大数据课程C4——ZooKeeper结构&&运行机制
文章作者邮箱:[email protected] 地址:广东惠州
▲ 本章节目的
⚪ 了解Zookeeper的特点和节点信息;
⚪ 掌握Zookeeper的完全分布式安装
⚪ 掌握Zookeeper的选举机制、ZAB协议、AVRO;
一、Zookeeper-简介
1. 特点
1. Zookeeper底层是一个树状结构,根节点是/。
2. Zookeeper中每一个节点称之为Znode节点,因此这棵树称之为Znode树。
3. Zookeeper自带了一个子节点/zookeeper。
4. Zookeeper在创建节点的时候可以携带数据也可以不携带(早版本的zookeeper中,创建节点必须携带数据),数 据可以是对节点的描述,或者可以是一些配置信息。
5. 在Zookeeper中不存在相对路径,所有的路径都必须从根节点开始计算。
6. Zookeeper会将携带的数据存储在内存以及磁盘中。
7. Zookeeper中数据的存储位置由dataDir属性决定,如果不指定默认在/tmp。
8. 在Zookeeper中会将每一个写操作(创建,修改,删除)看成一个事务,并且会给这个事务分配一个全局递增的事 务id,这个编号就是Zxid。
9. 其他命令:
9.1. create -e /video --创建临时节点video。
9.2. create -s /txt --表示创建的是持久顺序节点。
9.3. create -e -s /txt --表示创建一个临时顺序节点。
10. 临时节点不能挂载子节点-持久节点可以挂载子节点。
11. 在zookeeper中不能存在同名节点。
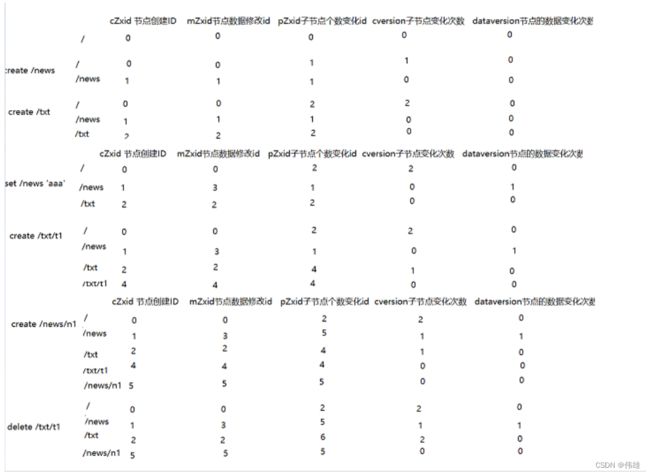
2. 节点信息
cZxid = 节点的创建的事务id。
ctime = 节点的创建时间。
mZxid = 节点的数据修改的事务id。
mtime = 节点的数据修改的时间。
pZxid = 子节点个数变化的事务id。
cversion = 子节点变化的次数。
dataVersion = 节点的数据变化次数。
aclVersion = 节点的权限策略变化的次数。
ephemeralOwner = 如果是持久节点,则此值为0,如果是临时节点,则此值为sessionid。
dataLength = 数据的子节个数。
numChildren = 子节点的个数。
3. 节点类型
| 持久节点 | 临时节点 | |
| 非顺序节点 | Persistent | Ephemeral |
| 顺序节点 | Persistent_Sequential | Ephemeral_Sequential |
4. 完全分布式安装
关闭防火墙
临时关闭:systemctl stop firewalld
永久关闭:systemctl disable firewalld
安装JDK
上传或者下载Zookeeper安装包,上课阶段统一要求将所有软件安装在/home/software目录下 解压Zookeeper安装包
tar -xvf apache-zookeeper-3.5.7-bin.tar.gz
进入Zookeeper安装目录的子目录conf下
cd apache-zookeeper-3.5.7-bin/conf
复制文件
cp zoo_sample.cfg zoo.cfg
编辑文件
vim zoo.cfg
修改属性dataDir,这个属性是用于指定Zookeeper快照文件的存储位置,如果不指定,则默认放在/tmp目录下, 例如:
dataDir=/home/software/apache-zookeeper-3.5.7-bin/tmp
在文件末尾添加server.x=IP/hostname:port1:port2,其中x表示选举编号,要求不重复,port1为原子广播端 口,port2为选举端口,例如:
server.1=10.9.152.110:2888:3888
server.2=10.9.152.111:2888:3888
server.3=10.9.152.112:2888:3888
新建dataDir指定的目录
cd /home/software/apache-zookeeper-3.5.7-bin/
mkdir tmp
进入该目录,在该目录下编辑文件myid,在这个文件中填写当前主机给定的编号
cd tmp
vim myid
填写编号,例如第一台主机给定的编号为1
将第一台主机的配置远程拷贝给其他另外两台主机,例如:
cd /home/software
scp -r apache-zookeeper-3.5.7-bin/ [email protected]:$PWD
scp -r apache-zookeeper-3.5.7-bin/ [email protected]:$PWD
拷贝完成之后,需要修改另外两台主机的myid
cd /home/software/apache-zookeeper-3.5.7-bin/tmp/
vim myid
修改成对应的编号,例如第二台主机给定编号为2
三台主机进入Zookeeper安装目录的子目录bin下,启动Zookeeper
cd /home/software/apache-zookeeper-3.5.7-bin/bin/
sh zkServer.sh start
查看Zookeeper运行状态
sh zkServer.sh status
5. 配置信息
| 参数 | 说明 |
| clientPort | 客户端连接服务器端的端口,即Zookeeper的对外服务端口,一般默认为2181。 |
| dataDir | 数据目录,即存储快照文件的目录。 |
| dataLogDir | 1. 事务日志输出目录。在不指定的情况下,和dataDir一致。 2. 正常运行过程中,针对所有事务操作,在返回客户端ACK的响应前,Zookeeper会确保已经将本次事务操作的事务日志写到 磁盘上,只有这样,事务才会生效。 |
| tickTime | Zookeeper中的一个时间单元。Zookeeper中所有时间都是以这个时间单元为基础,进行整数倍配置。 |
| initLimit | 1. follower在启动过程中,会从leader同步所有最新数据,然后确定自己能够对外服务的起始状态。leader允许follower在 initLimit 时间内完成这个工作。 2. 如果Zookeeper集群的数据量确实很大了,follower在启动的时候,从leader上同步数据的时间也会相应变长,因此在这种 情况下,有必要适当调大这个参数了。 3. 默认是:10*ticktime。 |
| syncLimit | 1. 表示leader 与 follower 之间发送消息,请求和应答时间长度。 2. 如果follower 在设置的时间内不能与leader 进行通信,那么此 follower 将被丢弃。 3. 默认是:5*ticktime。 4. 当集群网络环境不好时,可以适当调大。 |
| minSessionTimeout maxSessionTimeout | 1. Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。 2. 默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围。 |
| server.x=hostname:端口号 1:端口号2 | 1. 配置集群中的主机。 2. x是主机编号,即myid。 3. 端口号1是原子广播端口,用于leader和follower之间的通信。 4. 端口号2是选举端口,用于选举过程中的通信。 |
| jute.maxbuffer | 用于控制每一个节点的最大存储的数据量。 默认是1M。 |
| globalOutstandingLimit | 1. 最大请求堆积数。默认是1000。 2. Zookeeper运行的时候, 尽管server已经没有空闲来处理更多的客户端请求了,但是还是允许客户端将请求提交到服务器上 来,以提高吞吐性能。而为了防止server内存溢出,用该属性限制请求堆积数。 |
| preAllocSize | 1. 预先开辟磁盘空间,用于后续写入事务日志。 2. 默认是64M,即每个事务日志大小就是64M。 |
| leaderServers | 默认情况下,leader是会接受客户端连接,并提供正常的读写服务。但是,如果需要leader专注于集群中机器的事务协调(原 子广播),那么可以将这个参数设置为no,这样一来,会提高整个zk集群性能。 |
| maxClientCnxns | 控制的每一台zk服务器能处理的客户端并发请求数。默认是60。 |
二、选举机制
1. 概述
1. 当一个zookeeper集群刚启动的时候,会自动的进入选举状态, 此时所有的服务器(节点)都会推荐自己成为leader,并 且还会把自己的选举信息发送给其他的节点。
2. 当节点收到其他节点发过来的选举信息之后,会两两比较。 经过多轮比较,最后胜出的节点当leader。
2. 细节
1. 选举信息包含:
a. 当前节点的最大事务id。
b. 选举编号,即myid。
c. 逻辑时钟值-控制选举的轮数。
2. 比较原则
a. 先比较最大事务id,谁大谁赢。
b. 如果事务id一样,则比较myid,谁大谁赢。
c. 如果一个节点胜过了一半及以上的节点,这个节点才能成为leader-过半性。
3. 在zookeeper中,不存在单点故障的说法,如果leader宕机了,那么整个集群会选举一个新的leader继续对外提供服务。
4. 如果leader节点宕机之后重新启动,那么这个时候看做一个新的节点加入集群,所以此时这个节点的状态一定是follower。
5. 如果一个集群已经选举出来一个leader,为了维护集群的稳定性,无论新添加的节点的事务id或者myid是多少,都不会触 发重新选举,新添的节点只能是follower。
6. 如果集群中出现了多个leader,这种现象叫做脑裂。
7. zookeeper中脑裂出现的条件
a. 集群产生分裂。
b. 分裂之后产生了选举。
8. 在zookeeper中,如果存活的(可以相互通信的)节点数量不足一半,则这些节点不选举,同时也不对外提供服务-过半性。
9. zookeeper会对每一次选举出来的leader分配一个全局递增的编号,称之为epochid,当zookeeper发现存在多个leader的 时候,那么会自动的将epochid较小的节点的状态切换成follower。利用这种方案可以保证整个集群中只存在唯一的 leader。
10. 集群中节点的状态
a. looking/voting:选举状态
b. follower:追随者/跟随者
c. leader:领导者
d. observer:观察者
11. zookeeper并不是主从的框架,其中leader和follower指的是节点的状态而不是角色。
三、ZAB协议
1. 概述
1. ZAB(Zookeeper Atomic Broadcast)协议是专门为zookeeper设计的用于进行原子广播和崩溃恢复的一套协议。
2. ZAB是基于2PC算法设计实现的,利用了过半性+PAXOS进行了改进。
2. 原子广播
1. 作用:保证集群节点之间的数据一致性,即访问任意一个节点,获取到的数据都是相同的。
2. 原子广播就是基于2PC算法设计实现的。
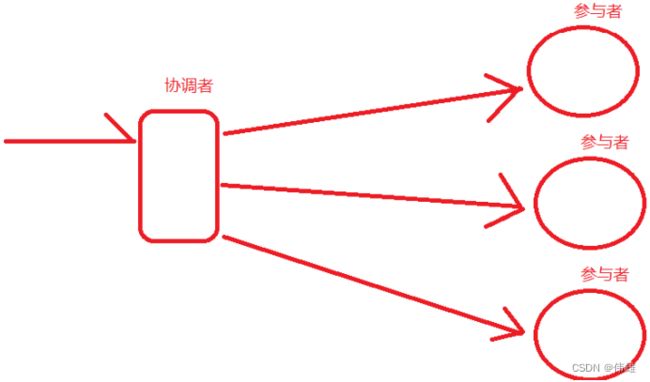
3. 2PC- two Phase Commit-二阶段提交。顾名思义,将一个请求拆分成了两个阶段。
a. 请求阶段。
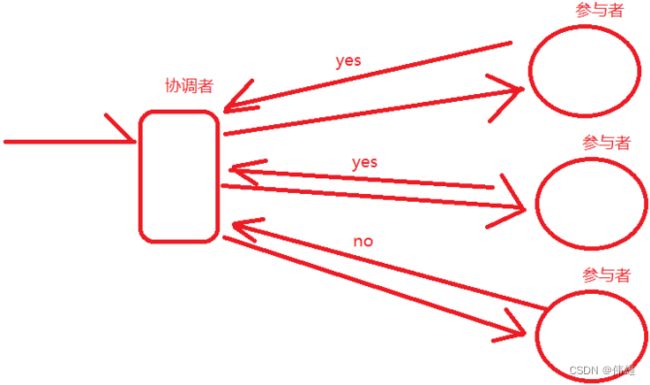
b. 提交阶段:如果协调者收到所有的参与者返回的yes,那么就认为这个请求可以执行,那么就会命令所有的参 与者执行这个请求。

c. 中止阶段:只要协调者没有收到所有参与者返回的yes,那么就认为这个请求无法执行,也就会要求所有的参 与者放弃刚才的请求。
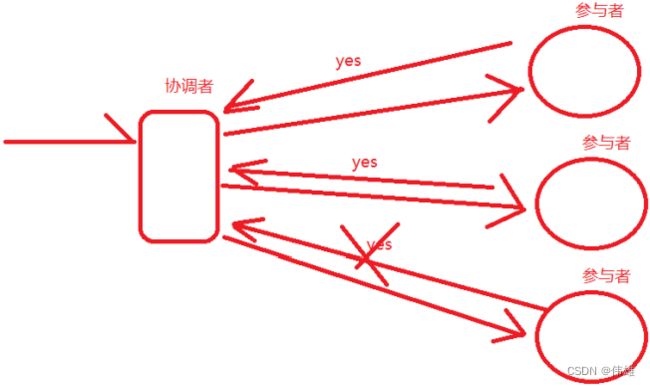
4. 在2PC算法中,要么是执行请求-提交阶段要么是执行请求-中止阶段。
5. 2PC的核心思想就是“一票否决”。
6. 2PC算法很容易理解,并且也很容易实现,但是在分布式环境中,2PC是的成功率很低。效率很低。也因此 zookeeper的原子广播在2pc的算法基础上加上了过半性。
7. 原子广播的过程

8. 查看日志的方式
a. 将zookeeper安装目录下lib目录中的zookeeper-3.5.7.jar和slf4J.api-1.7.25.jar和zookeeperjute-3.5.7.jar拷贝到log日志所在目录下。
b. 通过命令来查看:
i. java -cp .:zookeeper-3.5.7.jar:slf4j-api-1.7.25.jar:zookeeper-jute-3.5.7.jar org.apache.zookeeper.server.LogFormatter log.600000001
c. snapshot.xxx文件是一个快照文件,用于记录zookeeper的树结构,查看方式:
i. java -cp .:zookeeper-3.5.7.jar:slf4j-api-1.7.25.jar:zookeeper-jute-3.5.7.jar org.apache.zookeeper.server.SnapshotFormatter snapshot.300000000
d. follower存在日志记录失败的可能,例如文件被占用,磁盘损坏,磁盘已满。都可能导致日志文件记录失 败,这些原因不是zookeeper的原因,zookeeper是无法解决的。
e. 如果follower记录失败,那么会给leader发送请求,leader收到请求之后,会将欠缺的事务放到队列中返 回给follower要求follower补齐事务。
3. 崩溃恢复
1. 当leader宕机之后,整个zookeeper集群并不会就此停止,而是选举一个新的leader出来,然后继续对外提供 服务。
2. 作用:避免单点故障。
3. 在zookeeper集群中,会对每一次选举出来的leader分配一个全局递增的唯一编号,这个编号我们把它叫做 epochid,当leader被选举出来之后,这个leader就会将epochid分发给每一个follower,follower收到这个 epochid就会将它存储在acceptedEpoch文件中。
4. 在Zookeeper集群中,事务id(zxid)实际上是由64位二进制(16位16进制)数字组成,分成了两个部分,高32位实际上就是epochid,低32位才是实际的事务id,例如0x600000002表示的就是第6任leader被选举出来 之后产生的第2个写操作。
5. 当一个节点宕机重启之后,这个节点会先找到当前节点的最大事务id,找到之后会向leader所在的节点发送请 求比较事务id是不是一致的。leader收到请求,会比较两个事务id是否一致,如果一致,说明节点在宕机期间 没有发生写操作,如果不一致,那么leader就会将欠缺的事务放到队列中发送给follower要求补齐到和整个集 群一致的水平。follower在补齐事务的过程中不对外提供服务。
四、Zookeeper-其他
1. observer-观察者
1. observer在zookeeper中既不参与选举也不参与投票,但是会监听选举和投票的结果,但是根据结果进行指定的操作。
2. observer可以大概理解为没有选举权和投票权的follower-只有干活的义务没有选举的权利。
3. 在实际开发过程中,当集群规模庞大(节点个数比较多)或者网络环境一般的时候,会将一个集群中90%-97%的节点设置为 observer,例如100个节点组成的服务器,我们可以将91个节点设置为observer。

4. 由于observer不参与投票也不参与选举,所以observer存活与否并不会影响整个集群是否对外提供服务。假设现在有个21个节 点的集群。其中1leader,6follower,14observer。如果其中4个follower宕机了。即便observer存活也不会对外提供服务。但 是如果leader和follower全部存活即便14个observer全部宕机,也能对外提供服务。在zookeeper集群中,过半性是以能够参 加选举或者投票的节点的个数来决定的。
5. observer的配置
a. 进入conf
b. 找到zoo.cfg
c. 添加:
peerType=observer
server.1=10.42.105.87:2888:3888
server.2=10.42.64.11:2888:3888:observer
server.3=10.42.63.78:2888:3888
2. 特征
1. 过半性:过半选举,过半存活,过半操作。
2. 数据一致性,从任意节点获取数据,拿到的数据都是一样的
3. 原子性:一个操作要么所有节点都执行,要么都不执行
4. 顺序性:所有节点获取到的请求顺序是一致的-队列
5. 可靠性:主要指的就是崩溃恢复
6. 实时性:在网络条件比较好的时候,可以对zookeeper来实现实时监控
3. zookeeper集群操作
1. 实际上利用nc来实现,nc全程就是netcat,底层是通过发送TCP的请求来发送命令。
2. 安装nc:
a. 进入software。
b. 下载nc包 wget http://bj-yzjd.ufile.cn-north-02.ucloud.cn/nc-1.84-22.el6.x86_64.rpm。
c. 安装nc:rpm -ivh nc.rpm。
3. 集群指令:
a. 查看节点是否存活:echo ruok|nc 10.42.64.11 2181。
i. 如果提示ruok is not executed because it is not in the whitelist。
ii. 需要在配置文件当中添加 4lw.commands.whitelist=*。
b. 查看节点状态:echo stat|nc 10.42.64.11 2181。
c. 查看节点的配置信息 echo conf|nc 10.42.64.11 2181。
五、AVRO
1. 概述
1. AVRO是apache提供的用于进行序列化和RPC的一套框架。
2. AVRO原来是hadoop的子工程,后来被独立成为一个顶级工程。
2. 序列化
1. 本上是序列化就是对数据的转化:按照指定规则将对象转化成指定的格式的数据。
2. 目的/意义:存储和传输。
3. 序列化的衡量标准:
a. 对内存和CPU的耗费以及转化时间。
b. 序列化之后产生数据量的大小。
c. 序列化机制能否跨平台。:在现在的开发过程中,一个项目往往不是单一语言完成的,而是多语言复合的结果,所以 我们就需要考虑数据在不同语言之间的传输。
i. 数据想要在不同语言之间进行传输,那么就需要做到与语言无关:数字,布尔值,字符串。
ii. 好的序列化机制就需要做到跨语言。即这个序列化机制需要做到将对象转化成与语言无关的数据格式。
d. AVRO将对象转化成字符串来进行传输,本质上就是转化成了json。
3. RPC
1. RPC(Remote Procedure Call-远程过程调用)是指允许程序员在一个节点调用另一个节点上的方法而不用显示的实现 这个方法。
2. RPC最早是Nelson在1981年提出来的。
3. RPC也是分布式底层的重要组成之一。
4. 特点:简洁,高效,易懂。
5. RPC中通过存根(Stub)来统一结构。
6. RPC协议是传输层协议,通常用于服务器于服务器之间的通信。速度要快于htpp协议。