【Redis深度专题】「核心技术提升」探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群功能分析)
探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群功能分析)
- Redis集群的出现背景
-
- 提升性能
- 扩展性
- Redis集群概述
-
- Redis Cluster特性分布
- Redis Cluster的Failover机制
-
- Redis集群节点宕机
-
- 集群如何判断节点是否挂掉
- 集群进入失败状态的必要条件
- Failover概念定义
- Failover组成部分
- Failover设计原则
- Failover执行流程
- Redis Cluster的流程步骤
- Redis的投票机制
-
- 注意事项
- Redis集群部署
-
- 安装Redis
- 环境准备
-
- Redis安装脚本指令
-
- vm.overcommit_memory值的设置
-
- 内存使用问题
- overcommit_memory参数配置
- 启动Redis服务
- 关闭Redis服务
- 修改配置文件
-
- 配置主从复制集群
- 创建单台服务器多redis节点
-
- 复制配置文件
- 修改配置端口
- 启动Redis服务
- 查看Redis服务
- 创建Redis集群
-
- 搭建安装Ruby环境
-
- 安装了Ruby和RubyGems
- 安装扩展依赖库
- 启动Redis集群服务
-
- 实际案例介绍
- 先测试网络连通性
- 创建集群指令
- 问题分析
-
- 原因rvm版本过低
-
- 解决方案
- 查看现在版本为2.3.3则对
- 资源文件未重置和清理
- 解决方案
- Redis集群操作的演示效果
Redis集群的出现背景
Redis是单线程的,但通常作为缓存使用足够了,因为它具有非常快的读写速度。根据官方的简单测试,使用50个并发执行100,000个请求。每个请求设置和获取一个256字节的字符串。测试结果显示读取速度为110,000次/秒,写入速度为81,000次/秒。
提升性能
考虑到这样快速的读写速度,在一般的应用程序中已经足够满足需求。然而,对于高访问量的网站来说,可能还有一些提升性能的空间。那么,如何提升Redis的性能呢?搭建集群是最佳选择之一。
扩展性
通过搭建Redis集群,可以将数据分布在多个节点上,从而提高整体的读写容量和负载能力。Redis集群能够自动将数据分片存储,并且具备主从复制,故障转移等功能,确保数据的可靠性和可用性。通过增加节点数量,可以进一步提高Redis的性能和扩展性。
因此,Redis作为缓存使用时,由于其快速的读写速度,对于一般的应用程序来说足够满足需求。然而,对于高访问量的网站来说,搭建Redis集群是提升性能的最佳选择之一。集群可以增加整体的读写能力和负载容量,并提供数据可靠性和可用性的保障。
Redis集群概述
自Redis 3.0版本之后,Redis开始支持Cluster功能(因此您需要安装3.0版本或更高版本的Redis)。
Redis Cluster特性分布
-
节点自动发现:Redis Cluster能够自动发现加入集群的节点信息。
-
主从选举和集群容错:当主节点发生故障时,Redis Cluster会自动进行主从选举,确保集群的高可用性。
-
在线分片(Hot Resharding):Redis Cluster支持在线分片操作,可以动态地调整数据分片,实现负载均衡和容量扩展。
-
进群管理:Redis Cluster提供了方便的命令(cluster xxx)进行集群管理操作。
-
基于配置文件的集群管理:Redis Cluster通过nodes-port.conf配置文件来管理集群的相关信息。
-
ASK和MOVED转向机制:当客户端请求的数据不在当前节点时,Redis Cluster会使用ASK或MOVED转向机制将请求重定向到正确的节点上。
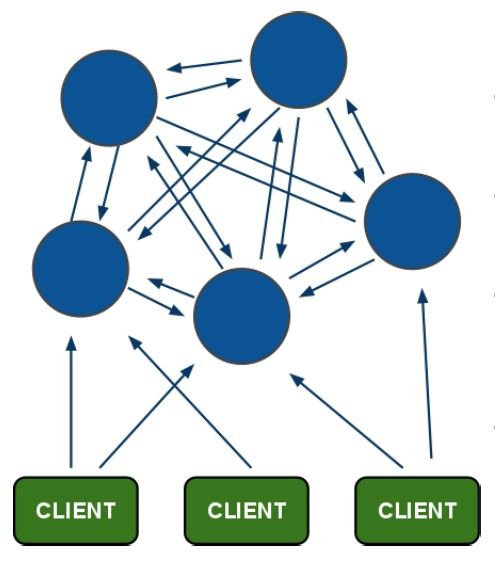
Redis Cluster是一个强大的分布式解决方案,从Redis 3.0版本开始支持。它具备自动发现、主从选举和容错、在线分片、集群管理等特性,为高可用性和可伸缩性的需求提供了解决方案。
Redis Cluster的Failover机制
Redis集群节点宕机
Redis集群是由多个Redis节点一起工作的,为了保证集群的可靠性,每个节点都应该至少有一个备用的Redis服务,也称为从节点(slave)。
集群如何判断节点是否挂掉
集群中的每个节点都存储着所有主节点和从节点的信息。它们通过相互之间的ping-pong通信来判断节点是否可连接。如果超过半数以上的节点在尝试ping一个节点时未能收到回应,集群就会将该节点标记为宕机,并尝试连接它的备用节点。
集群进入失败状态的必要条件
-
A. 如果某个主节点和其所有从节点都已宕机,集群将进入失败状态。
-
B. 如果集群中超过半数以上的主节点都宕机,无论是否有从节点,集群都将进入失败状态。
-
C. 如果集群中的任意主节点宕机且当前主节点没有从节点,集群也将进入失败状态。
因此增加从节点可以增强Redis集群的稳定性和容错性。
Failover概念定义
Failover是一种系统设计和实现的机制,旨在确保在主节点(Master)故障或不可用时能够无缝切换到备用节点(Slave)以保持服务的连续性和可用性。
Failover组成部分
在一个Failover系统中,通常有一个主节点和多个备用节点,当主节点出现故障时,备用节点会接管其角色并继续提供服务,以保证系统的正常运行。Failover可应用于各种系统和服务,如数据库集群、网络负载均衡器、高可用性服务器集群等。
Failover设计原则
Failover设计通常由两个关键部分组成:故障判定和Leader选举。
在Redis Cluster中,采用了去中心化(Gossip)的设计,每个节点通过发送Ping(包括Gossip信息)/Pong心跳的方式来检测其他节点的存活状态。当一个节点超过心跳超时时间没有响应时,该节点会被标记为PFail,意味着该节点可能失败了,可能是由于网络故障、分区等原因
导致通信失败。
Failover执行流程
一个节点之间的故障检测和Failover的过程,以及集群中Master节点之间的意见交换和Leader选举的机制。主要的内容包括:
- 节点A给节点B发送Ping/Pong心跳,如果超时则将B标记为PFAIL,表示A认为B节点失败。
- 要完全判定B失败,需要通过一种协商的方式,集群中一半以上的Master节点认为B处于PFail状态,才会正式将节点B标记为Fail。
- 使用Gossip协议进行信息交换,在节点A给C发送Ping的同时,A将已知节点随机挑选三个节点添加到Ping包中发给C。
- 经过多次Gossip后,A会将自己认为处于PFail状态的B节点告诉C,C将A节点添加到B节点的失败报告链表中。
- 集群中所有节点之间多次Gossip,一旦B的失败报告数量超过Master数量的一半以上,就立即标记B为Fail并广播给整个集群。
- 为避免误判,失败报告添加了一个有效期,在一定的时间窗口内,失败报告的数量超过Master的一半以上才标记为Fail。
- Redis Cluster中的Leader选举类似于Raft算法,但不同之处在于并不是slave之间进行投票,而是在所有Master节点中进行投票,这样即使是一主一从的情况下也能完成选举,避免资源浪费。
这些机制和策略可以确保在分布式系统中节点的故障被及时检测到,并进行有效的故障处理和切换,从而保障系统的连续性和可用性。
Redis Cluster的流程步骤
在Failover发生时,Redis Cluster会执行以下步骤:
-
对于已经被标记为PFail的节点,其他正常节点会通过发送Ping消息来检测其是否真的无法响应。
-
如果一个节点在一定时间内无法复活(即无法恢复正常响应),其他正常节点将参与到Leader选举过程中。
-
Leader选举是一个分布式协同的过程,正常的节点会通过共享信息和相互比较来选举出一个新的Master节点。
-
选出的新Master节点将接管原Master的数据,并开始提供服务。
Failover实现了Redis Cluster中的高可用性,通过去中心化的设计和Ping/Pong心跳机制,节点能够自动检测和处理故障节点,实现快速而可靠的主从切换。这种设计保证了Redis Cluster在面对节点故障时仍能持续提供稳定的服务。
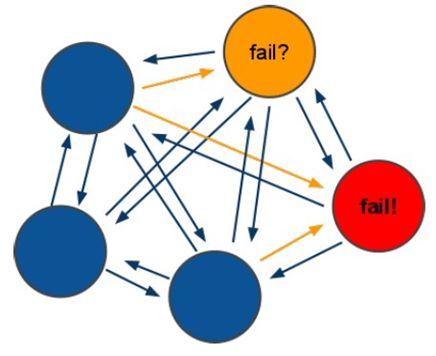
Redis的投票机制
-
投票过程是集群中所有主节点参与,如果超过半数以上的主节点与某个主节点通信超时(cluster-node-timeout),则认为该主节点挂掉。
-
选举新主节点的依据顺序为:网络连接正常 -> 5秒内回复过INFO命令 -> 10*down-after-milliseconds内与主节点连接过 -> 从服务器优先级 -> 复制偏移量 -> 运行ID较小。选出新主节点后,通过slaveof命令将其中一个从节点升级为新主节点。
-
使用slaveof命令让其他从节点复制新主节点的数据。
-
当旧主节点重新连接时,它会被设置为新主节点的从节点。需要注意的是,如果客户端与旧主节点分离,写入的数据在恢复后会由于旧主节点复制新主节点的数据而丢失。
-
集群中的每个节点都有1个至N个复制品,其中一个是主节点,其余是从节点。如果主节点下线,集群会将其中一个从节点升级为新的主节点,确保集群不会因为一个主节点的下线而停止工作。
注意事项
- 如果某个主节点及其所有从节点都下线,Redis集群将停止工作。Redis集群不能保证数据的强一致性,在特定情况下,已执行的写命令可能会丢失。
- 使用异步复制是Redis集群可能会丢失写命令的其中一个原因。在网络断开时间太长的情况下,Redis集群会启用新的主节点,之前发送给主节点的数据将会丢失。
Redis集群部署
安装Redis
- 官方网站
环境准备
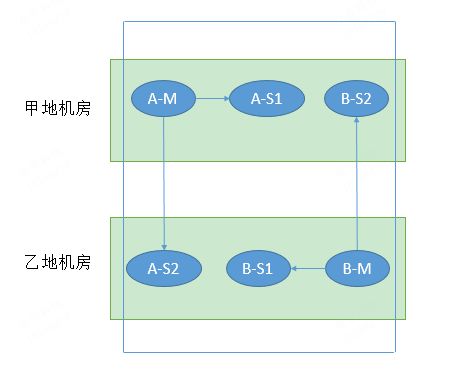
环境上面主要有两个服务器:服务器A上有三个Redis实例,分别监听端口6379,6380和6381。服务器B上也有三个Redis实例,分别监听端口6382,6383和6384。需要注意的是,在每台服务器上,要安装相同版本的Redis。这样做可以提供多个实例以增强性能和可靠性,并且确保Redis版本一致性以便于管理和维护。
-
服务器A准备:
- 服务器ip:10.0.0.1
- 端口6379
- 端口6380
- 端口6381
-
服务器B准备:
- 服务器ip:10.0.0.2
- 端口6382
- 端口6383
- 端口6384
-
两台服务器都准备了多个Redis实例,并且要求安装的Redis版本相同。
以上是对服务器A和服务器B的准备情况的总结。
Redis安装脚本指令
#Redis安装
wget http://download.redis.io/releases/redis-x.x.x.tar.gz
tar xzf redis-x.x.x.tar.gz
cd redis-x.x.x/src
make MANIFESTO=jemalloc && make PREFIX=/usr/local/redis-x.x.x install
ln -s /usr/local/redis-x.x.x /usr/local/redis
echo ' PATH=/usr/local/redis/bin/:$PATH' >> /etc/profile
source /etc/profile
vm.overcommit_memory值的设置
内存使用问题
Redis的数据回写机制有同步和异步两种。同步回写使用 SAVE 命令,主进程直接向磁盘回写数据,但对于大量数据会导致系统假死;异步回写使用 BGSAVE 命令,主进程fork出新的进程,通过这个新进程回写磁盘,不会导致假死,通常被默认采用。
修复问题后,通过修改 /etc/sysctl.conf 文件中的内核参数,将 vm.overcommit_memory 设置为1,然后运行命令 “sysctl -p” 使配置生效。
overcommit_memory参数配置
如果 “overcommit_memory” 值为0,则需要修改内核参数。在 /etc/sysctl.conf 文件中添加一行 “vm.overcommit_memory = 1”,然后重启系统使配置生效。或者执行命令 “sysctl vm.overcommit_memory=1” 使配置立即生效。
#设置内核参数
sysctl vm.overcommit_memory=1
sed -i "s#daemonize no#daemonize yes#g" /data/redis/conf/redis.conf
“vm.overcommit_memory” 是一个Linux内核参数,它用于控制内存分配策略。下面是三种取值的解释:
-
0:这个取值表示内核会进行内存检查,以确保系统中有足够的可用内存。当程序请求分配内存时,内核会检查当前系统的可用内存是否足够满足分配请求,如果不足则拒绝分配。这种模式下,会更加保守地分配内存,以避免系统因为过度分配而导致内存不足。
-
1:这个取值表示内核允许分配所有的物理内存,而不进行内存检查。当程序请求分配内存时,内核不会检查系统的可用内存情况,而是简单地根据请求的大小进行分配。这种模式下,内核相信系统中的应用程序可以理性地管理内存,即使系统的实际可用内存不足,也允许分配内存,这可能会导致系统出现内存不足的情况。
-
2:这个取值表示内核允许超过物理内存和交换空间总和的内存分配。这种模式被称为"无视"模式(“overcommit”),内核允许分配更多的内存,即使实际可用内存不足。这是一种比较激进的内存分配策略,它假设系统中的应用程序不会同时请求超过可用内存的分配,即使分配超过可用内存,也可以通过调用到后续的内存回收机制,如写入交换空间或OOM(Out of Memory)killer来解决内存不足的问题。
注意,选择适当的取值需要根据具体的应用场景和系统配置进行权衡。如果系统具有充足的物理内存并且应用程序对内存需求有良好的控制,可以考虑使用取值为1或2,以提高内存利用率。然而,如果系统的物理内存较为有限或者对内存分配的可控性要求较高,可以选择取值为0,以确保系统不会因为过度分配而导致内存不足。
启动Redis服务
mkdir /data/redis/conf -p
cp /redis-x.x.x/redis.conf /data/redis/conf/
redis-server -f /data/redis/conf/redis.conf
关闭Redis服务
redsi-cli shutdown
killall redis-server
修改配置文件
配置主从复制集群
port 6379 //先默认端口,等会再改
bind 本机ip //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群
daemonize yes //redis后台运行
pidfile /var/run/redis_6379.pid //pidfile文件对应
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes_6379.conf //集群的配置文件
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
appendonly yes
- 两台主机的配置文件都要进行以下修改:
- 端口(port):默认为6379,可以根据需要进行修改。
- 绑定IP(bind):默认为本机IP地址(127.0.0.1),需要改为其他节点机器可访问的IP地址,以便在创建集群时可以访问到对应的端口。
- 后台运行(daemonize):设置为yes,让Redis以后台进程的形式运行。
- PID文件(pidfile):指定存放进程ID的文件路径及文件名,例如/var/run/redis_6379.pid。
- 开启集群(cluster-enabled):去掉注释符号“#”,开启Redis集群功能。
- 集群配置文件(cluster-config-file):指定集群的配置文件路径及文件名,例如nodes_6379.conf。
- 请求超时时间(cluster-node-timeout):默认为15秒(15000毫秒),可以根据需要进行自定义设置。
- 启用AOF持久化(appendonly):设置为yes,开启AOF持久化机制。
创建单台服务器多redis节点
配置服务器A多Redis实例启动操作步骤,主要方案就是拷贝上述所生产的攻关redis.conf文件,并且进行拷贝,从而生成对应的多个节点下面的不同的端口的redis服务实例。
主要分为四个步骤操作:
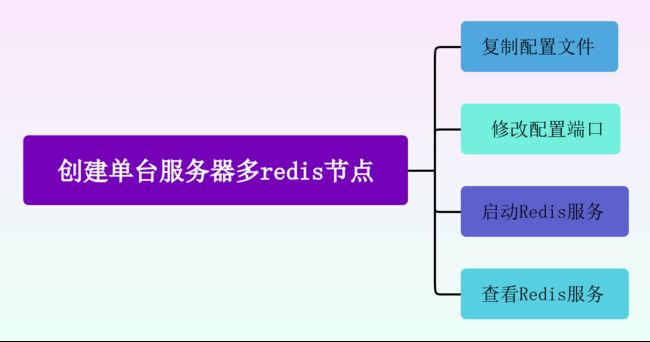
复制配置文件
cp /data/redis-x.x.x/redis.conf /data/redis/conf/6379.conf
cp /data/redis-x.x.x/redis.conf /data/redis/conf/6380.conf
cp /data/redis-x.x.x/redis.conf /data/redis/conf/6381.conf
修改配置端口
sed -i "s/6379/6379/g" /data/redis/conf/6379.conf
sed -i "s/6379/6380/g" /data/redis/conf/6380.conf
sed -i "s/6379/6381/g" /data/redis/conf/6381.conf
启动Redis服务
redis-server /data/redis/conf/6379.conf
redis-server /data/redis/conf/6380.conf
redis-server /data/redis/conf/6381.conf
查看Redis服务
查看是否启动成功以及查看redis监听端口。
ps -ef | grep redis
netstat -tnlp | grep redis
另一台服务器也是相类似的操作即可。
创建Redis集群
现在,我们已经准备好了可以搭建Redis集群的节点。接下来的步骤是将这些节点连接起来,形成一个集群。为了完成这个任务,Redis官方提供了一个工具叫做redis-trib.rb,它的路径是/usr/local/redis-3.2.1/src/redis-trib.rb。需要注意的是,这个工具是通过Ruby编写的,因此在使用之前我们还需要安装Ruby环境。
搭建安装Ruby环境
安装了Ruby和RubyGems
安装Ruby和RubyGems是一个相对简单的过程,以下是一些常见的安装方法:
-
使用包管理器安装:
-
如果您使用的是Ubuntu或Debian系统,可以使用apt包管理器执行以下命令来安装Ruby和RubyGems:
sudo apt-get update sudo apt-get install ruby rubygems -
如果您使用的是CentOS或RHEL系统,可以使用yum包管理器执行以下命令来安装Ruby和RubyGems:
sudo yum install ruby rubygems
-
-
使用Ruby版本管理器安装:
-
RVM (Ruby Version Manager) 是一个流行的工具,可让您在同一系统上安装和管理多个Ruby版本。您可以按照RVM官方文档的指导安装RVM,并通过它来安装Ruby和RubyGems。
\curl -sSL https://get.rvm.io | bash -s stable source ~/.rvm/scripts/rvm rvm install ruby -
rbenv 是另一个常用的Ruby版本管理器,可以帮助您在同一系统上安装和切换不同的Ruby版本。您可以按照rbenv官方文档的指导安装rbenv,并通过它来安装Ruby和RubyGems。
git clone https://github.com/rbenv/rbenv.git ~/.rbenv echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc echo 'eval "$(rbenv init -)"' >> ~/.bashrc source ~/.bashrc git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build rbenv install ruby -
安装完成后,您可以使用以下命令验证Ruby和RubyGems的安装是否成功:
ruby --version gem --version
-
请根据您的操作系统和偏好选择适合您的安装方法,并确保按照安装指南操作。如果您遇到任何问题,请随时向我提问。
安装扩展依赖库
两台服务器都已经安装了Ruby和RubyGems,并且我们还需要安装一些依赖库。执行以下命令来安装这些库:
yum -y install gcc openssl-devel libyaml-devel libffi-devel readline-devel autoconf
yum -y install zlib-devel gdbm-devel ncurses-devel gcc-c++ automake
之后,我们可以使用gem命令来安装Redis接口,gem是Ruby的一个工具包。在安装之前,我们需要更换一下源。执行以下命令来更换源:
gem source -l
gem source --remove http://rubygems.org/
gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/
gem source -l
然后,执行以下命令来安装Redis:
gem install redis
启动Redis集群服务
要完成Redis集群的搭建,首先需要确保所有节点已经启动,并确认两台服务器的防火墙已关闭,以避免出现无法路由到达的错误。下面是一些操作步骤:
-
确保所有节点已启动:
- 在每台服务器上运行适当的命令或脚本,以启动Redis实例。确保所有节点都已成功启动,并没有出现任何错误。
-
检查防火墙状态:
- 在每台服务器上检查防火墙的状态,并确保它们都已关闭。可以使用适当的命令或配置文件来关闭防火墙,以便确保Redis集群中的节点可以互相通信。
-
配置Redis集群:
- 使用redis-trib.rb或其他合适的工具进行配置。例如,使用以下命令可以使用redis-trib.rb工具来配置Redis集群:
其中,redis-trib.rb create --replicas: : : ... : :
- 使用redis-trib.rb或其他合适的工具进行配置。例如,使用以下命令可以使用redis-trib.rb工具来配置Redis集群:
-
验证集群配置:
- 使用redis-cli工具连接到Redis集群,并运行
CLUSTER INFO命令来验证集群的状态。确保所有节点都得到正确识别,并且没有任何错误提示。
- 使用redis-cli工具连接到Redis集群,并运行
实际案例介绍
先测试网络连通性
在服务器A上执行下面语句测试连通性
/data/redis-x.x.x/src/redis-cli -h 10.0.0.1 -p 6379
/data/redis-x.x.x/src/redis-cli -h 10.0.0.2 -p 6383
/data/redis-x.x.x/src/redis-cli -h 10.0.0.2 -p 6384
在服务器B上执行下面语句测试连通性
redis-cli -h 10.0.0.1 -p 6379
redis-cli -h 10.0.0.1 -p 6380
redis-cli -h 10.0.0.2 -p 6384
如果上面的测试没有问题,则可进行下步操作
创建集群指令
##在其中一台服务器执行下面命令即可
/data/redis-x.X.X/src/redis-trib.rb create --replicas 1 10.0.0.1:6379 10.0.0.1:6380 10.0.0.1:6381
10.0.0.2:6382 10.0.0.2:6383 10.0.0.2:6384
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
10.0.0.1:6379
10.0.0.2:6382
10.0.0.1:6380
Adding replica 10.0.0.2:6383 to 10.0.0.1:6379
Adding replica 10.0.0.1:6381 to 10.0.0.2:6382
Adding replica 10.0.0.2:6384 to 10.0.0.1:6380
M: d0b49faff3332cdf7389948593d4fb59caca1613 10.0.0.1:6379
slots:0-5460 (5461 slots) master
M: 8c8a578c750b820ce074026e59d4df059eeefd9b 10.0.0.1:6380
slots:10923-16383 (5461 slots) master
S: 731a69f9df773823be182e27e5001b95766b5528 10.0.0.1:6381
replicates b73a3a4528920064cba668aa9452f32387292ab6
M: b73a3a4528920064cba668aa9452f32387292ab6 10.0.0.2:6382
slots:5461-10922 (5462 slots) master
S: 139c02ceb5a2afe9eb0e350ed3170bceb3aa4c4b 10.0.0.2:6383
replicates d0b49faff3332cdf7389948593d4fb59caca1613
S: af498152476cd4732c47292aff44a57bcd57bb63 10.0.0.2:6384
replicates 8c8a578c750b820ce074026e59d4df059eeefd9b
Can I set the above configuration? (type 'yes' to accept): yes #输入yes即可
问题分析
原因rvm版本过低
如果执行gem install redis报下面错误
gem install redis
ERROR: Error installing redis:
redis requires Ruby version >= 2.2.2.
解决方案
gpg2 --keyserver hkp://keys.gnupg.net --recv-keys D39DC0E3
curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
rvm install 2.3.3
rvm use 2.3.3
rvm use 2.3.3 --default
rvm remove 2.0.0
查看现在版本为2.3.3则对
ruby –version
gem install redis
资源文件未重置和清理
[OK]All nodes agree about slots configuration.
>>Check for open slots...
>>>Check slots coverage,··
[OK]All 16384 slots covered.
Connecting to node xx.xx.xx.xx:xxx:OK
[ERR]Node xx.xx.xx.xx:xxx is not empty.Either the node already knows other nodes
check with CLUSTER NODES)or contains some key in database 0.
解决方案
-
删掉conf文件下的aof和rdb结尾的文件。
-
同时将新Node的集群配置文件删除,即:删除你redis.conf里面cluster-config-file所在的文件;
-
对新添加节点的数据库进行清除
redis-cli -h 10.0.0.1 -p 6379
登录后执行flushdb
redis-cli -h 10.0.0.1 -p 6381
登录后执行flushdb
redis-cli -h 10.0.0.1 -p 6382
登录后执行flushdb
Redis集群操作的演示效果
[rootemysql-dbo1 conf]#redis-cli -h 10.0.0.1 -c -p 6379
10.0.0.1:6379>set xxx taknk1
OK
10.0.0.1:6379>get xxx
"taknk1"
10.0.0.1:6379>exit
[rootemysql-db01 conf]#redis-cli -h 10.0.0.2 -c -p 6382
10.0.0.2:6382>get xxx
-Redirected to slot [4407]located at 10.0.0.1:6379
"taknkl'