Python自动化办公:读取pdf文档

在后台回复【阅读书籍】
即可获取python相关电子书~
Hi,我是山月。
上次给大家介绍了pypdf2的使用方法,但它主要用于文档的处理,比如合并、提取页面等。
但是对于pdf文档来说,如何读取它的内容也是我们需要面对的一个问题。
这不,今天就给大家带来了pdfplumber。
安装:pip install pdfplumber
官网:https://github.com/jsvine/pdfplumber
01
基础知识
1、加载 PDF
要开始使用 PDF,需要调用 pdfplumber.open(x),其中 x 可以是:
PDF 文件的路径
文件对象,作为字节加载
类文件对象,作为字节加载
open 方法返回 pdfplumber.PDF 类的一个实例。
要加载受密码保护的 PDF,需要传递密码关键字参数,例如 pdfplumber.open("file.pdf", password = "test")。
要将布局分析参数设置为 pdfminer.six 的布局引擎,需要传递 laparams 关键字参数,例如 pdfplumber.open("file.pdf", laparams = { "line_overlap": 0.7 })。
默认情况下,无效的元数据值被视为警告。如果不打算这样做,请将 strict_metadata=True 传递给 open 方法,如果 pdfplumber.open 无法解析元数据,它将引发异常。
2、pdfplumber.PDF
顶级 pdfplumber.PDF 类表示单个 PDF,并具有两个主要属性:

如加载一个有两页内容的数据.pdf:

import pdfplumber
pdf = pdfplumber.open("数据.pdf") #加载 PDF
print(pdf.metadata)
print(pdf.pages)
'''
{'Author': '是山月呀', 'Comments': '', 'Company': '', 'CreationDate': "D:20220317143148+06'31'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220320161111+08'00'", 'Producer': '', 'SourceModified': "D:20220317143148+06'31'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
[, ]
''' 3、pdfplumber.Page
pdfplumber.Page 类是 pdfplumber 的核心,用 pdfplumber 做的大部分事情都围绕这个类展开。
1、主要属性

2、主要方法
1、crop
.crop(bounding_box, relative=False)
'''
返回裁剪到边界框bounding_box的页面版本,bounding_box表示为 (x0, top, x1, bottom) 的 一个4 元组。
裁剪的页面保留了一少部分位于边界框内的对象。如果一个对象仅部分落在框内,则其尺寸将被切片以适合边界框。
如果 relative=True,边界框被计算为从页面边界框左上角的偏移量,而不是绝对定位。
'''2、within_bbox
.within_bbox(bounding_box, relative=False)
'''
类似于 .crop,但只保留完全落在边界框内的对象。
'''3、filter
.filter(test_function)
'''
返回仅包含 test_function(obj) 返回为 True 时的 .objects 页面版本。
'''4、dedupe_chars
.dedupe_chars(tolerance=1)
'''
返回具有重复字符的页面版本 ,即那些与其他字符共享相同的文本、字体名称、大小和位置(在容差内)的,然后删除。
'''5、extract_text
.extract_text(x_tolerance=3, y_tolerance=3, layout=False, x_density=7.25, y_density=13, **kwargs)
'''
将页面的所有字符对象整理成一个字符串。
当 layout=False 时:当一个字符的 x1 和下一个字符的 x0 之间的差异大于 x_tolerance 时添加空格。当一个字符的 doctop 与下一个字符的 doctop 之间的差异大于 y_tolerance时添加换行符。
当 layout=True 时(实验特征):尝试模仿页面上文本的结构布局,使用 x_density 和 y_density 来确定每个“点”的最小字符/换行数,单位为PDF 测量单位。所有剩余的 **kwargs 都被传递给 .extract_words(...) ,这是计算布局的第一步。
'''6、extract_words
.extract_words(x_tolerance=3, y_tolerance=3, keep_blank_chars=False, use_text_flow=False, horizontal_ltr=True, vertical_ttb=True, extra_attrs=[])
'''
返回所有看起来像单词的事物及其边界框的列表。
单词被认为是字符序列,其中(对于直立字符)一个字符的 x1 和下一个字符的 x0 之间的差异小于或等于 x_tolerance 并且其中一个字符的 doctop 和下一个字符的 doctop小于或等于 y_tolerance。
对非直立字符采用类似的方法,但是是测量它们之间的垂直距离而不是水平距离。
参数horizontal_ltr 和vertical_ttb 表示是否应该从左到右(对于水平单词)/从上到下(对于垂直单词)读取单词。
将 keep_blank_chars 更改为 True 将意味着空白字符被视为单词的一部分,而不是单词之间的空格。
将 use_text_flow 更改为 True 将使用 PDF 的基本字符流作为对单词进行排序和分割的指南,而不是按 x/y 位置对字符进行预排序。 (这模仿了拖动光标如何突出显示 PDF 中的文本;与此一样,顺序并不总是合乎逻辑的。)
传递 extra_attrs 列表(例如,["fontname", "size"] 将把每个单词限制为每个属性具有相同值的字符,结果单词dicts将指出这些属性。
'''7、extract_tables
.extract_tables(table_settings)
'''
从页面中提取表格数据。
'''8、to_image
.to_image(**conversion_kwargs)
'''
返回 PageImage 类的实例。
'''9、close
.close()
'''
默认情况下,Page 对象缓存其布局和对象信息,以避免重新处理它。
但是,在解析大型 PDF 时,这些缓存的属性可能需要大量内存。您可以使用此方法刷新缓存并释放内存。 (在版本 <= 0.5.25 中,使用 .flush_cache()。)
'''4、Objects
pdfplumber.PDF 和 pdfplumber.Page 的每个实例都提供对几种类型的 PDF 对象的访问,所有这些对象都源自 pdfminer.six PDF 解析。
以下属性均返回匹配对象的 Python 列表:
.chars,每个代表一个文本字符。
.lines,每个代表一个单一的一维线。
.rects,每个代表一个二维矩形。
.curves,每个代表无法识别为直线或矩形的任何一系列连接点。
.images,每个代表一个图像。
.annots,每个代表一个 PDF 注释
.hyperlinks,每个都代表子类型 Link 的单个 PDF 注释并具有 URI 操作属性
每个对象都表示为一个简单的 Python 字典,具有以下属性:
1、char属性

2、line属性
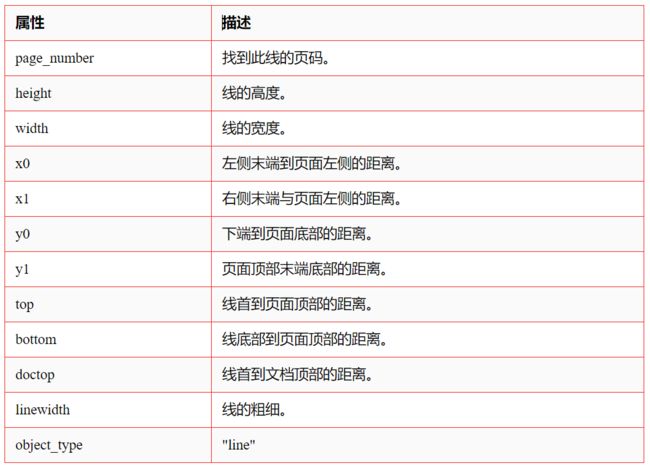
3、rect属性

4、curve 属性
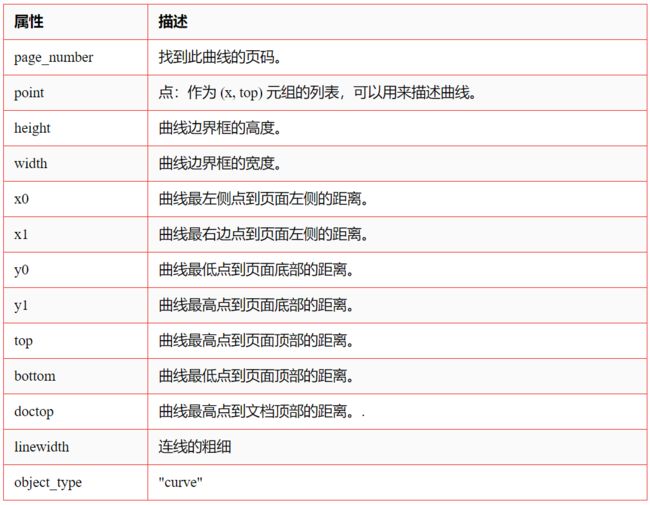
此外,pdfplumber.PDF 和 pdfplumber.Page 都提供对两个派生对象列表的访问:.rect_edges(将每个矩形分解为其四行)和 .edges(将 .rect_edges 与 .lines 组合)。
5、示例
import pdfplumber
pdf = pdfplumber.open("数据.pdf") #加载 PDF
first_page = pdf.pages[0] # 获取第1页
text = first_page.extract_text() #读取页面文字
print(text)
'''
这是第1页的内容。
只有文字:a,b,c。
'''
print(first_page.chars[0]) # 读取第一个字符属性
'''
{'fontname': 'JYVKAE+DengXian', 'adv': 209.0, 'upright': True, 'x0': 90.0, 'y0': 756.4061499999999,
'x1': 100.45, 'y1': 766.85615, 'width': 10.450000000000003, 'height': 10.450000000000045, 'size': 10.450000000000045,
'object_type': 'char', 'page_number': 1, 'stroking_color': (0, 0, 0), 'non_stroking_color': (0, 0, 0),
'text': '这', 'top': 75.04385000000002, 'bottom': 85.49385000000007, 'doctop': 75.04385000000002}
'''02
可视化调试
1、准备工作
要使用 pdfplumber 的可视化调试工具,需要安装两个额外的软件。
1、ImageMagick
安装说明:http://docs.wand-py.org/en/latest/guide/install.html#install-imagemagick-debian
1、安装 Wand:pip install Wand
Wand 是 ImageMagick 的 Python 绑定。
2、安装ImageMagick
1)下载
下载地址:https://imagemagick.org/script/download.php#windows
选择版本下载:
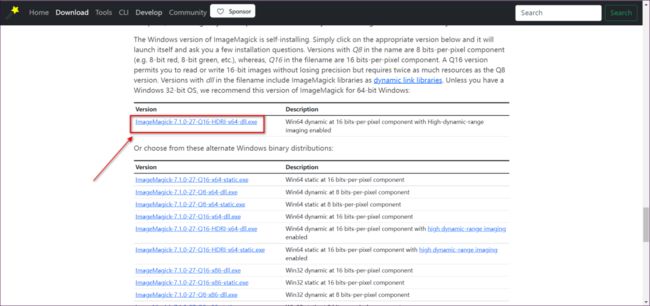
2)安装
双击下载的安装包,进行安装ImageMagick:

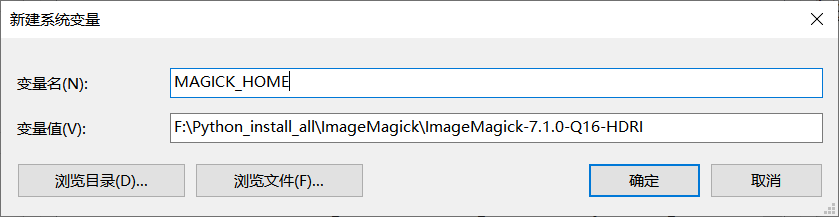
3)添加环境变量
将 MAGICK_HOME 环境变量设置为 ImageMagick 的路径:
2、ghostscript
安装说明:https://www.ghostscript.com/doc/current/Install.htm
1)下载
下载地址:https://www.ghostscript.com/releases/gsdnld.html
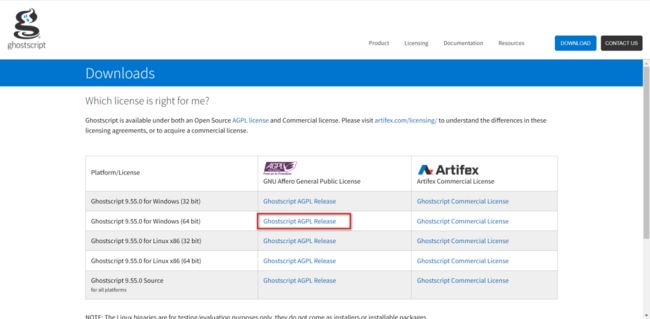
下载后:

2)安装
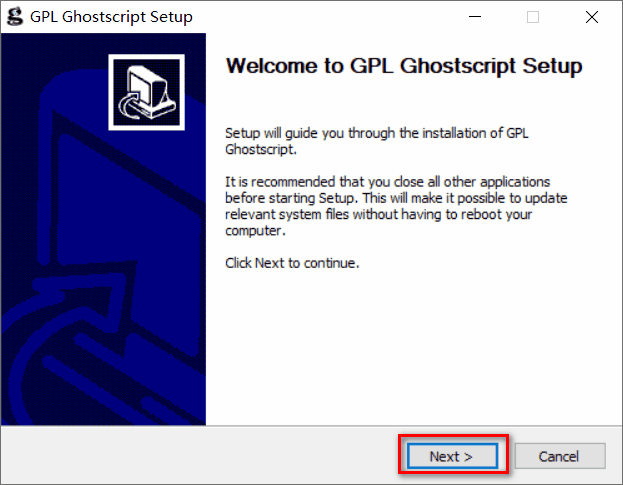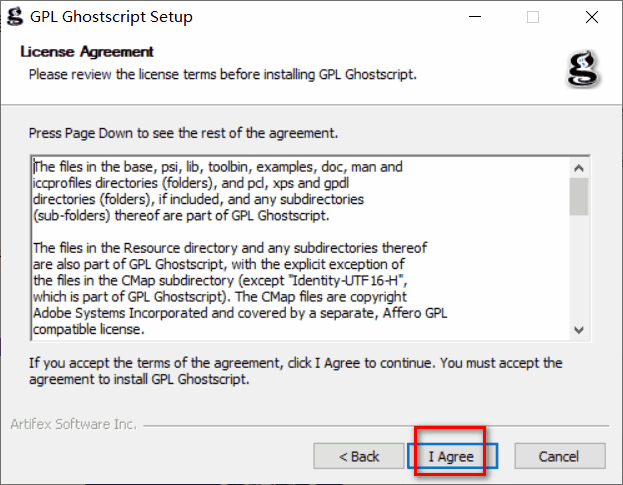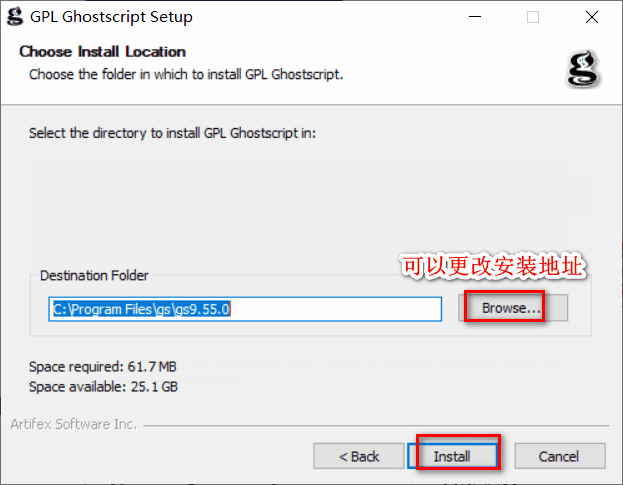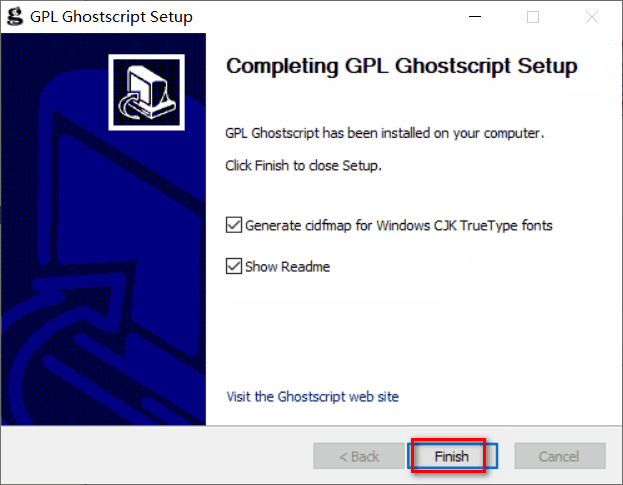
3)添加环境变量
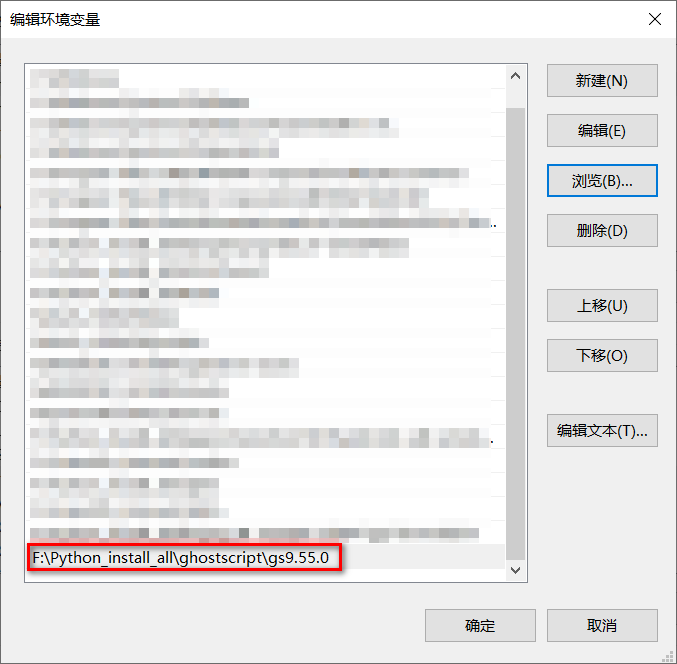
在环境变量的path目录下新增安装目录位置。
2、创建 PageImage
要将任何页面(包括裁剪页面)转换为 PageImage 对象,可以调用 my_page.to_image()。
调用时可以选择传递 resolution={integer} 关键字参数,默认为 72。
例如:
im = my_pdf.pages[0].to_image(resolution=150)3、基本 PageImage 方法
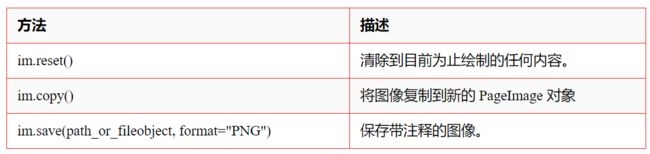
4、绘图方法
可以将坐标或pdfplumber PDF 对象(例如:char、line、rect)传递给这些方法。

注意:上面的方法是基于 Pillow 的 ImageDraw 方法构建的,但是为了与 SVG 的 fill/stroke/stroke_width 命名法保持一致,已经调整了参数。
5、实例
代码:
import pdfplumber
pdf = pdfplumber.open("数据.pdf") #加载 PDF
p2 = pdf.pages[1] # 获取第2页
im = p2.to_image(resolution=150) #把第2页转换成PageImage对象
im.draw_rects(p2.extract_words()) # 根据每个单词绘制矩形框
im.save('实例.PNG') # 保存图片效果:
03
表提取
pdfplumber 的表格检测方法是这样工作的:
对于任何给定的 PDF 页面,找到 (a) 明确定义和/或 (b) 由页面上的单词对齐方式隐含的行。
合并重叠或几乎重叠的线。
找到所有这些线的交点。
找到使用这些交点作为顶点的最细粒度的矩形集(即单元格)。
将连续的单元格分组到表格中。
1、提取表的方法
pdfplumber.Page 对象可以调用以下表格方法:
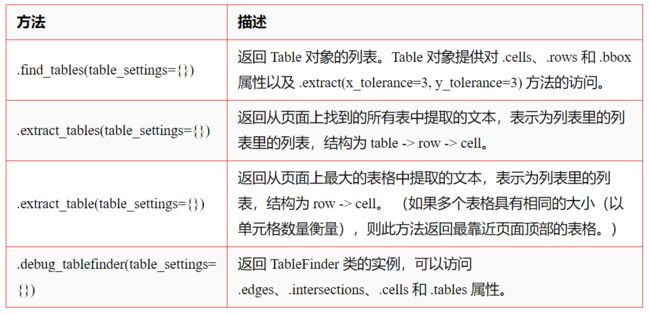
例如:
import pdfplumber
pdf = pdfplumber.open("数据.pdf") #加载 PDF
p2 = pdf.pages[1] # 获取第2页
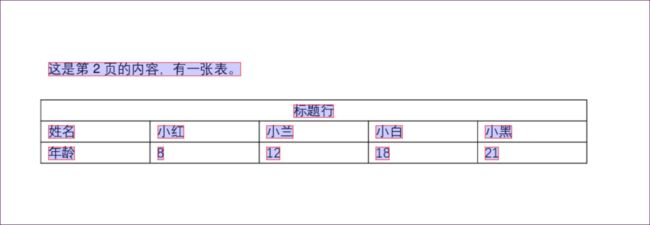
table = p2.extract_table() #.extract_table 返回一个由列表组成的列表,每个内部列表代表表中的一行
print(table) # 打印整个表
print(table[:2]) # 打印表前2行
'''
[['标题行', None, None, None, None], ['姓名', '小红', '小兰', '小白', '小黑'], ['年龄', '8', '12', '18', '21']]
[['标题行', None, None, None, None], ['姓名', '小红', '小兰', '小白', '小黑']]
'''对于结果,我们可以使用 pandas 将列表呈现为 DataFrame,然后进行处理。这里暂且不进行进一步的讨论。
如果你好奇它是如何工作的,可以使用 pdfplumber 的可视化调试来展示表格是如何被提取的。
红线代表在页面上找到的 pdfplumber 行;蓝色圆圈表示这些线的交叉点,浅蓝色阴影表示来自这些交叉点的单元格:
import pdfplumber
pdf = pdfplumber.open("数据.pdf") #加载 PDF
p2 = pdf.pages[1] # 获取第2页
im = p2.to_image(resolution=150) #把第2页转换成PageImage对象
im.debug_tablefinder() #展示表格是如何被提取的
im.save('实例.PNG') # 保存图片效果:

2、提取表的设置
默认情况下,extract_tables 使用页面的垂直线和水平线(或矩形边缘)作为单元格分隔符。
但是该方法也可以通过 table_settings 参数进行高度定制。
可能的设置及其默认值:
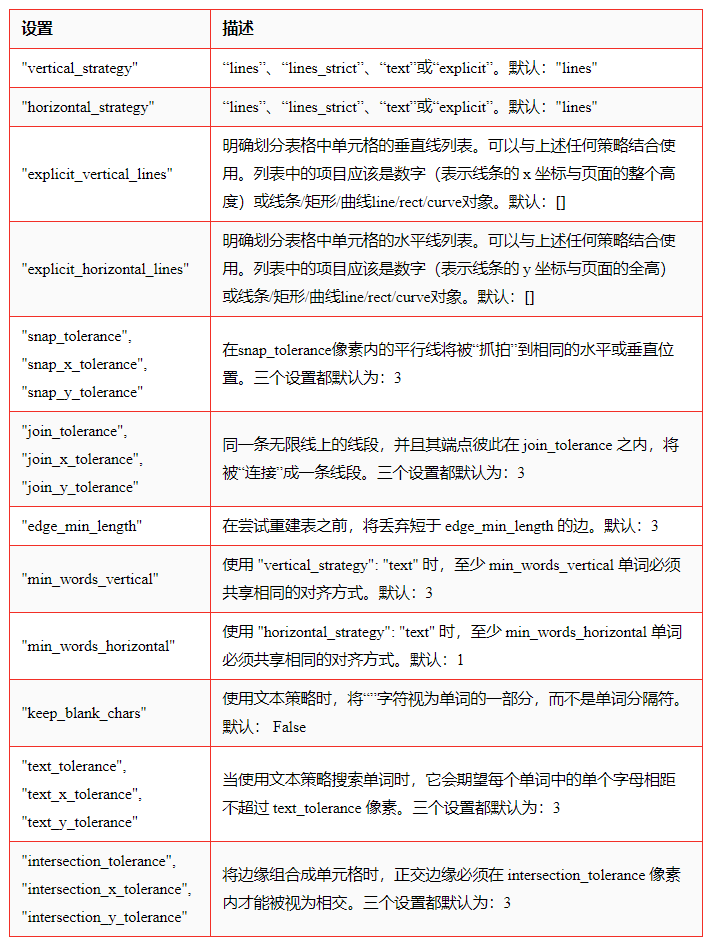
3、提取表的策略
vertical_strategy 和 Horizontal_strategy 都接受以下选项:

小tips:通常,在尝试提取表格之前裁剪页面(Page.crop(bounding_box))会很有帮助。
04
图片提取
文字内容和表格的提取在上面我们已经介绍了,但是对于pdf里的图片要如何获取呢?
pdfplumber目前没有专门的方法来提取,不过有一个间接的方法来提取图片。
基本思路:根据.images,获取图片在页面上的位置信息,然后通过.crop(bounding_box, relative=False)对页面进行裁剪,再把裁剪后的页面转换成PageImage对象。
假设有这样一个图片.pdf:

提取代码:
import pdfplumber
pdf = pdfplumber.open("图片.pdf") #加载 PDF
p1 = pdf.pages[0] # 获取第1页
print(p1.width) # 获取页宽
print(p1.height) # 获取页高
print(p1.images) # 获取图片的信息
'''
595.276
841.89
[{'x0': 68.446739, 'y0': 388.108032, 'x1': 537.446739, 'y1': 648.108032, 'width': 469.0, 'height': 260.0, 'name': 'KSPX5',
'stream': , 'Length': 893703, 'Filter': /'FlateDecode'}>,
'srcsize': (1350, 750), 'imagemask': None, 'bits': 8, 'colorspace': [/'DeviceRGB'], 'object_type': 'image', 'page_number': 1,
'top': 193.781968, 'bottom': 453.781968, 'doctop': 193.781968}]
'''
crop= p1.crop((65, 190, 540, 460) ) # 裁剪页面,bounding_box表示为 (x0, top, x1, bottom) 的 一个4 元组
im = crop.to_image(resolution=150) # 把裁剪后的页面转换成PageImage对象
im.save('实例.PNG') # 保存图片 效果:

好啦,今天的内容就到这~又是学习了的一天呢~

END

您的“点赞”、“在看”和 “分享”是我们产出的动力。