数据库的聚合函数和窗口函数
1. 聚合函数
数据库的聚合函数是用于对数据集执行聚合计算的函数。它们将一组值作为输入,并生成单个聚合值作为输出。聚合函数通常与GROUP BY子句结合使用,以便在数据分组的基础上执行聚合操作。
1.1. 常用的聚合函数
-
COUNT():计算指定列或表达式的行数。 -
SUM():计算指定列或表达式的总和。 -
AVG():计算指定列或表达式的平均值。 -
MIN():找到指定列或表达式的最小值。 -
MAX():找到指定列或表达式的最大值。 -
GROUP_CONCAT()(MySQL)/STRING_AGG()(PostgreSQL):将指定列的值连接成一个字符串,并可选择添加分隔符。 -
STDDEV():计算指定列或表达式的标准差。 -
VARIANCE():计算指定列或表达式的方差。 -
FIRST():返回指定列或表达式的第一个非空值。 -
LAST():返回指定列或表达式的最后一个非空值。
2. 窗口函数
数据库的窗口函数是一类强大的函数,它们用于在查询结果的特定窗口或分区上执行计算、排序、聚合等操作,而不影响查询结果集本身。窗口函数通常与OVER子句一起使用,以定义窗口的范围和排序规则。
2.1. 常用的窗口函数
-
ROW_NUMBER():为结果集中的每一行分配一个唯一的行号。
-
RANK():根据指定的排序规则,为结果集中的每一行分配一个排名,相同值的行将获得相同的排名,并跳过相应数量的排名。
-
DENSE_RANK():类似于RANK()函数,但它不会跳过相同值的排名,而是按照顺序分配连续的排名。
-
NTILE(n):将结果集分成 n 个相等大小的桶(窗口),并为每个桶分配一个标识符。
-
LEAD(column, offset [, default]):获取当前行之后偏移量为 offset 的行的值。可以用于计算行与后续行之间的差值或趋势。
-
LAG(column, offset [, default]):获取当前行之前偏移量为 offset 的行的值。可以用于计算行与前一行之间的差值或趋势。
-
聚合函数(例如SUM()、AVG()、MIN()、MAX())也可以用作窗口函数。它们可以与OVER子句结合使用,以在窗口范围内计算聚合值。
2.2. 窗口函数具体讲解
窗口函数跨一组与当前行有某种关联的表行执行计算。这与可以使用聚合函数完成的计算类型相当。但是,窗口函数不会像非窗口聚合调用那样将行分组为单个输出行。相反,他们保留了各自的身份。在后台,窗口函数能够访问的不仅仅是查询结果的当前行。
下面是一个例子,展示了如何比较每个员工的工资和他或她所在部门的平均工资:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
| depname | empno | salary | avg |
|---|---|---|---|
| develop | 11 | 5200 | 5020.0000000000000000 |
| develop | 7 | 4200 | 5020.0000000000000000 |
| develop | 9 | 4500 | 5020.0000000000000000 |
| develop | 8 | 6000 | 5020.0000000000000000 |
| develop | 10 | 5200 | 5020.0000000000000000 |
| personnel | 5 | 3500 | 3700.0000000000000000 |
| personnel | 2 | 3900 | 3700.0000000000000000 |
| sales | 3 | 4800 | 4866.6666666666666667 |
| sales | 1 | 5000 | 4866.6666666666666667 |
| sales | 4 | 4800 | 4866.6666666666666667 |
前三个输出列直接来自表empsalary,表中的每一行对应一个输出行。第四列表示与当前行具有相同depname值的所有表行的平均值。(这实际上是与非窗口avg聚合相同的函数,但OVER子句导致它被视为窗口函数并跨窗口框架计算。)
窗口函数调用总是包含一个OVER子句,紧跟在窗口函数的名称和参数之后。这就是它在语法上区别于普通函数或非窗口聚合的地方。OVER子句准确地确定如何分割查询的行,以便由窗口函数进行处理。OVER中的PARTITION BY子句将行划分为组或分区,这些组或分区共享PARTITION BY表达式的相同值。对于每一行,窗口函数是在与当前行属于同一分区的行之间计算的。
您还可以使用OVER中的order by来控制窗口函数处理行的顺序。(窗口ORDER BY甚至不必匹配输出行的顺序。)下面是一个例子:
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
| depname | empno | salary | rank |
|---|---|---|---|
| develop | 8 | 6000 | 1 |
| develop | 10 | 5200 | 2 |
| develop | 11 | 5200 | 2 |
| develop | 9 | 4500 | 4 |
| develop | 7 | 4200 | 5 |
| personnel | 2 | 3900 | 1 |
| personnel | 5 | 3500 | 2 |
| sales | 1 | 5000 | 1 |
| sales | 4 | 4800 | 2 |
| sales | 3 | 4800 | 2 |
如图所示,rank函数使用ORDER BY子句定义的顺序,为当前行的分区中的每个不同的ORDER BY值生成一个数字排名。rank不需要显式参数,因为它的行为完全由OVER子句决定。
窗口函数考虑的行是由查询的FROM子句过滤的WHERE、GROUP by和HAVING子句(如果有的话)生成的“虚拟表”。例如,由于不满足WHERE条件而删除的行不会被任何窗口函数看到。查询可以包含多个窗口函数,这些窗口函数使用不同的OVER子句以不同的方式分割数据,但它们都作用于这个虚拟表定义的同一行集合。
我们已经看到,如果行排序不重要,可以省略ORDER BY。也可以省略PARTITION BY,在这种情况下,只有一个包含所有行的分区。
与窗口函数相关的另一个重要概念是:对于每一行,在其分区内都有一组行,称为其窗框。一些窗函数只作用于窗框的行,而不是整个分区。默认情况下,如果提供了ORDER By,则框架由从分区开始到当前行的所有行组成,加上根据ORDER By子句与当前行相等的任何后续行。如果省略ORDER BY,则默认帧包含分区中的所有行。下面是一个使用sum的例子:
SELECT salary, sum(salary) OVER () FROM empsalary;
| salary | sum |
|---|---|
| 5200 | 47100 |
| 5000 | 47100 |
| 3500 | 47100 |
| 4800 | 47100 |
| 3900 | 47100 |
| 4200 | 47100 |
| 4500 | 47100 |
| 4800 | 47100 |
| 6000 | 47100 |
| 5200 | 47100 |
上面,由于OVER子句中没有ORDER BY,因此窗口框架与分区相同,由于没有partition BY,分区就是整个表;换句话说,每个和都占用整个表,因此我们对每个输出行都得到相同的结果。但是如果我们添加一个ORDER BY子句,我们会得到非常不同的结果:
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
| salary | sum |
|---|---|
| 3500 | 3500 |
| 3900 | 7400 |
| 4200 | 11600 |
| 4500 | 16100 |
| 4800 | 25700 |
| 4800 | 25700 |
| 5000 | 30700 |
| 5200 | 41100 |
| 5200 | 41100 |
| 6000 | 47100 |
这里的总和是从第一个(最低)工资到当前工资,包括当前工资的任何重复(注意重复工资的结果)。
窗口函数只允许在查询的SELECT列表和ORDER BY子句中使用。它们在其他地方是被禁止的,比如GROUP BY、HAVING和WHERE子句。这是因为它们在逻辑上是在处理那些子句之后执行的。此外,窗口函数在非窗口聚合函数之后执行。这意味着在窗口函数的参数中包含聚合函数调用是有效的,反之则不然。
如果需要在执行窗口计算后对行进行筛选或分组,则可以使用子选择。例如:
SELECT depname, empno, salary, enroll_date
FROM
(SELECT depname, empno, salary, enroll_date,
rank() OVER (PARTITION BY depname ORDER BY salary DESC,
empno) AS pos
FROM empsalary
) AS ss
WHERE pos < 3;
上面的查询只显示内部查询中排名小于3的行。
当查询涉及多个窗口函数时,可以使用单独的OVER子句写出每个窗口函数,但是如果多个函数需要相同的窗口行为,那么这是重复的并且容易出错。相反,每个窗口行为都可以在WINDOW子句中命名,然后在OVER中引用。例如:
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
3. 数据库实例样式
3.1. 数据准备
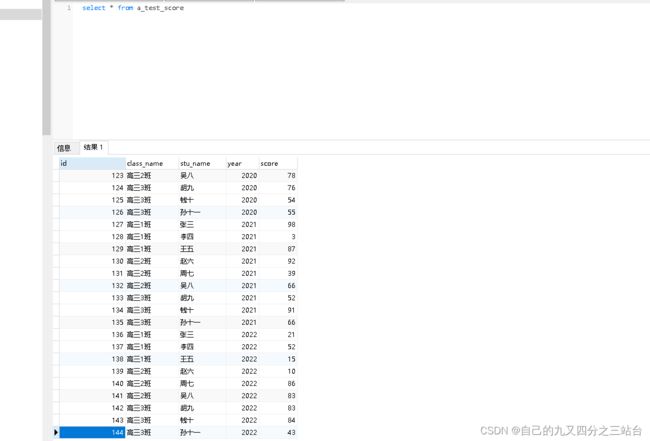
DROP TABLE IF EXISTS "a_test_score";
CREATE TABLE "a_test_score" (
"id" int4 NOT NULL DEFAULT nextval('a_test_score_id_seq'::regclass),
"class_name" varchar(20) COLLATE "pg_catalog"."default",
"stu_name" varchar(20) COLLATE "pg_catalog"."default",
"year" int4,
"score" numeric(255)
)
;
COMMENT ON COLUMN "a_test_score"."class_name" IS '班级名称';
COMMENT ON COLUMN "a_test_score"."stu_name" IS '用户名称';
COMMENT ON COLUMN "a_test_score"."year" IS '年份';
COMMENT ON COLUMN "a_test_score"."score" IS '成绩';
-- ----------------------------
-- Primary Key structure for table a_test_score
-- ----------------------------
ALTER TABLE "a_test_score" ADD CONSTRAINT "a_test_score_pkey" PRIMARY KEY ("id");
with
stu_info as (
select 1 as userid,'高三1班' as class_name,'张三' as stu_name
union all
select 2 as userid,'高三1班' as class_name,'李四' as stu_name
union all
select 3 as userid,'高三1班' as class_name,'王五' as stu_name
union all
select 4 as userid,'高三2班' as class_name,'赵六' as stu_name
union all
select 5 as userid,'高三2班' as class_name,'周七' as stu_name
union all
select 6 as userid,'高三2班' as class_name,'吴八' as stu_name
union all
select 7 as userid,'高三3班' as class_name,'胡九' as stu_name
union all
select 8 as userid,'高三3班' as class_name,'钱十' as stu_name
union all
select 9 as userid,'高三3班' as class_name,'孙十一' as stu_name
),
year_info as (
select 1 as id,2019 as year
union all
select 1 as id,2020 as year
union all
select 1 as id,2021 as year
union all
select 1 as id,2022 as year
)
insert into a_test_score(class_name,stu_name,year,score)
select stu_info.class_name,stu_name,year_info.year,(random()*100)::integer from year_info cross join stu_info order by year,stu_info.userid
3.2. 聚合函数和窗口函数的区别

3.3. 窗口函数和聚合函数的使用
3.3.1. 聚合函数sum、min、max的使用
select max(year),min(year),sum(score) from a_test_score;

3.4. 窗口函数的使用
- sum作为窗口函数
- 分组求和
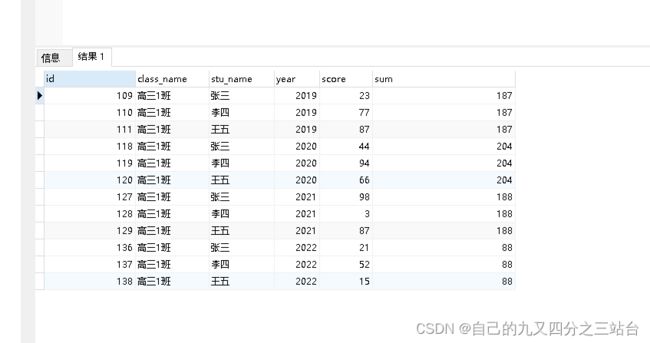
select *,sum(score) over(PARTITION by year) from a_test_score where class_name='高三1班';
- 分组求比例
select *,sum(score) over(PARTITION by year),score/(sum(score) over(PARTITION by year)) as score_bl_sum from a_test_score where class_name='高三1班';

以上写法同:
select t.*,(select sum(score) from a_test_score gt where gt.class_name=class_name and gt.year=year) from a_test_score t where class_name='高三1班';
- 故此可以实现以下表单汇总
- 基础统计信息,包括每一条学生信息和他的汇总聚合信息
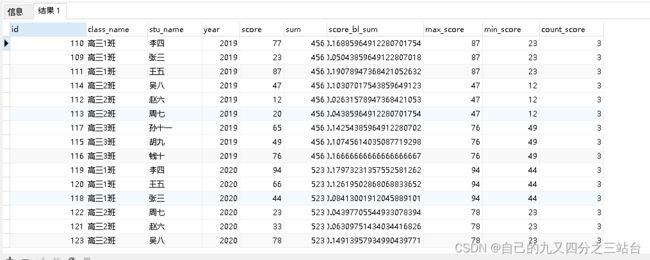
select *,
sum(score) over(PARTITION by year),score/(sum(score) over(PARTITION by year)) as score_bl_sum ,
max(score) over(PARTITION by class_name,year) as max_score,min(score) over(PARTITION by class_name,year) as min_score,count(score) over(PARTITION by class_name,year) as count_score
from a_test_score
order by "year",class_name;
- 获取每个班级,每一个年度 分数最高的记录信息
select * from
(
SELECT id,class_name,stu_name, year, score,
ROW_NUMBER() OVER (PARTITION BY class_name,year ORDER BY score DESC) AS rn
FROM a_test_score
order by "year",class_name
) t
where t.rn=1
同,可以使用以下sql
select * from
(
SELECT id,class_name,stu_name, year, score,
rank() OVER (PARTITION BY class_name,year ORDER BY score DESC) AS rn
FROM a_test_score
order by "year",class_name
) t
where t.rn=1
RANK和DENSE_RANK
RANK() 和 DENSE_RANK() 是数据库中常用的窗口函数,用于为结果集中的每一行分配排名值。这两个函数通常在需要对结果集中的行进行排名时使用,它们都可以结合 ORDER BY 子句来指定排序规则。
RANK() 函数为结果集中的每一行分配排名值,具有相同值的行将获得相同的排名,并且可能跳过后续的排名。也就是说,如果有多行具有相同的排序键值(例如成绩),它们将被分配相同的排名,并且下一个排名将被跳过。
假设:以下数据
| 学生姓名 | 成绩 |
|---|---|
| Alice | 90 |
| Bob | 85 |
| Charlie | 92 |
| David | 90 |
SELECT 学生姓名, 成绩, RANK() OVER (ORDER BY 成绩 DESC) AS 排名
FROM 表名;
| 学生姓名 | 成绩 | 排名 |
|---|---|---|
| Charlie | 92 | 1 |
| Alice | 90 | 2 |
| David | 90 | 2 |
| Bob | 85 | 4 |
DENSE_RANK() 函数也为结果集中的每一行分配排名值,但具有相同值的行将获得相同的排名,并且不会跳过后续的排名。也就是说,如果有多行具有相同的排序键值(例如成绩),它们将被分配相同的排名,并且下一个排名将紧接着。
SELECT 学生姓名, 成绩, DENSE_RANK() OVER (ORDER BY 成绩 DESC) AS 排名
FROM 表名;
| 学生姓名 | 成绩 | 排名 |
|---|---|---|
| Charlie | 92 | 1 |
| Alice | 90 | 2 |
| David | 90 | 2 |
| Bob | 85 | 3 |
- 其他窗口函数的使用
FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE()
FIRST_VALUE()函数
LAG(column, offset, default)函数返回当前行之前偏移量为 offset 的行的指定列的值。如果指定的偏移量超出了窗口范围,则可以提供 default 参数作为默认值。
LAST_VALUE()函数
LAG(column, offset, default)函数返回当前行之前偏移量为 offset 的行的指定列的值。如果指定的偏移量超出了窗口范围,则可以提供 default 参数作为默认值。
LAG()函数
LAG(column, offset, default)函数返回当前行之前偏移量为 offset 的行的指定列的值。如果指定的偏移量超出了窗口范围,则可以提供 default 参数作为默认值。
LEAD()函数
LAG(column, offset, default)函数返回当前行之前偏移量为 offset 的行的指定列的值。如果指定的偏移量超出了窗口范围,则可以提供 default 参数作为默认值。
NTH_VALUE()函数
NTH_VALUE(column, n)函数返回窗口内指定位置 n(从1开始)的行的指定列的值。
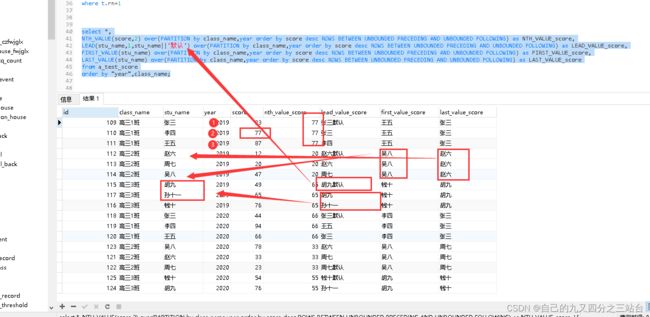
select *,
NTH_VALUE(score,2) over(PARTITION by class_name,year order by score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as NTH_VALUE_score,
LEAD(stu_name,1,stu_name||'默认') over(PARTITION by class_name,year order by score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as LEAD_VALUE_score,
FIRST_VALUE(stu_name) over(PARTITION by class_name,year order by score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as FIRST_VALUE_score,
LAST_VALUE(stu_name) over(PARTITION by class_name,year order by score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as LAST_VALUE_score
from a_test_score
order by "year",class_name;