huggingface NLP工具包教程1:Transformers模型
huggingface NLP工具包教程1:Transformers模型
原文:TRANSFORMER MODELS
本课程会通过 Hugging Face 生态系统中的一些工具包,包括 Transformers, Datasets, Tokenizers, Accelerate 和 Hugging Face Hub。
课程简介如下:
- 第 1 章至第 4 章将介绍 Transformers 库。包括 Transformer 模型的工作原理,如何使用 Hugging Face Hub 中的模型,如何在数据集上对其进行微调,并在 Hub 上分享自己的模型。
- 第 5 章至第 8 章介绍了 Datasets 库和 Tokenizer 库,这都是 NLP 任务必须的环节。完成这部分的介绍之后,结合 Transformers 库,就可以自己解决常见的NLP问题了。
- 第 9 章至第 12 章不只包含 NLP ,将介绍如何使用 Transformer 模型来处理语音和视觉中的任务。还会介绍如何构建和共享模型,并针对生产环境优化对其进行优化。

安装
直接使用 pip 安装:
pip install transformers
这样安装得到的是轻量版本的 transformers 库,也就是说,没有安装配套的 Pytorch 和 Tensorflow。由于接下来要经常使用到它们,所以建议直接安装开发者版本,虽然会多花费一些时间和空间,但该版本会将所以依赖项全部一起安装:
pip install transformers[sentencepiece]
自然语言处理简介
在进入介绍 Transformer 模型之前,这里先概述一下什么是自然语言处理以及它有什么应用。
什么是NLP?
NLP是语言学和机器学习的一个领域,试图理解与人类语言相关的一切。NLP任务的目的不仅是单独理解单个单词,而且能够理解这些单词的上下文。以下是常见NLP任务,以及每个任务的一些示例:
- 对整个句子进行分类:获取评论的情感,检测电子邮件是否为垃圾邮件,确定一个句子是否语法正确,或两个句子是否逻辑相关
- 对句子中的每个单词进行分类:识别句子的语法成分(名词、动词、形容词)或命名实体(人、位置、组织)
- 生成文本内容:用自动生成的文本完成提示,用屏蔽词填充文本中的空白
- 从文本中提取答案:给定问题和上下文,根据上下文中提供的信息提取问题的答案
- 从输入文本生成新句子:将文本翻译成另一种语言,文本摘要
NLP并不局限于书面文本。它还解决了语音识别和计算机视觉方面的复杂挑战,例如生成音频样本的抄本或图像描述。
为什么它具有挑战性?
计算机处理信息的方式与人类不同。例如,当我们读到“我饿了”这个句子时,我们很容易理解它的意思。类似地,给定“我饿了”和“我很难过”这两个句子,我们可以很容易地判断它们有多相似。对于机器学习模型,这样的任务很困难,文本处理的方式需要考虑到是否便于模型从中学习。关于如何表示文本已经有了很多研究工作,我们将在下一章中讨论一些方法。
Transformer模型能做什么?
本节将介绍 Transformer 模型到底能做什么,并将使用到 transformers 库中的第一个函数:pipeline() 。该函数是 transfomres 库中的一个重要函数,它将模型及其必要的前处理、后处理步骤集成起来,使得我们能够直接输入文本,并得到答案:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
# 输出:
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
也支持直接传入多个句子:
classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
# 输出:
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
默认情况下,pipeline 会选择一个特定的预训练模型,该模型在英文的情感分析数据集上经过了微调。当我们常见 classifier 对象时,会下载并缓存模型,缓存过的模型再次使用时无需重新下载。
当我们将一段文本传给 pipeline 时,主要包括了三个步骤:
- 通过预处理,将文本转换为模型能够理解的形式
- 将预处理过后的输入传递给模型
- 模型的预测结果经过后处理,得到人类能够理解的输出
目前支持的 pipelines 如下:
feature-extraction(得到文本的向量表示)fill-maskner(命名实体识别)sentiment-analysissummarizationtext-generationtranslationzero-shot-classification
下面介绍其中几个。
Zero-shot classification
我们将从一个比较难的任务开始:对未标记的文本进行分类。这中场景在现实中很常见,因为给文本打标签通常很耗时,且需要领域专业知识。zero-shot-classification pipeline 很强大:我们可以指定用于分类的标签,不依赖于预训练模型的标签。刚才已经介绍过模型如何将句子情感分类为正向或负向,而 zero-shot-classification 可以使用任何我们指定的标签对文本进行分类。
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
# 输出:
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
zero-shot ,顾名思义,我们不需要在自己的数据上微调模型。它可以直接返回我们想要的标签列表的概率分数。
text-generation
现在我们来看一下如何使用 pipeline 进行文本生成。主要的思想就是由我们提供一个 prompt(提示词),模型会自动补全(续写)prompt 后面的部分。文本生成具有随机性,所以我们输入同样的 prompt 得到不同的结果是正常的。
from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
Copied
# 输出:
[{'generated_text': 'In this course, we will teach you how to understand and use '
'data flow and data interchange when handling user data. We '
'will be working with one or more of the most commonly used '
'data flows — data flows of various types, as seen by the '
'HTTP'}]
可以通过 num_return_sequences 参数来控制生成不同序列的个数,通过 max_length 参数来控制生成文本的总长度。
在pipeline中使用Hub中的模型
在之前的例子中,都是使用 pipeline 中对应各个任务默认的模型,实际上在使用 pipeline 时,我们也可以选择 Hub 中的模型。比如,对于文本生成,到 Model Hub 中,点击左侧对应 tag 来查看某个特定任务的模型,也就是来到这样一个页面。
这里我们使用 distilgpt2 模型,以下是在 pipeline 中加载制定模型的方式:
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
# 输出:
[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
'move your mental and physical capabilities to your advantage.'},
{'generated_text': 'In this course, we will teach you how to become an expert and '
'practice realtime, and with a hands on experience on both real '
'time and real'}]
还可以通过制定语言 tag 来进一步搜索想要的模型,然后选择一个可以生成其他语言的模型。Hub 中甚至有一些权重文件是支持多种语言的。
在选定一个模型之后,会有一个小部件来直接在线尝试。这样,就可以在下载模型之前快速测试其功能。在浏览器中直接测试模型能力使用的是 Inference API,可以在 Hugging Face website 查看。在该页面,可以直接与模型交互,输入一些自己的文本,然后观察模型处理输入数据的过程。Inference API 也有付费版本,可以在 定价页面 查看。
Mask filling
接下来要介绍的 pipeline 是 fill-mask。该任务是要填充给定文本的空白部分:
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about models." , top_k=2)
# 输出:
[{'sequence': 'This course will teach you all about mathematical models.',
'score': 0.19619831442832947,
'token': 30412,
'token_str': ' mathematical'},
{'sequence': 'This course will teach you all about computational models.',
'score': 0.04052725434303284,
'token': 38163,
'token_str': ' computational'}]
top_k 参数指定返回的结果的种类数。需要注意的是,该模型填充了一个特殊的
Named entity recognition
在命名实体识别(NER)任务中,模型需要找到输入文本中哪些部分是实体,如人名,地名,机构名等。
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
# 输出:
[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
]
上例中模型准确识别出了 Sylvain 是一个人名(PER),Hugging Face 是一个机构名(ORG),Brooklyn 是一个地名(LOC)。
我们在 pipeline 创建函数中传入参数 grouped_entities=True,告诉 pipeline 将句子中对应于同一实体的部分重新组合在一起:在上例中,模型将 “Hugging” 和 “Face” 正确地分组为一个机构名,尽管实体名由多个单词组成。事实上,预处理可能会将一些单词分割成更小的部分。例如,Sylvain 被分成四部分:S、##yl、##va、##in。在后处理步骤中,pipeline 会将它们重新组合成正确的单词。
Question answering
问答任务会根据给定文本的信息回答问题。
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
# 输出:
{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
注意该 pipeline 是通过在给定文本中抽取部分信息作为答案,而非生成答案。
Summarization
摘要任务是将一个文本缩减为一个较短的文本,同时保留文本中的所有(或大部分)重要内容。
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
# 输出:
[{'summary_text': ' America has changed dramatically during recent years . The '
'number of engineering graduates in the U.S. has declined in '
'traditional engineering disciplines such as mechanical, civil '
', electrical, chemical, and aeronautical engineering . Rapidly '
'developing economies such as China and India, as well as other '
'industrial countries in Europe and Asia, continue to encourage '
'and advance engineering .'}]
像文本生成一样,也可以指定结果的最大长度或最小长度。
Translation
翻译任务,我们可以通过在任务名中指定语言对(如 translation_en_to_fr)来使用默认的模型,但是更方便的方式是从 Model Hub 中挑选模型。这里以法语翻英语为例:
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")
# 输出:
[{'translation_text': 'This course is produced by Hugging Face.'}]
同样可以指定最大长度和最小长度。
目前展示的 pipeline 主要是介绍一些用法。它们是为特定任务而设计的,无法是用它们的变体。在下一节中,将介绍 pipeline() 函数内部的内容以及如何自定义其行为。
Transformers如何工作
本节将从较高的视角来概览一下 Transformer 模型的架构。
Transformer历史
下图是 NLP 领域 Transformer 模型历史的一些参考节点
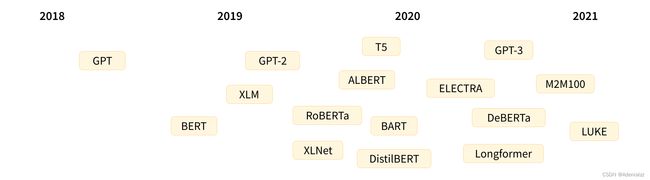
Transformer 架构最早于 2017 年 6 月被提出,最初被用于解决机器翻译任务。随后有一系列颇具影响力的工作:
- June 2018: GPT,第一个 Transformer 预训练模型,可以在各种 NLP 任务上微调
- October 2018: BERT, 另一个大型预训练模型,BERT 用于产生更好的句子表示
- February 2019: GPT-2,升级版(并且更大的)GPT,由于伦理道德的原因,并未直接公开
- October 2019: DistilBERT,一个蒸馏版本的 BERT,速度快了60%,内存节省了40%,并保持了 BERT 97% 的性能
- October 2019: BART and T5,两个大型预训练模型,它们使用了与原始 Transformer 模型相同的架构
- May 2020, GPT-3,GPT-2 的更大版本,不需要微调,就可以在许多任务上表现得很好,这称为零样本学习(zero-shot learning)
当然,除了这个列表之中的模型还有许多相关工作,这里列出只是为了突出几种不同类型的Transformer模型。大体上,它们可以分为三类:
- GPT-like,也称为自回归式 Transformer 模型
- BERT-like,也称为自编码式 Transformer 模型
- BART/T5-like,也称为 seq2seq 式 Transformer 模型
稍后将更为详细地介绍这三类模型。
Transformer是语言模型
上述所有 Transformer 模型(GPT、BERT、BART、T5等)都是作为语言模型(Language Model)进行训练。也就是说,他们以自监督的方式在大量无标签文本上进行训练。自监督学习是一种训练方式,其中目标函数是根据模型的输入自动生成的。即不需要人类来标记数据。
这类模型建立了对语言的统计理解,但一般不能直接用于实际任务。因此,一般的预训练模型会经历一个称为迁移学习的过程。在这个过程中,模型通过有监督的方式进行微调,即在给定任务上使用带人工标签的数据进行训练。自监督训练任务的一个例子是,在阅读了前面 n 个单词之后,预测句子中的下一个单词。这被称为 causal language modeling,因为输出依赖于过去和现在的输入,而不是未来的输入。

另一个语言模型的例子是 masked language modeling,它需要预测句子中被掩码遮盖的单词。

Transformer是大模型
除了极少数以轻量化为目的的 Transformer 模型(如 DistilBERT),一个通用的提高模型性能的策略是同时增大模型的尺寸和数据的规模(大力出奇迹)。
遗憾的是,训练模型,尤其是大模型,需要大量数据。这在时间和计算资源方面变得非常昂贵。它甚至转化为环境影响,如下图所示。

这是一个由一个团队领导的(非常大的)模型项目,该团队试图减少预培训对环境的影响。运行大量试验以获得最佳超参数的 footprints 将更大。想象一下,如果每次一个研究团队、一个学生组织或一家公司想要训练一个模型,它都会从头开始。这将导致巨大的、不必要的全球成本!这就是为什么共享语言模型是至关重要的:共享经过训练的权重并在已经训练的权重基础上构建,可以降低社区的总体计算成本和 carbon footprint。
预训练(Pretraining)是指从头训练一个模型,在开始时权重会随机初始化,也不会有任何的先验知识。预训练通常需要在非常大规模的语料库数据上进行,通常持续数周。

微调(Fine-tuning),是指在模型完成预训练之后进行的训练过程。在开始微调之前,首先需要拿到一个大型的、预训练过的语言模型,然后再在自己特定的数据集上进行有监督训练。为什么不直接在最终的任务上进行训练呢?有以下原因:
- 预训练模型已经在与微调数据集相似的数据集上进行了训练。因此,微调过程能够利用初始模型在预训练期间获得的知识(例如,对于NLP问题,预训练模型将对任务所使用的语言有某种统计理解)。
- 由于模型已经在大规模数据上进行过预训练,微调只需要较少的数据就能得到不错的结果。
- 另外,训练所需要的时间和资源也降低不少。
例如,可以利用一个经过英语训练的预训练模型,然后在 arXiv 语料库上对其进行微调,从而形成一个基于科学/研究的模型。微调只需要很少的数据量:预训练模型获得的知识是 “迁移的”(transfered),因此称为转移学习(transfer learning)。
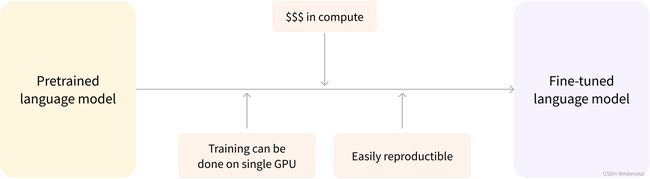
因此,微调模型具有更低的时间、数据、财务和环境成本。迭代不同的微调方案也更快、更容易,因为训练比完全预训练约束更少。这个过程也会比从头开始的训练取得更好的结果(除非有大量的数据),这就是为什么要利用预训练模型——一个尽可能接近我们手头任务的模型——并对其进行微调。
整体架构
本节将简要介绍 Transformer 模型的整体架构。
引言
- 编码器(左侧):编码器接收输入并构建出输入的表示(特征)。即,编码器通过训练来试图理解输入
- 解码器(右侧):解码器使用编码器得到的表示(特征)和另外一些输入,来生成目标序列。即,解码器通过训练来生成输出。
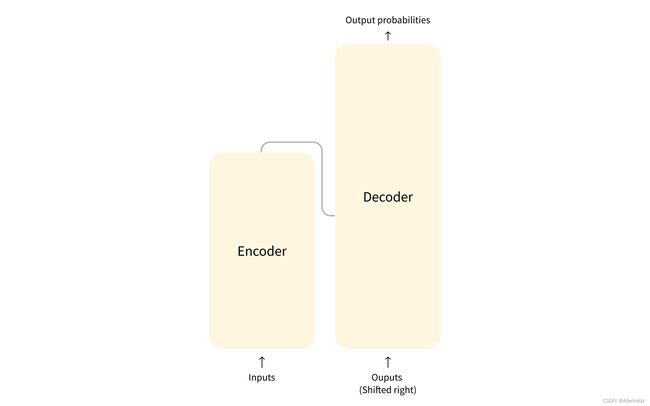
上述部分都可以独立使用,具体使用哪一部分取决于任务:
- 仅有编码器的模型:适合于需要理解输入的任务,比如句子分类和命名实体识别。
- 仅有解码器的模型:适合于生成式的任务,比如文本生成。
- 编码器-解码器模型(或者称为 seq2seq 模型):适合于生成式,且也需要理解输入的任务,比如机器翻译和文本摘要。
后面会展开讲。
注意力层
Transformer 模型的一个关键结构是注意力层。事实上,正如提出 Transformer 架构的论文的标题所说:“Attention is all you need”!我们将在本课程的稍后部分探讨注意力层的细节。现在,从整体上来理解:该层将告诉模型在处理每个单词的表示时,要特别注意序列中的某些单词(并或多或少忽略其他单词)。
举个例子,在英语翻法语的任务中,给定输入“You like this course”,翻译模型还需要关注相邻单词 “You”,以获得单词 “like” 的正确翻译,因为在法语中,动词“like” 的变化取决于主语。然而,句子的其余部分对该词的翻译没有帮助。同样,在翻译 “this” 时,模型需要注意单词 “course”,因为 “this“ 的翻译方式不同,取决于相关名词是阳性还是阴性。同样,句子中的其他单词对于 “this” 的翻译也无关紧要。对于更复杂的句子(以及更复杂的语法规则),该模型需要特别注意可能出现在句子中更远的单词,从而正确翻译每个单词。
同样的概念适用于与自然语言相关的任何任务:一个单词本身就有意义,但这种意义受到上下文的深刻影响,上下文可以是被研究单词之前或之后的任何其他单词。
现在我们已经整体上了解了注意力层是什么,那么让我们来仔细看看Transformer架构。
原始架构
Transformer 架构最初设计用于机器翻译。在训练期间,编码器接收特定语言的输入(句子),而解码器接收所需目标语言的相同句子。在编码器中,注意力层可以使用句子中的所有单词(因为,正如我们刚才看到的,给定单词的翻译可能取决于句子中的前后内容)。然而,解码器按顺序工作,只能注意它已经翻译的句子中的单词(因此,只有当前生成的单词之前的单词)。例如,当我们预测了翻译目标的前三个单词时,我们将它们提供给解码器,解码器随后使用编码器的所有输入来尝试预测第四个单词。
为了在训练过程中加快速度(训练时模型能够看到目标句子),会将整个目标句子输入给解码器,但不允许它使用后面的单词(如果它在尝试预测位置 2 的单词时能够访问位置 2 的词,那就不要预测了)。例如,当试图预测第四个单词时,注意力层只能访问位置 1 到 3 的单词。原始的 Transformer 架构如下所示,编码器在左侧,解码器在右侧:

注意,解码器中的第一个注意力层关注解码器的所有(过去的)输入,但第二个注意力层使用编码器的输出。因此,它可以根据整个输入句子,来预测当前单词。这非常有用,因为不同的语言可能有语法规则,将单词按不同的顺序排列,或者句子后面提供的上下文可能有助于确定给定单词的最佳翻译。注意掩码也可以在编码器/解码器中使用,以防止模型注意某些特殊单词。例如,当将句子分批在一起时,用于使所有输入具有相同长度的特殊填充词。
Architectures与checkpoints
当我们在本课程中深入研究 Transformer 模型时,将反复提到 architecture 和 checkpoints 以及 model。这些术语的含义略有不同:
- architecture:这是模型的结构——每个层的定义以及模型中发生的每个操作。
- checkpoints:这些是将在给定架构中加载的权重。
- model:这是一个总括术语,不像 “architecture” 或 “checkpoints” 那么精确。它可以同时表示两者。
例如,BERT是一种 architecture,而BERT-base-cased(谷歌团队 BERT 的第一个版本训练的一组权重)是一个 checkpoints。然而,人们可以说 “BERT model” 和“BERT-base-cased model”
Encoder模型
编码器模型仅使用 Transformer 的编码器。在每个阶段,注意力层都可以访问初始句子中的所有单词。这些模型通常具有 “双向” 关注的特点,通常称为自编码模型。这些模型的预训练通常围绕着以某种方式破坏给定的句子(例如,通过掩码掉其中的随机单词),并让模型寻找或重建初始句子。编码器模型最适合于需要理解完整句子的任务,例如句子分类、命名实体识别(以及更一般的单词分类)和抽取式问答。
这一系列模型的代表包括:
- ALBERT
- BERT
- DistilBERT
- ELECTRA
- RoBERTa
Decoder模型
解码器模型仅使用 Transformer 的解码器。在每个阶段,对于给定的单词,注意力层只能访问句子中位于其前面的单词。这些模型通常称为自回归模型。解码器模型的预训练通常围绕着预测句子中的下一个单词。这些模型最适合于涉及文本生成的任务。
这一系列模型的代表包括:
- CTRL
- GPT
- GPT-2
- Transformer XL
sequence-to-sequence模型
编码器-解码器模型(也称为 sequence-to-sequence 模型)使用 Transformer 架构的两部分。在每个阶段,编码器的注意力层可以访问输入句子中的所有单词,而解码器的注意力层只能访问位于当前单词之前的单词。这类模型的预训练可以使用编码器或解码器模型的目标来完成,但通常涉及一些更复杂的事情。例如,T5通过用一个掩码特殊词替换随机的文本跨度(可以包含几个单词)来进行预训练,其目的是预测该掩码词所替换的文本。seq2seq 模型最适合于根据给定输入生成新句子的任务,例如文本摘要、机器翻译或生成性问答。
这一系列模型的代表包括:
- BART
- mBART
- Marian
- T5
局限性与偏见
如果想要在生产中使用预训练模型或微调版本,请注意,尽管这些模型是强大的工具,但它们也有局限性。其中最大的一点是,为了能够对大量数据进行预培训,研究人员通常会收集所有他们能找到的内容,从互联网上获得最好的和最坏的信息。
举个例子,我们回到使用 BERT 模型的 fill-mask pipeline 的示例:
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print([r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print([r["token_str"] for r in result])
# 输出:
['lawyer', 'carpenter', 'doctor', 'waiter', 'mechanic']
['nurse', 'waitress', 'teacher', 'maid', 'prostitute']
当要填写这两个句子中缺失的单词时,模型只给出了一个性别无关的答案(waiter/waitress)。其他的职业通常与一个特定的性别相关,prostitute (妓女)在与“woman” 和 “work” 相关的前五位可能性中名列前茅。尽管 BERT 是少数几个数据不来自互联网的Transformer模型之一,而是使用比较中立的数据(它是根据英语维基百科和BookCorpus数据集训练的),他还是会出现这种情况。因此,在使用这些工具时,需要记住,这些预训练模型很容易产生性别歧视、种族主义或同性恋内容。根据标注数据对模型进行微调不会使这种固有偏见消失。