5.2.tensorRT基础(2)-使用onnx解析器来读取onnx文件(源码编译)
目录
-
- 前言
- 1. ONNX解析器
- 2. libnvonnxparser.so
- 3. 源代码编译
- 4. 补充知识
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 基础-使用 onnx 解析器来读取 onnx 文件(源码编译)
课程大纲可看下面的思维导图
1. ONNX解析器
这节课我们来学习 onnx 解析器
onnx 解析器有两个选项,libnvonnxparser.so 或者 https://github.com/onnx/onnx-tensorrt(源代码)。使用源代码的目的,是为了更好的进行自定义封装,简化插件开发或者模型编译的过程,更加具有定制化,遇到问题可以调试。
源代码编译后其实就是 .so 文件,libnvonnxparser.so 如果出现问题,你也调试不了,使用源代码最大的好处就是方便调试,找到问题,分析上下文
我们来对比下杜老师写的两个 repo
infer 这个 repo 是通过调用 libonnxparser.so 这个库文件来解析 onnx 模型的,这个 repo 相对简单,上手难度较小
tensorRT_Pro 这个 repo 是编译修改好的源代码来解析 onnx 模型,这个 repo 难度相对较大,但是它更具定制化,写插件也更加的方便
2. libnvonnxparser.so
我们先来演示下 libnvonnxparser.so 解析 onnx 模型,从而完成模型的搭建工作
先使用 gen-onnx.py 导出一个简单的 onnx 模型,方便演示,代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.onnx
import os
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 1, 3, padding=1)
self.relu = nn.ReLU()
self.conv.weight.data.fill_(1)
self.conv.bias.data.fill_(0)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
# 这个包对应opset11的导出代码,如果想修改导出的细节,可以在这里修改代码
# import torch.onnx.symbolic_opset11
print("对应opset文件夹代码在这里:", os.path.dirname(torch.onnx.__file__))
model = Model()
dummy = torch.zeros(1, 1, 3, 3)
torch.onnx.export(
model,
# 这里的args,是指输入给model的参数,需要传递tuple,因此用括号
(dummy,),
# 储存的文件路径
"workspace/demo.onnx",
# 打印详细信息
verbose=True,
# 为输入和输出节点指定名称,方便后面查看或者操作
input_names=["image"],
output_names=["output"],
# 这里的opset,指,各类算子以何种方式导出,对应于symbolic_opset11
opset_version=11,
# 表示他有batch、height、width3个维度是动态的,在onnx中给其赋值为-1
dynamic_axes={
"image": {0: "batch", 2: "height", 3: "width"},
"output": {0: "batch", 2: "height", 3: "width"},
}
)
print("Done.!")
导出的 onnx 模型如下:
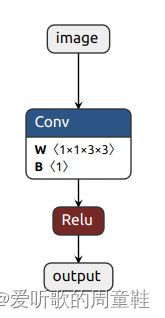
接下来就是使用 onnxparser 来解析 onnx 模型,在此之前你需要在 Makefile 文件中包含 libonnxparser.so 库文件,main.cpp 内容如下:
// tensorRT include
// 编译用的头文件
#include 这与我们之前自己搭建的模型编译的流程差不多,只不过是利用 liboonnxparser.so 解析器来编译,
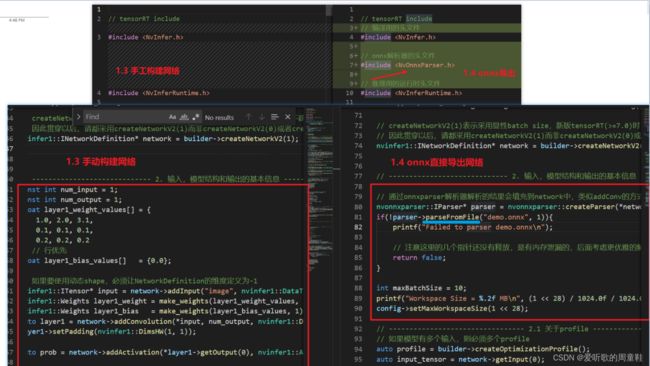
需要你包含 onnx 解析器的头文件 #include ,除此之外,网络的搭建不再使用 C++ API 完成,而是使用 onnxparser 解析,如下图所示:
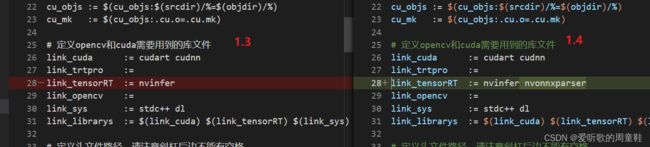
当然你在 Makefile 文件中也需要包含 libonnxparser.so 这个库文件
案例运行效果如下所示:
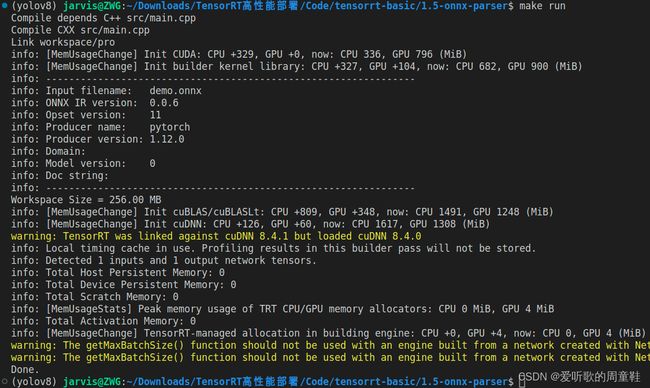
编译完成后会在 workspace 文件夹下生成 engine.trtmodel,是我们通过解析 onnx 模型文件编译生成的,相比于之前通过 C++ API 一层层搭建确实省事了,不过你会发现它的底层依旧是去调用 C++ 的 API 去构建网络的。
3. 源代码编译
我们再来了解如何用源代码解析 onnx 模型
在这个案例中我们同样提供了 gen-onnx.py 来产生一个简单 onnx,可以发现 src/onnx 目录下有 4 个文件,如下图所三,这四个文件是由 proto 文件生成的,具体生成可参考 onnx/make_pb.sh 文件
其实就是通过我们上节课程提到的 protobuf 的编译器 protoc 去编译两个 protoc 文件生成的,onnx 解析器就是靠这 4 个文件来完成 onnx 的解析的,因此这个是基础
上节课程我们不是提到过 onnx 的本质就是一个 protobuf 文件嘛,那么怎么去描述这个文件呢,主要是通过 onnx-ml.proto 和 onnx-operators-ml.proto 这两个 protobuf 文件来描述 onnx,而我们实际上想要使用其他类型的语言如 Python、C++ 来描述解释 onnx 文件,因此我们就需要 protoc 这个编译器和 onnx-ml.proto 和 onnx-operators-ml.proto 这两个 protobuf 文件来生成对应的 Python 或 C++,具体转换流程上节课程也提到过。
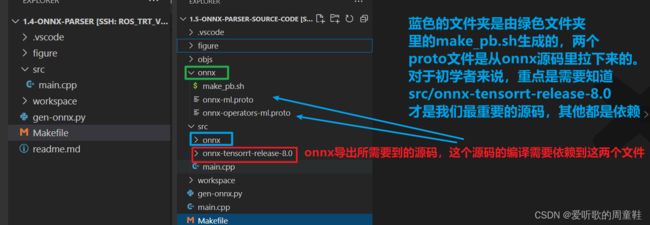
onnx-tensorrt-release-8.0 就是源代码 https://github.com/onnx/onnx-tensorrt 下载下来的东西,删除了一些不必要的文件,内容并没有去修改,可以看到源代码中也有一个 NvONNXParser.h。
接下来我们来看看 main.cpp 的差别,可以发现头文件修改了,使用的是源代码中的头文件,如下图所示,同时 Makefile 文件中也删除了对应的 libnvonnxparser.so 文件,其它的和上个案例一样

运行效果如下:
4. 补充知识
到此为止我们已经演示了使用 so 和源代码两种方式来解析 onnx 文件,我们拿到源代码知道解析是这么解析还不够,我们还要了解源代码怎么去使用它,怎么去修改它
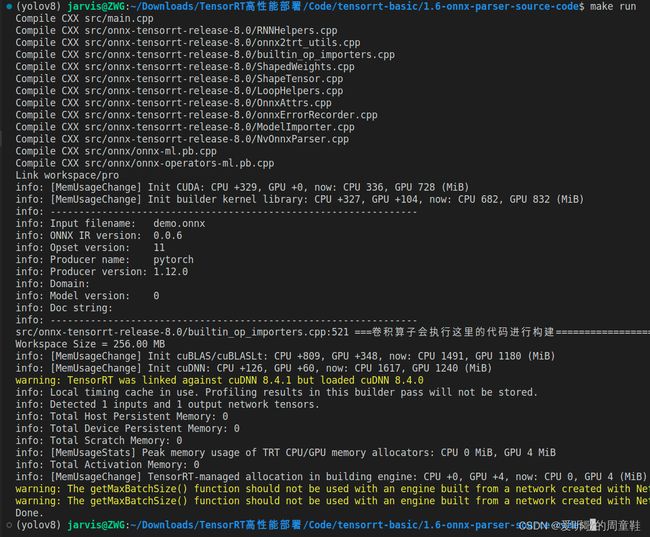
源代码虽然很多,看起来很复杂,但是我们大部分时间关注 builtin_op_importers.cpp 就行,所有 tensorRT 支持的算子都会出现在这个文件中,那我们解读这个文件的必要性就非常大。
我们在 Conv 算子中添加了一个打印语句,从 图3-3 的运行效果来看该打印语句正常打印了,说明修改如期进行。
DEFINE_BUILTIN_OP_IMPORTER(Conv) 看起来似乎有点奇怪,其实它是用宏定义来写的,对应 importConv( IImporterContext* ctx, ::onnx::NodeProto const& node, std::vector,它有一个 context,还有一个 node 作为输入,Conv 的输入 x 是 Tensor,而 Conv 的权重其实不是定义为 Tensor 而是定义为 Weights,因为它是来自 Initializer 里面的东西,是这么区分的
DEFINE_BUILTIN_OP_IMPORTER(Conv)
{
printf("src/onnx-tensorrt-release-8.0/builtin_op_importers.cpp:521 ===卷积算子会执行这里的代码进行构建==================\n");
if (inputs.at(1).is_tensor())
{
if (inputs.size() == 3)
{
ASSERT(
inputs.at(2).is_weights() && "The bias tensor is required to be an initializer for the Conv operator",
ErrorCode::kUNSUPPORTED_NODE);
}
// Handle Multi-input convolution
return convDeconvMultiInput(ctx, node, inputs, true /*isConv*/);
}
nvinfer1::ITensor* tensorPtr = &convertToTensor(inputs.at(0), ctx);
auto kernelWeights = inputs.at(1).weights();
nvinfer1::Dims dims = tensorPtr->getDimensions();
LOG_VERBOSE("Convolution input dimensions: " << dims);
ASSERT(dims.nbDims >= 0 && "TensorRT could not compute output dimensions of Conv", ErrorCode::kUNSUPPORTED_NODE);
const bool needToExpandDims = (dims.nbDims == 3);
if (needToExpandDims)
{
// Expand spatial dims from 1D to 2D
std::vector<int> axes{3};
tensorPtr = unsqueezeTensor(ctx, node, *tensorPtr, axes);
ASSERT(tensorPtr && "Failed to unsqueeze tensor.", ErrorCode::kUNSUPPORTED_NODE);
dims = tensorPtr->getDimensions();
}
if (kernelWeights.shape.nbDims == 3)
{
kernelWeights.shape.nbDims = 4;
kernelWeights.shape.d[3] = 1;
}
const int nbSpatialDims = dims.nbDims - 2;
// Check that the number of spatial dimensions and the kernel shape matches up.
ASSERT( (nbSpatialDims == kernelWeights.shape.nbDims - 2) && "The number of spatial dimensions and the kernel shape doesn't match up for the Conv operator.", ErrorCode::kUNSUPPORTED_NODE);
nvinfer1::Weights bias_weights;
if (inputs.size() == 3)
{
ASSERT(inputs.at(2).is_weights() && "The bias tensor is required to be an initializer for the Conv operator.", ErrorCode::kUNSUPPORTED_NODE);
auto shapedBiasWeights = inputs.at(2).weights();
// Unsqueeze scalar weights to 1D
if (shapedBiasWeights.shape.nbDims == 0)
{
shapedBiasWeights.shape = {1, {1}};
}
ASSERT( (shapedBiasWeights.shape.nbDims == 1) && "The bias tensor is required to be 1D.", ErrorCode::kINVALID_NODE);
ASSERT( (shapedBiasWeights.shape.d[0] == kernelWeights.shape.d[0]) && "The shape of the bias tensor misaligns with the weight tensor.", ErrorCode::kINVALID_NODE);
bias_weights = shapedBiasWeights;
}
else
{
bias_weights = ShapedWeights::empty(kernelWeights.type);
}
nvinfer1::Dims kernelSize;
kernelSize.nbDims = nbSpatialDims;
for (int i = 1; i <= nbSpatialDims; ++i)
{
kernelSize.d[nbSpatialDims - i] = kernelWeights.shape.d[kernelWeights.shape.nbDims - i];
}
nvinfer1::Dims strides = makeDims(nbSpatialDims, 1);
nvinfer1::Dims begPadding = makeDims(nbSpatialDims, 0);
nvinfer1::Dims endPadding = makeDims(nbSpatialDims, 0);
nvinfer1::Dims dilations = makeDims(nbSpatialDims, 1);
nvinfer1::PaddingMode paddingMode;
bool exclude_padding;
getKernelParams(
ctx, node, &kernelSize, &strides, &begPadding, &endPadding, paddingMode, exclude_padding, &dilations);
for (int i = 1; i <= nbSpatialDims; ++i)
{
ASSERT( (kernelSize.d[nbSpatialDims - i] == kernelWeights.shape.d[kernelWeights.shape.nbDims - i])
&& "The size of spatial dimension and the size of kernel shape are not equal for the Conv operator.",
ErrorCode::kUNSUPPORTED_NODE);
}
int nchan = dims.d[1];
int noutput = kernelWeights.shape.d[0];
nvinfer1::IConvolutionLayer* layer
= ctx->network()->addConvolutionNd(*tensorPtr, noutput, kernelSize, kernelWeights, bias_weights);
ASSERT(layer && "Failed to add a convolution layer.", ErrorCode::kUNSUPPORTED_NODE);
layer->setStrideNd(strides);
layer->setPaddingMode(paddingMode);
layer->setPrePadding(begPadding);
layer->setPostPadding(endPadding);
layer->setDilationNd(dilations);
OnnxAttrs attrs(node, ctx);
int ngroup = attrs.get("group", 1);
ASSERT( (nchan == -1 || kernelWeights.shape.d[1] * ngroup == nchan) && "Kernel weight dimension failed to broadcast to input.", ErrorCode::kINVALID_NODE);
layer->setNbGroups(ngroup);
// Register layer name as well as kernel weights and bias weights (if any)
ctx->registerLayer(layer, getNodeName(node));
ctx->network()->setWeightsName(kernelWeights, inputs.at(1).weights().getName());
if (inputs.size() == 3)
{
ctx->network()->setWeightsName(bias_weights, inputs.at(2).weights().getName());
}
tensorPtr = layer->getOutput(0);
dims = tensorPtr->getDimensions();
if (needToExpandDims)
{
// Un-expand spatial dims back to 1D
std::vector<int> axes{3};
tensorPtr = squeezeTensor(ctx, node, *tensorPtr, axes);
ASSERT(tensorPtr && "Failed to unsqueeze tensor.", ErrorCode::kUNSUPPORTED_NODE);
}
LOG_VERBOSE("Using kernel: " << kernelSize << ", strides: " << strides << ", prepadding: " << begPadding
<< ", postpadding: " << endPadding << ", dilations: " << dilations << ", numOutputs: " << noutput);
LOG_VERBOSE("Convolution output dimensions: " << dims);
return {{tensorPtr}};
}
我们可以简单解读下这段代码,首先它会判断你的第一个输入是不是 tensor,可以从 onnx 模型中看到 Conv 的第一个输入是 X 即 images,随后是 W 和 B,如下图所示
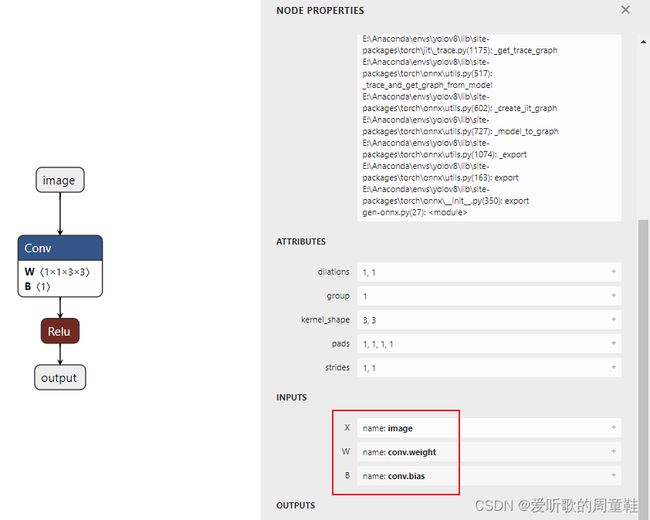
由于索引是从 0 开始,因此 1 号为 weight,上面有提到它在 onnx 中被解释为 weights 而不是 tensor,所以这行不成立,往下走;接下来会把 Conv 的第 0 号输入转化为 tensor,是把 onnx2trt::Tensor 转换为 nvinfer1::ITensor,后面就是各种维度的计算,最后执行 ctx->network()->addConvolutionNd(*tensorPtr, noutput, kernelSize, kernelWeights, bias_weights),还是跟我们手动加的方法一模一样,然后手动去设置 padding,stride 等等,最后输出 tensorPtr 也就是 layer 的 output。
所以说整个 onnx 解析器本质上还是在调用 C++ 的 API 来形成网络的结构,如果有不认识的算子,你完全可以在源代码中去添加解释它,转变为一种你认为 ok 的一种方式,然后加入到 tensorRT 中去。无论是插件还是什么也好,本质上都是这么做的,所以说你要关注的就算 builtin_op_importers.cpp 这个文件,那其他的文件你基本上不会去关注或者说很少去关注
总结
本节课程我们学习了使用 onnx 解析器来搭建模型,主要包括 libnvonnxparser.so 库文件和源代码两种方式,库文件使用方便,但是无法调试,而源代码虽然看起来复杂,但是可以实现更多定制化的操作,也可以调试分析上下文,库文件和源代码也对应着 infer 和 tensorRT_Pro 这两个 repo,下节课程我们将会从零开始带你从下载 onnx-tensorrt 到编译运行。