Redis高级(一):redis特点、redis优缺点、redis应用场景
Redis特点
一:速度快
1、 由c语言编写,更快解析语言代码。
2、 数据都是缓存在内存中,纯内存操作。
3、 采用单线程,避免了不必要的上下文切换和竞争条件,不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
4、 数据结构简单,对数据操作也简单。
5、 使用多路I/O复用模型,非阻塞I/O。
二:简单稳定
1、Redis是一个高性能(支持并发11万读8万写)的key-value存储系统。
2、Redis采用的是键值对的存储形式(key-value)
3、支持事务,操作都是原子性。
三:支持多语言
Redis 很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java,Python,Ruby,Erlang,PHP等,使用很方便。
Redis优缺点
优点:
1、 高并发读写的性能,Redis能读的速度是110000次/s,写的速度是81000次/s 。
2、 多种数据结构支持,如支持string,list,set,sorted set,hash。
3、 支持订阅发布功能(Pub/Sub) tip:游戏公告,推送广告(或者活动)消息。
3、 减轻数据库负担,有集合计算功能(优于普通数据库和同类别产品)。
4、 支持数据持久化,支持AOF和RDB两种持久化方式。
5、 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点:(后续详解)
1、缓存和数据库双写一致性问题
2、缓存雪崩问题
3、缓存击穿问题
4、缓存的并发竞争问题
Nosql比较
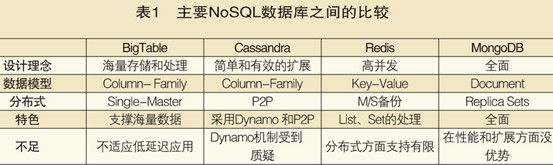
redis与memcache比较:
1、存储类型:memcached所有的值均是简单的字符串,而redis具有string,list,set,sorted set,hash等类型。
2、持久化:memcache数据是存储到内存里面,一旦断电,或重启,则数据丢失。redis数据也是存储到内存里面的,但是可以持久化,周期性的把数据给保存到硬盘里面,导致重启,或断电不会丢失数据。
3、数据量:memcahce一个键存储的数据最大是1M,而redis的一个键值,存储的最大数据量是1G的数据量(string类型512M)。
4、灾难恢复:memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复。
5、Redis支持数据的备份,即master-slave模式的数据备份。
平台使用
新浪微博 Redis
Goodle Bigtable
Amazon SimpleDB
淘宝数据平台 Tair
优酷视频 MongoDB
飞信空间 HandleSocket
视觉中国网站 MongoDB
应用场景
1、高性能适合当做缓存
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。 作为缓存使用时,一般有两种方式保存数据:
1、读取前,先去读Redis,如果没有数据,读取数据库,将数据拉入Redis。
2、插入数据时,同时写入Redis。
2、丰富的数据格式性能更高,应用场景丰富
Redis相比其他缓存,有一个非常大的优势,就是支持多种数据类型。
数据类型说明string字符串,最简单的k-v存储hashhash格式,value为field和value,适合ID-Detail这样的场景。list简单的list,顺序列表,支持首位或者末尾插入数据set无序list,查找速度快,适合交集、并集、差集处理sorted set有序的set
其实,通过上面的数据类型的特性,基本就能想到合适的应用场景了。
string——适合最简单的k-v存储,类似于memcached的存储结构,短信验证码,配置信息等,就用这种类型来存储。
hash ——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情,个人信息详情,新闻详情等。
list ——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省市区表、字典表等。因为list是有序的,适合根据写入的时间来排序,如:最新的列表,消息队列等。
set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set最牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人共同的好友等。
Sorted Set——是set的增强版本,增加了一个score参数,自动会根据score的值进行排序。比较适合类似于top 10等不根据插入的时间来排序的数据。
如上所述,虽然Redis不像关系数据库那么复杂的数据结构,但是,也能适合很多场景,比一般的缓存数据结构要多。了解每种数据结构适合的业务场景,不仅有利于提升开发效率,也能有效利用Redis的性能。
3、单线程可以作为分布式锁
谈到Redis和Memcached 的区别,大家更多的是谈到数据结构和持久化这两个特性,其实还有一个比较大的区别就是:
1、Redis 是单线程,多路复用方式提高处理效率。
2、Memcached 是多线程的,通过CPU线程切换来提高处理效率。
所以Redis单线程的这个特性,其实也是很重要的应用场景,最常用的就是分布式锁。
应对高并发的系统,都是用多服务器部署,每个技术框架针对数据锁都有很好的处理方式,如 .net 的lock,java 的synchronized,都能通过锁住某个对象来应对线程导致的数据污染问题。但是毕竟,只能控制本服务器的线程,分布式部署以后数据污染问题,就比较难处理了。
4、自动过期能有效提升开发效率
Redis针对数据都可以设置过期时间,这个特点也是大家应用比较多的,过期的数据清理无需使用方去关注,所以开发效率也比较高,当然,性能也比较高。最常见的就是:短信验证码、具有时间性的商品展示等。无需像数据库还要去查时间进行对比。因为使用比较简单,就不赘述了。
5、分布式和持久化有效应对海量数据和高并发
Redis初期的版本官方只是支持单机或者简单的主从,大多应用则都是自己去开发集群的中间件,但是随着应用越来越广泛,用户关于分布式的呼声越来越高,所以Redis 3.0版本时候官方加入了分布式的支持,主要是两个方面:
1、Redis服务器主从热备,确保系统稳定性
2、Redis分片应对海量数据和高并发
而且Redis虽然是一个内存缓存,数据存在内存,但是Redis支持多种方式将数据持久化,写入硬盘,所有,Redis数据的稳定性也是非常有保障的,结合Redis的集群方案,有的系统已经将Redis当做一种NoSql数据存储来适用。