数据库基础之——索引&事务
索引(index|key)
1 概念
是数据库内部维护的一套数据结构,专门用于搜索的数据结构。目标就是提升搜索速度(性能)!
数据存储的数据主要保存在硬盘上,维护的索引数据结构同样也保存在硬盘上。(硬盘上的数据,能够持久性的保存,断电后数据依旧存在)
2 索引分类
索引的分类,由于存在不同的分类标准,因此索引分类比较乱。以下介绍几种常用的索引:
(1)使用场景(建索引的时候)
- 主键索引(primary):一个表中,用来区分记录,永远不重复,不为null
- 唯一键(unique):唯一不重复,可以为null
- 普通索引(index/key):提供索引,没有其他约束作用,单纯为了提高查询效率
- 全文索引(full text):搜索场景,提供几个关键词,查找哪些记录中包含这些关键词。目前多被搜索引擎替代
- 空间索引(spacial):高德地图、百度地图等附近空间中搜索
(2)实现原理角度
首先回顾一下搜索专用的数据结构/算法。
1. 数组上遍历搜索。 O(n),只适用于n比较小的时候(n<1w)
2. 有序树上的二分搜索 。适用于n相对比较大,同时数据集基本不变的情况。
3. 搜索树(平衡搜索树)。二叉平衡搜索树(AVL树、红黑树)、B-树系列(多叉平衡搜索树)B+树、R-树系列
4. 哈希表
5. 跳表
接下来整理适用于索引的结构:
- B+树索引:一般提供索引,没有特别声明,都是B+树索引
- 哈希索引:只有少数搜索引擎支持
- R-树索引:只有少数搜索引擎支持
我们接下来主要进行讨论的是InnoDB引擎下的B+树/普通索引/二级索引,其主要目的为提升查询效率!
2.1 什么情况下考虑添加索引?
1. 数据量大到一定程度!O(n)远大于O(log(n))
2. 数据查询的次数远多于数据的修改次数(包含插入/删除/更新)
2.2 索引的hit(命中)和miss的问题。
即如何使用,可以让数据库更容易去使用索引?(属于数据库优化范畴)
一张表中,命中索引被称为 hit,有索引但未命中被称为 miss
(1)在使用索引的时候,只有针对指定的字段作为条件,才能用上索引。
(2)好的索引能带来数据的区分度。
(3)order by也会影响MySQL是否决定使用索引。
(4)聚簇索引(clustered index)和二级索引(secondary index)
MySQL存储引擎:不同存储引擎,具体保存数据的方式不同,带来的特性也不同。
聚簇和二级索引是只针对于MySQL InnoDB引擎下专有的概念。 InnoDB引擎是MySQL自5.5之后的默认存储引擎。

通过一个B+树来保存数据记录本身。key是主键,value是整条记录。可以看做索引,被称为聚簇索引。 在InnoDB引擎下,主键索引就是聚簇索引。

idx_name也是B+树,key是姓名(在姓名上建的索引),value是主键的列表。

2.3 explain命令
通过 explain 命令可以判断是否命中索引,将 explain 命令加载 select 命令前即可
只会将执行计划列出来,不会真正去执行了搜索。
事务(Transaction)
1. 概念
- 事务这个词的含义很广泛,并不一定特指数据库中的事务
- 在开发者看来,一个不可再分的业务动作就是一个事务,这个动作最终表达为一条或者多条 SQL 语句
2. RDBMS事务的4大特性ACID
2.1 原子性(Atomic)
业务动作对应的 SQL 应该是看作一个整体,不可再分的。即:一个事务的执行结果,要么SQL全部成功;要么SQL全部失败。
2.2 持久性(Durability)
持续性也称为永久性,指一个事务一旦提交,它对数据库中数据的改变是永久性的。
2.3 隔离性(Isolation)
最理想的隔离性是,业务方之间感受不到相互的存在,每个业务方都隔离在一个密闭空间中,相互不受影响。
实际上,如果要追求真正的隔离性,就要以牺牲并发性为代价的,所以 SQL 标准制定了隔离级别。
2.4 一致性(Consistency)
一致性是核心,是最终目的!!!属于开发人员+RDBMS(关系数据库管理系统)共同的职责,其余三个特性都为其服务。
针对不同的业务,对数据都有一套约束,这个约束不能被破坏,否则就得认为数据损坏了。
数据库场景下,事务可以分为隐式事务(一条SQL组成)和显式事务(多条SQL组成)。
3. 如何操作事务
3.1 SQL 操作事务
- begin/start transaction:标志开启一个新的事务
- rollback:回滚当前事务,如果事务中的任何一条语句失败,那么这个事务中的所有更改都会撤销
- commit:提交事务,代表事务提交,对事务的操作只有commit才会生效
举例:
begin;
update books set current=current-1 where bid=4;
insert into records(uid,bid,borrowed_at) values(2,4,'2022-12-27 11:34:18';
commit;-- 提交,修改会生效
rollback;-- 回滚,修改不会生效3.2 JDBC操作事务
在使用 JDBC 时,Connection 下有一个 autocommit 属性,会使事务自动提交,默认情况下,此属性值是 true。开启状态下,每个SQL各自是一个整体,每条SQL都可以看做是一个独立的事务(隐式事务)。
因此,需要调整connection对象的autoCommit属性从true-->false,将多条SQL在同一个事务中。
修改之后,不会自动提交,需要用到Connection下的方法:commit和rollback来手动提交和失败。
Connection 创建-->c.setAutoCommit(false)-->N多条SQL-->c.commit()/c.rollback();4. 隔离级别
理想情况下,应该同时使用RDBMS的用户之间互相不影响,但是基本上做不到,或者说如果真的这样执行,性能非常差,只能串行去执行。
串行执行期间会因为顺序发生诸多问题,因此,现实生活中,做了一些妥协,把SQL92标准把隔离性做了隔离级别的区分,供RDBMS根据自己的实际情况进行选择。
读未提交(read uncommitted)
读已提交(read committed)
可重复读(repeated read)
快照读(snapshot read)
串行化(serializable)
4.1 读未提交
多个同时执行的事务,可以读取到其他事务处于未提交时所做的数据修改,可以认为完全没有隔离性,在此隔离级别下会产生副作用——脏读、不可重复读、幻读
脏读:读取到了脏数据,读到了其他事物没有提交的数据修改,其这段数据随时都可能回滚,从而破坏一致性。(看到了CSDN别人草稿箱的东西)
不可重复读,发生在读未提交这种前提下,在同一个事务中,可能出现多次读取同一份数据,但是最终得到的结果不同(有可能读到别的事务已经提交的修改数据)。

4.2 读已提交
一个事务可以看到同时间其他事务提交之后的修改数据。
“读已提交”隔离级别中避免了脏读,但是不可避免 不可重复读和幻读。
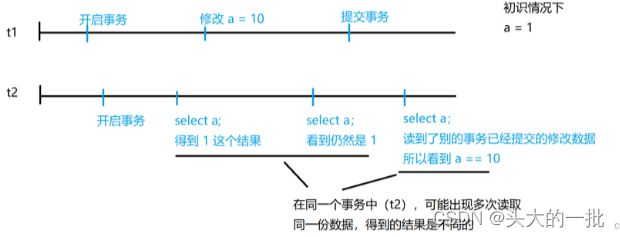
4.3 可重复读
保证了在一次事务中(无提交和回滚),读取到的同一块数据无论何时的值都保持一致,即使别的任务对这块数据做了修改,也不会产生影响。
传统意义上的可重复读避免了脏读和不可重复读,但是仍然避免不了幻读。

幻读:本事务修改了表中的数据,但是在本事务提交之前表中被另一个事务插入了一条数据并且提交了,这样就会导致本数据会看到一条突然出现的 “ 幽灵般的 ” 数据。
出现幻读的原因是:可重复读只针对表中已有的数据做保护,对新添加的数据不做保护
4.4 快照读
快照读其实不是标准中存在的隔离级别,快照读连幻读的副作用都没有,目前来说基本没有副作用MySQL 中的 “ 可重复读 ” 可以看作实际上的 “ 快照读 ”,MySQL 默认情况下的隔离级别就是可重复读
4.5 可串行化
微观视角下,每个事务必须排好队,一次只执行一条事务,每条事务之间完全隔离;宏观视角下,仍然看作 “ 同时进行 ”,但是并发性(性能)差。

MyISAM和InnoDB的区别
