Spring Cloud【分组消费、为什么需要链路追踪 、Spring Cloud Sleuth是什么、微服务集成Sleuth实现链路打标】(十二)

目录
消息驱动_分组消费
分布式请求链路追踪_为什么需要链路追踪
分布式请求链路追踪_Spring Cloud Sleuth是什么
分布式请求链路追踪_微服务集成Sleuth实现链路打标
消息驱动_分组消费

什么是消息分组
比如在电商场景中,订单系统我们做集群部署,都会从RabbitMQ 中获取订单信息,那如果一个订单同时被两个服务获取到,那么就会造成数据错误,我们得避免这种情况。
注意: 我们可以使用Stream中的消息分组来解决。在Stream中处于同 一个group中的多个消费者是竞争关系,就能够保证消息只会被其中一个应用消费一次。
服务生产者工程8001
编写controller新增接口
// 发送分组消息
@PostMapping("/group")
public String sendGroupMessage(@RequestParam("body") String body) {
MyMessage myMessage = new MyMessage();
myMessage.setPayload(body);
// 生产消息
streamBridge.send("myGroup-out-0", myMessage);
return "SUCCESS";
}application.yml 配置
server:
port: 800
eureka:
instance:
# 实例名字
instance-id: stream-producer8001
client:
service-url:
# 指定单机eureka server地址
#defaultZone: http://localhost:7001/eureka/
defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/
spring:
application:
name: stream-producer
rabbitmq:
port: 5672
host: 192.168.66.101
username: guest
password: guest
cloud:
stream:
bindings:
# 广播消息
myBroadcast-out-0: # 生产者绑定名称,myBroadcast是自定义的绑定名称,out代表生产者,0是固定写法
destination: my-broadcast-topic
# 对应的真实的 RabbitMQ Exchange
# 分组消息
myGroup-out-0: # 生产者绑定名称
destination: my-group-topic # 对应的真实的 RabbitMQ Exchange消费者工程8002,8003
新增接收信息方法
// 消费分组消息
@Bean
public Consumer myGroup() {
// 方法名必须与生产消息时自定义的绑定名称一致
return message -> {
log.info("接收分组消息:{}", message.getPayload());
};
} application.yml 配置
server:
port: 8003
eureka:
instance:
# 实例名字
instance-id: stream-consumer8003
client:
service-url:
# 指定单机eureka server地址
#defaultZone: http://localhost:7001/eureka/
defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/
spring:
application:
name: stream-consumer
rabbitmq:
port: 5672
host: 192.168.66.101
username: guest
password: guest
cloud:
function:
# 定义消费者,多个用分号分隔,当存在大于1个的消费者时,不定义不会生效
definition: myBroadcast;myGroup
stream:
bindings:
# 广播消息
myBroadcast-in-0: # 消费者绑定名称,myBroadcast是自定义的绑定名称,in代表消费者,0是固定写法
destination: my-broadcast-topic # 对应的真实的 RabbitMQ Exchange
# 分组消息
myGroup-in-0: # 消费者绑定名称
destination: my-group-topic # 对应的真实的 RabbitMQ Exchange
group: my-group-1 # 同一分组的消费服务,只能有一个消费者消费到消息验证分组消息
将 Stream 工程 启动两个实例,调用发送分组消息接口,查看消息消费情况。
发送分组消息接口:GET http://localhost:8001/group?message=hello这是一条分组消息!

自动生成的 Exchange

自动生成的 Queue

分布式请求链路追踪_为什么需要链路追踪
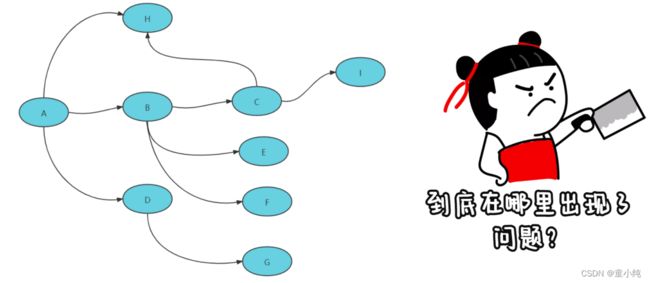
在这个微服务系统中,用户通过浏览器的 H5页面访问系统,这个用户请求会先抵达微服务网关组件,然后网关再把请求分发给各个微服务。所以你会发现,用户请求从发起到结束要经历很多个微服务的处理,这里面还涉及到消息组件的集成。

存在的问题:
1、服务之间的依赖与被依赖的关系如何能够清晰的看到?
2、出现异常时如何能够快速定位到异常服务?
3、出现性能瓶颈时如何能够迅速定位哪个服务影响的?

解决:
为了能够在分布式架构中快速定位问题,分布式链路追踪应运而生。将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服 务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
常见链路追踪技术有那些
市面上有很多链路追踪的项目,其中也不乏一些优秀的,如下:
Sleuth:SpringCloud 提供的分布式系统中链路追踪解决方案。很可惜的是阿里系并没有链路追踪相关的开源项目,我们可以采用Spring Cloud Sleuth+Zipkin来做链路追踪的解决方案。
zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统, 用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。该产品结合 spring-cloud-sleuth 使用较为简单, 集成很方便, 但是功能较简单。
pinpoint:韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入
skywalking:SkyWalking是本土开源的基于字节码注入的调用 链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
实时效果反馈
1.Spring Cloud Sleuth组件主要解决____问题。
A 注册中心
B 负载均衡
C 服务熔断
D 链路追踪
2.下列不是分布式链路追踪技术的是____。
A Sleuth
B SkyWalking
C Eureka
D Zipkin
分布式请求链路追踪_Spring Cloud Sleuth是什么

Spring Cloud Sleuth实现了一种分布式的服务链路跟踪解决方案, 通过使用Sleuth可以让我们快速定位某个服务的问题。简单来说, Sleuth相当于调用链监控工具的客户端,集成在各个微服务上,负责产生调用链监控数据。
注意:
Spring Cloud Sleuth只负责产生监控数据,通过日志的方式展示出来,并没有提供可视化的UI界面。
Sleuth核心概念

Span:基本的工作单元,相当于链表中的一个节点,通过一个唯一ID标记它的开始、具体过程和结束。我们可以通过其中存储的开始和结束的时间戳来统计服务调用的耗时。除此之外还可以获取 事件的名称、请求信息等。
Trace:一系列的Span串联形成的一个树状结构,当请求到达系统的入口时就会创建一个唯一ID (traceId),唯一标识一条链路。这个traceId始终在服务之间传递,直到请求的返回,那么就可以使用这个traceId将整个请求串联起来,形成一条完整的链路。

通过这些Sleuth 的特殊标记,我们就可以根据时间顺序,将一次服 务请求经过的调用节点都梳理出来,这样你就能迅速发现报错信息 发生在哪个阶段。这是使用Zipkin 生成的链路追踪的可视化信息。 你可以看出,每个服务调用都以时间先后顺序规整好了,红色的部分就是发生线上Exception的服务。

除了Trace和Span之外,Sleuth还有一个特殊的数据结构,叫做 Annotation,被用来记录一个具体的“事件”。我把Sleuth所支持的 四种事件做成了一个表格,你可以参考一下。

在这里我举个例子,来帮你理解怎么使用这四种事件。
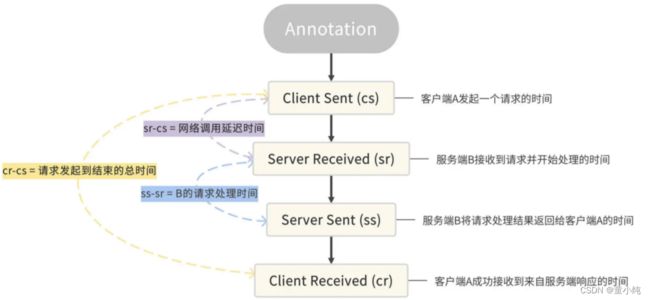
流程: 如果你用服务B的ss减去 sr,你就可以得到请求在服务B阶段的处理时间。如果用服务B的sr减去服务A的cs,就可以得到服务A 到服务B之间的网络调用延迟时间。如果用服务A的 cr减去 cs, 就可以得到当次请求从发起到结束所花费的总时间。
实时效果反馈
1.Spring Cloud Sleuth只负责_____数据。
A 服务熔断
B 负载均衡
C 产生监控数据
D 链路追踪
2.Spring Cloud Sleuth是通过____来实现链路追踪。
A 打标记
B 打日志
C 保存数据库
D 以上都是错误
分布式请求链路追踪_微服务集成Sleuth实现链路打标

整合Spring Cloud Sleuth其实没什么的难的,在这之前需要准备以下三个服务:
1、cloud-gateway-gateway9527:作为网关服务
2、cloud-consumer-feign-order80:订单微服务
3、cloud-provider-payment8001:支付微服务
三个服务的调用关系如下图:

流程: 客户端请求网关发起订单的请求,网关路由给订单服务,订单服务调用支付服务进行支付。
实现步骤
第一步,我们需要将 Sleuth 的依赖项添加到三个微服务的pom.xml文件
org.springframework.cloud
spring-cloud-starter-sleuth
第⼆步,我们打开微服务模块的 application.yml 配置⽂件,在配置 ⽂件中添加采样率和每秒采样记录条数。
spring:
sleuth:
sampler:
# 采样率的概率,100%采样
probability: 1.0
# 每秒采样数字最⾼为100
rate: 1000注意:
在配置文件里设置了⼀个 probability,它应该是⼀个 0 到 1 的 浮点数,用来表示采样率。我这⾥设置的 probability 是 1,就表示对请求进⾏ 100% 采样。如果我们把 probability 设置成⼩于 1 的数,就说明有的请求不会被采样。如果⼀个请求未被采样,那么它将不会被调⽤链追踪系统 Track 起来。
三个服务中调整日志级别
由于sleuth并没有UI界面,因此需要调整一下日志级别才能在控制台看到更加详细的链路信息。在三个服务的配置文件中添加以下配置:
## 设置openFeign和sleuth的日志级别为debug,方便查看日志信息
logging:
level:
org.springframework.cloud.openfeign: debug
org.springframework.cloud.sleuth: debug
演示接口完善
演示接口完善 http://localhost:9527/order/index

日志格式中总共有四个参数,含义分别如下:
第一个:服务名称
第二个:traceId,唯一标识一条链路
第三个:spanId,链路中的基本工作单元id