,还能咋样?这种思路的时间复杂度是 O(N),由于这个场景下对 nums 的修改非常频繁,所以效率会很低下。
这里就需要差分数组的技巧,类似前缀和技巧构造的 preSum 数组,我们先对 nums 数组构造一个 diff 差分数组,diff[i] 就是 nums[i] 和 nums[i-1] 之差:
int[] diff = new int[nums.length];
// 构造差分数组
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
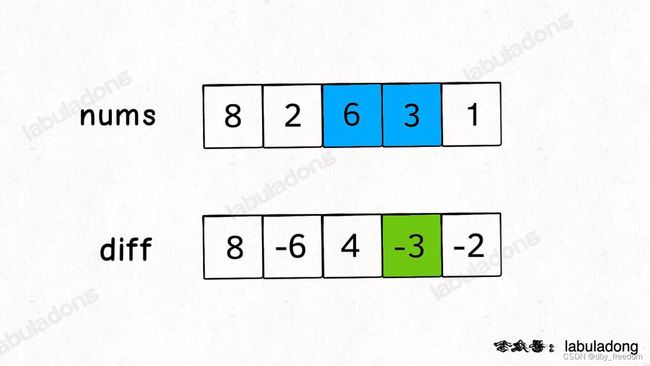
通过这个 diff 差分数组是可以反推出原始数组 nums 的,代码逻辑如下:
int[] res = new int[diff.length];
// 根据差分数组构造结果数组
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
这样构造差分数组 diff,就可以快速进行区间增减的操作,如果你想对区间 nums[i…j] 的元素全部加 3,那么只需要让 diff[i] += 3,然后再让 diff[j+1] -= 3 即可:
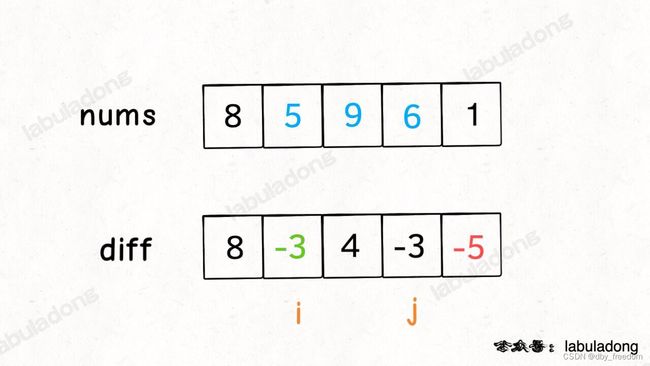
原理很简单,回想 diff 数组反推 nums 数组的过程,diff[i] += 3 意味着给 nums[i…] 所有的元素都加了 3,然后 diff[j+1] -= 3 又意味着对于 nums[j+1…] 所有元素再减 3,那综合起来,是不是就是对 nums[i…j] 中的所有元素都加 3 了?
只要花费 O(1) 的时间修改 diff 数组,就相当于给 nums 的整个区间做了修改。多次修改 diff,然后通过 diff 数组反推,即可得到 nums 修改后的结果。
现在我们把差分数组抽象成一个类,包含 increment 方法和 result 方法:
// 差分数组工具类
class Difference {
// 差分数组
private int[] diff;
/* 输入一个初始数组,区间操作将在这个数组上进行 */
public Difference(int[] nums) {
assert nums.length > 0;
diff = new int[nums.length];
// 根据初始数组构造差分数组
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
}
/* 给闭区间 [i, j] 增加 val(可以是负数)*/
public void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
/* 返回结果数组 */
public int[] result() {
int[] res = new int[diff.length];
// 根据差分数组构造结果数组
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
}
这里注意一下 increment 方法中的 if 语句:
public void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
当 j+1 >= diff.length 时,说明是对 nums[i] 及以后的整个数组都进行修改,那么就不需要再给 diff 数组减 val 了。
2.1 算法实践
首先,力扣第 370 题「区间加法」 就直接考察了差分数组技巧:

那么我们直接复用刚才实现的 Difference 类就能把这道题解决掉:
int[] getModifiedArray(int length, int[][] updates) {
// nums 初始化为全 0
int[] nums = new int[length];
// 构造差分解法
Difference df = new Difference(nums);
for (int[] update : updates) {
int i = update[0];
int j = update[1];
int val = update[2];
df.increment(i, j, val);
}
return df.result();
}
当然,实际的算法题可能需要我们对题目进行联想和抽象,不会这么直接地让你看出来要用差分数组技巧,这里看一下力扣第 1109 题「航班预订统计」:
函数签名如下:
int[] corpFlightBookings(int[][] bookings, int n)
这个题目就在那绕弯弯,其实它就是个差分数组的题,我给你翻译一下:
给你输入一个长度为 n 的数组 nums,其中所有元素都是 0。再给你输入一个 bookings,里面是若干三元组 (i, j, k),每个三元组的含义就是要求你给 nums 数组的闭区间 [i-1,j-1] 中所有元素都加上 k。请你返回最后的 nums 数组是多少?
Note
因为题目说的 n 是从 1 开始计数的,而数组索引从 0 开始,所以对于输入的三元组 (i, j, k),数组区间应该对应 [i-1,j-1]。
这么一看,不就是一道标准的差分数组题嘛?我们可以直接复用刚才写的类:
int[] corpFlightBookings(int[][] bookings, int n) {
// nums 初始化为全 0
int[] nums = new int[n];
// 构造差分解法
Difference df = new Difference(nums);
for (int[] booking : bookings) {
// 注意转成数组索引要减一哦
int i = booking[0] - 1;
int j = booking[1] - 1;
int val = booking[2];
// 对区间 nums[i..j] 增加 val
df.increment(i, j, val);
}
// 返回最终的结果数组
return df.result();
}
这道题就解决了。
还有一道很类似的题目是力扣第 1094 题「拼车」,我简单描述下题目:
你是一个开公交车的司机,公交车的最大载客量为 capacity,沿途要经过若干车站,给你一份乘客行程表 int[][] trips,其中 trips[i] = [num, start, end] 代表着有 num 个旅客要从站点 start 上车,到站点 end 下车,请你计算是否能够一次把所有旅客运送完毕(不能超过最大载客量 capacity)。
函数签名如下:
boolean carPooling(int[][] trips, int capacity);
比如输入:
trips = [[2,1,5],[3,3,7]], capacity = 4
这就不能一次运完,因为 trips[1] 最多只能上 2 人,否则车就会超载。
相信你已经能够联想到差分数组技巧了:trips[i] 代表着一组区间操作,旅客的上车和下车就相当于数组的区间加减;只要结果数组中的元素都小于 capacity,就说明可以不超载运输所有旅客。
但问题是,差分数组的长度(车站的个数)应该是多少呢?题目没有直接给,但给出了数据取值范围:
0 <= trips[i][1] < trips[i][2] <= 1000
车站编号从 0 开始,最多到 1000,也就是最多有 1001 个车站,那么我们的差分数组长度可以直接设置为 1001,这样索引刚好能够涵盖所有车站的编号:
boolean carPooling(int[][] trips, int capacity) {
// 最多有 1001 个车站
int[] nums = new int[1001];
// 构造差分解法
Difference df = new Difference(nums);
for (int[] trip : trips) {
// 乘客数量
int val = trip[0];
// 第 trip[1] 站乘客上车
int i = trip[1];
// 第 trip[2] 站乘客已经下车,
// 即乘客在车上的区间是 [trip[1], trip[2] - 1]
int j = trip[2] - 1;
// 进行区间操作
df.increment(i, j, val);
}
int[] res = df.result();
// 客车自始至终都不应该超载
for (int i = 0; i < res.length; i++) {
if (capacity < res[i]) {
return false;
}
}
return true;
}
至此,这道题也解决了。
最后,差分数组和前缀和数组都是比较常见且巧妙的算法技巧,分别适用不同的场景,而且是会者不难,难者不会。所以,关于差分数组的使用,你学会了吗?
更多经典的数组/链表技巧习题见 数组链表解题技巧精讲。
2.2 差分数组总结
- 差分数组适用场景:差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减;
- 个人体感,差分数组的适用范围更广一些,尤其是针对问题的抽象如公交车&航班问题;
参考文献
[1] 小而美的算法技巧:前缀和数组
[1] 小而美的算法技巧:差分数组