编译原理实验之语法分析
一、实验目的
编写一个语法分析程序,实现对词法分析提供的单词序列的检查和结果分析。
二、实验要求
用高级语言编写程序,实现对简单语言的语法分析
(1)待分析语言的文法

(2)实验要求说明
输入简单语言,并以 “#” 结尾,输出栈里的内容及其相应的行为,如果成功,打印success,否则打印error。
三、实验过程
本次实验采用的是LL(1)方法,使用的是Java语言编写
1. 求First和Follow

2. 构造预测分析表
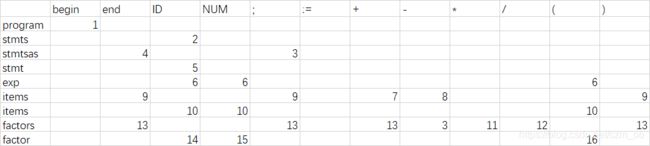
(1) 对文法生成式编号
- program -> begin stmts end
- stmts -> stmt stmtsas
- stmtsas -> ; stmt stmtsas
- stmtsas -> ε
- stmt -> ID := exp
- exp -> item items
- items -> + item items
- items -> - item items
- items -> ε
- item -> factor factors
- factors -> * factor factors
- factors -> / factor factors
- factors -> ε
- factor -> ID
- factor -> NUM
- factor -> (exp)
(2)预测分析表
(3)测试用例
测试用例1(正确用例):
begin
x := (3 +5) / 2;
y :=(4 - 1 * x) * 2;
y := x
end #
对应输出:

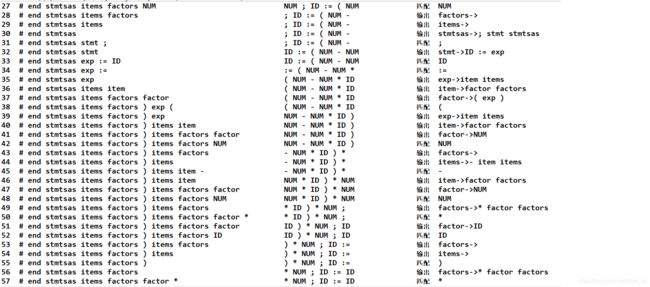

输出的success表示测试通过.
测试用例2(错误用例):
begin
x := (3 +5) / 2;
y :=(4 - 1 * x) * 2;
y := x;
end #
对应输出:
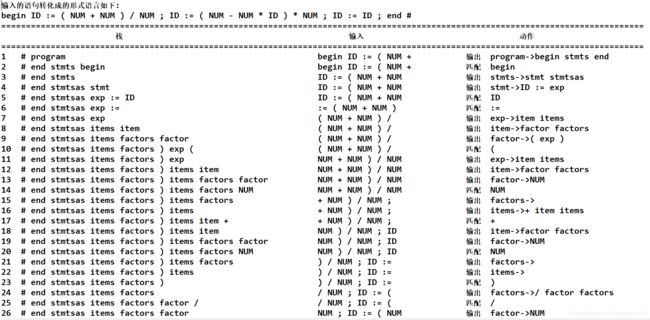


输出的error表示测试失败.
3. 分析
(1) 试比较测试用例1和测试用例2,会发现测试用例2只在 “end #” 前面多加了个 “;”, 从测试用例的结果(第三张图75行处)来看,出错在栈顶元素为stmt,输入的首单词为end处,查看预测分析表,发现在表中stmt行、end列并没有相应的产生式,故出错。但是正常情况下每行语句后都应有";"表示结束,故我们可以在分析表中的此处加入产生式stmt -> ε,即可解决此问题。
(2) 这个问题是所给文法存在缺陷而造成的,故读者可以根据实际情况来修改,加入的产生式体现在代码71行处,供读者参考。
四、完整代码
主体部分:
package grammar;
import java.io.IOException;
import java.util.Stack;
public class Grammar
{
//预测分析表
private String[][] LL1_table = new String[9][12];
//非终结符
private String[] vn = {"program", "stmts", "stmtsas", "stmt", "exp", "items", "item", "factors", "factor"};
//终结符
private String[] vt = {"begin", "end", "ID", "NUM", ";", ":=", "+", "-", "*", "/", "(", ")"};
//定义栈
private Stack<String> a = new Stack<>();
//将栈里的内容拼接成字符串输出
private StringBuilder sstack = new StringBuilder();
//将输入串的前6位(不包括已匹配的单词)拼接成字符串显示
private StringBuilder sin = new StringBuilder();
//作为每一个<栈, 输入, 动作>的行序号
private int cnt = 1;
/**
* 查找非终结符
* @param s
* @return
*/
public int find_vn(String s)
{
for(int i = 0; i < vn.length; i++)
if(s.equals(vn[i]))
return i;
return -1;
}
/**
* 查找终结符
* @param s
* @return
*/
public int find_vt(String s)
{
for(int i = 0; i < vt.length; i++)
if(s.equals(vt[i]))
return i;
return -1;
}
/**
* 手动建立预测分析表
* 行表示终结符、列表示非终结符
* 分别对应vn[]和vt[]
*
* //stmtsas ->
* LL1_table[2][1] = ""; 表示的是stmtsas -> ε
* LL1_table[2][4] = "; stmt stmtsas"; 表示的是stmtsas ->; stmt stmtsas
*/
public void LL1()
{
//program ->
LL1_table[0][0] = "begin stmts end";
//stmts ->
LL1_table[1][2] = "stmt stmtsas";
//stmtsas ->
LL1_table[2][1] = "";
LL1_table[2][4] = "; stmt stmtsas";
//stmt ->
// LL1_table[3][1] = ""; //加入此产生式后,在测试用例的最后一条语句后面(即end前)加";",可使测试用例通过
LL1_table[3][2] = "ID := exp";
//exp ->
LL1_table[4][2] = "item items";
LL1_table[4][3] = "item items";
LL1_table[4][10] = "item items";
//items ->
LL1_table[5][1] = "";
LL1_table[5][4] = "";
LL1_table[5][6] = "+ item items";
LL1_table[5][7] = "- item items";
LL1_table[5][11] = "";
//item ->
LL1_table[6][2] = "factor factors";
LL1_table[6][3] = "factor factors";
LL1_table[6][10] = "factor factors";
//factors ->
LL1_table[7][1] = "";
LL1_table[7][4] = "";
LL1_table[7][6] = "";
LL1_table[7][7] = "";
LL1_table[7][8] = "* factor factors";
LL1_table[7][9] = "/ factor factors";
LL1_table[7][11] = "";
//factor ->
LL1_table[8][2] = "ID";
LL1_table[8][3] = "NUM";
LL1_table[8][10] = "( exp )";
}
/**
* 按空格进行切割,并将其倒叙入栈
* @param s
*/
public void split(String s)
{
String[] str = s.split(" ");
for(int i = str.length - 1; i >= 0; i--)
if(str[i] != "") //为空, 不入栈
a.push(str[i]);
}
/**
* 输出栈的内容
* @param s
*/
public void out1(String[] s)
{
//清空字符串sstack
sstack.delete(0, sstack.length());
//将栈的内容拼接成字符串
for(String s1 : a)
sstack.append(s1 + " ");
//输出栈里的元素,并设置为60个宽度
System.out.printf("%-4d%-60s", cnt, sstack.toString());
}
/**
* 显示输入的内容
* 由于输入可能很大,最多只显示未匹配的前6项
* @param s
* @param x
*/
public void out2(String[] s, int x)
{
//清空字符串sin
sin.delete(0, sin.length());
//拼接输入串的前6个单词
for(int i = x; i <= x + 5; i++)
{
//不显示null
if(s[i] == null) break;
sin.append(s[i] + " ");
}
//显示输入串的前6个单词,并设置为30个宽度
System.out.printf("%-30s", sin.toString());
}
/**
* 主方法
* 对字符串数组s[]里的内容进行预测分析时执行的步骤,并将其输出
* 判断是否匹配成功,并输出
* @param s
* @throws IOException
*/
public void scan(String[] s) throws IOException
{
System.out.println("输入的语句转化成的形式语言如下:");
//将输入的语句转换为形式化语言
for(String s1 : s)
{
if(s1 == null) break;
System.out.print(s1 + " ");
}
System.out.println();
for(int i = 0; i < 130; i++)
System.out.print("=");
//设置宽度保证其在各自区域的中间
System.out.printf("\n%-50s%-100s%-70s%s\n", " ", "栈", "输入", "动作");
for(int i = 0; i < 130; i++)
System.out.print("=");
System.out.println();
a.push("#"); //栈底元素入栈
a.push("program"); //开始符号入栈
LL1(); //输入预测分析表
out1(s); //输出栈里的内容
int x = 0;
while(!a.isEmpty())
{
while(a.peek().equals(s[x])) //栈顶的终结符与输入相等
{
String sss = a.pop(); //栈顶元素出栈,并赋值给sss
out2(s, x); //输出输入信息
System.out.println("匹配 " + sss); //输出匹配动作
cnt++; //行序号加一
//栈为空,匹配成功,结束
if(a.isEmpty())
{
System.out.println("success");
return;
}
else //不为空,继续
{
out1(s); //输出栈里的内容
}
x++;
}
int i = this.find_vn(a.peek()); //非终结符下标
int j = this.find_vt(s[x]); //终结符下标
if(i == -1 || j == -1 || this.LL1_table[i][j] == null) //匹配失败
{
out2(s, x);
System.out.println("\nerror");
return;
}
else //成功找到,替换栈顶的非终结符
{
a.pop(); //将产生式左部出栈
this.split(this.LL1_table[i][j]); //产生式右部入栈
out2(s, x); //输出输入信息
System.out.println("输出 " + vn[i] + "->" + this.LL1_table[i][j]); //输出推导动作
cnt++; //行序号加一
out1(s); //输出栈里的内容
}
}
}
}
测试部分:
package grammar;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import lexical.Lexical;
public class Test
{
public static void main(String[] args)
{
try
{
BufferedReader br = new BufferedReader(new FileReader("F:\\Grammar.txt"));
//调用词法分析的主函数scan,得到str[],供语法分析使用
Lexical l = new Lexical();
l.scan(br);
//调用语法分析的主函数scan
Grammar g = new Grammar();
g.scan(l.str);
}
catch (IOException e)
{
e.printStackTrace();
}
}
}