kotlin高阶函数
kotlin高阶函数
函数式API:一个函数的入参数为Lambda表达式的函数就是函数式api
例子:
public inline fun Iterable.filter(predicate: (T) -> Boolean): List {
return filterTo(ArrayList(), predicate)
}
上面这段函数: 首先这个函数是一个泛型函数
泛型函数的定义:就是我们在写完一个函数后,只知道一个总的类型,而这个总的类型下有很多继承了这个总类型的类,在返回时我们不知道这个函数具体返回哪个子类,这时我们就可以在这个函数前面加一个泛型,泛型中放这些子类的基类,上面的filter方法也可以看作 Iterable的扩展方法
例子:
// A为基类
public class A{
}
public class B extends A{
}
public class C extends A{
}
// 我们不知道下面这个方法具体返回A,B,C到底哪一个类型时,因为类B和C继承自A,这时我们就可以将这个返回类型指定为基类型A
public static test(){
}
下面我写kotlin的写法
class ReportV2Controller : Controller(){
}
和上面java一样有多个类继承自Controller()这个类,kotlin中继承都是以函数的形式,因为这样写直观的表现了自类具体会调用基类的哪个构造函数
public inline fun Iterable.filter(predicate: (T) -> Boolean): List {
return filterTo(ArrayList(), predicate)
}
上面的filter方法是迭代集合Iterable,但是在kotlin中这个Iterable是一个被inline修饰的内联函数
内联函数的出现的原因:
1.首先在kotlin中有高阶函数的原因,因为高阶函数的传参可以是一个函数,而且出参也可以为一个函数
// 下面这段代码原作者为csdn: Mr YiRan
fun num1AndNum2(num1:Int,num2:Int,operator:(Int,Int)->Int):Int{
val result=operator(num1,num2)
return result
}
上面这段代码高阶函数num1AndNum2入参为两个Int类型与一个函数类型operator,这个operator又接收两个int类型的参数,这个operator返回类型为int,operator返回的类型int同时也是num1AndNum2高阶函数的返回类型,同时num1AndNum2函数的入参数,也可以当作函数operator的入参
fun num1AndNum2(num1:Int,num2:Int,operator:(Int,Int)->Int):Int{
val result=operator(num1,num2)
return result
}
// 定义两个具体的运算函数
fun plus(num1: Int,num2: Int):Int{
return num1+num2
}
fun minus(num1: Int,num2: Int):Int{
return num1-num2
}
fun main(){
val num1=100
val num2=80
// 这是一个函数引用方式的写法,表示将plus()和minus()函数作为参数传递给num1AndNum2()函数
val result1= num1AndNum2(num1,num2,::plus)
val result2 = num1AndNum2(num1, num2, ::minus)
println("result1 is $result1")
println("result2 is $result2")
}
fun main(){
val num1=100
val num2=80
// 上面的函数引用写法的调用可以改为Lambda表达式的方式来调用高阶函数
val result1=num1AndNum2(num1,num2){ n1,n2 ->
n1+n2
}
val result2=num1AndNum2(num1,num2){ n1,n2 ->
n1-n2
}
println("result1 is $result1")
println("result2 is $result2")
}
Lambda表达式的优点与缺点
优点 :
如果一个抽象类或者接口中只有一个方法,我们又不想实例化这个类的对象就想调用这个方法,而且也不想将这个类中的方法标记为静态的方法,就可以用匿名内部类的方式类写,但是这样写代码很不美观,所以就简化成Lambda表达式的方式来写
缺点:
Lambda表达式的方式,系统会默认实例化一个匿名内部类的方式,就会造成额外的内存开销与cpu性能损耗
因为就算高阶函数中的传参写成Lambda表达式的方式,其内部运行顺序也为先实例化最外层类的对象,然后通过对象去引用当前这个对象的方法,将当前对象的方法存入方法区进行压栈然后再实例化一个Lambda表达式的匿名内部类,再通过这个对象去引用这个匿名内部类中的方法,再进行压榨
kotlin是如何解决这种因为传入Lambda表达式写法的性能开销的
内联函数
在定义高阶函数时加上inline关键字,就表示此高阶函数是一个内联函数
inline fun num1AndNum2(num1:Int,num2:Int,operation:(Int,Int)->Int):Int{
val result=operation(num1,num2)
return result
}
如何消除 Lambda表达式额外开销
简单来说就是:在调用传参为 Lambda表达式的高阶函数时,将 Lambda表达式的函数体直接拷贝在调用参数为 Lambda表达式的高阶函数后方
示例
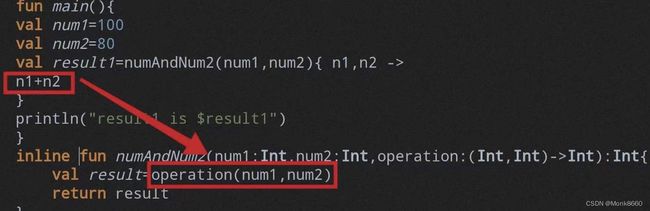
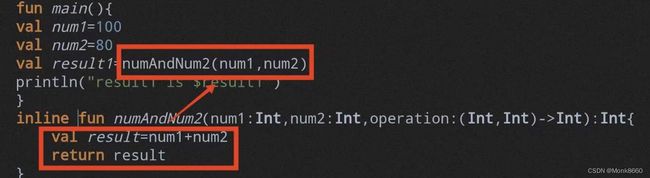
1.首先将 Lambda表达式的入参拷贝到函数类型参数的参数入参列表中
2.其次再将内联函数的方法体拷贝到调用该高阶函数的地方
3.总结为:将实例化匿名内部类调用方法压栈改为方法入参数拷贝和方法体拷贝的过程
下面给一个返回值是一个函数的高阶函数
示例
/**
- 定义一个返回值是函数的高阶函数
- @param name 入场
- @return 返回一个函数或者lambda
*/
fun highFunction2(name:String):(Int) -> Int{
if (name == “A”){
// 这里返回一个函数引用,意思调用returnFun函数
// 上面的highFunction2函数入参为两个一个String类型的name,还有一个入参是一个参数为一个int类型的Lambda表达式
// 如果想调用returnFun函数那highFunction2函数传入的Lambda表达式入参类,数量与顺序必须完全与函数returnFun一致
return ::returnFun
}
//返回lambda
return {a -> a + 10}
}
/**
- 作为高阶函数的返回函数
*/
fun returnFun(a:Int):Int{
return a * 100
}
//使用高阶函数
val res = highFunction2("A")
println(res(20)) //打印2000
val res2 = highFunction2("B")
println(res2(20)) //打印30
扩展函数
fun main() {
open class Shape
class Rectangle: Shape()
fun Shape.getName() = "Shape"
fun Rectangle.getName() = "Rectangle"
fun printClassName(s: Shape) {
println(s.getName())
}
printClassName(Rectangle())
上面函数的最终返回结果是打印"Shape",因为虽然printClassName的函数的传入参数是Rectangle()函数,但是最终会调用Shape类的getName()函数,这是因为最终返回的类型取决于printClassName函数传入参数s的类型
成员函数与扩展函数
如果一个类定义有一个成员函数与一个扩展函数,而这两个函数又有相同的接收者类型、 相同的名字,并且都适用给定的参数,这种情况总是取成员函数
示例
fun main() {
class Example {
fun printFunctionType() { println("Class method") }
}
fun Example.printFunctionType() { println("Extension function") }
Example().printFunctionType()
}
这里最后会输出:“Class method”,因为是以类的成员函数为准的,优先级为先成员函数
如果是扩展类型的重载,那么以传入参数为准
由于静态调用扩展方法是在编译时执行,因此,如果父类和子类都扩展了同名的一个扩展方法,引用类型均为父类的情况下,会调用父类的扩展方法
示例
fun main() {
class Example {
fun printFunctionType() { println("Class method") }
}
fun Example.printFunctionType(i: Int) { println("Extension function") }
Example().printFunctionType(1)
}
最后输出结果为:Extension function
top-level函数
不依赖于任何类的静态函数,经Kotlin编译成Java文件后,成为:<静态函数所在的文件名> + "Kt"的Java类的静态成员函数。如果原kotlin文件的文件名首字母为小写时,转换成大写。
示例
/** joinsample.kt */
package com.example.kotlin
import java.lang.StringBuilder
fun <T> joinToString(
collection: Collection<T>,
separator: String = ", ",
prefix: String = "",
postfix: String = ""
): String {
val result = StringBuilder(prefix)
for ((index, element) in collection.withIndex()) {
if (index > 0) {
result.append(separator)
}
result.append(element)
}
result.append(postfix)
return result.toString()
}
import com.example.kotlin.JoinsampleKt;
import java.util.Arrays;
import java.util.List;
public class JavaSample {
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world");
JoinsampleKt.joinToString(list, ", ", "", "");
}
}
扩展属性
由于扩展没有实际的将成员插入类中,因此对扩展属性来说幕后字段是无效的。这就是为什么扩展属性不能有初始化器。他们的行为只能由显式提供的 getters/setters 定义。
扩展声明为成员
就是说有两个类,可以在其中一个类中为另一个类声明一个扩展函数,被声明的扩展函数,此时是当前类的成员函数
示例
class Host(val hostname: String) {
fun printHostname() { print(hostname) }
}
class Connection(val host: Host, val port: Int) {
fun printPort() { print(port) }
// 这里可以为Host类定义扩展函数,是因为类Connection的主构造函数中将Host类传入进来
fun Host.printConnectionString() {
printHostname() // 调用 Host.printHostname()
print(":")
printPort() // 调用 Connection.printPort()
}
fun connect() {
/*……*/
host.printConnectionString() // 调用扩展函数
}
}
fun main() {
// 这里直接使用类Connection的主构造函数传入Host类然后调用Host的主构造函数,然后调用Host类的printHostname()函数
// 被定义的扩展函数必须在定义该扩展函数的类中使用
// 意思就是说Host的printConnectionString()函数必须在类Connection中使用
// Connection(Host("kotl.in"),443).printConnectionString()
Connection(Host("kotl.in"), 443).connect()
//Host("kotl.in").printConnectionString(443) // 错误,该扩展函数在 Connection 外不可用
}
class Connection {
// 这里给Host类定义一个扩展函数
// 在这个扩展函数中调用toString()
// 因为在kotlin中所有的类都继承自Any类,而toString方法是属于Any类的
// 如果想调用Connection类的toString()方法需要向下面那种写法
// [email protected]()
fun Host.getConnectionString() {
toString() // 调用 Host.toString()
this@Connection.toString() // 调用 Connection.toString()
}
}