LLaMA 2: Open Foundation and Fine-Tuned Chat Models
LLaMA 2: Open Foundation and Fine-Tuned Chat Models
- Pre-training
- Fine-tuning
- Reward model
- RLHF
- 参考
Pre-training
数据层面:
预训练语料比LLaMA1多了40%,一共2T tokens,更关注了高质量数据的清洗。
其中数据不包含Meta产品与服务,并且尽量的移除了 private individu als。
模型架构层面:
与LLaMA 1 基本一致,RMSNorm + ROPE + SWiGLU。
主要区别是引入了 grouped-query atttention 和 context length 从 2048->4096.
超参数:
训练Loss:
在训练图中发现还没有发现饱和的征兆。
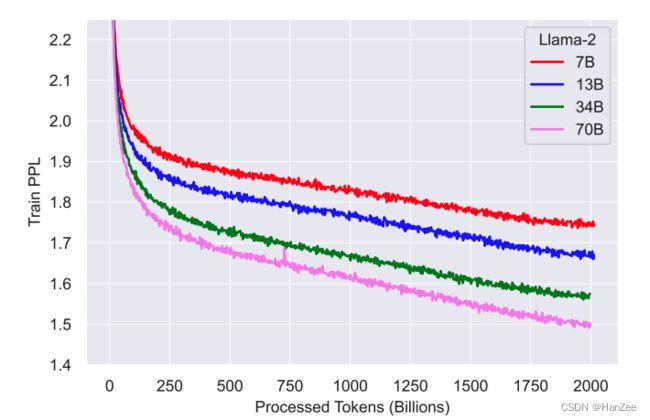
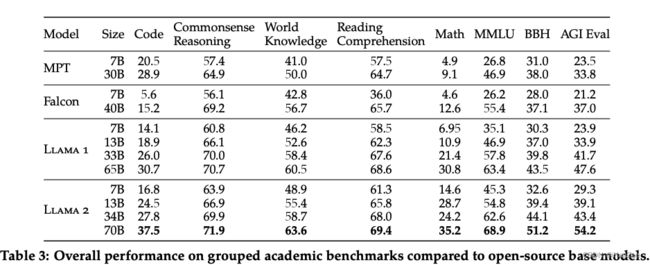
评估结果:
Fine-tuning
数据的质量 is all you need.其中作者发现,收集 10k左右的高质量数据就可以实现一个还不错的结果。这里一共收集了27540条QA数据。但是不包含meta用户信息。
作者发现不用平台、运营商标注的相同领域数据可能导致不同的结果,作者认为数据检查十分重要。
Fine-tuning 细节:
拼接input、output用一个特殊token,只计算output loss。
![]()
Reward model
数据标注:在InstructGPT中,通过不同的prompt输出9个不同的response,然后给这9个排名。
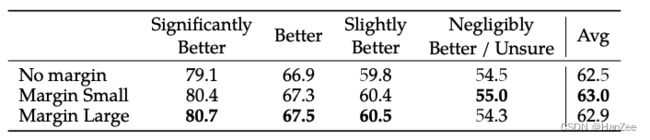
Meta只需要同一个prompt 通过不同的prompt、model等只输出两个response,然后对着两个标注排名,此外,还需要标注 这两个你标注的response排名 的confidence,也就是你有多大把握这样排,分为四个等级:
- significant better
- better
- slightly better
- unsure
之后要求labeler自己编写prompt 由浅入深,为了训练更稳定。
然后还需要标注信息 这两个response 是否安全,分为:
prefered 安全, rejected 不安全 (18%)
都安全 (47%)
都不安全 (35%)
然后, prefered 不安全, rejected 安全的样本都被删掉了, 因为meta 相信更安全的回复应当被人类更偏好。
此外还收集了额外的偏好数据:
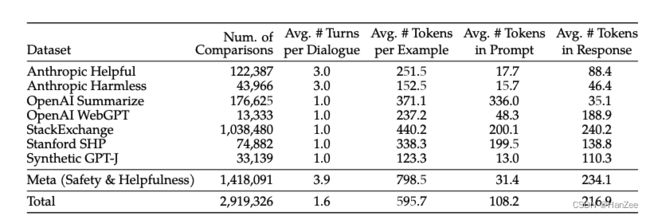
引入其他的偏好数据实际上是违背了Meta标注的初衷,但是通过实验发现混合后,效果不会变差,也可以起到正则的作用。
reward model:
作者认为一个奖励模型可能不能很好的处理有用性和安全性,所以作者准备分别训练两个奖励模型,为了让奖励模型更好的理解什么是对话,两个模型都以SFT后的检查点作为初始化。
![]()
Loss与InstructGPT的loss很像,让两个不同排名的奖励差距尽可能大,不同的是多了m函数。
其中m是一个离散函数,对应之前标注的确定程度。
数据配比:
在helpfulness奖励模型上,meta的数据与开源数据 1:1
在safety奖励模型上, meta safety和anthropic harmless的数据,然后又混合了helpful和开源数据 比例为90:10.
超参数:learning rate: 70B 用的5e-6, 其他都用1e-5. cosine decay, down to 10% of the maximum learning rate. We use a warm-up of 3% of the total number of steps, with a minimum of 5. The effective batch size is kept fixed at 512 pairs, or 1024 rows per batch.
结果:

之后作者发现,奖励模型的性能越好,最终在llama2-chat上面的性能也就越好。
RLHF
Rejection Sampling
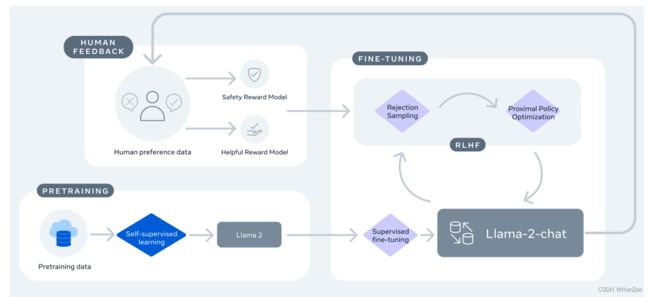
这是一种监督学习的方式,通过SFT后的模型,prompt model 对同一个input 生成N个 output,然后通过奖励模型对多个response利用奖励模型打分,选择得分最高的,这样就收集了更符合奖励模型篇好的数据。
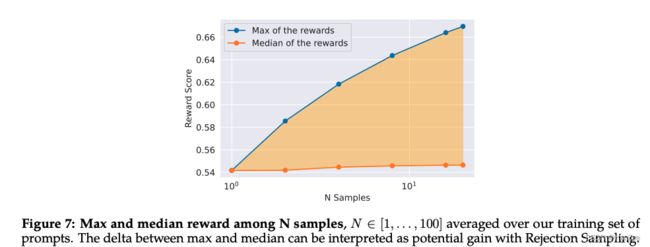
对于同一个input,生成不同的response对 Reward score的影响:
之后作者还测试了不同的 temperature 对 reward score的影响:
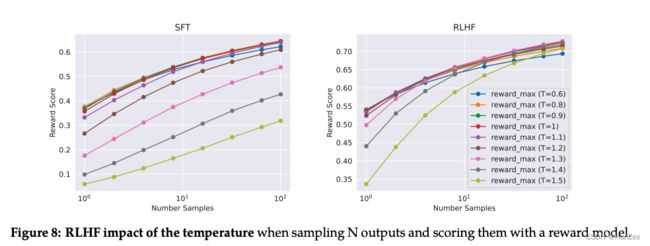
在 10 到 100 个输出之间采样时的最佳温度为1.2-1.3 。
了解Rejection sampling,RLHF的流程如下图:

PPO:
PPO与InstructGPT中介绍的基本类似,主要是奖励模型不一致,改为了Helpfulness和Safety奖励模型的混合。

PPO的loss为:
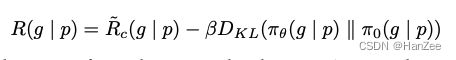
参考
https://scontent-hkt1-2.xx.fbcdn.net/v/t39.2365-6/10000000_662098952474184_2584067087619170692_n.pdf?_nc_cat=105&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=RYfzDCymkuYAX9_S8GO&_nc_ht=scontent-hkt1-2.xx&oh=00_AfDLNhReR8DuItMWjMFDSjhlh1yHYjiAbdD4f0pVxDAWTA&oe=64C25B7F
https://zhuanlan.zhihu.com/p/644697081