Mysql实现按月份查询挂号统计数据(聚合函数的使用)
最近公司要实现一个通过年月来查询每个月的挂号统计(当日挂号,预约挂号),因为医院每个月都要来问我们这边一次,每次都去数据库查询太麻烦了,所以就需要开发一个查询挂号统计的接口。
前面用了很多种方法,要不就是数据不对,要不就是行不通
最后才决定使用聚合函数加上条件语句
SQL语句
SELECT LEFT(create_date,7) AS `yearMonth`,
SUM(CASE WHEN isday = 1 THEN 1 ELSE 0 END) AS drghCount,
SUM(CASE WHEN isday = 0 THEN 1 ELSE 0 END) AS yyghCount
FROM
toregister
WHERE
LEFT(create_date,7) BETWEEN '2022-01'
AND '2022-12'
GROUP BY
LEFT(create_date,7)
LFFT函数
LEFT 函数是 SQL 中常用的字符串函数,用于截取一个字符串的左边若干个字符,并返回截取到的字符串。
LEFT 函数的语法如下:
LEFT(string, length)
其中,string 表示要截取的字符串,length 表示要截取的字符长度。LEFT 函数将字符串 string 截取到 length 字符长度,返回截取后的字符串。
示例:
SELECT LEFT('Hello, World!', 5);
返回结果为 “Hello”,因为该函数将 “Hello, World!” 这个字符串的左边 5 个字符 “Hello” 进行截取。
上面SQL中的 LEFT(create_date,7) 就是用来截取 toregister 表中的 create_date 字段,截取的起始位置是 0,截取的长度是 7,表示将 create_date 字段按年月的格式进行展示,格式类似 2021-05。
CASE函数
MySQL的CASE函数可以根据条件表达式返回不同的结果。它类似于其他程序语言中的switch或if/else语句。CASE函数有两种语法形式:简单CASE函数和搜索CASE函数。
CASE case_expr
WHEN when_expr1 THEN result1
WHEN when_expr2 THEN result2
...
ELSE else_result
END
其中 case_expr 是要测试的表达式,when_expr1, when_expr2, ... 是不同的条件表达式,result1, result2, ... 是当条件表达式为真时要返回的结果,else_result 是所有条件表达式都不为真时要返回的结果。
下面是一个简单CASE函数的示例:
SELECT score,
CASE
WHEN score >= 90 THEN 'A'
WHEN score >= 80 THEN 'B'
WHEN score >= 70 THEN 'C'
WHEN score >= 60 THEN 'D'
ELSE 'F'
END AS grade
FROM student_score;
在这个示例中,我们使用了一个简单CASE函数来根据分数计算出一个等级。如果分数大于等于90,等级就是A,如果分数大于等于80,等级是B,以此类推。如果分数低于60,等级是F。我们还给这个结果集中的等级列起了一个别名叫做“grade”。
接下来是搜索CASE函数的语法形式:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE else_result
END
其中 condition1, condition2, ... 是用来测试的条件表达式,与简单CASE函数的 when_expr1, when_expr2, ... 相似。当一个条件表达式(condition1, condition2, …)为 TRUE 时,对应的 result1, result2, … 就会被返回。与简单CASE函数不同的是,搜索CASE函数不需要一个测试表达式,它只需要一系列条件表达式和结果。
下面是一个搜索CASE函数的示例:
SELECT grade,
CASE
WHEN grade LIKE 'A%' THEN 'Excellent'
WHEN grade LIKE 'B%' THEN 'Good'
WHEN grade LIKE 'C%' THEN 'Fair'
WHEN grade LIKE 'D%' THEN 'Poor'
ELSE 'Failing'
END AS result
FROM grades;
在这个示例中,我们使用了一个搜索CASE函数来给每个等级(比如A、B、C、D和F)赋一个结果(比如“Excellent”、“Good”、“Fair”、“Poor”和“Failing”)。如果等级以A开头,结果就是“Excellent”,以此类推。我们还给这个结果集中的结果列起了一个别名叫做“result”。
上面SQL中的 CASE WHEN isday = 0 THEN 1 ELSE 0 END 就是当isday这个字段的值等于0时这时候对应的值就是1,否则为0。
SUM函数
SUM 函数规则:
- SUM函数用于计算指定列的总和,可以用于数值列,如整数、小数等。
- SUM函数不计算NULL值,它会忽略包含NULL值的行。
- SUM函数返回的结果类型与被计算列的数据类型相同。
SUM 函数的语法如下:
select SUM(column_name) from table_name
其中,column_name 是一个列或一个表达式,可以是常量、字段或其他函数的组合,table_name为要从中检索的表名。SUM 函数的执行步骤如下:
- 扫描表中的每一行。
- 将指定列或表达式中的元素相加到累加器中。
- 返回累加器中的结果。
例如,假设有一个存储销售数据的表 Sales,表结构如下:
Sales (id, product_name, sales_amount, sales_date)
要计算所有销售额的总和,可以使用下面的 SQL 语句:
SELECT SUM(sales_amount)
FROM Sales;
上面SQL中SUM(CASE WHEN isday = 1 THEN 1 ELSE 0 END) AS drghCount,SUM(CASE WHEN isday = 0 THEN 1 ELSE 0 END) AS yyghCount就是统计当日挂号和预约挂号的总数的。
GROUP BY和HAVING用法
GROUP BY是一种SQL函数,通常与聚合函数(如SUM、COUNT、AVG等)一起使用,以对数据库表的数据进行分组并进行统计计算。
语法格式如下:
SELECT 列1, 列2, 聚合函数列3
FROM 表名
GROUP BY 列1, 列2
注意: 在使用GROUP BY时,除聚合函数列外,所有选定列都必须在GROUP BY子句中出现,如果列中只有聚合函数而没有普通列就不需要使用GROUP BY函数
如果要按产品名称和销售日期汇总销售额,可以使用 GROUP BY 子句,如下:
SELECT product_name, sales_date, SUM(sales_amount)
FROM Sales
GROUP BY product_name, sales_date;
上述语句将按产品名称和销售日期分组统计相应的销售额。
上面SQL中GROUP BY LEFT(create_date,7)根据创建的时间年月来进行分组
SELECT LEFT(create_date,7) AS `yearMonth`,
SUM(CASE WHEN isday = 1 THEN 1 ELSE 0 END) AS drghCount,
SUM(CASE WHEN isday = 0 THEN 1 ELSE 0 END) AS yyghCount
FROM
toregister
WHERE
LEFT(create_date,7) BETWEEN '2022-01'
AND '2022-12'
GROUP BY
LEFT(create_date,7)
上述SQL解释起来就是
1.先查询挂号表toregister
2.然后在执行WHERE条件语句,再使用LEFT(create_date,7)将创建时间中的年-月截取出来,使用BETWEEN条件进行数据筛选
3.再使用GROUP BY分组函数对LEFT(create_date,7)年-月进行分组
4.进行聚合函数的计算SUM(CASE WHEN isday = 1 THEN 1 ELSE 0 END) AS drghCount 先执行里面的条件语句:如果isday=1那么对应的值就为1,
否则为0(因为当日挂号的值我们设置的是1,预约挂号的值是0);SUM(CASE WHEN isday = 0 THEN 1 ELSE 0 END) AS yyghCount这个与前面的那个相反。
5.最后查询出select 里面的列,第一个参数使用LEFT(create_date,7)将创建时间中的年-月截取出来
得到的结果如下
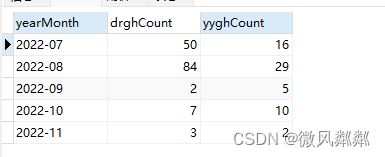
HAVING是SQL中用于对分组查询结果进行筛选的关键词。在使用GROUP BY对数据进行分组后,我们可以使用HAVING来进行条件过滤,只保留满足条件的分组数据。
例如,以下SQL查询语句可以获取每个部门中工资总额大于10000的员工数量和平均工资:
SELECT dept_id, COUNT(*) AS num_employees, AVG(salary) AS avg_salary
FROM employees
GROUP BY dept_id
HAVING SUM(salary) > 10000;
该查询首先使用GROUP BY对employees表中的数据按照dept_id进行了分组,然后使用HAVING对分组数据进行了过滤,只保留工资总额大于10000的数据。最终,查询结果返回了每个部门中工资总额大于10000的员工数量和平均工资。
竟然上面已经介绍了这么多了,不如我们把聚合函数也介绍了吧。
聚合函数
- SUM(column):返回列中所有值的总和。
- COUNT(column):返回列中所有值的计数。
- MAX(column):返回列中所有值的最大值。
- MIN(column):返回列中所有值的最小值。
- AVG(column):分会列中所有值的平均值
- GROUP_CONCAT(column):返回多行字符串(列)的合并结果。
sum函数已经描述过了,这里就不做赘述了
1.聚合函数规则
以下是聚合函数的一些常见规则:
- 聚合函数只能作用于一列数据,若要对多列数据进行聚合,可以使用GROUP BY语句。
- 聚合函数不能包含在WHERE语句中,这是因为WHERE语句用于过滤数据行,在数据行过滤之前评估聚合函数无意义。
- 若在SELECT中同时出现有普通列和聚合函数列,那么普通列必须包含在GROUP BY语句中,否则会报错。
- 在包含GROUP BY语句的SELECT语句中,HAVING子句用于返回满足特定条件的数据分组。HAVING子句是对聚合数据进行过滤,它是在GROUP BY子句执行之后对分组结果进行筛选,例如:HAVING SUM(column) > 1000。
- 在包含GROUP BY语句的SELECT语句中,若未指定ORDER BY子句,则查询结果的行顺序是无序的。
- 所有聚合函数只能用于一列数据,不能对多列进行操作。如果想对多列进行操作,可以分别使用聚合函数来进行对应的操作。
- 如果聚合函数在查询中使用了GROUP BY子句,它将根据分组进行对应的操作,并返回每个分组的值。
创建一张学生表用于后面的学习,以下的 SQL 语句创建一个名为 students 的表,其中包含 id、name、age 和 score 四个列:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `students`;
CREATE TABLE `students` (
`id` int(0) NOT NULL,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`age` int(0) NULL DEFAULT NULL,
`score` int(0) NULL DEFAULT NULL,
`grade` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
新增学生表数据
INSERT INTO `students` VALUES (1, 'Tom', 16, 85, 1);
INSERT INTO `students` VALUES (2, 'Jack', 15, 90, 1);
INSERT INTO `students` VALUES (3, 'Alice', 18, 78, 2);
INSERT INTO `students` VALUES (4, 'Bob', 19, 95, 3);
INSERT INTO `students` VALUES (5, 'Jenny', 18, 80, 3);
INSERT INTO `students` VALUES (6, 'David', 17, 82, 2);
INSERT INTO `students` VALUES (7, 'Helen', 17, 89, 1);
INSERT INTO `students` VALUES (8, 'Peter', 18, 75, 2);
SET FOREIGN_KEY_CHECKS = 1;
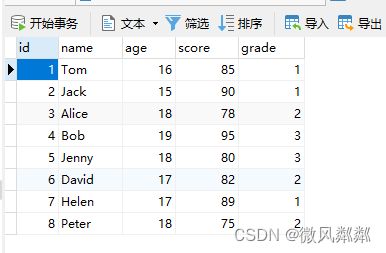
这里的年级就代表高中的一二三年级吧。
2.AVG函数
AVG函数规则:
- AVG函数用于计算指定列的平均值,可以用于数值列,如整数、小数等。
- AVG函数不计算NULL值,它会忽略包含NULL值的行。
- AVG函数返回的结果会根据列的数据类型而有所不同。对于整数列,返回的是整数结果;对于浮点数列,返回的是浮点数结果。
AVG函数的语法如下:
SELECT AVG(column_name) FROM table_name;
其中,column_name为要计算平均值的列名,table_name为要从中检索的表名。
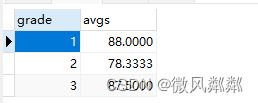
- 求出每个年级的平均成绩是多少?
SELECT s.grade,AVG(s.score) AS score FROM students s GROUP BY s.grade
- 求出所有学生的平均成绩是多少?
SELECT AVG(s.score) AS score FROM students s
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YxDB1h2B-1687946045131)(E:\PRD\Images\image-20230627143231246.png)]](http://img.e-com-net.com/image/info8/7220cbf0e0214eae9dacda1168652d13.jpg)
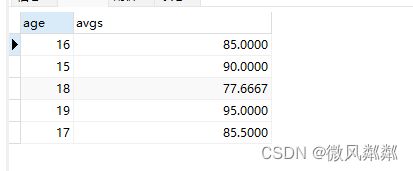
- 求出每个年龄段的平均成绩是多少?
SELECT s.age,AVG(s.score) AS score FROM students s GROUP BY s.age
3.COUNT函数
count函数规则:
- COUNT函数可以用于任意列,包括字符型、数值型、日期型等。
- COUNT函数有两种常用的用法:
- COUNT(column):计算指定列非空(不为NULL)的行数。
- COUNT(*):计算整个结果集的行数,包括包含NULL值的行。
- COUNT函数不会统计NULL值,只统计非空的行数。如果希望统计包括NULL值的行数,可以使用COUNT(*)。
- COUNT函数可以与DISTINCT关键字一起使用,以计算指定列的去重行数。例如:COUNT(DISTINCT column)。
- COUNT函数始终返回一个整数值,表示匹配条件的行数或去重行数。
COUNT函数的语法如下:
SELECT COUNT(column_name) FROM table_name WHERE condition;
其中,column_name是指定要统计的列名,table_name是指定的表名,condition是选取的条件语句。
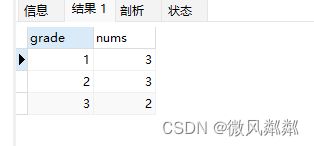
- 求出每个年级的学生数量是多少?
SELECT s.grade,COUNT(1) AS nums FROM students s GROUP BY s.grade
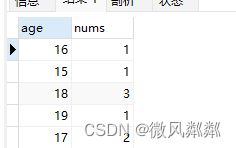
- 求出每个年龄段的学生数量是多少?
SELECT s.age,COUNT(1) AS nums FROM students s GROUP BY s.age
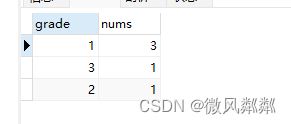
- 求出每个年级的分数大于80的学生数量是多少?
SELECT s.grade,COUNT(1) AS nums FROM students s WHERE s.score > 80 GROUP BY s.grade
4.MAX函数
MAX函数规则:
- MAX函数用于计算指定列的最大值,可以用于数值列、日期列、字符列等。
- MAX函数不考虑NULL值,它会忽略包含NULL值的行。
- MAX函数返回的结果类型与被计算列的数据类型相同。
MAX函数的语法如下:
SELECT MAX(column_name) FROM table_name;
其中,column_name为要计算最大值的列名,table_name为要从中检索的表名。
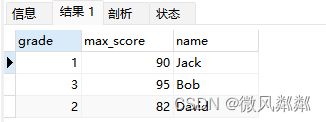
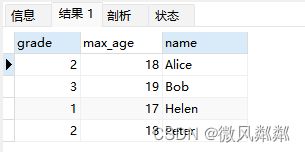
- 求出每个年级中分数最高的学生的姓名和分数?
SELECT grade, MAX(score) AS max_score, name
FROM students
WHERE (grade, score) IN (
SELECT grade, MAX(score)
FROM students
GROUP BY grade
)
GROUP BY grade, name;
- 求出每个年级中年龄最大的学生的姓名和年龄?
SELECT grade, MAX(age) AS max_age, name
FROM students
WHERE (grade, age) IN (
SELECT grade, MAX(age)
FROM students
GROUP BY grade
)
GROUP BY grade,name;
5.MIN函数
MIN函数规则:
- MIN函数用于计算指定列的最小值,可以用于数值列、日期列、字符列等。
- MIN函数不考虑NULL值,它会忽略包含NULL值的行。
- MIN函数返回的结果类型与被计算列的数据类型相同。
MIN函数的语法如下:
SELECT MIN(column_name) FROM table_name;
其中,column_name为要计算最小值的列名,table_name为要从中检索的表名。
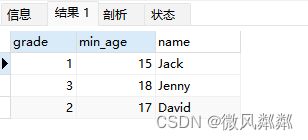
- 求出每个年级中分数最低的学生的姓名和分数?
SELECT grade, MIN(score) AS min_score, name
FROM students
WHERE (grade, score) IN (
SELECT grade, MIN(score)
FROM students
GROUP BY grade
)
GROUP BY grade,name;

- 求出每个年级中年龄最小的学生的姓名和年龄?
SELECT grade, MIN(age) AS min_age, name
FROM students
WHERE (grade, age) IN (
SELECT grade, MIN(age)
FROM students
GROUP BY grade
)
GROUP BY grade,name;
6.GROUP_CONCAT函数
GROUP_CONCAT函数的规则:
- GROUP_CONCAT函数用于将一个列的多个值拼接成一个字符串,并以指定的分隔符进行分隔。
- GROUP_CONCAT函数不考虑NULL值,它会忽略包含NULL值的行。
- GROUP_CONCAT函数返回的结果是一个字符串。
- GROUP_CONCAT函数只能用于一列数据,不能对多列进行拼接。如果想拼接多列的值,可以使用字符串连接函数(如CONCAT)和其他函数一起使用。
- 可以使用SEPARATOR关键字来指定拼接结果中的分隔符。如果未指定SEPARATOR关键字,默认使用逗号(,)作为分隔符。
- 如果GROUP_CONCAT函数在查询中使用了GROUP BY子句,它将根据分组进行拼接,并返回每个分组的拼接结果。
- 可以使用ORDER BY子句对拼接的结果进行排序。
- 可以使用DISTINCT关键字对拼接的结果进行去重。
GROUP_CONCAT函数的语法如下:
GROUP_CONCAT函数的语法通常如下:
GROUP_CONCAT([DISTINCT] expression [ORDER BY clause] [SEPARATOR 'separator'])
其中,关键字和参数的含义如下:
[DISTINCT]:可选项,表示对拼接结果进行去重处理。expression:要进行拼接的表达式或列名。[ORDER BY clause]:可选项,用于对拼接结果进行排序。可以指定排序的列名,也可以使用表达式。[SEPARATOR 'separator']:可选项,指定用于分隔拼接结果的符号或字符串,如果不指定,则默认使用逗号(,)作为分隔符。
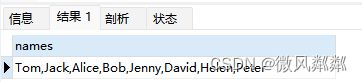
- 对students表中的name列进行拼接?
SELECT GROUP_CONCAT(s.name) AS names FROM students s
- 对students表中的grade,name,age,score列进行拼接,并按照这种(grade-name-age-score)方式进行拼接,并使用|符号作为分隔符?
SELECT GROUP_CONCAT(CONCAT(s.grade,'-',s.name,'-',s.age,'-',s.score) SEPARATOR '|') AS student_info FROM students s
CONCAT函数用于将多个字符串连接成一个字符串。它是一种常用的字符串函数,在不同的编程语言和数据库中有不同的语法。
SQL(结构化查询语言):
CONCAT(string1, string2, ...)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jRkQtDom-1687946045135)(E:\PRD\Images\image-20230628144239015.png)]](http://img.e-com-net.com/image/info8/e33ff4c02790418291d2db902271f711.jpg)
- 对students表中score列进行拼接,并按升序排序?
SELECT GROUP_CONCAT(s.score ORDER BY s.score ASC) AS scores FROM students s
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VRAyBKlA-1687946045135)(E:\PRD\Images\image-20230628144914289.png)]](http://img.e-com-net.com/image/info8/7290d430df2149cfae9537b2548a40be.jpg)
- 对students表中age列进行拼接,去除重复的值,并按降序排序,并使用分号作为分隔符?
SELECT GROUP_CONCAT(DISTINCT s.age ORDER BY s.age DESC SEPARATOR ';') AS ages FROM students s
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wkDBG9gm-1687946045136)(E:\PRD\Images\image-20230628145311367.png)]](http://img.e-com-net.com/image/info8/0ca4df8b69094e14b8fcbd348675da79.jpg)
7.更多聚合函数问题
在这之前,我们先多添加几条数据,以方便后面的问题
INSERT INTO students (id, name, age, score, grade)
SELECT (SELECT MAX(id) FROM students) + 1, 'Amy', 16, 90, 1 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 2, 'Michael', 15, 85, 1 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 3, 'Sophia', 19, 82, 2 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 4, 'Daniel', 18, 92, 2 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 5, 'Jessica', 17, 88, 1 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 6, 'Kevin', 18, 95, 3 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 7, 'Lily', 17, 83, 3 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 8, 'Ryan', 16, 87, 2 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 9, 'Mia', 19, 90, 1 UNION ALL
SELECT (SELECT MAX(id) FROM students) + 10, 'Jacob', 17, 80, 3;
- 求学生表中每个年级的学生数量,并筛选出学生数量大于平均学生数量的年级?
SELECT COUNT(1) FROM students s GROUP BY s.grade; #求每个年级的学生数量
每个年级的学生数量

最终实现,使用子查询先将每个年级的学生数量查询出来,然后在使用AVG函数进行求平均值,然后在筛选学生数量大于平均学生数量的年级。
SELECT
s.grade,
COUNT( 1 ) AS nums
FROM
students s
GROUP BY
s.grade
HAVING
nums > (
SELECT
AVG( nums1 )
FROM
( SELECT COUNT( 1 ) AS nums1 FROM students s GROUP BY s.grade ) s2)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-meuEnMA0-1687946045137)(E:\PRD\Images\image-20230628163637382.png)]](http://img.e-com-net.com/image/info8/ccc4db5a883045de85f04d164e768ed5.jpg)
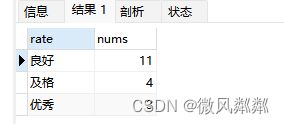
- 求学生表中每个分数段的学生数量,并按照学生数量降序排序?
先使用子查询将分数进行分段
SELECT r.rate,COUNT(rate) AS nums FROM (SELECT CASE
WHEN s.score BETWEEN 60 AND 80 THEN "及格"
WHEN s.score BETWEEN 81 AND 90 THEN "良好"
WHEN s.score BETWEEN 91 AND 100 THEN "优秀"
ELSE "不及格"
END AS rate FROM students s ) r
GROUP BY r.rate
ORDER BY nums DESC
- 求学生表中出现次数最多的年龄?
这个问题与问题一类似,就不做赘述了。
SELECT
age,
COUNT( age ) AS nums
FROM
students
GROUP BY
age
HAVING
nums = (
SELECT
MAX( nums1 )
FROM
( SELECT COUNT( age ) AS nums1 FROM students GROUP BY age ) AS s1)
