学好Elasticsearch系列-核心概念
本文已收录至Github,推荐阅读 Java随想录
文章目录
-
- 节点
- 角色
-
- master:候选节点
- data:数据节点
- Ingest:预处理节点
- ml:机器学习节点
- remote_ cluster_ client:候选客户端节点
- transform:转换节点
- voting_ only:仅投票节点
- Coordinating only node:协调节点
- 分片
-
- Shards主分片
- Replicas副本分片
- 集群
-
- 集群状态
- 健康值检查
-
- 返回参数说明
- 索引和文档
公司使用Elasticsearch的场景还是挺多的,打算开个新的坑,写一个关于Elasticsearch的系列,这是第一章。
这章主要是对Elasticsearch中的基本概念以及涉及到的一些名词做下讲解,能够对Elasticsearch有一个初步的认识。
节点
- 每个Elasticsearch节点实际上就是一个Java进程,就是一个Elasticsearch的实例。
- 一个节点 ≠一台服务器,也就是说我可以在一台服务器上启动多个Elasticsearch实例。
角色
集群节点角色可以在配置文件elasticsearch.yml中通过node.roles配置,如果配置了节点角色,那么该节点将只会执行配置的角色功能。
master:候选节点
所谓master节点,就是在主节点down机的时候,可以参与选举,取而代之的节点。举个例子:主节点好比班长,在班长不在的时候(主节点down机了),要选举出一个临时班长(master中选举)。master节点不仅有选举权还有被选举权。每个master节点主要负责索引创建、索引删除、追踪节点信息和决定分片分配节点等。
配置节点(下面节点配置方法同):
node.roles: [ master ]
data:数据节点
数据节点顾名思义就是存放数据的节点,数据节点负责存储文档数据和数据的CRUD操作。因此该节点是CPU和IO密集型,需要实时监控该节点资源信息,以免过载。数据节点又分为:data_content,data_hot,data_warm,data_code。
- data_content:数据内容节点,目录节点负责存储常量数据,且不随着时间的推移,改变数据的温层(hot、warm、cold)。且该节点的查询优先级是高于其它IO操作,所以该节点search和aggregations都会较快一些。
- data_hot:热节点,保存热数据,经常会被访问,用于存储最近频繁搜索和修改的时序数据。
- data_code:冷节点,保存冷数据,很少会被访问,当数据不再更新,那么可以将该数据移动到冷数据节点;冷数据节点用于存储只读,且访问频率较低的数据。该节点机器性能可以低一点。
- data_warm:温节点,介于热节点和冷节点之间(温节点是我自己翻译的),当数据访问频率下降,可以将其移动到温节点,温节点用于存储修改较少,但仍然有查询的数据。查询的频率肯定比热点节点要少。
Ingest:预处理节点
作用类似于Logstash中的Filter,Ingest其实就是管道的入口节点,比如说我们在做日志分析的时候,可以把日志输出的数据交给预处理节点做预处理。
ml:机器学习节点
机器学习节点负责处理机器学习相关请求。
remote_ cluster_ client:候选客户端节点
远程候选节点可以作为远程集群的客户端,主要负责搜索远程集群数据和同步两个集群间数据。
transform:转换节点
转换节点会进行一种特殊操作,通过特定聚集语句计算,然后将结果写到新的索引中。
voting_ only:仅投票节点
在master选举过程中,仅投票节点顾名思义就是仅仅投票,不会被选举为master。
Coordinating only node:协调节点
协调节点主要负责根据集群状态路由分发搜索,路由分发bulk操作。此外每个节点都是自带协调节点功能。
分片
分片的思想在很多分布式应用和海量数据处理的场所非常常见,通常来说,面对海量数据的存储,单个节点显得力不从心。通俗解释,分片就是将数据拆分多份,放到不同的服务器节点。
Elasticsearch里的分片为为2种:主分片和副本分片。
Shards主分片
es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。这里和索引分片的算法有关,因为是通过取模算法去判断分到哪,如果改变了就无法正常查询之前的索引。
当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。路由算法:shard = hash(routing) % number_of_primary_shards。这里的routing指的就是document的id,如果number_of_primary_shards在查询的时候取余发生的变化,无法获取到该数据。
Replicas副本分片
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
- 一个索引包含一个或多个分片,在7.0之前默认五个主分片,每个主分片一个副本;在7.0之后默认一个主分片。副本可以在索引创建之后修改数量,但是主分片的数量一旦确定不可修改,只能创建索引。
- 每个分片都是一个Lucene实例,有完整的创建索引和处理请求的能力。
- ES会自动在nodes上做分片均衡。
- 一个doc不可能同时存在于多个主分片中,但是当每个主分片的副本数量不为一时,可以同时存在于多个副本中。
- 每个主分片和其副本分片不能同时存在于同一个节点上,所以最低的可用配置是两个节点互为主备。
- 副本分片是不能直接写入数据的,只能通过主分片做数据同步。
- 增减节点时,shard会自动在nodes中负载均衡。
集群
上面所说的节点角色构成了整个集群。
集群状态
- Green:主/副分片都已经分配好且可用,集群处于最健康的状态100%可用。
- Yellow:主分片可用,但是至少有一个副本是未分配的。这种情况下数据也是完整的,但是集群的高可用性会被弱化。
- Red:至少有一个不可用的主分片。此时只是部分数据可以查询,已经影响到了整体的读写,需要重点关注。
健康值检查
//查看集群健康状况
_cat/health
_cluster/health
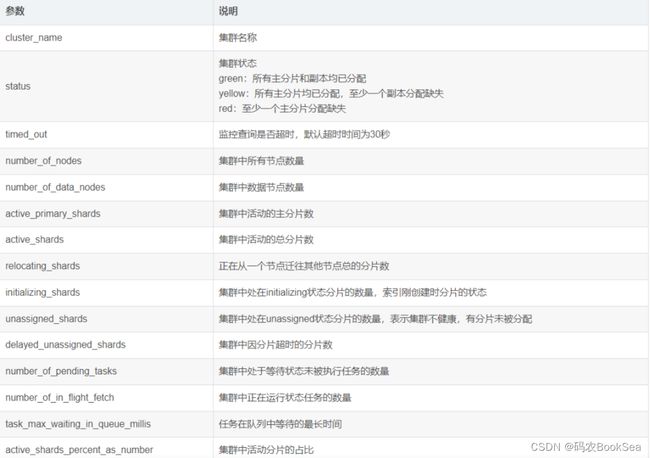
返回参数说明
示例:
{
"cluster_name" : "elastic-log-xxx",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 24,
"number_of_data_nodes" : 21,
"active_primary_shards" : 27777,
"active_shards" : 27804,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
索引和文档
es中索引类比为关系型数据库中的Table,在7.0版本之前index由若干个type组成,type实际上是文档的逻辑分类,而文档是es存储的最小单元。7.0及之后弱化了type的概念,7.x版本index只有一个type:_doc。文档(doc)可以类比为关系型数据库中的行,每个文档都有一个文档id。
本篇文章就到这里,感谢阅读,如果本篇博客有任何错误和建议,欢迎给我留言指正。文章持续更新。