SparkSQL知识点总结
一、SparkSql的概述
1.1 SparkSql是什么
1. SparkSql 是Spark生态体系中的一个基于SparkCore的SQL处理模块
2. 用途是处理具有结构化的数据文件的
3. 前身叫Shark,由于Shark是基于Hive,而Hive的发展限制了Shark的功能更新,因此该项目的负责人停止项目的发展,将相应的SQl处理功能独立出来,更名为SparkSQL
4. SparkSQL也是基于内存和RDD的
5. 本质是SparkSQL会在底层转成sparkcore程序

1.2 SparkSQL的特点
1. 融合特点:
将 SQL 查询与 Spark 程序无缝混合。 可以使用熟悉的sql在 Spark 程序中查询结构化数据
2. 统一的数据访问接口
可以使用统一的接口来访问各种数据源,比如avro,json,parquet,orc,hive以及jdbc等
3. hive集成
就是可以使用sparksql直接访问hive的数据
4. 提供了标准的jdbc和odbc连接接口
可以像其他语言一样,使用jdbc或者odbc连接RDBMS等
5. sparksql内置了优化器策略。列式存储,等加快查询速度。
1.3 SparkSQL的数据模型
1.3.0 RDD的回顾
1. RDD是弹性分布式数据集,是一个不存储数据的,不可变,可分区的,并行计算的数据集合
2. 有五大特征:
--分区列表: 每一个RDD在处理数据时,对于流经过来的数据都是进行分区的。数据都是有自己的分区号的。
换句话说,每一个RDD都是有固定的分区号的,比如有三个分区,就是0,1,2三个号码
--依赖关系: 当前的RDD存储这依赖关系
RDD4---算子3-->RDD3--算子2-->RDD2--算子1-->RDD1
--计算表达式: 接受的就是传入到算子中的匿名函数:比如 _*2
map(_*2)
--可选的分区器:PairRDD才会用到分区器
--可选的首选位置:用于计算的节点选择。
简单的说: 整个sparkcore的运算过程如下:
1. 先通过程序构建有向无环图,每个节点都是一个RDD. 此时RDD没有任何数据,只有属性初始化。
2. Task将程序发送到各个节点后,通过行动算子触发真正的程序运算,也就是数据流动。
3. 所有的RDD其实就是数据在各个节点(RDD)间不断的流动。最终计算出结果,这期间RDD不存储数据,只是临时经过而已。
1.3.1 DataFrame
1. RDD是一个弹性分布式数据集,DataFrame在RDD的基础上加了Schema的概念,这里的Schema就是表头。
扩展:Schema表示描述数据的数据,即可以认为是元数据,
DataFrame曾经就有个名字叫SchemaRDD
2. DataFrame在SparkCore基础上了提供了自己的API接口(其实就是各种算子),还提供SQL风格的写法
3. DataFrame可以理解为是一张二维表, 参考下图
4. DataFrame和RDD一样,不能存储数据,
简单来说:DataFrame就是对RDD的再次封装. 只不过多了一个Schema的概念
res0:RDD[String] = sc.textFile("D:/data/a.txt") //获取一个RDD
res1:DataFrame = res0.toDF() // 将RDD转成DataFrame数据结构
res1的具体的表结构:[value: string] //表示表头只有一个字段叫value,类型是String的数据结构
res2: RDD[Row] = res1.rdd // 将DataFrame转成RDD
通过上述代码可知:DataFrame就是一个特殊的额RDD. 特殊在泛型为Row的RDD。
其实:就是将每一行的对应的一个String解析成了多个字段,这一行的所有字段加起来构成一个Row对象。
假设RDD中的两行数据长这样.

那么DataFrame中的数据长这样

如果处理一个文件,文件的内容如下:
1001,zhangsan,23,f
1002,lisi,24,f
1003,wangwu,23,m
那么RDD的样子: RDD[String], 每一个String表示一行记录。
DataFrame的样子如下:
stuid:Int name:String age:Int gender:Chcar
1001 zhangsan 23 f
1002 lisi 24 f
1003 wangwu 23 m
value:String
1001,zhangsan,23,f
1.3.2 DataSet
1. DataSet 也是一种弹性分布式数据集,在RDD的基础上提供了强制类型检测和转换的功能
-- RDD封装的是多行字符串,而强制类型表示相当于RDD里封装的每一行记录都是一个类型的对象
2. DataSet 提供了自己的API接口,多种算子都和DataFrame一样,只不过在这基础上扩展了一些功能。
3. DataSet 在编译期间会检查类型是否匹配,如果不匹配,直接报错。而DataFrame在编译期间不检查,所以针对于程序员来说,体验度非常差。
假设RDD中的两行数据长这样

那么Dataset的数据模型可以理解为如下图所示:(每行数据是个Object)

var rdd1: RDD[String] = sc.textFile("D:....")
var df:DataFrame[Row] = rdd1.toDF() // 将RDD中的每一行记录都封装成Row对象
var rdd2: RDD[Student] = sc.makeRDD(List(Student(1001,"zhangsan"),Student(1002,"lisi")))
var df:DataFrame[Row] = rdd2.toDF() // 将RDD中的每一个Student又封装成Row对象,
因此 DataFrame的数据结构非常具有局限性。RDD的任何类型都会被描述成Row对象,非常单一。
因此SparkSql引入了DataSet数据模型, DataSet数据模型中的数据可以是任意的自定义类型。有点类似于JDBC里的结果集
String sql = "select ename,empno,sal,job from emp"
PreparedStatement ps = conn.preparestatement(sql)
ResultSet[Emp] rs = ps.executeQuery()
while(rs.next){
emp.getEmpno()
emp.getJob()
emp.getSal()
emp.getEname()
}
二、SparkSQL的核心编程
2.1 SparkSession的介绍
1. SparkSession是SparkSql的编程入口,就像SparkContext是SparkCore的编程入口一样。
2. 在Spark2.0版本以前,没有SparkSession的概念,而是有两个入口,一个是SqlContext,另一个是HiveContext,HiveContext是SqlContext的子类型,提供了与Hive有关的功能实现,比如row_number开窗函数等。
3. 在Spark2.0版本以后,将两个入口合并成一个入口,就是SparkSession.
4. SparkSession的获取方式有很多种,比如:
--(1) 使用构建器和SparkConf配合一起获取SparkSession对象
--(2) 使用构造器直接获取SparkSession对象
--(3) 通过连接hive获取SparkSession对象
--(4) 通过SparkContext获取SparkSession对象
--还有很多方法,可以自行百度学习。
window下的spark-shell
1. 将spark安装包解压到没有中文和空格的路径下。
D:\Users\uyihsgnaw\Documents\spark-2.2.3-bin-hadoop2.7
2. 配置环境变量,添加到Path
Path的值:追加路径bin。
D:\Users\uyihsgnaw\Documents\spark-2.2.3-bin-hadoop2.7\bin
3. 可以直接运行bin下的spark-shell指令
简单演示一下小案例:
scala> val df = spark.read.json("D:/data/emp.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, id: string ... 1 more field]
scala> df.show -- show是行动算子
+---+----+---------+
|age| id| name|
+---+----+---------+
| 23|1001|zhangsqan|
| 24|1002| lisi|
+---+----+---------+
scala> df.select("age").show
+---+
|age|
+---+
| 23|
| 24|
+---+
scala> df.select("name","age").show
+---------+---+
| name|age|
+---------+---+
|zhangsqan| 23|
| lisi| 24|
+---------+---+
scala> df.select($"age"+1).show
+---------+
|(age + 1)|
+---------+
| 24|
| 25|
+---------+
scala> df.select('age+1).show
+---------+
|(age + 1)|
+---------+
| 24|
| 25|
+---------+
scala> df.count
res15: Long = 2
2.2 DataFrame的应用
2.2.1 DataFrame的创建方式
1. 读外部设备的文件,返回DataFrame对象
2. 从RDD转换成DataFrame对象
3. 读取Hive中的表,返回DataFrame对象
4. 调用createDataFrame方法,返回DataFrame对象
2.2.2 两种编程风格的介绍
1) SQL风格编程
就是编写sql语句,底层翻译成相关算子进行执行
步骤如下:
步骤1): 获取DataFrame对象,然后使用相关方法描述成一张临时视图名称
DataFrame的四个方法如下:
createGlobalTempView: 创建全局临时视图, 意思就是整个SparkSql中都可以使用
如果已经存在,则提示错误
createOrReplaceGlobalTempView: 创建或替换全局临时视图
如果已经存在,就替换
createTempView: 创建当前会话的临时视图,
如果已经存在,则提示错误
createOrReplaceTempView: 创建或替换当前会话的临时视图
如果已经存在,就替换
步骤2) 使用SparkSession提供的Sql方法,来编写sql语句
案例演示:
scala> val df = spark.read.json("D:/data/emp.json")
scala> df.show
+----+------+-----+------+----------+---------+----+----+
|comm|deptno|empno| ename| hiredate| job| mgr| sal|
+----+------+-----+------+----------+---------+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600|
| 500| 30| 7521| WARD|1981-02-22| SALESMAN|7698|1250|
|null| 20| 7566| JONES|1981-04-02| MANAGER|7839|2975|
|1400| 30| 7654|MARTIN|1981-09-28| SALESMAN|7698|1250|
|null| 30| 7698| BLAKE|1981-05-01| MANAGER|7839|2850|
..........
scala> df.createTempView("emp") -- 创建当前会话的临时视图
scala> spark.sql("select * from emp") -- 没有行动算子
scala> spark.sql("select * from emp").show -- 调用show行动算子
+----+------+-----+------+----------+---------+----+----+
|comm|deptno|empno| ename| hiredate| job| mgr| sal|
+----+------+-----+------+----------+---------+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600|
| 500| 30| 7521| WARD|1981-02-22| SALESMAN|7698|1250|
|null| 20| 7566| JONES|1981-04-02| MANAGER|7839|2975|
|1400| 30| 7654|MARTIN|1981-09-28| SALESMAN|7698|1250|
|null| 30| 7698| BLAKE|1981-05-01| MANAGER|7839|2850|
|null| 10| 7782| CLARK|1981-06-09| MANAGER|7839|2450|
|null| 20| 7788| SCOTT|1987-04-19| ANALYST|7566|3000|
|null| 10| 7839| KING|1981-11-17|PRESIDENT|null|5000|
| 0| 30| 7844|TURNER|1981-09-08| SALESMAN|7698|1500|
|null| 20| 7876| ADAMS|1987-05-23| CLERK|7788|1100|
|null| 30| 7900| JAMES|1981-12-03| CLERK|7698| 950|
|null| 20| 7902| FORD|1981-12-02| ANALYST|7566|3000|
|null| 10| 7934|MILLER|1982-01-23| CLERK|7369|1300|
+----+------+-----+------+----------+---------+----+----+
scala> spark.sql("select empno,ename,sal,deptno from emp").show
+-----+------+----+------+
|empno| ename| sal|deptno|
+-----+------+----+------+
| 7369| SMITH| 800| 20|
| 7499| ALLEN|1600| 30|
| 7521| WARD|1250| 30|
| 7566| JONES|2975| 20|
| 7654|MARTIN|1250| 30|
| 7698| BLAKE|2850| 30|
| 7782| CLARK|2450| 10|
| 7788| SCOTT|3000| 20|
| 7839| KING|5000| 10|
| 7844|TURNER|1500| 30|
| 7876| ADAMS|1100| 20|
| 7900| JAMES| 950| 30|
| 7902| FORD|3000| 20|
| 7934|MILLER|1300| 10|
+-----+------+----+------+
scala> spark.sql("select empno,ename,sal,deptno from emp where deptno = 20").show
+-----+-----+----+------+
|empno|ename| sal|deptno|
+-----+-----+----+------+
| 7369|SMITH| 800| 20|
| 7566|JONES|2975| 20|
| 7788|SCOTT|3000| 20|
| 7876|ADAMS|1100| 20|
| 7902| FORD|3000| 20|
+-----+-----+----+------+
scala> spark.sql("select deptno,sum(sal),max(sal),min(sal),avg(nvl(sal,0)) from emp group by deptno").show
+------+--------+--------+--------+----------------------+
|deptno|sum(sal)|max(sal)|min(sal)|avg(nvl(emp.`sal`, 0))|
+------+--------+--------+--------+----------------------+
| 10| 8750| 5000| 1300| 2916.6666666666665|
| 30| 9400| 2850| 950| 1566.6666666666667|
| 20| 10875| 3000| 800| 2175.0|
+------+--------+--------+--------+----------------------+
scala> spark.sql("select * from emp where sal>(select sal from emp where ename='ALLEN')").show
+----+------+-----+-----+----------+---------+----+----+
|comm|deptno|empno|ename| hiredate| job| mgr| sal|
+----+------+-----+-----+----------+---------+----+----+
|null| 20| 7566|JONES|1981-04-02| MANAGER|7839|2975|
|null| 30| 7698|BLAKE|1981-05-01| MANAGER|7839|2850|
|null| 10| 7782|CLARK|1981-06-09| MANAGER|7839|2450|
|null| 20| 7788|SCOTT|1987-04-19| ANALYST|7566|3000|
|null| 10| 7839| KING|1981-11-17|PRESIDENT|null|5000|
|null| 20| 7902| FORD|1981-12-02| ANALYST|7566|3000|
+----+------+-----+-----+----------+---------+----+----+
scala> df.createGlobalTempView("t1") -- 创建全局的临时视图
-- 注意: 使用全局的临时视图时,访问要使用global_temp.来访问
scala> spark.sql("select * from global_temp.t1 where empno=7369").show
+----+------+-----+-----+----------+-----+----+---+
|comm|deptno|empno|ename| hiredate| job| mgr|sal|
+----+------+-----+-----+----------+-----+----+---+
|null| 20| 7369|SMITH|1980-12-17|CLERK|7902|800|
+----+------+-----+-----+----------+-----+----+---+
scala> spark.newSession.sql("select * from global_temp.t1").show -- 开启新会话进行访问
+----+------+-----+------+----------+---------+----+----+
|comm|deptno|empno| ename| hiredate| job| mgr| sal|
+----+------+-----+------+----------+---------+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600|
| 500| 30| 7521| WARD|1981-02-22| SALESMAN|7698|1250|
|null| 20| 7566| JONES|1981-04-02| MANAGER|7839|2975|
|1400| 30| 7654|MARTIN|1981-09-28| SALESMAN|7698|1250|
|null| 30| 7698| BLAKE|1981-05-01| MANAGER|7839|2850|
|null| 10| 7782| CLARK|1981-06-09| MANAGER|7839|2450|
|null| 20| 7788| SCOTT|1987-04-19| ANALYST|7566|3000|
|null| 10| 7839| KING|1981-11-17|PRESIDENT|null|5000|
| 0| 30| 7844|TURNER|1981-09-08| SALESMAN|7698|1500|
|null| 20| 7876| ADAMS|1987-05-23| CLERK|7788|1100|
|null| 30| 7900| JAMES|1981-12-03| CLERK|7698| 950|
|null| 20| 7902| FORD|1981-12-02| ANALYST|7566|3000|
|null| 10| 7934|MILLER|1982-01-23| CLERK|7369|1300|
+----+------+-----+------+----------+---------+----+----+
2) DSL风格编程
Domain-Special Language的简写,指的是特殊领域的语言风格,换言之就是使用各种算子来分析数据。
案例演示:
scala> val session = spark
scala> df.show
+----+------+-----+------+----------+---------+----+----+
|comm|deptno|empno| ename| hiredate| job| mgr| sal|
+----+------+-----+------+----------+---------+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600|
.........
scala> df.printSchema --打印df对应的schema
root
|-- comm: long (nullable = true)
|-- deptno: long (nullable = true)
|-- empno: long (nullable = true)
|-- ename: string (nullable = true)
|-- hiredate: string (nullable = true)
|-- job: string (nullable = true)
|-- mgr: long (nullable = true)
|-- sal: long (nullable = true)
scala> val session = spark
scala> df.show
+----+------+-----+------+----------+---------+----+----+
|comm|deptno|empno| ename| hiredate| job| mgr| sal|
+----+------+-----+------+----------+---------+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600|
| 500| 30| 7521| WARD|1981-02-22| SALESMAN|7698|1250|
|null| 20| 7566| JONES|1981-04-02| MANAGER|7839|2975|
|1400| 30| 7654|MARTIN|1981-09-28| SALESMAN|7698|1250|
|null| 30| 7698| BLAKE|1981-05-01| MANAGER|7839|2850|
|null| 10| 7782| CLARK|1981-06-09| MANAGER|7839|2450|
|null| 20| 7788| SCOTT|1987-04-19| ANALYST|7566|3000|
|null| 10| 7839| KING|1981-11-17|PRESIDENT|null|5000|
| 0| 30| 7844|TURNER|1981-09-08| SALESMAN|7698|1500|
|null| 20| 7876| ADAMS|1987-05-23| CLERK|7788|1100|
|null| 30| 7900| JAMES|1981-12-03| CLERK|7698| 950|
|null| 20| 7902| FORD|1981-12-02| ANALYST|7566|3000|
|null| 10| 7934|MILLER|1982-01-23| CLERK|7369|1300|
+----+------+-----+------+----------+---------+----+----+
scala> df.select("deptno","ename","sal","comm").show --select是一个可变参数的转换算子
+------+------+----+----+
|deptno| ename| sal|comm|
+------+------+----+----+
| 20| SMITH| 800|null|
| 30| ALLEN|1600| 300|
| 30| WARD|1250| 500|
| 20| JONES|2975|null|
| 30|MARTIN|1250|1400|
| 30| BLAKE|2850|null|
| 10| CLARK|2450|null|
| 20| SCOTT|3000|null|
| 10| KING|5000|null|
| 30|TURNER|1500| 0|
| 20| ADAMS|1100|null|
| 30| JAMES| 950|null|
| 20| FORD|3000|null|
| 10|MILLER|1300|null|
+------+------+----+----+
scala> df.select("deptno","ename").where("deptno=10").show
+------+------+
|deptno| ename|
+------+------+
| 10| CLARK|
| 10| KING|
| 10|MILLER|
+------+------+
scala> df.select("deptno","ename").where("deptno=10").where("ename='KING'").show
+------+-----+
|deptno|ename|
+------+-----+
| 10| KING|
+------+-----+
scala> df.select("deptno","ename").where("deptno=10 and ename = 'KING'").show
+------+-----+
|deptno|ename|
+------+-----+
| 10| KING|
+------+-----+
scala> df.select("deptno","ename").where("deptno=10").where("ename='KING'").show
+------+-----+
|deptno|ename|
+------+-----+
| 10| KING|
+------+-----+
-- 先执行select算子,然后对返回值执行分组查询,然后求聚合函数的操作,
-- 因为分组查询的返回值为RelationalGroupedDataset 而它只有右边这些方法agg avg count max mean min pivot sum
scala> df.select("deptno","ename","sal").groupBy("deptno").sum("sal").show
+------+--------+
|deptno|sum(sal)|
+------+--------+
| 10| 8750|
| 30| 9400|
| 20| 10875|
+------+--------+
scala> df.select("deptno","ename","sal").where("ename=7369").show
+------+-----+
|deptno|ename|
+------+-----+
| 10| KING|
+------+-----+
-- 注意:会报错。原因 sum返回的类型是DataFrame类型,而再次调用DataFrame类型时,是没有sum方法的,所以报错
scala> df.select("deptno","ename","sal").groupBy("deptno").sum("sal").sum("deptno").show()
2.2.3 DataFrame与RDD的转换
1)DataFrame=>RDD
scala> val df = session.read.json("D:/data/emp.json")
scala> val rdd1 = df.rdd -- 返回的RDD[Row]类型
-- 获取Row的数据如下
scala> rdd1.map(row=>{println(row.get(1))}).collect()
20
30
30
20
scala> rdd1.map(row=>{println(row.get(0))}).collect()
null
300
500
null
1400
null
null
null
null
0
null
null
null
null
res95: Array[Unit] = Array((), (), (), (), (), (), (), (), (), (), (), (), (), ())
scala> rdd1.map(row=>{println(row.get(0)+","+row.get(1)+","+row.get(2))}).collect()
null,20,7369
300,30,7499
500,30,7521
null,20,7566
1400,30,7654
null,30,7698
null,10,7782
null,20,7788
null,10,7839
0,30,7844
null,20,7876
null,30,7900
null,20,7902
null,10,7934
2)RDD=>DataFrame
scala> var rdd1 = sc.makeRDD(List(1,2,3,4,5,6))
scala> var df = rdd1.toDF
df: org.apache.spark.sql.DataFrame = [value: int]
scala> df.select("value").show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+-----+
scala> var df = rdd1.toDF("id") -- 指定列名
df: org.apache.spark.sql.DataFrame = [id: int]
scala> df.select("id").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+---+
scala> var rdd1 = sc.makeRDD(List(("1001","zhangsan","f"),("1002","lisi","f")))
rdd1: org.apache.spark.rdd.RDD[(String, String, String)] = ParallelCollectionRDD[189] at makeRDD at <console>:24
scala> var df = rdd1.toDF("id","name","gender")
df: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
scala> df.select("*").show
+----+--------+------+
| id| name|gender|
+----+--------+------+
|1001|zhangsan| f|
|1002| lisi| f|
+----+--------+------+
2.3 DataSet的应用
2.3.1 DataSet的创建方式
1. 要维护一个样例类
case class Student(id:Int, name:String, gender:Int, age:Int)
2. 在内存中维护几个样例类对象,存储到集合中
var students = List(
Student(1001,"zhangsan",0,23),
Student(1002,"lisi",1,24),
Student(1003,"zhangsi",0,25),
Student(1004,"zhaosan",1,23))
3. 调用createDataset方法获取Dataset对象
var ds = session.createDataset(students)
var ds = session.createDataset[Student](students)
案例测试:
scala> case class Student(id:Int, name:String, gender:Int, age:Int)
scala> var students = List(
Student(1001,"zhangsan",0,23),
Student(1002,"lisi",1,24),
Student(1003,"zhangsi",0,25),
Student(1004,"zhaosan",1,23))
scala> var ds = session.createDataset(students)
scala> ds.groupBy("age").sum().show
+---+-------+-----------+--------+
|age|sum(id)|sum(gender)|sum(age)|
+---+-------+-----------+--------+
| 23| 2005| 1| 46|
| 25| 1003| 0| 25|
| 24| 1002| 1| 24|
+---+-------+-----------+--------+
scala> ds.groupBy("age").max().show
+---+-------+-----------+--------+
|age|max(id)|max(gender)|max(age)|
+---+-------+-----------+--------+
| 23| 1004| 1| 23|
| 25| 1003| 0| 25|
| 24| 1002| 1| 24|
+---+-------+-----------+--------+
scala> ds.where("age=23").where("id=1001").show
+----+--------+------+---+
| id| name|gender|age|
+----+--------+------+---+
|1001|zhangsan| 0| 23|
+----+--------+------+---+
scala> case class Cat(id:Int,name:String,color:String)
defined class Cat
scala> val ds = session.createDataset(List(Cat(1,"m1","black"),Cat(2,"m2","black"),Cat(3,"m3","red")))
ds: org.apache.spark.sql.Dataset[Cat] = [id: int, name: string ... 1 more field]
scala> ds.groupBy("color").count
res107: org.apache.spark.sql.DataFrame = [color: string, count: bigint]
scala> ds.groupBy("color").count.show
+-----+-----+
|color|count|
+-----+-----+
| red| 1|
|black| 2|
+-----+-----+
2.3.2 DataSet与RDD之间的转换
- DataSet=>RDD
scala> case class Cat(id:Int,name:String,color:String)
defined class Cat
scala> val ds = session.createDataset(List(Cat(1,"m1","black"),Cat(2,"m2","black"),Cat(3,"m3","red")))
scala> var rdd1 = ds.rdd
rdd1: org.apache.spark.rdd.RDD[Cat] = MapPartitionsRDD[229] at rdd at <console>:29
scala> rdd1.foreach{case a:Cat => println(a.id+"\t"+a.name+"\t"+a.color)}
3 m3 red
2 m2 black
1 m1 black
2)RDD=>DataSet
scala> var rdd1 = sc.makeRDD(List(1,2,3,4,5,6))
scala> var ds = rdd1.toDS --toDS() 是无参方法,toDF是可变参数方法
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> ds.select("value").show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+-----+
scala> ds.select("*").show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+-----+
scala> var rdd1 = sc.makeRDD(List(("1001","zhangsan","f"),("1002","lisi","f")))
rdd1: org.apache.spark.rdd.RDD[(String, String, String)] = ParallelCollectionRDD[237] at makeRDD at <console>:24
scala> var ds = rdd1.toDS
ds: org.apache.spark.sql.Dataset[(String, String, String)] = [_1: string, _2: string ... 1 more field]
scala> ds.select("*").show
+----+--------+---+
| _1| _2| _3|
+----+--------+---+
|1001|zhangsan| f|
|1002| lisi| f|
+----+--------+---+
scala> ds.select("_1","_2").show
+----+--------+
| _1| _2|
+----+--------+
|1001|zhangsan|
|1002| lisi|
+----+--------+
scala> var rdd1 = sc.makeRDD(List(("1001","zhangsan","f"),("1002","lisi","f")))
-- 将集合里的每一个元组对象,封装成Cat对象
scala> import org.apache.spark.rdd.RDD
import org.apache.spark.rdd.RDD
scala> var rdd2:RDD[Cat] = rdd1.map(ele=>{Cat(ele._1.toInt,ele._2,ele._3)})
scala> var ds = rdd2.toDS
ds: org.apache.spark.sql.Dataset[Cat] = [id: int, name: string ... 1 more field]
scala> ds.select("id","name").show
+----+--------+
| id| name|
+----+--------+
|1001|zhangsan|
|1002| lisi|
+----+--------+
2.3.2 DataSet与DataFrame之间的转换
- DataSet=>DataFrame
scala> ds
res121: org.apache.spark.sql.Dataset[Cat] = [id: int, name: string ... 1 more field]
scala> ds.to
toDF toJSON toJavaRDD toLocalIterator toString
scala> var df = ds.toDF
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df.select("id","name").show
+----+--------+
| id| name|
+----+--------+
|1001|zhangsan|
|1002| lisi|
+----+--------+
2)DataFrame=>Dataset
scala> var df = ds.toDF --注意:df 有id,name,color三个字段
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
--定义一个样例类,属性一致
scala> case class Dog(id:Int,name:String,color:String)
defined class Dog
scala> var ds = df.as[Dog] -- 转使用as[类型名]
ds: org.apache.spark.sql.Dataset[Dog] = [id: int, name: string ... 1 more field]
三者之间的转换如图所示:
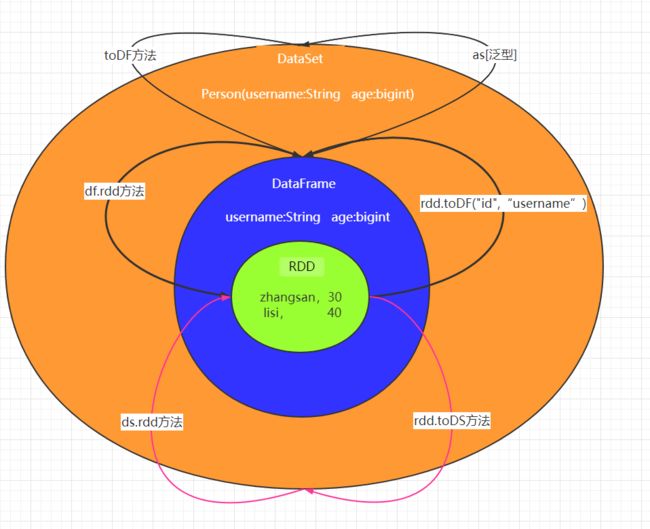
2.4 IDEA开发SparkSQL
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>spark_sz2102artifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.8scala.version>
<spark.version>2.2.3spark.version>
<hadoop.version>2.7.6hadoop.version>
<scala.compat.version>2.11scala.compat.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>${spark.version}version>
dependency>
dependencies>
project>
2.4.1 SparkSession的获取方式演示案例
package com.qf.sparksql.day02
import org.apache.hadoop.hive.conf.HiveConf
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SQLContext}
/**
* 研究一下SparkSession(sparksql的编程入口)的获取方式
* 1: 先研究低版本的SQLContext和HiveContext的获取
*/
object Spark_01_GetSparkSession {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setMaster("local[*]").setAppName("GetSparkSession")
var sparkContext = new SparkContext(conf)
/**
* 旧版本的SQLContext的获取
*/
val sqlContext = new SQLContext(sparkContext)
val df: DataFrame = sqlContext.read.json("data/emp.json")
df.show()
/**
* 旧版本的SQLContext的获取, 注意,需要配置hive的连接参数才可以。
* 如果连接成功,只需要调用hiveContext的table方法访问表即可。
*/
val hiveContext = new HiveContext(sparkContext)
val df1: DataFrame = hiveContext.table("sz2103.emp")
df1.show()
}
}
新版本的SparkSession的获取方式
package com.qf.sparksql.day02
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.{DataFrame, SQLContext, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 研究一下SparkSession(sparksql的编程入口)的获取方式
* 2: 获取SparkSession的方式
*/
object Spark_02_GetSparkSession_new {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setMaster("local[*]").setAppName("GetSparkSession")
/**
* SparkSession 是一个半生对象,可以直接使用,如果想要获取该对象,需要获取构建器对象,调用getOrCreate方法。
* 注意事项:
* 1. 必须指定master的配置
* --方式1: 可以调用master()来指定
* --方式2: 可以调用config(conf:SparkConf),传入spark配置对象来指定
* config有很多重载方法,用于指定配置参数和参数值。如config(key:String,value:*)
*/
//val spark: SparkSession = SparkSession.builder().master("local[*]").getOrCreate()
//val spark: SparkSession = SparkSession.builder().config(conf).config("topn",10).config("author","michael").conf.getOrCreate()
/**
* 2: 获取连接Hive的SparkSession对象
*/
val spark: SparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
}
}
2.4.2 两种编程风格的案例演示
1)SQL风格
package com.qf.sql.day02
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
object _02SQLStyle {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setMaster("local[*]").setAppName("TwoStyle")
val session = SparkSession.builder().config(conf).getOrCreate()
//获取DataFrame对象
val df: DataFrame = session.read.json("D:/input/user.json")
// df.show()
/**
* 1:SQL风格的演示
*
*
* -- 创建视图
* createTempView
* createOrReplaceTempView
*
* createGlobalTempView
* createOrReplaceGlobalTempView
*
* show算子:行动算子
* show(): 默认显示前20行,如果字段的值的长度超过20个,则截断显示
* show(truncate: Boolean)
* show(numRows: Int, truncate: Boolean)
* show(numRows: Int, truncate: Int)
* show(numRows: Int)
*
*/
df.createTempView("user")
// session.sql("select * from user").show()
// session.sql("select age,count(1),avg(age) from user group by age order by age desc").show()
// val sql = "select age,count(1),avg(age) from user group by age order by age limit 2"
// session.sql(sql).show()
//注意:sparksql中的sql风格,如果单独指定sql语句,一般使用以下方式,可以进行换行
val sql1 =
"""
|select age,
|count(1),
|avg(age),
|max(age) maxAge
|from user
|group by age
|order by age desc
|limit 2
|""".stripMargin
session.sql(sql1).show()
}
}
2)DSL风格
DSL风格,就是调用DataFame或者使Dataset的算子。 注意返回值类型,是否可以连续调用
package com.qf.sql.day02
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
object _03DSLStyle {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setMaster("local[*]").setAppName("TwoStyle")
val session = SparkSession.builder().config(conf).getOrCreate()
val df: DataFrame = session.read.json("D:/input/user.json")
/**
* 第二种风格: DSL风格, 即调用算子
*
* df的一些算子返回的如果依然是DataFrame,则可以连续调用。 但是要注意返回的DataFrame代表的数据是什么
*/
// df.select("age","username").where("age>30").show()
// df.groupBy("age").max("age").select("age").show
import session.implicits._
// df.groupBy("age").max("age").show
// df.select($"age",$"username").where($"age">20).show()
// df.select('age,'username).where('age > 20).show()
// df.select(new Column("age"),'username).where('age > 20).show()
// 别名的演示:
// df.select('age.as("myage"),'username.as("user")).where('age > 20).show()
// df.groupBy("age").max("age").select($"age".as("age1"),$"max(age)".as("maxAge")).show()
// df.selectExpr("age","username").where("age > 20").show()
// df.selectExpr("age as age1","username as user").where("age > 20").show()
//查询时,并计算
df.select("age + 1").show()
df.select($"age" + 1).show()
df.selectExpr("age + 1").where("age > 20").show()
session.stop()
}
}
3)DSL风格总结:
算子传入的参数,可以概括两种形式:
第一种传入的是字符串类型: 比如select(col:String,cols:String*)
注意:
-- 不能直接做运算
-- 不能使用别名
第二种传入的是Column类型: 比如select(col:Column,cols:Column*),该类型有以下几种写法
--1. 使用$符号,
select($"age",$"username")
--2. 使用一个单引号,
select(’age,‘username)
--3. 使用new Column,
select(new Column("age"),new Column("username"))
--4. 使用col,
select(col("age"),col("username"))
--5. 使用DataFrame变量,
select(df("age"),df("username"))
注意:
-- 可以直接做运算
-- 可以使用别名,需要在select算子中使用
-- 需要导入隐式转换操作:import sparkSession.implicits._
2.4.3 DataFrame和Dataset的创建方式
1)DataFrame的创建方式
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 创建DataFrame的方式有以下几种
* 1. 读外部设备的文件,返回DataFrame对象
* 2. 从RDD转换成DataFrame对象
* 3. 读取Hive中的表,返回DataFrame对象
* 4. 调用createDataFrame方法,返回DataFrame对象
*/
object Spark_06_CreateDataFrame_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession
.builder()
.config(conf)
//.enableHiveSupport() // 开启hive支持
.getOrCreate()
//因为后续的代码,不一定那地方就需要隐式转换操作,所以建议在获取编程入口时,直接写隐式转换
import sparkSession.implicits._
/**
* 第一种方式:读取外部文件,获取DataFrame
*/
//val frame: DataFrame = sparkSession.read.json("data/emp.json")
/**
* 第二种方式:从RDD转换成DataFrame对象
*/
val rdd1: RDD[String] = sparkSession.sparkContext.makeRDD(List("zhangsan", "lisi", "wangwu"))
/**
* toDF(): 将rdd转成DataFrame, 默认将rdd的元素转成一列,列名叫value.
* toDF(cols:String*), 用于指定转成DataFrame的列名。
*
*
*/
/*val df: DataFrame = rdd1.toDF()
df.select("value").show()*/
/* val df: DataFrame = rdd1.toDF("name")
df.select("name").show()*/
val rdd2: RDD[String] = sparkSession.sparkContext.makeRDD(List("1001,zhangsan,23", "1002,lisi,24", "1003,wangwu,23"))
val rdd3: RDD[(String,String,String)] = rdd2.map(line => {
val arr: Array[String] = line.split(",")
(arr(0),arr(1),arr(2))
})
val frame: DataFrame = rdd3.toDF("id", "name", "age")
frame.select("*").show()
/**
* 第三种方式:读取Hive中的表,返回DataFrame对象
* 需要开启hive支持,然后就可以使用SparkSession里提供的table方法读取hive表了
*/
//val frame1: DataFrame = sparkSession.table("sz2103.emp")
sparkSession.stop()
}
}
第四种方式的情况1:javaBean+反射
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 创建DataFrame的方式有以下几种
* 1. 读外部设备的文件,返回DataFrame对象
* 2. 从RDD转换成DataFrame对象
* 3. 读取Hive中的表,返回DataFrame对象
* 4. 调用createDataFrame方法,返回DataFrame对象
*
* 这里研究第四种的方式
* 可以细分为两种情况
* 第一种:使用javaBean+反射机制 注意,普通的值类型不可以
* 第二种:动态编程
*/
object Spark_07_CreateDataFrame_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
//因为后续的代码,不一定哪地方就需要隐式转换操作,所以建议在获取编程入口时,直接写隐式转换
import sparkSession.implicits._
//定义一个集合,存储多个Student类型
val list = List(new Student(1001,"zhangsan",23),
new Student(1002,"lisi",23),
new Student(1003,"wangwu",24),
new Student(1004,"zhaoliu",24))
/**
* 调用会话的createDataFrame(java.util.List<_>,beanClass)
* 第一个参数:java类型的集合
* 第二个参数:Class对象
*/
//该作用是将java类型的集合转成Scala类型的集合
import scala.collection.JavaConversions._
val frame: DataFrame = sparkSession.createDataFrame(list,classOf[Student])
frame.createTempView("student")
val sql =
"""
|select
| count(1) `学生个数`,
| max(age) `最大年龄`,
| min(age) `最小年龄`
|from student
|""".stripMargin
sparkSession.sql(sql).show()
sparkSession.stop()
}
}
package com.qf.sparksql.day02;
public class Student {
private int id;
private String name;
private int age;
public Student(){}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString(){
return id+","+name+","+age;
}
}
第四种方式的情况1:动态编程
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* 创建DataFrame的方式有以下几种
* 1. 读外部设备的文件,返回DataFrame对象
* 2. 从RDD转换成DataFrame对象
* 3. 读取Hive中的表,返回DataFrame对象
* 4. 调用createDataFrame方法,返回DataFrame对象
*
* 这里研究第四种的方式
* 可以细分为两种情况
* 第一种:使用javaBean+反射机制 注意,普通的值类型不可以
* 第二种:动态编程
*/
object Spark_08_CreateDataFrame_3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
//因为后续的代码,不一定哪地方就需要隐式转换操作,所以建议在获取编程入口时,直接写隐式转换
/** 使用动态编程的方式获取DataFrame, 其实就是使用StructField和StructType类型以及rowRDD构建DataFrame
*/
//构建一个RowRDD
val rdd1: RDD[Row] = sparkSession.sparkContext.makeRDD(
List(
Row(1001, "zhangsan", 23),
Row(1002, "lisi", 25),
Row(1003, "wangwu", 24),
Row(1004, "zhaoliu", 23)
))
/**
* StructField(name: String,dataType: DataType, nullable: Boolean = true,metadata: Metadata = Metadata.empty)
* 是一个用来描述字段的信息的样例类
* name: 字段名称
* dataType: 字段类型
* nullable: 是否可以为null
* metadata: 元信息
*/
val fields:Array[StructField] = Array(
StructField("id",IntegerType),
StructField("name",StringType),
StructField("age",IntegerType))
/**
* StructType(fields: Array[StructField])
* 是一个用来构建表头信息的样例类
* 参数: 描述列的一个集合或数组
*/
val schema:StructType =StructType(fields);
/**
* 调用createDataFrame(rowRDD: RDD[Row], schema: StructType)
* 第一个参数:泛型为Row的RDD
* 第二个参数:用于规定表头的元数据
*/
val df: DataFrame = sparkSession.createDataFrame(rdd1, schema)
df.show()
sparkSession.stop()
}
}
2)Dataset的创建方式
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 创建Dataset的方式和创建DataFrame的方式差不多。
* 1. 从RDD转换而来
* 2. 调用createDataset方法创建而来
*/
object Spark_09_CreateDataset_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
//第一种方式:rdd转换成Dataset
/* val rdd1: RDD[Int] = sparkSession.sparkContext.makeRDD(List(1, 2, 3, 4, 5))
val ds: Dataset[Int] = rdd1.toDS()
ds.show()*/
/**
* 第二种使用createDataset方法
*/
val ts = List(Teacher(1001,"lucy",23),
Teacher(1002,"lily",23),
Teacher(1003,"Tom",24))
val ds: Dataset[Teacher] = sparkSession.createDataset(ts)
//需求:按照年龄分组,查询每种年龄的个数
ds.groupBy("age").count().show()
sparkSession.stop()
}
case class Teacher(id:Int,name:String,age:Int)
}
2.4.4 RDD与DataFrame、Dataset之间的转换
- rdd => DF|DS
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* RDD 转 DataFrame 或者是Dataset
*/
object Spark_10_RDD_ToDFOrDS {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val rdd1: RDD[Int] = sparkSession.sparkContext.makeRDD(List(1, 2, 3, 4, 5))
println("--------------RDD===>DataFrame: RDD的元素只有一列的情况-----------------------")
val df1: DataFrame = rdd1.toDF("num")
df1.show()
println("--------------RDD===>Dataset: RDD的元素只有一列的情况-----------------------")
val ds: Dataset[Int] = rdd1.toDS()
ds.show()
val rdd2: RDD[(Int,String,Int)] = sparkSession.sparkContext.makeRDD(List((1,"lily",23),(1,"lucy",24),(1,"tom",25)))
println("--------------RDD===>DataFrame: RDD的元素只有多列的情况,只能使用元组-----------------------")
val df2: DataFrame = rdd2.toDF("id","name","age")
df2.show()
println("--------------RDD===>Dataset: RDD的元素是元组多列的情况下,列名是_1,_2,_3,....... -----------------------")
val ds1: Dataset[(Int, String, Int)] = rdd2.toDS()
ds1.select("_2").show()
val rdd3: RDD[Dog] = sparkSession.sparkContext.makeRDD(List(Dog("旺财", "白色"), Dog("阿虎", "棕色")))
println("--------------其他自定义类型的RDD===>DataFrame -----------------------")
val df3: DataFrame = rdd3.toDF()
df3.select("color").where("color='白色'").show()
println("--------------其他自定义类型的RDD===>Dataset -----------------------")
val ds3: Dataset[Dog] = rdd3.toDS()
ds3.where("color='棕色'").select("*").show()
sparkSession.stop()
}
case class Dog(name:String,color:String)
}
2)df=>rdd|ds
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.util.Date
/**
* DataFrame 转 RDD 或者是Dataset
*/
object Spark_11_DF_ToRDDOrDS {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val df: DataFrame = sparkSession.read.json("data/emp.json")
println("--------------DataFrame=>RDD 注意:RDD的泛型为Row-----------------------")
val rdd1: RDD[Row] = df.rdd
//rdd1.foreach(println)
rdd1.foreach(row=>println(row.get(0)+","+row.get(1)+","+row.get(2)))
println("--------------DataFrame=>Dataset 注意: 1 需要自定义一个类型与df中的列数以及类型进行匹配,2,使用as[自定义类型]进行转换即可-----------------------")
val ds: Dataset[E] = df.as[E]
ds.show()
sparkSession.stop()
}
case class E(empno:Long,ename:String,job:String,mgr:Long,hiredate:String,sal:Double,comm:Double,Deptno:Long)
}
3)ds=>rdd|df
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 或者是Dataset 转 RDD 或者是DataFrame
*/
object Spark_12_DS_ToRDDOrDF {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val emps = List(Employee(1001,"lucy","saleman",1000),
Employee(1002,"lily","saleman",1001),
Employee(1003,"john","saleman",1001),
Employee(1004,"michael","boss",1002))
val ds: Dataset[Employee] = sparkSession.createDataset(emps)
println("------------Dataset => RDD 两个数据模型的泛型是一样的-------------------------")
val rdd1: RDD[Employee] = ds.rdd
rdd1.foreach(emp=>println(emp.ename+"\t"+emp.job))
println("------------Dataset => DataFrame :本质就是将Dataset的泛型转成Row形式 ------------------------")
val df: DataFrame = ds.toDF()
df.where("mgr=1001").select("*").show()
sparkSession.stop()
}
case class Employee(empno:Long,ename:String,job:String,mgr:Long)
}
2.5 常用算子的演示
sparksql里的算子同样分两种类型,一种是转换算子,一种是行动算子。转换算子的作用是ds|df转成另外一种ds或者df;行动算子是用于触发程序执行的。
准备数据:emp.json文件
{"empno":7369,"ename":"SMITH","job":"CLERK","mgr":7902,"hiredate":"1980-12-17","sal":800,"comm":null,"deptno":20}
{"empno":7499,"ename":"ALLEN","job":"SALESMAN","mgr":7698,"hiredate":"1981-02-20","sal":1600,"comm":300,"deptno":30}
{"empno":7521,"ename":"WARD","job":"SALESMAN","mgr":7698,"hiredate":"1981-02-22","sal":1250,"comm":500,"deptno":30}
{"empno":7566,"ename":"JONES","job":"MANAGER","mgr":7839,"hiredate":"1981-04-02","sal":2975,"comm":null,"deptno":20}
{"empno":7654,"ename":"MARTIN","job":"SALESMAN","mgr":7698,"hiredate":"1981-09-28","sal":1250,"comm":1400,"deptno":30}
{"empno":7698,"ename":"BLAKE","job":"MANAGER","mgr":7839,"hiredate":"1981-05-01","sal":2850,"comm":null,"deptno":30}
{"empno":7782,"ename":"CLARK","job":"MANAGER","mgr":7839,"hiredate":"1981-06-09","sal":2450,"comm":null,"deptno":10}
{"empno":7788,"ename":"SCOTT","job":"ANALYST","mgr":7566,"hiredate":"1987-04-19","sal":3000,"comm":null,"deptno":20}
{"empno":7839,"ename":"KING","job":"PRESIDENT","mgr":null,"hiredate":"1981-11-17","sal":5000,"comm":null,"deptno":10}
{"empno":7844,"ename":"TURNER","job":"SALESMAN","mgr":7698,"hiredate":"1981-09-08","sal":1500,"comm":0,"deptno":30}
{"empno":7876,"ename":"ADAMS","job":"CLERK","mgr":7788,"hiredate":"1987-05-23","sal":1100,"comm":null,"deptno":20}
{"empno":7900,"ename":"JAMES","job":"CLERK","mgr":7698,"hiredate":"1981-12-03","sal":950,"comm":null,"deptno":30}
{"empno":7902,"ename":"FORD","job":"ANALYST","mgr":7566,"hiredate":"1981-12-02","sal":3000,"comm":null,"deptno":20}
{"empno":7934,"ename":"MILLER","job":"CLERK","mgr":7369,"hiredate":"1982-01-23","sal":1300,"comm":null,"deptno":10}
1)常用的行动算子
--show() 用于展示前N条记录 n默认值使20
--collect(): 将df的数据转成数组类型,数组的泛型为Row
--collectAsList():将df的数据转成java的集合类型,集合类型的泛型为Row
--first|head : 取出df中的第一个row对象
--take(topn:Int): 取出df中的前n个row,封装到Array里
--takeAsList(topn:Int): 取出df中的前n个row,封装到java.util.List里
--printSchema
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.util
/**
* 行动算子的演示:
*/
object Spark_13_Action_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
val df: DataFrame = sparkSession.read.json("data/emp.json")
/**
* show算子,用于触发程序的运行,并显示数据
* 1. show() : 默认显示前20行
* 2. show(numRows: Int): Unit :自定义显示的行数
* 3. show(truncate: Boolean): Unit : 自定义是否截取
* 4. show(numRows: Int, truncate: Boolean): Unit :自定义现实的额行数,自定义是否截取超长的字节数量
* 5. show(numRows: Int, truncate: Int): Unit : 自定义显示的行数,每列的显示的最长字节数据量,超出的截断。
*/
df.show(10,4)
/**
* collect()算子: 搜集算子,将df的数据搜集成数组类型,数组的泛型为Row
* collectAsList():将df的数据转成java的集合类型,集合类型的泛型为Row
*/
val rows: Array[Row] = df.collect()
rows.foreach(println)
val rows1: util.List[Row] = df.collectAsList()
println(rows1)
println("-------------first|head : 取出df中的第一个row对象-------------")
//val row: Row = df.first()
val row: Row = df.head()
println(row)
println("-------------take(topn:Int)|head(n:Int): 取出df中的前n个row,封装到Array里-------------")
//val rows2: Array[Row] = df.take(2)
val rows2: Array[Row] = df.head(2)
rows2.foreach(println)
println("-------------takeAsList(topn:Int): 取出df中的前n个row,封装到java.util.List里-------------")
val rows3: util.List[Row] = df.takeAsList(2)
println(rows3)
println("-------------printSchema-------------")
df.printSchema()
sparkSession.stop()
}
}
2)常用的转换算子
--select(): 参数类型有两种类型,一种是字符串,一种是Column类型
df.select(df("ename"),df("job")).show <--- Column
df.select("ename","job").show <--- String
--filter()
--where() : 用于条件过滤, 注意条件如果是等号的话,一个等号即可,和mysql一样
字符串时,要使用单引号
--describe(col:String*),
用来显示指定字段的分析数据,分析数据有五个,分别使max,min,count,mean,stddev
--selectExpr(expr:String*)
df.selectExpr("ename as uname","sal","sal + 1000 as addsal").show
--drop(col:String*)
排除df中的指定字段
--limit(n:Int)
取出前n条记录
--orderBy(col:Column*)|sort(col:Column*)
--sortWithinPartitions(col:Column*) : 用于分区内排序
--groupBy(col:String*):
返回值为RelationalGroupedDataset, 因此只能再次调用聚合算子
--dropDuplicates(col:String*) :用于指定字段组合进行去重,同一个组合不能有相同的记录
--union: 两个df做联合操作, 追加
--join: 参数有以下几种
ds.join(ds,"关联字段","join的类型").show
ds.join(ds,"关联字段","inner").show
ds.join(ds,"关联字段","full").show
ds.join(ds,"关联字段","left").show
--explode: 展开
scala> df.explode("hiredate","dt"){x:String => x.split("-")}.show
+----+------+-----+------+----------+--------+----+----+----+
|comm|deptno|empno| ename| hiredate| job| mgr| sal| dt|
+----+------+-----+------+----------+--------+----+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|1980|
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800| 12|
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800| 17|
| 300| 30| 7499| ALLEN|1981-02-20|SALESMAN|7698|1600|1981|
| 300| 30| 7499| ALLEN|1981-02-20|SALESMAN|7698|1600| 02|
| 300| 30| 7499| ALLEN|1981-02-20|SALESMAN|7698|1600| 20|
+----+------+-----+------+----------+--------+----+----+----+
--withColumn : 基于sal新增一列salary
scala> df.withColumn("salary", df("sal")).show
+----+------+-----+------+----------+---------+----+----+------+
|comm|deptno|empno| ename| hiredate| job| mgr| sal|salary|
+----+------+-----+------+----------+---------+----+----+------+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600| 1600|
+----+------+-----+------+----------+---------+----+----+------+
--withColumnRenamed: 给字段重命名
scala> df.withColumnRenamed("ename", "name").show
+----+------+-----+------+----------+---------+----+----+
|comm|deptno|empno| name| hiredate| job| mgr| sal|
+----+------+-----+------+----------+---------+----+----+
|null| 20| 7369| SMITH|1980-12-17| CLERK|7902| 800|
| 300| 30| 7499| ALLEN|1981-02-20| SALESMAN|7698|1600|
+----+------+-----+------+----------+---------+----+----+
--intersect: 交集
--except:差集
演示1:
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.{Column, DataFrame, Row, SparkSession}
import java.util
/**
* 行动算子的演示:
*/
object Spark_14_Transfer_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val df: DataFrame = sparkSession.read.json("data/emp.json")
println("------- select():选择要显示的字段,一种传入字符串类型,一种传入Column类型-------------------")
df.select("empno","ename","job").show()
df.select($"empno",'ename,new Column("job"),col("mgr")).show()
println("------- filter() :用于过滤数据的,内部需要传入一个返回boolean类型的表达式-------------------")
df.filter("empno>7800 and empno <7850").show()
println("------- where() :用于过滤数据的 , 条件中带有字符串,需要使用单引号 -------------------")
df.where("empno>7800 and ename like 'K%'" ).show()
println("------- describe(col:String*),用来显示指定字段的分析数据,分析数据有五个,分别使max,min,count,mean,stddev -------------------")
df.describe("sal","comm").show()
println("------- selectExpr(expr:String*) -------------------")
df.selectExpr("ename as uname","sal","sal + 1000 as addsal").show
println("------- drop(col:String*): 排除df中的指定字段 -------------------")
df.drop("mgr","hiredate").show()
println("------- limit(n:Int) : 取出前n条记录 -------------------")
df.limit(3).show()
println("------- orderBy(col:Column*)|sort(col:Column*) -------------------")
df.orderBy($"deptno").show()
df.orderBy($"deptno".desc).show()
df.orderBy(-$"deptno").show()
df.sort($"deptno",-$"sal").show()
sparkSession.stop()
}
}
演示2:
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
/**
* 行动算子的演示:
*/
object Spark_14_Transfer_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val list = List(
Animal(1001,"A",3),
Animal(1002,"B",4),
Animal(1003,"C",5),
Animal(1004,"D",4),
Animal(1005,"E",3),
Animal(1005,"F",4),
Animal(1007,"G",2)
)
val rdd1: RDD[Animal] = sparkSession.sparkContext.makeRDD(list, 2)
val df: DataFrame = rdd1.toDF()
println("------- sortWithinPartitions(col:Column*) : 用于分区内排序-------------------")
df.sortWithinPartitions(-$"id",-$"age").show()
println("------- groupBy(col:String*): 返回值为RelationalGroupedDataset, 因此只能再次调用聚合算子-------------------")
df.groupBy("age").count().show()
sparkSession.stop()
}
case class Animal(id:Int,name:String,age:Int)
}
演示3:
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
/**
* 行动算子的演示:
*/
object Spark_14_Transfer_3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val df: DataFrame = sparkSession.read.json("data/emp.json")
println("------- dropDuplicates(col:String*) :用于指定字段组合进行去重,同一个组合留一条---------------------")
df.dropDuplicates("deptno","job").show()
println("------- union: 两个df做联合操作, 追加---------------------")
println(df.union(df).count())
import scala.collection.JavaConversions._
println("------- join: 参数有以下几种---------------------")
val ds = df.as[F]
ds.join(ds,"deptno").show(100)
println("------- -withColumn : 新增一列, 需要基于某一列---------------------")
df.withColumn("newSal",$"sal"+1000).show()
sparkSession.stop()
}
case class F(empno:Long,ename:String,job:String,mgr:Long,hiredate:String,sal:Double,comm:Double,Deptno:Long)
}
扩展:这两个函数是高阶分组函数
假如有一张销售表:
年 月 日 销售额
2021 1 1 10
2021 1 1 1000
2021 1 1 102
............
数据分析人员的需求可能如下:
select 年 月 日 销售额 from ...group by 年 月 日
union
select 年 null 日 销售额 from ...group by 年 日
union
select 年 月 null 销售额 from ...group by 年 月
union
select null 月 日 销售额 from ...group by 月 日
union
select null 月 null 销售额 from ...group by 月
union
select 年 null null 销售额 from ...group by 年
union
select null null 日 销售额 from ...group by 日
union
select null,null,null,销售额 from ...
针对于上述需求: 有一个高阶函数cube与之对应。
--cube: cube(A,B,C)
先三个字段组合分组, 然后两个字段组合分组,再一个字段分组,最后整张表为一组
在实际生产环境中的合理性:
select 年 月 日 销售额 from ...group by 年 月 日
union
select 年 月 null 销售额 from ...group by 年 月
union
select 年 null null 销售额 from ...group by 年
union
select null,null,null,销售额 from ...
针对于上述需求: 有一个高阶函数rollup与之对应。
--rollup: rollup(A,B,C)
先三个字段组合分组,然后依次从后面开始少一个字段分组,
即再前两个字段分组,然后前一个字段分组,然后整张表为一组
package com.qf.sparksql.day03
import org.apache.spark.sql.SparkSession
/**
* 高阶分组函数的讲解:
* 1. cube : cube(A,B,C) 先三个字段组合分组, 然后两个字段组合分组,再一个字段分组,最后整张表为一组
* 2. rollup: rollup(A,B,C) 先三个字段组合分组,然后依次从后面开始少一个字段分组,
* 即再前两个字段分组,然后前一个字段分组,然后整张表为一组
*/
object Spark_01_Transfer_4 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("高阶分组函数").getOrCreate()
import spark.implicits._
val df = spark.read.json("data/emp.json")
df.show()
println("----------------cube(A,B)-----------------------")
df.cube("deptno","job").sum("sal").show()
df.groupBy("deptno","job").sum("sal").show()
println("----------------rollup(A,B)-----------------------")
df.rollup("deptno","job").sum("sal").show()
spark.stop()
}
}
三、sparksql的加载与落地
3.1 SparkSql加载文件
package com.qf.sparksql.day03
import org.apache.spark.sql.{DataFrame, SparkSession}
object Spark_02_ReadFile {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("readFile").getOrCreate()
/**
* SparkSession想要加载文件时,需要获取DataFrameReader对象,然后调用该对象的load方法加载文件。
*
* load方法,默认加载的是parquet类型的文件。
*/
var df = spark.read.load("data/users.parquet")
df.show()
/**
* 如果想要读取别的类型的数据,需要使用format方法来指定格式
*/
//csv格式的文件,默认会使用逗号作为列分隔符进行解析。
val df1: DataFrame = spark.read.format("csv").load("data/country.csv")
df1.toDF("id","name","code").show()
val df2: DataFrame = spark.read.format("json").load("data/emp.json")
df2.show()
val df3: DataFrame = spark.read.format("parquet").load("data/sqldf.parquet")
df3.show()
val df4: DataFrame = spark.read.format("orc").load("data/student.orc")
df4.show()
//注意: 读取Text文件时,SparkSql只会将一行的内容解析成一列。
val df5: DataFrame = spark.read.format("text").load("data/dailykey.txt")
df5.show()
/**
* 正常情况下,不能读取avro类型的文件,需要导入其他第三方的jar包才可以。
*/
//val df6: DataFrame = spark.read.format("avro").load("data/users.avro")
/**
* option方法的一个应用, 用于指定分隔符
*
* csv格式的文件,默认会使用逗号作为列分隔符进行解析。可以使用option("sep","自定义分隔符")来指定
* sep:是英文单词separator的简写
*
* option方法的另一个应用, 将文件的第一行设置成表头: option("header","true")
*/
val df6: DataFrame = spark.read.option("header","true").option("sep","|").format("csv").load("data/location-info.csv")
df6.show()
spark.stop()
}
}
3.2 SparkSql保存文件
package com.qf.sparksql.day03
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object Spark_03_SaveFile {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("readFile").getOrCreate()
import spark.implicits._
val frame: DataFrame = spark.read.json("data/emp.json")
/**
* 将DF保存成文件时,应该调用DataFrameWriter的save方法进行保存,可以使用format来指定要保存的数据源格式
*/
//保存成csv格式时,如果是null,则默认保存成空字符串
frame.write.format("csv").save("out/csv")
//保存成json格式时,如果是null,则不存储键值对
frame.write.format("json").save("out/json")
frame.write.format("orc").save("out/orc")
frame.write.format("parquet").save("out/parquet")
/**
* 注意: 将df保存成text格式时,只能将df的多列转成一列进行存储,否则报错
*/
val rdd: RDD[Row] = frame.rdd
val rdd2: RDD[String] = rdd.map(row => {
row.get(0) + "," + row.get(1) + "," + row.get(2) + "," + row.get(3) + "," + row.get(4) + "," + row.get(5) + "," + row.get(6) + "," + row.get(7)
})
//将新的RDD2转成DF再进行存储。
rdd2.toDF().write.format("text").save("out/text")
//正常情况下Spark2.0版本,不支持保存成avro格式
//frame.write.format("avro").save("out/avro")
println("-------------SparkSql的存储方式的简化方式-----------------")
frame.write.json("out1/json")
frame.write.option("sep","|").csv("out1/csv")
frame.write.orc("out1/orc")
//frame.write.text("out1/text")
frame.write.parquet("out1/parquet")
spark.stop()
}
}
3.3 Spark连接MySql
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.21version>
dependency>
mysql里的数据准备
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`EMPNO` int(4) NOT NULL,
`ENAME` varchar(10),
`JOB` varchar(9),
`MGR` int(4),
`HIREDATE` date,
`SAL` int(7),
`COMM` int(7),
`DEPTNO` int(2),
PRIMARY KEY (`EMPNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `emp` VALUES ('7369', 'SMITH', 'CLERK', '7902', '1980-12-17', '800', null, '20');
INSERT INTO `emp` VALUES ('7499', 'ALLEN', 'SALESMAN', '7698', '1981-02-20', '1600', '300', '30');
INSERT INTO `emp` VALUES ('7521', 'WARD', 'SALESMAN', '7698', '1981-02-22', '1250', '500', '30');
INSERT INTO `emp` VALUES ('7566', 'JONES', 'MANAGER', '7839', '1981-04-02', '2975', null, '20');
INSERT INTO `emp` VALUES ('7654', 'MARTIN', 'SALESMAN', '7698', '1981-09-28', '1250', '1400', '30');
INSERT INTO `emp` VALUES ('7698', 'BLAKE', 'MANAGER', '7839', '1981-05-01', '2850', null, '30');
INSERT INTO `emp` VALUES ('7782', 'CLARK', 'MANAGER', '7839', '1981-06-09', '2450', null, '10');
INSERT INTO `emp` VALUES ('7788', 'SCOTT', 'ANALYST', '7566', '1987-04-19', '3000', null, '20');
INSERT INTO `emp` VALUES ('7839', 'KING', 'PRESIDENT', null, '1981-11-17', '5000', null, '10');
INSERT INTO `emp` VALUES ('7844', 'TURNER', 'SALESMAN','7698', '1981-09-08', '1500', '0', '30');
INSERT INTO `emp` VALUES ('7876', 'ADAMS', 'CLERK', '7788', '1987-05-23', '1100', null, '20');
INSERT INTO `emp` VALUES ('7900', 'JAMES', 'CLERK', '7698', '1981-12-03', '950', null, '30');
INSERT INTO `emp` VALUES ('7902', 'FORD', 'ANALYST', '7566', '1981-12-03', '3000', null, '20');
INSERT INTO `emp` VALUES ('7934', 'MILLER', 'CLERK', '7782', '1982-01-23', '1300', null, '10');
package com.qf.sparksql.day03
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import java.util.Properties
/**
* 使用SparkSql连接Mysql
*/
object Spark_04_Jdbc_Mysql {
def main(args: Array[String]): Unit = {
write()
}
/**
* 将DF对应的数据保存到mysql中, 小贴士: sparksql向mysql里保存数据时,不需要提前建表
*/
def write(): Unit ={
val spark = SparkSession.builder().master("local[*]").appName("readFile").getOrCreate()
val frame: DataFrame = spark.read.option("sep", "|").option("header", "true").csv("data/student.csv")
val url = "jdbc:mysql://localhost:3306/sz2103?serverTimezone=UTC"
val table = "student"
val prop = new Properties()
prop.setProperty("user","root")
prop.put("password","mmforu")
//保存的时候,使用DataFrame对象调用
frame.write.jdbc(url,table,prop)
spark.stop()
}
/**
* 读取Mysql里的表操作
*/
def read(): Unit ={
val spark = SparkSession.builder().master("local[*]").appName("readFile").getOrCreate()
/**
* jdbc(url: String, table: String, properties: Properties)
* 解析: 作用是连接mysql,读取mysql里的表数据,返回DataFrame
* url: 连接mysql的路径: 8.0版本:jdbc:mysql://ip:port/dbname?serverTimezone=UTC
* 低版本:jdbc:mysql://ip:port/dbname
* table: 数据库里的表名
* properties: 用于指定连接mysql的用户名,密码等一个Properties对象
*/
val url = "jdbc:mysql://localhost:3306/sz2103?serverTimezone=UTC"
val table = "emp"
val prop = new Properties()
prop.setProperty("user","root")
prop.put("password","mmforu")
// 注意:读取的时候,使用会话对象调用
val df: DataFrame = spark.read.jdbc(url, table, prop)
df.createTempView("employee")
val sqlText =
"""
|select
| deptno,max(sal) maxSal,avg(nvl(sal,0)) avgSal,count(1) totalPeople
|from employee
|where deptno = (
| select deptno from employee where empno = 7369
| )
|group by deptno
|""".stripMargin
spark.sql(sqlText).show()
spark.stop()
}
}
保存模式的研究:
package com.qf.sparksql.day03
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import java.util.Properties
/**
* 使用SparkSql连接Mysql
*/
object Spark_05_SaveMode {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("saveMode").getOrCreate()
val frame: DataFrame = spark.read.option("sep", "|").option("header", "true").csv("data/student.csv")
val url = "jdbc:mysql://localhost:3306/sz2103?serverTimezone=UTC"
val table = "student"
val prop = new Properties()
prop.setProperty("user","root")
prop.put("password","mmforu")
/**
* 在保存数据时,可以指定保存模式
* SaveMode.Append :追加模式, 在原有数据的基础上追加数据,要考虑主键的问题,如果有主键约束,可能报错
* SaveMode.Overwrite :覆盖模式, 删除原有的数据,再添加数据
* SaveMode.ErrorIfExists :如果存在该表,就报错 默认模式
* SaveMode.Ignore :忽略模式, 不添加数据
*/
frame.write.mode(SaveMode.Ignore).jdbc(url,table,prop)
spark.stop()
}
}
3.4 SparkSQL连接Hive
3.4.1 说明
SparkSQL连接hive,指的是spark读hive中的表,转成DF或者是DS,然后使用相关算子计算。 和hive的执行引擎是spark,不是同一个概念
3.4.2 spark命令行连接hive
可以使用spark-sql命令脚本连接hive。 默认连接的是本地的spark环境,这种情况在企业中根本不用
1. 将hive的hive-site.xml拷贝到spark的conf目录下
2. 将mysql的驱动包,拷贝到spark的jars目录下
3. 测试1:使用spark-sql脚本
../spark-local/bin/spark-sql
就可以正常写sql语句了
spark-sql (default)> select deptno,max(sal) from emp group by deptno;
测试2: 使用beeline工具
(1) 先启动服务项, ../spark-local/sbin/start-thriftserver.sh
(2) 使用beeline指令连接:
../spark-local/bin/beeline -u jdbc:hive2://localhost:10000 -n root
3.4.3 代码连接hive
1)读取hive中的表
package com.qf.sparksql.day03
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import java.util.Properties
/**
* 使用SparkSql连接hive
*
* 正常情况下,要配置连接hive的一系列参数,不过,可以将hive-site.xml拷贝到程序中,注意是否识别的问题,
* 需要加载mysql的驱动包到idea的classpath下,即在pom.xml里添加mysql的坐标
*
* 识别的解决方式:
* 1. 可以重启idea
* 2. 可以将hive-site.xml文件拷贝到classes目录下
*/
object Spark_06_readFromHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("saveMode")
.enableHiveSupport() //开启hive支持,
.getOrCreate()
val df: DataFrame = spark.table("sz2103.emp")
df.createTempView("emp")
val sqlText =
"""
|select deptno,
| max(sal),
| min(sal),
| count(1)
|from emp
| group by deptno
|""".stripMargin
spark.sql(sqlText).show()
spark.stop()
}
}
2)向hive中写数据
package com.qf.sparksql.day03
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 使用SparkSql连接hive
*
* 正常情况下,要配置连接hive的一系列参数,不过,可以将hive-site.xml拷贝到程序中,注意是否识别的问题,
* 需要加载mysql的驱动包到idea的classpath下,即在pom.xml里添加mysql的坐标
*
* 识别的解决方式:
* 1. 可以重启idea
* 2. 可以将hive-site.xml文件拷贝到classes目录下
*/
object Spark_07_WriteToHive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root")
val spark = SparkSession.builder()
.master("local[*]")
.appName("saveMode")
.enableHiveSupport() //开启hive支持,
.getOrCreate()
val df: DataFrame = spark.read.option("sep", "|").option("header","true").csv("data/student.csv")
/**
* 将df对应的数据写到hive中
*
* 注意:
* SaveMode.ErrorIfExists 默认模式
* SaveMode.Append 追加模式
* SaveMode.Overwrite 覆盖模式
* SaveMode.Ignore 忽略模式
*/
df.write.mode(SaveMode.Ignore).saveAsTable("sz2103.student")
spark.stop()
readTest
}
def readTest(): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("saveMode")
.enableHiveSupport() //开启hive支持,
.getOrCreate()
val df: DataFrame = spark.table("sz2103.student")
println(df.count())
spark.stop()
}
}
四、SparkSQL的自定义函数
4.1 函数的分类情况
1)从功能上进行分类
1) 数值函数
round(x,[d]): 对x保留d位小数,同时会四舍五入
floor(x): 获取不大于x的最大整数。
ceil(x): 获取不小于x的最小整数。
rand(): 获取0到1之间的随机数
abs(x): 取绝对值
pow(a, b): 获取a的b次幂
sin(x):
cos(x):
tan():
2) 字符串函数
length(str): 返回字符串str的长度
instr(str, substr): 作用等同于str.indexOf(substr),
substr(str, pos[, len])|substring(str, pos[, len]):
从str的pos位置开始,截取子字符串,截取len的长度,如果不传len,截取余下所有。
substring(str,delim,count):返回的字符串是从头到第count个delim为止。不包括这个delim
concat(str1, str2,......): 拼接字符串
concat_ws(separator, str1, str2):使用指定分隔符来拼接字符串
3) 日期函数:
unix_timestamp|to_unix_timestamp:
转时间戳(单位是秒) 注意:指定的是北京时间,但是得到的是本初子午线的时间
spark.sql("select to_unix_timestamp('1970-1-1 0:0:0','yyyy-MM-dd HH:mm:ss')").show
from_unixtime: 时间戳转日期 注意:默认指定的是本初子午线的时间,获取的是东八区的时间
所以,如果想要指定北京时间,则需要-28800
spark.sql("select from_unixtime(0,'yyyy-MM-dd HH:mm:ss')").show
current_date(),获取当前的日期,日期格式为标准格式:yyyy-MM-dd
current_timestamp():获取当前日期的时间戳,格式:yyyy-MM-dd HH:mm:ss.SSS
add_months(start_date, num_months):返回start_date之后num_months月的日期
spark.sql("select add_months('2021-10-10',-2)").show
date_add(start_date, num_days):返回start_date之后num_days天的日期
date_sub(start_date, num_days):返回start_date之前num_days天的日期
spark.sql("select date_add('2021-10-27',-10)").show
next_day(start_date, day_of_week),返回下一个周几, 第二个参数:需要写星期的简写
spark.sql("select next_day('2022-2-9','Mon')").show
dayofmonth(date) 返回date对应月份中的第几天
weekofyear(date) 返回date对应年份中的第几周
日期分量函数:获取日期中的某一个部分值
second
minute
hour
day
month
year
spark.sql("select second(current_timestamp())").show
date_format(日期,格式化),返回指定格式化时间
datediff(date1, date2),返回date1和date2之间的差值(单位是天)
to_date(datetime)返回datetime中的日期部分
4) 统计函数:
max() min() avg() sum() count()
index(arr, n),就是arr(n), 获取索引n对应的元素
5) 条件函数:
if(expression,value1,value2)
spark.sql("select if(2<1,'ok','no')").show
case when.....then....
when.....then.....
else....end
case when相当于多个条件的If分支
when后写条件, then后写值
如果都没有满足条件,则走else
比如:
case when job='MANAGER' then sal+1000
when job='SALESMAN' then sal+100
else sal+10 end
case job when 'MANAGER' then sal+1000
when 'SALESMAN' then sal+100
else sal+10 end
6) 特殊函数:
array:返回数组
collect_set:返回一个元素不重复的set集合
collect_list:返回一个元素可重复的list集合
split(str, regex):使用regex分隔符将str进行切割,返回一个字符串数组
explode(array):将一个数组,转化为多行
cast(type1 as type2):将数据类型type1的数据转化为数据类型type2
2)从定义的角度进行分类
一种是框架中内置函数, 上述函数都是内置的
另外一种就是用户自定义的函数,而用户自定义函数在sparksql中可以分为两类,
--udf :用户自定义函数, 通常指的是一对一形式,进入一条记录,出来一条记录
--udaf 用户自定义聚合函数, 通常指的是多对一形式,进入多条记录,出来一条记录,比如模拟max
4.2 自定义函数案例演示
4.2.1 UDF
案例1)
package com.qf.sparksql.day03
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* sparksql定义udf函数
*/
object Spark_08_UDF_1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("saveMode").getOrCreate()
val df: DataFrame = spark.read.json("data/emp.json")
//需求:使用内置的函数length 统计人名长度大于4的员工信息
df.createTempView("emp")
spark.sql("select ename,length(ename) from emp where length(ename)>4 ").show()
/**
* 需求: 使用自定义udf函数来完成上述需求
*
* 步骤1: 定义一个方法
* 步骤2: 注册 register(name:String , func: Function)
* name: 要注册的函数的昵称
* func: 表示函数的逻辑体
*/
def f1(content:String):Long={
content.length
}
spark.udf.register("mylen",f1 _)
spark.sql("select ename,mylen(ename) from emp where mylen(ename)>4 ").show()
spark.stop()
}
}
案例2)
package com.qf.sparksql.day03
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, LongType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* sparksql定义udaf函数
*/
object Spark_09_UDAF_1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("saveMode").getOrCreate()
val df: DataFrame = spark.read.json("data/emp.json")
//需求:查询每个部门的人数,工资之和,平均工资
df.createTempView("emp")
spark.sql("select deptno,count(1),sum(sal),avg(nvl(sal,0)) from emp group by deptno").show()
//需求:使用用户自定义分析函数来完成上述的求平均值的需求。
/**
* 步骤1: 先自定义一个类型,实现UserDefinedAggregateFunction
* 步骤2: 注册
*/
spark.udf.register("myavg",new MyUDAF)
spark.sql("select deptno,count(1),sum(sal),myavg(nvl(sal,0)) from emp group by deptno").show()
spark.stop()
}
/**
* UDAF类型,需求继承抽象的UserDefinedAggregateFunction,重写里面的方法
*
* 求平均值的原理: 使用一个变量sum来累加所有的值,再使用另一个变量count来累加个数。 平均值: sum/count
*/
class MyUDAF extends UserDefinedAggregateFunction{
// 用于指定进入函数的数据的类型
override def inputSchema: StructType = StructType(Array(
StructField("sal",DoubleType)
))
// 用于设计计算过程中所需要的数据信息, 而我们的这个需求需要两个变量,一个sum,一个count
override def bufferSchema: StructType = StructType(Array(
StructField("sum",DoubleType),
StructField("count",LongType)
))
//函数的返回数据类型
override def dataType: DataType = DoubleType
//函数是否稳定
override def deterministic: Boolean = true
//初始化, 初始化需要两个变量的值,这两个变量是一个数组的两个元素,第一个元素充当sum,第二个元素充当count
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0D // sum的初始化
buffer(1) = 0L // count的初始化
}
//分区内的计算过程中的更新, buffer就是临时存储的数组,input是进入的每一条记录
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getDouble(0)+input.getDouble(0)) //累加和,然后设置回去
buffer.update(1,buffer.getLong(1)+1) //累加个数
}
//分区间的合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0,buffer1.getDouble(0)+buffer2.getDouble(0)) //累加和,然后设置回去
buffer1.update(1,buffer1.getLong(1)+buffer2.getLong(1)) //累加个数
}
// 最终的计算
override def evaluate(buffer: Row): Any = {
buffer.getDouble(0)/buffer.getLong(1)
}
}
}
4.2.2 UDAF
package com.qf.sparksql.day03
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* sparksql定义udf函数
*/
object Spark_09_UDF_2 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("saveMode").getOrCreate()
val df: DataFrame = spark.read.json("data/emp.json")
//需求:显示每个员工的工资级别。 >4000的为 level4 >2500的为leve3 >1000的为level2 其他的为level1
df.createTempView("emp")
val sqlText =
"""
| select empno,ename,sal,
| (case when sal>4000 then 'level4'
| when sal>2500 then 'level3'
| when sal>1000 then 'level2'
| else 'level1' end) level
| from emp
|""".stripMargin
spark.sql(sqlText).show()
//需求:显示每个员工的工资级别。 >4000的为 level4 >2500的为leve3 >1000的为level2 其他的为level1
val sqlText2 =
"""
| select
| (case when sal>4000 then 'level4'
| when sal>2500 then 'level3'
| when sal>1000 then 'level2'
| else 'level1' end) level, count(1)
| from emp
| group by (case when sal>4000 then 'level4'
| when sal>2500 then 'level3'
| when sal>1000 then 'level2'
| else 'level1' end)
|""".stripMargin
spark.sql(sqlText2).show()
//需求: 使用udf函数来完成上述需求
def myfunc(sal:Double):String={
if(sal>4000)
"level4"
else if(sal>2500)
"level3"
else if(sal>1000)
"level2"
else
"level1"
}
spark.udf.register("mylevel",myfunc _)
val sqlText3 =
"""
| select mylevel(sal), count(1)
| from emp
| group by mylevel(sal)
|""".stripMargin
spark.sql(sqlText3).show()
spark.stop()
}
}
五、SparkSQL和Spark的优化
5.1 SparkSql的优化
5.1.1 内存参数
| spark.sql.inMemoryColumnarStorage.compressed | true | 如果假如设置为true,SparkSql会根据统计信息自动的为每个列选择压缩方式进行压缩。 |
|---|---|---|
| spark.sql.inMemoryColumnarStorage.batchSize | 10000 | 控制列缓存的批量大小。批次大有助于改善内存使用和压缩,但是缓存数据会有OOM的风险。 |
5.1.2 其他调优参数
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.files.maxPartitionBytes | 134217728 (128 MB) | 获取数据到分区中的最大字节数。 |
| spark.sql.files.openCostInBytes | 4194304 (4 MB) | 该参数默认4M,表示小于4M的小文件会合并到一个分区中,用于减小小文件,防止太多单个小文件占一个分区情况。 |
| spark.sql.broadcastTimeout | 300 | 广播等待超时时间,单位秒。 |
| spark.sql.autoBroadcastJoinThreshold | 10485760 (10 MB) | 最大广播表的大小。设置为-1可以禁止该功能。当前统计信息仅支持Hive Metastore表。 |
| spark.sql.shuffle.partitions | 200 | 设置shuffle分区数,默认200。 |
5.2 Spark的优化机制
5.2.1 spark的优化基础篇
参考文章:https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
开发原则:
原则一:避免创建重复的RDD
原则二:尽可能复用同一个RDD 原则1和原则2 都要由原则3来配合使用
原则三:对多次使用的RDD进行持久化
持久化的级别,要针对于具体应用场景来选择
原则四:尽量避免使用shuffle类算子
原则五:使用map-side预聚合的shuffle操作
原则六:使用高性能的算子
原则七:广播大变量
原则八:使用Kryo优化序列化性能
原则九:优化数据结构
资源参数调优
num-executors
executor-memory
executor-cores
driver-memory
spark.default.parallelism
spark.storage.memoryFraction
spark.shuffle.memoryFraction
案例演示:
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
5.2.2 spark的优化高阶篇
主要就是处理数据倾斜问题
参考文章:https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
解决方案一:使用Hive ETL预处理数据
解决方案二:过滤少数导致倾斜的key
解决方案三:提高shuffle操作的并行度
解决方案四:两阶段聚合(局部聚合+全局聚合)
解决方案五:将reduce join转为map join
解决方案六:采样倾斜key并分拆join操作
解决方案七:使用随机前缀和扩容RDD进行join
解决方案八:多种方案组合使用
实际生产环境中,要具体情况具体分析,采用哪一种,或哪几种方案的组合
5.3 局部聚合+全局聚合解决数据倾斜问题
package com.qf.sparksql.day03
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* 使用局部聚合+全局聚合來解決数据倾斜的问题
*/
object Spark_10_DataSkew {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("data skew").getOrCreate()
import spark.implicits._
var rdd1 = spark.sparkContext.makeRDD(List("a,a,a,a,a,a,a,a,a,a,a,a,a,a,a,a,a,a","b,c,d,e,f","b,b,c,c,d,e,f,g","a,b,a,c,f"))
val df: DataFrame = rdd1.toDF("line")
df.createTempView("temp")
println("----------------先正常统计每个字符的个数, 发现a特别多,那么下游的RDD对应的Task处理所有的a的时候,时间就会很长,出现数据倾斜-----------------------")
val sql =
"""
|select word,count(1)
|from
|(
|select explode(split(line,",")) word
|from temp) t1
|group by t1.word
|
|""".stripMargin
spark.sql(sql).show()
/**
* 上述的查询,可能会发生数据倾斜,因为a特别多
*/
println("----------------先在单词前面拼接随机数字,比如0,1,2,3-----------------------")
val sql1 =
"""
|select concat(floor(rand()*4),"-",word)
|from
|(
| select explode(split(line,",")) word
|from temp) t1
|
|""".stripMargin
spark.sql(sql1).show()
println("----------------將加上前缀的单词,进行预聚合 统计的时候:可能会出现 3-a:6 2-a:8 1-a:2 0-a:4 此时跟a有关的就4条数据了,远远小于20条 -----------------------")
val sql2 =
"""
|
|select prefix_word,count(1)
|from(
|select concat(floor(rand()*4),"-",word) prefix_word
|from
|(
| select explode(split(line,",")) word
|from temp) t1
|) t2
|group by prefix_word
|
|""".stripMargin
spark.sql(sql2).show()
println("----------------去掉前缀,进行全局聚合-----------------------")
val sql3 =
"""
|
|select substr(prefix_word,instr(prefix_word,"-")+1) w,sum(num)
|from
| (select prefix_word,count(1) num
| from(
| select concat(floor(rand()*4),"-",word) prefix_word
| from(
| select explode(split(line,",")) word
| from temp) t1
| ) t2
| group by prefix_word
| ) t3
|group by w
|""".stripMargin
spark.sql(sql3).show()
spark.stop()
}
}