YOLOv6 论文学习
1. 解决了什么问题?
吸收了学术圈和工业界最新的目标检测方法,包括网络结构、训练策略、测试技巧、量化和优化方法。
作者有如下几点发现:
- 目前还没有人深入研究 RepVGG 重参数化对检测任务的影响。直接缩放 RepVGG 模块的效果并不好,对于小模型而言,简单的单通道结构更好,但对于大模型来说,参数量会呈指数增加,计算量极其高昂。
- 对重参数化的检测器做量化要格外小心,因为训练和推理时的网络结构不一致会导致性能大幅度退化。
- 考虑到网络结构的变化,标签分配策略和损失函数设计需要进一步验证。
- 我们可以接受改善模型表现而不增加推理成本的方案,比如知识蒸馏。
2. 提出了什么方法?
YOLOv6 涉及了网络设计、标签分配、损失函数、数据增强、量化和部署等。
2.1 网络设计
主干网络
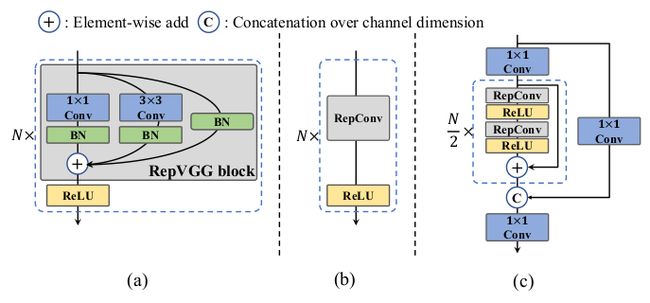
主干网络对于检测模型的性能影响重大。多分支网络比单分支网络能取得更好的分类表现,但并行程度低,并增加推理延迟。像 VGG 这样的单分支计算并行程度高、内存占用少,推理效率更高。RepVGG 是一个结构重参数方法,将训练时的多分支结构与推理时的单分支结构解耦,实现速度-准确率的平衡。
作者提出了一个高效的重参数化主干网络,叫做 EfficientRep。在小模型中,训练阶段时主干网络的主要构成就是 RepBlock,如下图(a) 所示。在推理阶段,如下图(b) 所示,每个 RepBlock 都转换为一组 3 × 3 3\times 3 3×3卷积层及 ReLU 激活函数。在主流的 GPU 和 CPU 上, 3 × 3 3\times 3 3×3卷积都高度优化了,能达到很高的计算密度。因此,EfficientRep 主干网络能充分利用硬件的计算能力,降低推理延迟、增强表征能力。
但作者发现,随着模型体积的增大,单通路网络的计算成本和参数量会呈指数增长。于是作者设计了 CSPStackRep 模块,作为大中型网络的主干部分。如下图©,CSPStackRep 模块包括三个 1 × 1 1\times 1 1×1卷积层和一组子模块(训练时包括两个 RepVGG 模块,推理时包括两个 RepConv,以及一个残差连接)。此外,cross stage partial(CSP) 连接用于提升表现,不会增加多少计算成本。
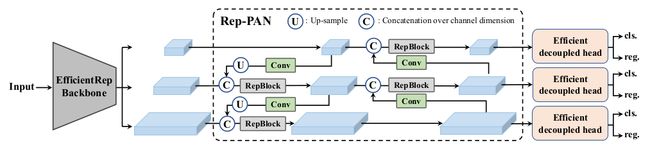
Neck
YOLOv6 采用了 PAN 结构,延续了 YOLOv4 和 YOLOv5。使用 RepBlocks(小模型) 或 CSPStackRep(大模型) 来代替 YOLOv5 的 CSPBlocks,得到 Rep-PAN。
Head
YOLOv5 使用了一个耦合的 head,分类和回归分支的参数是共享的。而 FCOS 和 YOLOX 则解耦了两个分支,在每个分支中增加了两个 3 × 3 3\times 3 3×3卷积层来提升表现。在 YOLOv6,作者采用了一个 hybrid-channel 策略,构建更高效的解耦 head,将中间 3 × 3 3\times 3 3×3卷积层的个数降低为一个。Head 的宽度与主干和 neck 的宽度是协同缩放的。这样降低了计算成本和推理延迟。
Anchor-free
Anchor-free 检测器具有更优的泛化性和简洁性。后处理时间被大幅缩短。有两类 anchor-free 检测器:基于 anchor point 的和基于关键点的。YOLOv6 采用了 anchor point 范式,边框回归分支预测的是 anchor point 到边框四条边的距离。
2.2 标签分配
标签分配是在训练阶段,将标签分配给预先定义的 anchors。评测了多个标签分配策略,发现 TAL 效果更好,训练更稳定。
SimOTA
OTA 将目标检测的标签分配看作为最优运输问题。它从全局的角度定义每个 ground-truth 目标的正负样本。SimOTA 是 OTA 的简化版,降低了超参数个数。作者发现,SimOTA 会降低训练速度,可能造成训练不稳定。
Task Alignment Learning
TAL 首先由 TOOD 提出,该度量将分类得分和预测框质量统一起来考虑。使用该度量代替 IoU 来分配目标标签。这样,分类和回归任务不对齐的问题得到一定缓解。
TOOD 另一个贡献就是提出了任务对齐 head(T-head)。T-head 堆叠卷积层来构建交互特征,在其上是任务对齐预测器(TAP)。PP-YOLOE 将 T-head 的层注意力替换为轻量的 ESE 注意力,得到 ET-head。本文作者发现,ET-head 会降低推理速度,无法提升准确率。因此,作者保留了原设计。
此外,作者发现 TAL 要比 SimOTA 带来更多的性能提升,而且训练更稳定。因此作者采用了 TAL 作为分配策略。
2.3 损失函数
目标检测包括两个子任务:分类和定位,分别对应分类损失和边框回归损失。作者选用了 VariFocal Loss 作为分类损失,SIoU/GIoU 作为回归损失。
分类损失
Focal Loss 改进了传统的交叉熵损失,解决正负样本、容易困难样本不均衡的问题。为了解决训练和推理时,边框定位质量预测与分类不一致的问题,QFL 使用分类得分和定位质量的联合表征进一步拓展 Focal Loss。VariFocal Loss 源于 Focal Loss,但它对待正负样本并不一样,正负样本具有不同的重要度,从而平衡学习信号。
边框回归损失
IoU 系列损失
IoU 损失将预测边框的四条边看作为一个整体,它与评测时的度量保持了一致,因而更加高效。它现在有许多的变体,如 GIoU、CIoU、DIoU、SIoU 等。
概率损失
DFL 将边框的位置看作为一个离散的概率分布。它考虑了数据的模糊性与不确定性,没有引入额外的先验,有助于提升模型的定位准确性,尤其是当边框的边界是模糊的。DFLv2 设计了一个小网络,基于分布统计和实际定位质量之间的关系,提升检测表现。但是 DFL 通常输出 17 × 17\times 17×的回归数值,造成不小的计算成本,对于小模型来说不友好。在 YOLOv6-M/L 中,作者使用了 DFL。
目标损失
FCOS 引入的目标损失,降低低质量边框的得分,从而在后处理时能被滤掉。YOLOX 也使用了,加速收敛,提升准确率。但是在 YOLOv6,作者并没有发现什么效果。
2.4 其他技巧
训练更多的 Epochs
作者将训练时长从 300 个 epochs 增加到 400 个 epochs,能达到更好的收敛。
自蒸馏
为了进一步提升模型准确率,而不增加计算成本,作者使用了知识蒸馏技巧,最小化教师模型和学生模型预测结果之间的 KL 散度。教师模型就是学生模型自身,但经过了预训练,所以叫自蒸馏。KL 散度一般用于评价数据分布之间的差异。目标检测有两个子任务,只有分类任务能基于 KL 散度,直接利用知识蒸馏。但通过 DFL 损失,我们也能对边框回归使用知识蒸馏。知识蒸馏损失写作:
L K D = K L ( p t c l s ∣ ∣ p s c l s ) + K L ( p t r e g ∣ ∣ p s r e g ) L_{KD}=KL(p_t^{cls} || p_s^{cls}) + KL(p_t^{reg}|| p_s^{reg}) LKD=KL(ptcls∣∣pscls)+KL(ptreg∣∣psreg)
其中 p t c l s , p s c l s p_t^{cls},p_s^{cls} ptcls,pscls是教师模型和学生模型的类别预测结果, p t r e g , p s r e g p_t^{reg},p_s^{reg} ptreg,psreg是回归预测结果。总体损失如下:
L t o t a l = L d e t + α L K D L_{total}=L_{det}+\alpha L_{KD} Ltotal=Ldet+αLKD
其中 L d e t L_{det} Ldet是目标检测损失。 α \alpha α平衡两个损失。在训练开始阶段,教师模型的软标签很容易学习。随着训练的持续,学生模型的表现会追上教师模型,这时硬标签对学生模型更有帮助。因此作者使用了余弦退火来调节 α \alpha α,动态地调节硬标签和教师模型软标签的信息。
图像的灰色边界
在 YOLOv5 和 YOLOv7 评测模型时,会在图像周围增加一圈灰色边界,它能改善图像边缘目标的检测效果。
这一圈灰色像素会降低推理速度,但没有它们的话,模型表现会退化。作者猜测这与 Mosaic 增强的灰色边界有关系。作者修改了灰色边界的面积,将图像缩放为原图大小。这样,模型的表现得到了提升,推理速度没有下降。
量化和部署
对于工业部署,一般会采用量化对推理做加速,而且性能不会下降。PTQ 使用一个小型校准集来直接量化模型。而 QAT 则使用训练集进一步提升性能,通常与蒸馏一起使用。但由于 YOLOv6 的重参数化模块,PTQ 和 QAT 并没什么用。
重参数化优化器
RepOptimizer 提出在每一优化步骤进行梯度重参数化。该技术也很好地解决了重参数模型的量化问题。作者于是重新构建了 YOLOv6,用 RepOptimizer 来训练,得到 PTQ 友好的权重。特征图的分布大幅度变窄了,这对量化过程非常有帮助。

敏感性分析
作者将量化敏感的操作部分转换为浮点计算,提升 PTQ 表现。为了获得敏感性分布,采用了均方误差(MSE)、信噪比(SNR)和余弦相似度度量。通常,人们可以挑选某一层激活函数后的特征图,计算量化前后的上述度量。也可以将某一层的量化开启或关闭,然后计算其验证集 AP。
通道蒸馏的 QAT
作者觉得 PTQ 不够,又使用 QAT 提升量化后表现。为了解决训练和推理时 fake quantizers 的不一致,有必要基于 RepOptimizer 来进行 QAT。如下图,在 YOLOv6 中使用了通道蒸馏,它也是一个自蒸馏方法,教师网络是 FP32 的学生网络。
