mysql+HeatWave测试
HeatWave简介
-
定位
HeatWave最佳场景定位于数据本身在mysql存储的,且渴望超大幅度提升查询速度的场景 -
简介
HeatWave 是一种分布式、可扩展、无共享( shared noting(SN))、基于内存、混合列式查询处理引擎,专为极致性能而设计。当您将 HeatWave 集群添加到 MySQL 数据库系统时会启用它。(混合列式存储:载入数据到heateWave集群后,数据分片存储到内存,片内数据列式存储,总体行式存储)
HeatWave 集群包括一个 MySQL 数据库系统节点和两个或多个 HeatWave 节点。MySQL DB System 节点有一个HeatWave 插件,负责集群管理,将数据加载到HeatWave 集群,查询调度,并将查询结果返回给MySQL DB System。HeatWave 节点将数据存储在内存中并处理分析查询。每个 HeatWave 节点都包含一个 HeatWave 查询处理引擎 ( RAPID)的实例。
所需的 HeatWave 节点数量取决于数据大小和将数据加载到 HeatWave 集群时实现的压缩量。HeatWave 集群最多支持 64 个节点。 -
架构
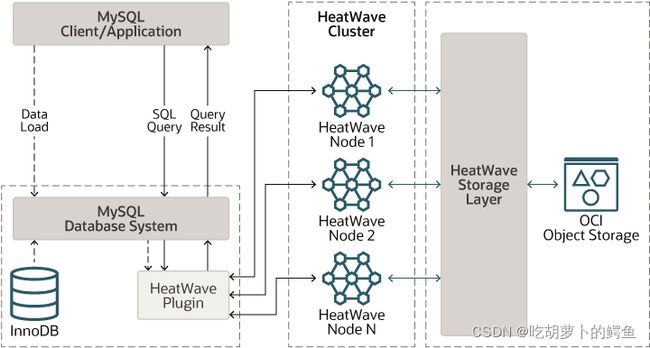
1.查询是从连接到 MySQL 数据库系统节点的 MySQL 客户端或应用程序发出的。客户端和应用程序不直接连接到 HeatWave。支持的查询会自动从 MySQL 数据库系统卸载到 HeatWave 以加速处理。结果将返回到 MySQL 数据库系统节点和发出查询的 MySQL 客户端或应用程序
2.将数据加载到 HeatWave 涉及在 MySQL 数据库系统上准备表并执行加载命令。准备表包括排除列、定义字符串列编码、添加数据放置键以及将表标记为辅助引擎候选等任务。(InnoDB是主要引擎。)
3.当 HeatWave 加载一个表时,数据被分片并分布在 HeatWave 节点之间。加载表后,表上的 DML 操作会自动传播到 HeatWave 节点。无需用户操作即可同步数据。
4.在对数据运行查询后,您可以使用 HeatWave Advisor 来优化您的工作负载。顾问分析您的数据和查询历史以提供字符串列编码和数据放置建议
架构
前期准备
oracle clound 上MDS(mysql数据库)+Heatewave,mysql版本从8.0.27-u1-cloud测试到8.0.27-u3-cloud(本文主要关注的版本区别在于与heatwave结合是否支持视图,u1不支持视图,从u2版本开始支持视图,截至u3版本,不支持视图多个子查询,)下图为无法进入到RAPID处理引擎的原因
+-----------------------------------------------+---------------------------------------------------------------------+
| QUERY | TRACE->'$**.Rapid_Offload_Fails' |
+-----------------------------------------------+---------------------------------------------------------------------+
| explain select * from viwe | [{"Reason": "This join order is not supported (num_selects = 3)."}] |
+-----------------------------------------------+---------------------------------------------------------------------+
1 row in set (0.03 sec)
不支持的语句示例:
-- 视图含有多个子查询
create view as
(select * from table1)
union all
(select * from table2)

数据迁移
数据从S3导入到orecle clound 的对象存储中

数据导入到mysql
数据本身是不在mysql中的,需要先建表然后,然后导入数据
导入数据到mysql表中命令:
mysqlsh --mysql 数据库用户名@数据库ip
util.importTable("/root/1.txt",{"schema":"slowtech","table":"cfg_costs_advanced",dialect:"csv-unix"})
语句支持本地文件和url ,schema指定数据库
mysql数据导入到HeatWave
- 先关闭需要导入表的第二引擎
alter table database_name.table_name secondary_engine=null;
-设置并行度
set session innodb_parallel_read_threads = 32;
加载到heatwave
alter table database_name.table_name secondary_load;
数据跨区域迁移
假设你要从oracle首尔的MDS集群导入到东京的MDS集群
-- 从MDS中导出
sudo yum -y install mysql-shell
mysqlsh --mysql 数据库用户名@数据库ip
--整个数据库导出
util.dumpInstance("MDS-export", {osBucketName: "桶名", threads: 16, ocimds: true, compatibility: ["strip_restricted_grants", "strip_definers", "ignore_missing_pks", "skip_invalid_accounts"]})
-- 选择数据库和表导出:
util.dumpTables("库名", [ "表1", "表2", "..."], "MDS-export-tables",{osBucketName: "桶名", threads: 16, ocimds: true, compatibility: ["strip_restricted_grants", "strip_definers", "ignore_missing_pks", "skip_invalid_accounts"]})
--后台导入到新MDS(上面语句可根据此格式修改为后台执行,数据量大建议后台)
nohup mysqlsh -h 新MDS的ip -u用户 -p密码 -e "util.loadDump(\"对象名\", {osBucketName: \"桶名\", osNamespace: \"cnepnlsifwhr\", threads: 16})" &
–
数据量比较大的话需要等待一下
SQL语句调试方法
-
查看执行计划
explain {sql语句};

如果看到Using secondary engine RAPID ,说明语句执行是用的HeatWave的RAPID引擎,反之就是用的innodb -
查看无法进入HeatWave原因
1.查看数据是否载入到HwatWave
select name,load_status from performance_schema.rpd_tables,performance_schema.rpd_table_id where rpd_tables.id=rpd_table_id.id;
2.查看无法进入的原因
SET SESSION optimizer_trace="enabled=on";
SET optimizer_trace_offset=-2;
desc select count(*),sleep(10) from sbtest.sbtest1;--替换为自己的SQL
SELECT QUERY, TRACE->'$**.Rapid_Offload_Fails' FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;

根据提示的原因做对应处理
- oom解决方案
官方解决方案:
Problem: You have encountered an out-of-memory error when executing a query.
Solution: HeatWave optimizes for network usage rather than memory. If you encounter out of memory errors when running a query, try running the query with the MIN_MEM_CONSUMPTION strategy by setting rapid_execution_strategy prior to executing the query:
SET SESSION rapid_execution_strategy = MIN_MEM_CONSUMPTION;
Also consider checking the size of your data by performing a node count estimate. If your data has grown substantially, you may require additional HeatWave nodes. For node count estimate instructions, refer to the MySQL Database Service User Guide.
Avoid or rewrite queries that produce a Cartesian product. For more information, see Running Queries.
--执行如下
SET SESSION rapid_execution_strategy = MIN_MEM_CONSUMPTION;
--后,再执行查询
- 解决视图无法执行
使用 with as
问题汇总
1、oracle测试账号限制比较多,不是很稳定,可能会遇到集群关闭后无法启动,需要设置好自动备份,最好阶段性手动备份,自动备份删除集群时也会被删除,
2.对依赖视图的查询支持不友好
测试结果
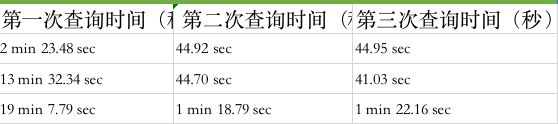
初次运行可能会比较久一点
其中第一条数据量为5000 inner join (10000000 union (10000000 left join 1700))字段数20左右,字段类型包括datatime verchar int,主要处理有deta_format,count,运行时间如下
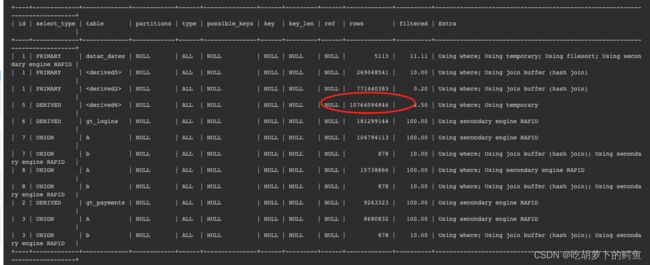
 笛卡尔积,出现oom,执行计划如下:
笛卡尔积,出现oom,执行计划如下:
参考链接
mysql官方文档
heatWave参考文档