Hive数据仓库
数据仓库概念与起源发展由来
数仓概念
- 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
- 数据仓库的目的是构建面相分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
数仓专注分析
- 数据仓库本身并不“产生”任何数据,其数据来源不同外部系统;
- 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用;
- 这也是为什么叫“仓库”,而不叫“工厂”的原因。
数据仓库面世
- 当分析所涉及数据规模较小时,在业务低峰期可以在OLTP系统上开展直接分析。
- 但为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平台。该平台的目的很简单:面相分析,支持分析,并且和OLTP系统解耦合。
- 基于这种需求,数据仓库的出行开始在企业中出现。
数据仓库的构建
- 如数仓定义所说,数仓是一个用于存储、分析、报告的数据系统,目的时构建面向分析、支持分析的系统称之为OLAP(联机分析处理)系统。当然,数据仓库OLAP系统的一种实现。
数据仓库主要特征——面向主体、集成、非易失、时变
数仓主要特征
- 面向主题(Subject-Oriented):主题是一个抽象的概念,是较高层次上数据综合、归类并进行分析利用的抽象
- 集成性(Integrated):主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。需要集成到数仓主题下。
- 非易失性(Non-Volatile):也叫非易变性。数据仓库是分析数据的平台,而不是创造数据的平台。
- 时变性(Time-Variant):数据仓库的数据需要随着时间更新,以适应决策的需要。
面向主题性(Subject-Oriented)
- 主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。
- 传统OLTP系统对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。
集成性(Integrated)
- 主题相关的数据通常会分布在多个操作系统中,彼此分散、独立、异构。
- 因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步,所要完成的工作有:
- 要统一源数据中所有矛盾之处
如字段的同名异义、异名同义、单位不统一、字长不一致等等。 - 进行数据综合计算
数据仓库中的数据综合工作可以在从原有的数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
非易失性、非易变性(Non-Volatile)
- 数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变。
- 数据仓库的数据反映的是一段相当长的时间内历史数据的内容,数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。
- 数据仓库中一般由大量的查询操作,但修改和删除操作很少。
时变性(Time-Variant)
- 数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。
- 当业务变化后十渠时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。
- 从这个角度讲,数据仓库建设是一个项目,更是一个过程。
数仓主流开发语言——SQL介绍
数仓开发语言概述
- 数仓作为面相分析的数据平台,其主职工作就是对存储在其中的数据开展分析,那么如何读取数据分析呢?
- 理论上来说,任何一款编程语言只要具备读写数据、处理数据的能力,都可以用于数仓的开发。比如大家耳熟能详的C、java、Python等;
- 关键在于编程语言是否易学、好用、功能是否强大。遗憾的是上面所列出的C、python等编程语言都需要一定的时间进行语法的学习,并且学习语法之后还需要结合分析的业务场景进行编码,跑通业务逻辑。
- 不管从学习成本还是开发效率来说,上述所说的编程语言都不是十分友好的。
- 在数据分析领域,不得不提的就是SQL编程语言,应该称之为分析领域主流开发语言。
SQL语言介绍
- 结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存储数据以及查询、更新和管理数据。
- SQL语言是我们有能力访问数据库,并且SQL是一种ANSI(美国国家标准化组织)的标准计算机语言,各大数据库厂商在生产数据库软件的时候,几乎都会去支持SQL的语法,以使得用户在使用软件时更加容易上手,以及在不通厂商软件之间进行切换更加适应,因为大家的SQL语法都差不多
- SQL语言功能很强,十分简洁,核心功能只用了9个动词。语法接近英语口语,索引,用户很容易学习和使用。
数仓与SQL
- 虽然SQL语言本身是针对数据库软件设计的,但是在数据仓库领域,尤其是大数据仓库领域,很多数仓软件都会去支持SQL语法
- 原因在于一是用户学习SQL成本低,二是SQL语言对于数据分析真的十分友好,爱不释手。
结构化数据
- 结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格的遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
- 与结构化数据相对的是不适用于数据库二维表来表现的非结构化数据,包括所有格式的办公文档、XML、HTML、各类报表、图片和音频、视频信息等。
- 通俗来说,结构化数据会有严格的行列对其,便于解读与理解。
SQL语法分类
SQL主要语法分为两个部分:数据定义语言(DDL)和数据操作语言(DML)。
- DDL语法使我们有能力创建或删除表,以及数据库、索引等各种对象,但是不涉及表中具体数据操作。
- DML语法使我们有能力针对表中的数据进行插入、更新、删除、查询操作。
Apache Hive软件介绍与Hadoop关系
什么是Hive
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表体统了一种类似SQL的查询喵星,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转化为MapReduce程序,然后将程序提交到Hadoop群集执行。
- Hive由Facebook实现并开源
为什么使用Hive
- 使用Hadoop MapReduce直接处理数据所面临的问题
人员学习成本太高 需要掌握java语言
MapReduce实现复杂查询逻辑开发难度太大 - 使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力(简单、易上手)
避免直接写MapReduce,减少开发人员的学习成本
支持自定义函数,功能扩展很方便
背靠Hadoop,擅长存储分析海量数据集
Hive和Hadoop关系
- 从功能来说没时间仓库软件,至少需要具备下述两种能力:
存储数据的能力、分析数据的能力 - Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。 - 这样突然发现Hive没什么用,不过是套壳Hadoop罢了。其实不然,Hive的最大魅力在于用户专注于编写HQL,Hive帮你转换成为MapReduce程序完成对数据的分析。
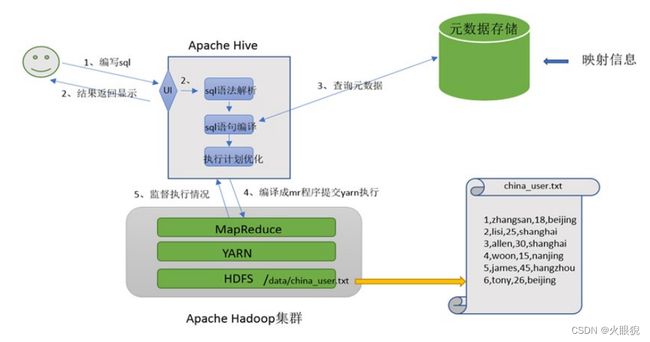
场景设计——Hive功能模拟实现底层猜想
如何模拟实现Apache Hive的功能
在HDFS文件系统上有一个文件,路径为/data/china_user.txt;
需求:统计来自于上海年龄大于25岁的用户有多少个?
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,wangwu,15,nanjing
5,james,45,huangzhou
6,tony,26,beijing
场景目的
- 重点理解下面两点:
Hive能将数据文件映射成一张表,这个映射是指什么?
Hive软件本身到底承担了什么功能职责?
映射信息记录
- 映射在数学上称之为一种对应关系,比如y==x+1,对于每一个x的值都有与之对应的y值。
- 在hive中能够写sql处理的前提是针对表,而不是文件,因此需要交文件和表之间的对应关系描述记录清楚。映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据metadata)。
- 具体来看,要记录的元数据信息包括:
表对应着哪个文件(位置信息)
表的列对应着文件哪一个字段(顺序信息)
文件字段之间的分隔符是什么
SQL语法解析、编译
- 用户写完SQL之后,Hive需要针对上sql进行语法校验,并且根据记录的元数据信息解读SQL背后的含义,指定执行计划。
- 并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户。
对Hive的理解
- Hive能将数据文件映射成一张表,这个映射是指什么?
文件和表之间的对应关系 - Hive软件本身到底承担了什么功能职责?
SQL语法机械编译成为MapReduce
最终效果
- 基于上述分析,最终想要模拟实现的Hive的功能大致需要下图组件参与其中。
- 从中可以感受一下Hive承担了什么职责,当然,也可以把这个理解为Hive的架构图
Apache hive——各组件功能
Hive组件
- 用户接口
包括CLI、JDBC/ODBC、WebGUI。其中,CLI(commmand line interface)为shell命令;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。 - 元数据存储
通常是存储在关系数据库如mysql/derby中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 - Driver驱动程序,包括语法解析器、优化器、计划编译器、执行器
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有执行引擎调用执行。 - 执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
Apache hive安装部署——metadata与metastore、远程模式介绍
什么是元数据
- 元数据(metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata
- Hive Metadata即Hive的元数据。
- 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
- 元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore
- Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接Metastore服务,有Metastore再去连接MySQL数据库来存取元数据。
- 有了Metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接Metastore服务即可。某种程度上也保证了hive元数据的安全。
Metastore配置方式
- Metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
- 区分3中配置方式的关键是弄清楚两个问题:
Metastore服务是否需要单独配置、单独启动?
Metastore是存储在内置的Derby中,还是第三方RDBMS,比如MySQL。 - 本系列课程中使用企业推荐模式——远程模式部署。
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| Metastore单独配置、启动 | 否 | 否 | 是 |
| metadata存储介质 | Derby | MySQL | MySQL |
Metastore远程模式
- 在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
Apache hive安装部署–与Hadoop整合、MySQL安装
安装前准备
- 由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
- 服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装 - Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群。特别要注意,需要等待HDFS安全模式关闭之后再启动运行Hive。
Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
Hadoop与Hive整合
- 因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;
- 因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行。
- 修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效。
<!-整合hive ->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
step1:MySQL安装
### Hive3安装
-----
#### Mysql安装
- 卸载Centos7自带的mariadb
```shell
[root@node3 ~]# rpm -qa|grep mariadb
mariadb-libs-5.5.64-1.el7.x86_64
[root@node3 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
[root@node3 ~]# rpm -qa|grep mariadb
[root@node3 ~]#
-
安装mysql
mkdir /export/software/mysql #上传mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压 tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar #执行安装 yum -y install libaio [root@node3 mysql]# rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm warning: mysql-community-common-5.7.29-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.29-1.e################################# [ 25%] 2:mysql-community-libs-5.7.29-1.el7################################# [ 50%] 3:mysql-community-client-5.7.29-1.e################################# [ 75%] 4:mysql-community-server-5.7.29-1.e################ ( 49%) -
mysql初始化设置
#初始化 mysqld --initialize #更改所属组 chown mysql:mysql /var/lib/mysql -R #启动mysql systemctl start mysqld.service #查看生成的临时root密码 cat /var/log/mysqld.log [Note] A temporary password is generated for root@localhost: o+TU+KDOm004 -
修改root密码 授权远程访问 设置开机自启动
[root@node2 ~]# mysql -u root -p Enter password: #这里输入在日志中生成的临时密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.29 Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #更新root密码 设置为hadoop mysql> alter user user() identified by "hadoop"; Query OK, 0 rows affected (0.00 sec) #授权 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; #mysql的启动和关闭 状态查看 (这几个命令必须记住) systemctl stop mysqld systemctl status mysqld systemctl start mysqld #建议设置为开机自启动服务 [root@node2 ~]# systemctl enable mysqld Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service. #查看是否已经设置自启动成功 [root@node2 ~]# systemctl list-unit-files | grep mysqld mysqld.service enabled -
Centos7 干净卸载mysql 5.7
#关闭mysql服务 systemctl stop mysqld.service #查找安装mysql的rpm包 [root@node3 ~]# rpm -qa | grep -i mysql mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #卸载 [root@node3 ~]# yum remove mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #查看是否卸载干净 rpm -qa | grep -i mysql #查找mysql相关目录 删除 [root@node1 ~]# find / -name mysql /var/lib/mysql /var/lib/mysql/mysql /usr/share/mysql [root@node1 ~]# rm -rf /var/lib/mysql [root@node1 ~]# rm -rf /var/lib/mysql/mysql [root@node1 ~]# rm -rf /usr/share/mysql #删除默认配置 日志 rm -rf /etc/my.cnf rm -rf /var/log/mysqld.log
Apache hive安装部署–配置文件修改编辑
step2:上传解压Hive安装包(node1安装即可)
-
上传安装包 解压
tar zxvf apache-hive-3.1.2-bin.tar.gz -
解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/ -
修改配置文件
-
hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib -
hive-site.xml
vim hive-site.xml<configuration> <property> <name>javax.jdo.option.ConnectionURLname> <value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8value> property> <property> <name>javax.jdo.option.ConnectionDriverNamename> <value>com.mysql.jdbc.Drivervalue> property> <property> <name>javax.jdo.option.ConnectionUserNamename> <value>rootvalue> property> <property> <name>javax.jdo.option.ConnectionPasswordname> <value>hadoopvalue> property> <property> <name>hive.server2.thrift.bind.hostname> <value>node1value> property> <property> <name>hive.metastore.urisname> <value>thrift://node1:9083value> property> <property> <name>hive.metastore.event.db.notification.api.authname> <value>falsevalue> property> configuration>
-
-
上传mysql jdbc驱动到hive安装包lib下
mysql-connector-java-5.1.32.jar -
初始化元数据
cd /export/server/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表 -
在hdfs创建hive存储目录(如存在则不用操作)
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse
Apache hive安装部署 – metastore服务启动方式
Metastore服务启动方式
- 前台启动,进程会一直占据终端,ctrl+c结束进程,服务关闭。可以根据需求添加参数开启debug日志,获取详细日志信息,便于排错。
- 后台启动,输出日志信息在/root目录下nohup.out
-
启动hive
-
1、启动metastore服务
#前台启动 关闭ctrl+c /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore #前台启动开启debug日志
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
#后台启动 进程挂起 关闭使用jps+ kill -9
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore & -
Apache hive --新老客户端使用与hiveserver2服务
- hive自带客户端
- bin/hive、bin/beeline
HiveServer2服务介绍
- 远程模式下beeline通过Thrift连接到单独的HiveServer2服务上,这也是官方推荐在生产环境中使用的模式。
- HiveServer2支持多客户端的兵法和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。
关系梳理
- HiveServer2通过Metastore服务读写元数据。所以在远程模式下,启动HiveServer2之前必须首先启动Metastore服务。
- 特别注意:远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而bin/hive是通过Metastore服务访问的。
bin/beeline客户端使用
-
在hive安装的服务器上,首先启动Metastore服务,然后
-
2、启动hiveserver2服务
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #注意 启动hiveserver2需要一定的时间 不要启动之后立即beeline连接 可能连接不上 -
3、beeline客户端连接
-
拷贝node1安装包到beeline客户端机器上(node3)
scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/ -
错误
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node1:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate root (state=08S01,code=0)-
修改
在hadoop的配置文件core-site.xml中添加如下属性: <property> <name>hadoop.proxyuser.root.hostsname> <value>*value> property>
-
连接访问
/export/server/apache-hive-3.1.2-bin/bin/beeline beeline> ! connect jdbc:hive2://node1:10000 beeline> root beeline> 直接回车
-
-
-
错误解决:Hive3执行insert插入操作 statstask异常
-
现象
在执行insert + values操作的时候 虽然最终执行成功,结果正确。但是在执行日志中会出现如下的错误信息。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cXkBc0UE-1661569579125)(Hive3安装.assets/image-20201109144915808.png)]
-
开启hiveserver2执行日志。查看详细信息
2020-11-09 00:37:48,963 WARN [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. setPartitionColumnStatistics ERROR [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] exec.StatsTask: Failed to run stats task
-