Hadoop生态体系-2
目录标题
-
- 1、MapReduce介绍
- 2、数据仓库
- 3、HIVE
- 4、HQL
-
- 4.1 hive读写文件机制
- 4.2 Hive数据存储路径
1、MapReduce介绍
思想:分而治之
map:“分”,即把复杂的任务分解为若干个“简单的任务”来处理。可以进行拆分的前提是这些小任务可以并行计算,彼此之间没有依赖关系
Reduce:“合”,对map阶段的结果进行全局汇总
MapReduce 是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序
map 阶段处理的数据如何传递给 reduce 阶段,这个流程就叫 shuffle
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快
2、数据仓库
数据仓库,英文名称为 Data Warehouse,可简写为 DW 或 DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。它出于分析性报告和决策支持目的而创建。
特征:
数据仓库是面向主题的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和时变的(Time-Variant )数据集合,用以支持管理决策 。
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing,)
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing)
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认
为是 ETL(抽取 Extract, 转化 Transform , 装载 Load)的过程
3、HIVE
hive是基于hadoop的一个数据仓库工具,可以将结构化数据文件映射成一张数据库表,并提供类SQL查询功能。
本质:将SQL转换为MapReduce程序

HIVE组件:
用户接口
元数据存储
解释器、编译器、优化器、执行器
HIve与hadoop的关系:hive利用HDFS存储数据,利用mapreduce查询分析数据.
Metadata 即元数据
Metastore 即元数据服务,作用是:客户端连接 metastore 服务,metastore再去连接 MySQL 数据库来存取元数据。
metastore 服务配置有 3 种模式:内嵌模式、本地模式、远程模式
4、HQL
数据定义语言 (Data Definition Language, DDL),是 SQL 语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言。create、drop、alter
HQL 中 create 语法(尤其 create table)将是学习掌握 DDL 语法的重中之重。
Hive 数据类型整体分为两个类别:原生数据类型(primitive data type)和复杂数据类型
原生数据类型包括:数值类型、时间类型、字符串类型、杂项数据类型;
复杂数据类型包括:array 数组、map 映射、struct 结构、union 联合体
- 英文字母大小写不敏感;
- 除 SQL 数据类型外,还支持 Java 数据类型,比如:string;
- int 和 string 是使用最多的,大多数函数都支持;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用
原生类型从窄类型到宽类型的转换称为隐式转换
4.1 hive读写文件机制
SerDe 是 Serializer、Deserializer 的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。
Hive 使用 SerDe(和 FileFormat)读取和写入行对象。
SerDe的语法:
row format delimited | serde
其中 ROW FORMAT 是语法关键字,DELIMITED 和 SERDE 二选其一。
如果使用 delimited 表示使用默认的 LazySimpleSerDe 类来处理数据。如果数据文件格式比较特殊可以使用 ROW FORMAT SERDE serde_name 指定其他的Serde 类来处理数据,甚至支持用户自定义 SerDe 类。
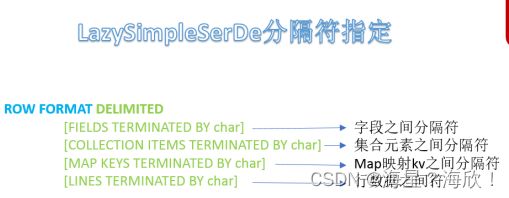
hive 建表时如果没有 row format 语法。此时字段之间默认的分割符是’\001’,是一种特殊的字符,使用的是 ascii 编码的值,键盘是打不出来的。
4.2 Hive数据存储路径
默认存储路径:/user/hive/warehouse
指定存储路径:location语法,location ‘指定路径’