LLM Data Pipelines: 解析大语言模型训练数据集处理的复杂流程
编者按:在训练大语言模型的过程中,构建高质量的训练数据集是非常关键的一步,但关于构建大模型训练所需数据集的通用数据处理流程(Data pipelines)的相关资料极为稀少。
本文主要介绍了基于Common Crawl数据集的数据处理流程。首先,文章概述了Common Crawl的不同数据格式WARC、WAT和WET的区别及应用场景。然后,文章详细阐述了数据处理流程的几个关键步骤,包括从数据源获取数据、去重、语言识别、使用模型筛选以及LLaMA中添加的“是否是参考来源”筛选等等。在各个步骤中,文章总结了不同的数据处理方案及它们的优劣。
高质量的数据最终将带来高质量的语言模型,数据处理流程需要大量的试验和计算资源投入,每个决策都会对最终结果产生影响,需要我们审慎评估。
以下是译文,Enjoy!
作者 | Christian S. Perone
编译 | 岳扬
Erik Desmazieres’s “La Bibliothèque de Babel”. 1997.
多年来,我们一直没有停止训练语言模型(LMs),但关于构建大模型训练所需数据集的通用数据处理流程(Data pipelines)的相关资料极为稀少,找到这部分的资料极具挑战性。原因可能是我们常常认为大语言模型训练所需的数据集肯定存在(或者至少曾经存在过?只是如今重现这些数据集变得越来越困难)。然而,我们必须要考虑到创建这样的数据处理流程涉及的众多决定,每个决定都会对最终模型的质量有着重要的影响,正如我们试图去复现LLaMA(LLaMA: Open and Efficient Foundation Language Models[1])中所遇到的困难那样。或许会有人认为,由于现在的大模型可以较好地扩展,模型结构并没有发生太大变化,因此数据构建流程变得比模型构建流程更加重要。但实际上,不论模型如何演变,数据始终都是至关重要的。
本文简要介绍了用于创建LLaMA训练数据的处理流程(pipeline)。这一处理流目前也出现了很多变体,故本文还将在相关的位置详细介绍其变体方法的详细信息,例如RefinedWeb(The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only[2])和The Pile(The Pile: An 800GB Dataset of Diverse Text for Language Modeling[3])。
本文主要基于 Meta 的CCNet(CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data[4])和 LLaMA 论文中描述的流程。CCNet被设计用于最大的、但在质量方面也最具挑战性的数据源:Common Crawl[5]。
01 概览 The big picture
CCNet的整个流程(加上LLaMA论文做出的一些小修改)如下所示,包括以下几个阶段:从数据源(data source)获取数据、去重(deduplication)、语言识别(language)、使用模型筛选(filtering)以及LLaMA中添加的“是否是参考来源”筛选(“is-reference” filtering) 。接下来我将逐个介绍这些阶段。
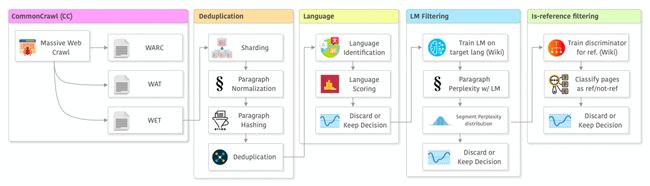
在LLaMA中对CCNet处理流程进行修改后的概览图像
02 Common Crawl

Common Crawl(CC)数据集是由同名的非营利组织[5]对互联网进行大规模爬取的,并采取宽松的条件供大家使用。整理这个数据集并非易事,需要过滤垃圾信息、决定爬取哪些URL、从不同服务器获取大量数据等等。因此,如果您使用该数据集,请考虑捐赠[6]来支持他们的工作。
Common Crawl提供了多种可供使用的数据集格式。目前,主要有三种不同的主要格式(除了索引):WARC、WAT和WET。
WARC/WAT/WET 格式
1) WARC格式
WARC格式是数据量最大的格式,因为其是爬取后未经处理的原始数据,该格式以一种非常聪明的方式记录了HTTP响应头,因此我们甚至可以获取所有被爬取的服务器信息。由于其数据量庞大且包含训练大语言模型所不需要的数据,因此在自然语言处理(NLP)中很少使用。然而,作为Common Crawl的主要数据格式之一,其数据内容非常丰富,对于制作多模态数据集可能用处非常大,这也是为什么我认为在未来的几年,WARC和WAT(下文会描述)可能会被大家广泛应用。
2) WAT和WET格式
这两种格式的数据集是Common Crawl的次要数据源,它们都是经过处理的数据。这两种格式经常用于训练语言模型,这也是不同数据处理流程开始出现差异的地方。这些格式包含不同类型的记录(records),其中WAT比WET包含更多的元数据,还包括HTML标签内容和链接。WET主要是一个纯文本格式。 [译者注:“records”是指在文中提到的数据记录或数据项,它们是特定格式中的单个条目或数据单元。在该段中,“records”指的是存储在 WAT 和 WET 格式中的不同类型的数据。“metadata”是指元数据,它是描述数据的数据。在这种情况下,“metadata”指的是有关记录的附加信息,例如记录的来源、创建时间、作者等。]
如果您想查看WARC/WAT/WET的使用案例,请参考此链接[7]。为了让文章更加简洁,在此省略了示例,但这几种格式的数据都非常有趣,值得我们一看,无论是去使用还是了解如何加载和解析这些数据。
如今,CCNet(CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data[8])使用的是纯文本的WET格式,这一点值得我们重点关注。然而,还有其他一些处理流程却使用WAT,因为他们认为如果要提取高质量的文本数据,必须使用WAT而非WET(bypassing the CommonCrawl processing to extract text)。有一个不使用WET格式文件的例子是The Pile(The Pile: An 800GB Dataset of Diverse Text for Language Modeling[9]),他们使用了jusText[10]。他们提到,与使用WET格式的文件相比,这种方法可以提取更高质量的文本。
您可能已经意识到,我们才刚刚开始接触CC,就已经有了多种从中提取数据的选择。最近另一种名为RefinedWeb[11](在Falcon中使用)的处理流程也直接使用了WARC,跳过了CC流程中进行文本提取的步骤(即生成WET文件这一步)。RefinedWeb使用trafilatura[12]而非jusText进行文本提取。
03 URL Filtering URL过滤
尽管CCNet中没有提及,但许多处理流程都使用公开的成人/暴力/恶意软件等网站的屏蔽列表来进行URL过滤。例如,在RefinedWeb中使用了一个包含460万个域名的屏蔽列表,并且还使用了基于单词的URL过滤(a word-based filtering of the URL)。在这个步骤,您可以发挥创意,从不同来源汇总多个屏蔽列表。
04 Deduplication 去重
现在让我们讨论一下去重,这可能是一个饱含争议的步骤。在《Deduplicating Training Data Makes Language Models Better[13]》一文中,可以对相关研究结果有一定了解。然而,《Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling[14]》认为:“……对我们的训练数据进行去重对语言模型的性能没有明显的好处。”。因此,本文认为去重流程仍然是一个有待讨论的问题,但考虑到LLaMA取得的出色效果,我们不应忽视任何新模型训练流程中的去重步骤,并且我们可能在不久的将来会看到更多相关的出色研究。
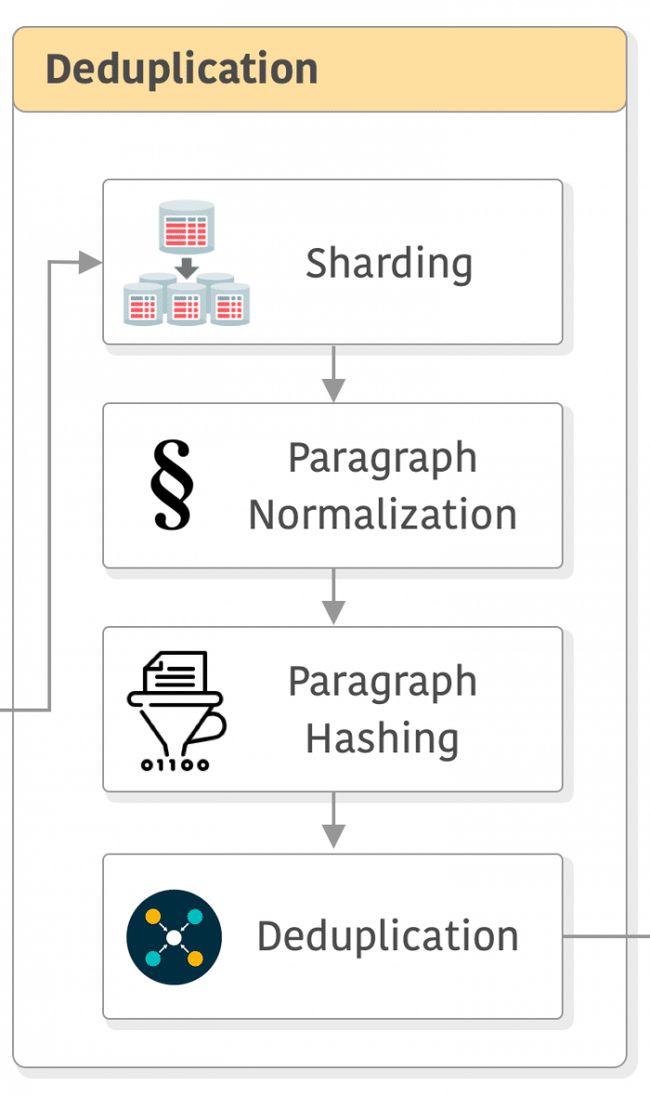
现在我们来讨论一下CCNet进行去重的工作原理。CC 快照文件很大,例如2023年3月/4月的WET文件大小为8.7 TiB,而WAT文件大小为21.1 TiB(这两个文件都已经压缩了!)。CCNet首先将这些WET快照文件分割成大小为5GB的片段,并以JSON格式保存,其中每个条目对应一个已爬取的网页。
分片后的下一步是进行段落归一化,因为去重是在段落级别进行的。他们通过以下步骤对每个段落进行归一化处理:将其转换为小写、用占位符替换数字,并移除所有Unicode标点符号[15](您也可以选择替换它们)和重音符号。 [译者注:重音符号(accent marks)是一种标点符号,用于表示音节的重音或发音上的特殊注释。在一些语言中,如法语、西班牙语和德语中,重音符号用于改变字母的发音方式或强调特定音节。它们可以以形状、大小或位置的改变来表示。例如,法语中的重音符号包括重音符号(´)、抑扬符号(`)和环绕符号(ˆ)。在文本归一化过程中,去除重音符号可以帮助统一文本的表示,使得对比、匹配和去重更加准确。]
接下来,计算每个段落的SHA1哈希值,并使用前64位进行去重。 此后,可以选择通过比较所有分片或固定数量的分片来进行删除去重。如果您对这个步骤比较感兴趣,可以参考他们的论文[16]获取更多详细信息。
值得注意的是,RefinedWeb数据集的处理方式似乎更为激进,采用近似去重(fuzzy deduplication)和使用“strict settings”,这导致了“其删除率远高于其他数据集”(CCNet相关报告称其重复数据占文本的70% )。这无疑对数据集的多样性产生了重大影响。
去重的另一个重要的方面在CCNet论文中有所描述:该步骤可以去除许多模板内容,例如导航菜单、Cookie提醒和联系信息。此外,它还可以从其他语言页面中删除英文内容,并使下文我们将要讨论的语言识别(language identification)更加可靠。
以下是该步骤的概述:

如您所见,该过程的第一步是去除空格,然后将文本转换为小写,并将数字替换为占位符(例如零)。接下来,它会删除(或替换)Unicode标点符号,对文本执行SHA1哈希算法,并使用前8个字节进行去重比较(以段落为单位)。需要注意的是,不要将去重过程与训练过程混淆,这个过程仅用于计算最终的哈希值和去重数据,而不是用于训练模型。
在RefinedWeb中,采用了与Gopher[17]类似的方法,在进行去重筛选之前先消除文档中存在的过多的行、段落或重复的 n-gram 序列(n-gram repetitions)。 (译者注:当文档中某个连续的 n 个单词或字符序列在多个地方重复出现时,就会被视为 n-gram repetitions。) 然后使用MinHash算法(计算文档相似性和包含性的一种算法[18]),发现这种算法对于去除SEO模板(即在多个网站上重复出现的SEO文本)非常有效。这种方法还进行了精确的去重,但由于CC的数据规模巨大,他们采用了CCNet提出的一种替代方案,即首先将数据分片,然后在每个分片中进行去重处理。
05 Language 语言识别

让我们现在来详细介绍一下语言识别(language identification)、评分(scoring)和过滤(filtering)。在CCNet中,他们采用了fastText[19](一种用于高效文本分类的技巧包[20]),并使用来自维基百科、Tatoeba和SETimes的数据进行了训练。fastText支持176种语言,并为每种语言生成一个得分。
在CCNet中,如果被算法判断为最可能的那一种语言的得分低于0.5(50%),则会将该网页丢弃;否则,该网页会被标识为这种最可能的语言,以便进行后续操作。
需要注意的是,尽管LLaMA数据集从CC数据集中过滤掉了非英语数据,但它还利用了其他数据集进行训练,这些数据集包含了其他语言的内容(例如维基百科)。据我的经验,LLaMA在处理其他语言(例如葡萄牙语)方面也表现出色。
像CCNet一样,RefinedWeb这种处理流程也使用了fastText来识别语言。这里有一个重要的区别,RefinedWeb这个处理流程采用了不同的得分判断阈值,即0.65,而不是0.5,并且这种处理流程调整了去重和语言识别的顺序,先进行语言识别,然后再进行去重处理。
06 LM Filtering 使用模型筛选
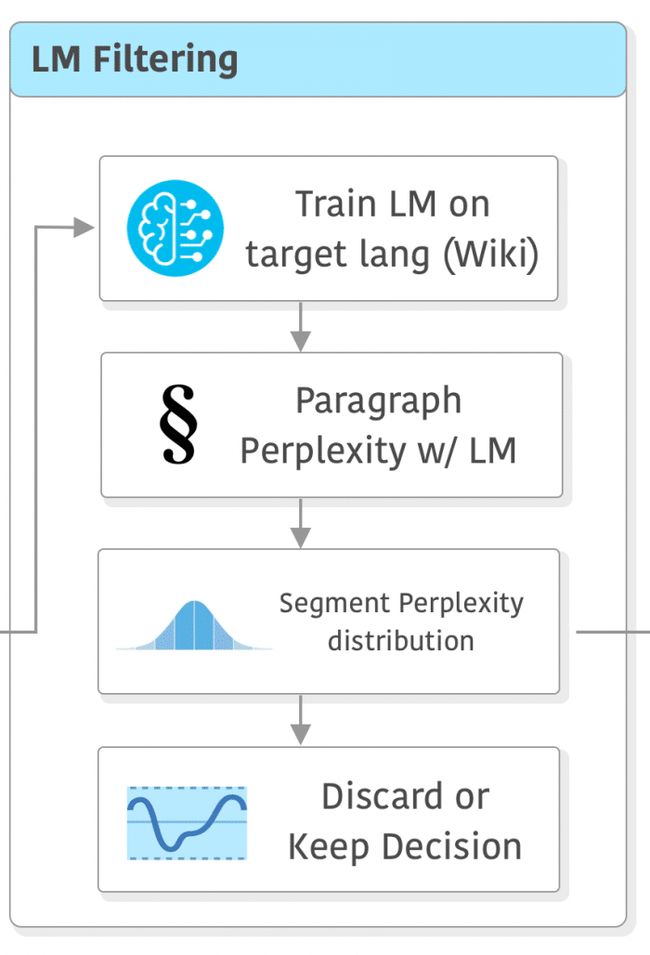
到目前为止,我们已经完成了数据的去重,语言的识别和第一次过滤筛选。然而,经历这些步骤并不意味着数据的质量就一定很好。这就是CCNet还需要进行另一个过滤步骤的原因:CCNet将在目标领域语言上训练的语言模型的困惑度(perplexity)作为一个相对较好的质量评估指标。他们在与目标领域相同语言的维基百科数据集上训练了一个5-gram Kneser-Ney模型,然后使用这些模型计算每个段落的困惑度。
有了困惑度的值后,还需要确定阈值。CCNet论文中描述了他们如何从每种语言的困惑度分布(the distribution of perplexities)中计算出三个等分的部分(头部、中间部分和尾部),因为不同语言的困惑度分布差异很大。(译者注:困惑度是指语言模型对段落的理解和连贯性的评估。通过计算不同段落的困惑度,可以得到一个困惑度值的集合,然后分析这个集合的分布情况,以确定阈值或者其他统计特征,用于判断段落的质量或可靠性。)下面是该论文中的一个重要内容摘录:
(…) Some documents despite being valid text ends up in the tail because they have a vocabulary very different from Wikipedia. This includes blog comments with spokenlike text, or very specialized forums with specific jargon. We decided to not remove content based on the LM score because we think that some of it could be useful for specific applications. (…)
尽管一些段落的文本是有效的,但由于其所用的词汇与维基百科不同之处较多,这些段落最终被归类到尾部。其中包括使用类似口语文本的博客评论,或者带有特定行业术语的专业论坛内容。我们决定不会根据语言模型的得分来删除这些内容,因为我们认为其中的一些内容在特定应用中可能是有用的。
这意味着要怎么做取决于您的应用领域,因为仅仅使用在维基百科上训练的语言模型进行盲目的阈值过滤可能会导致您删除重要的数据。在RefineWeb中,他们避免使用语言模型进行过滤,而是仅依靠简单的规则和启发式方法(simple rules and heuristics)。他们采用了与Gopher中使用的非常相似的流程,通过“总长度、符号与单词的比例以及其他确保文档是真实自然语言的标准”来过滤异常值。他们强调这也需要针对每种语言进行特殊处理,因为过度依赖与语言特征相关的启发式方法通常会带来问题。
07 “Is reference” filtering “是否是参考来源”筛选

在CCNet中并没有提到这一部分,但在LLaMA数据集中这一部分作为额外的补充步骤出现。因此,我决定在此也加以说明。尽管LLaMA的论文中对这一步骤的描述并不详细,但似乎是通过训练一个简单的线性分类器(不确定使用哪些特征)来对维基百科中引用作参考的页面和随机抽样的页面进行分类,然后将被分类为“未被引用参考”的页面舍弃。
乍一看,这一步骤可能显得简单,但它对数据集的质量有着重要的影响,不过也取决于所设定的阈值。我认为LLaMA数据集在使用LM进行过滤这一方面更加保守,主要为了避免删除相关数据,因此他们增加了这个额外的步骤来处理可能存在的质量问题,但这仅仅是我的猜测。
08 附录:RefinedWeb diagram
RefinedWeb论文中有一张非常漂亮的Sankey处理流程图:
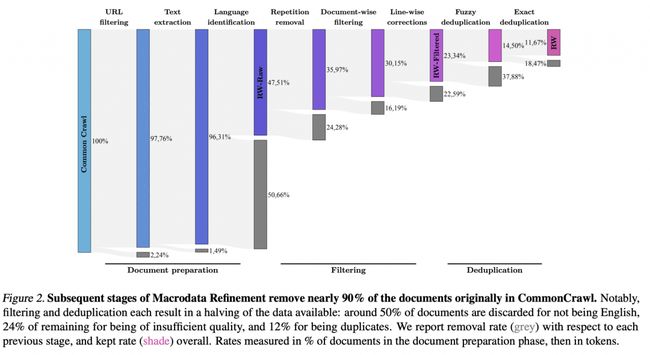
图片来源:The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only. Guilherme Penedo et al. 2023. https://arxiv.org/abs/2306.01116.
这是一个信息量非常丰富的图表,它告诉我们有多少数据被舍弃了。个人而言,我对在去重步骤中被删除的数据量感到印象深刻。
09 结束语
希望您喜欢这篇文章。这篇文章的主要目的是对在训练大型语言模型(LLM)之前需要采取的数据处理步骤和决策进行简要概述。当然,还有其他许多重要的方面,比如不同比例数据集的混合、分词(tokenization)等。鉴于CC数据集一般来说就是LLM训练领域中最大的数据集,因此我决定着重介绍在进行分词之前与该特定数据集直接相关的数据处理处理流程。
在数据预处理流程中,许多设计、策略都是考虑到性能要求而做出的,因为我们处理的是来自CC数据集的大数据块。在我看来,投入更多计算资源可能会在数据方面找到更好的平衡,尤其是考虑到训练LLM的成本。然而,很难预测在数据处理流程中做出不同决策对训练完成的LLM模型会产生怎样的影响,这就是为什么小型实验(small experiments)、人工数据检查(manual data inspection)和探索性数据分析(exploratory data analysis)对于了解具体情况至关重要。
总之,每家公司都拥有符合其需求的数据集。这也是一项需要长期投资的工作,涉及到大量的试验、工程化投入、对细节的注意以及在不确定的情况下进行判断的直觉能力。不过,这同时也是一项长期收益可观的投资。
END
参考资料(可上下滑动)
1.https://arxiv.org/abs/2302.13971v1
2.https://arxiv.org/abs/2306.01116
3.https://arxiv.org/abs/2101.00027
4.https://aclanthology.org/2020.lrec-1.494/
5.https://commoncrawl.org/
6.https://commoncrawl.org/donate/
7.https://commoncrawl.org/the-data/get-started/#WARC-Format
8.https://aclanthology.org/2020.lrec-1.494/
9.https://arxiv.org/abs/2101.00027
10.https://github.com/miso-belica/jusText
11.https://huggingface.co/datasets/tiiuae/falcon-refinedweb
12.https://trafilatura.readthedocs.io/en/latest/
13.https://arxiv.org/abs/2107.06499
14.https://arxiv.org/abs/2304.01373
15.https://github.com/facebookresearch/cc_net/blob/main/cc_net/text_normalizer.py#LL10C1-L10C14
16.https://aclanthology.org/2020.lrec-1.494.pdf
17.https://arxiv.org/abs/2112.11446
18.https://www.cs.princeton.edu/courses/archive/spring13/cos598C/broder97resemblance.pdf
19.https://fasttext.cc/docs/en/language-identification.html
20.https://arxiv.org/abs/1607.01759
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://blog.christianperone.com/2023/06/appreciating-llms-data-pipelines/