python爬虫入门——requests库、BeautifulSoup库和re库
对于大多数网页,如果它们的页面是由html代码静态生成的,那么我们可以通过访问网页的源代码,即网页对应的html文档内容,从文档中解析出我们想要的内容,然后将其摘录下来,存储在一定的数据结构中
在上一篇博客中,我简单介绍了一下基本的html知识,这些基本知识将会在本章的文档解析和信息摘录部分起到作用
写在前面
我的爬虫学习按照Mooc中国大学上的北理工嵩天老师的课程内容进行,目前进行入门级的爬虫程序,只需要编写50行以内的代码(没有优化,可能十分冗余)就能够完成一些非常简单的任务。因此,本博客仅供入门爬虫参考使用。
从网页源代码到→html标签树
上一章节简单介绍了html知识,这里将操作一般网页的html文档,并让其友好显示
一个网页的源代码获取
html网页的源代码获取可以通过requests库非常简单的实现,这里编写一个getHtmlText()函数来简单说明。
import requests
def getHtmlText(url):
try:
r = requests.get(url) #访问一个网页
r.raise_for_status() #检查网页是否响应,若否,抛出一个异常,转入except代码行
r.encoding = r.apparent_encoding #自动解析并赋值页面编码格式
return r.text #返回网页的html文档
except:
print('fail connect')
这里使用requests对给定的网页进行访问,若访问正常,则获得该网页的html文档。每一步的意义在代码中由注释说明。
从源代码到→标签树
html文档直接打印出来会非常不友好,中英文显示,外加结构不清晰,将会对我们解析网页结构有很大的干扰,因此这里建议对获得的html文档构造一个标签树,标签树将会把html文档以层级结构显示出来,从而使文档内容显示的更加友好。
下面用一个函数来说明如何对html文档构造一个标签树(代码承接上一部分代码)。
from bs4 import BeautifulSoup
def tagstree(htmltext,printtree=False):
soup = BeautifulSoup(htmltext,'html.parser') #构造一个标签树
if printtree = True:
print(soup.prettify()) #打印出有层级结构的标签树
return soup #返回标签树,是bs4库中的BeautifulSoup类
else:
return soup
函数每一步的作用和最终返回的结果均在代码注释中,不再解释。
信息的收集:向标签树中寻找信息
上面说到,标签树函数最终返回的是bs库中的BeautifulSoup类,这个类具有一类查找其自身(标签树)内容的方法,这里举最常用的find_all()方法进行演示。
在标签树被打印出来后,我们能够很清楚看到页面中每个信息或元素在标签树中的位置。那么,当我们想要该类元素时,我们便可以通过提取标签树中对应位置的标签,然后对这类标签的特征进行解析,提取出我们想要的内容。
在用一段代码函数演示前,我首先给出前两个函数的结果。下面是对bilibili视频网站首页的标签树构建结果。
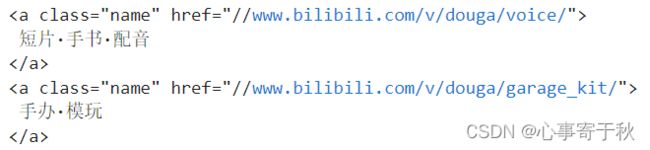
现在,我希望提取网站首页的所有视频分类名称,如上图的中文所示。借助BeautifulSoup库构造信息提取函数如下:
def getvideotype(tree):
video_type_list = [] #用列表储存所有视频类别
video_types = tree.find_all('a',{'class':'name'}) #按照上图需要信息所在的标签特征,进行查找(链接标签,类别属性是name)
for video_type in video_types: #返回的video_types是bs4库中的ResultSet类,是一个可迭代对象,我们需要遍历其中搜索到的对象,依次提取我们需要的信息
video_type_list.append(video_type.string) #提取的信息是标签的string内容,提取后存在预先构造的列表中
return video_type_list
每一步的意义见注释。简单爬取后,得到的列表数据如下:

信息的收集_2:利用正则表达式向html文档查找
使用第一个函数获得的html文档实质是一串字符串,那么我们可以使用正则表达式re库向其进行检索,找到我们想要的内容。
使用正则表达式对文本进行查找会很快。不过,我们也需要先知道信息大概长什么样,前后的文本特征有什么特点,才能够正确使用正则表达式查找到我们想要的信息。
这里构造一个正则表达式来实现与上一个函数相同的功能。
注:正则表达式我刚刚使用,并没有深入学习。所以写的可能有些冗余
import re #引入正则表达式库
url = ''https://www.bilibili.com/?spm_id_from=444.41.0.0''
match = re.findall(r'"name">.+?,
getHtmlText(url)) #向html文档查询符合正则特征的所有字符,并将所有查出的字符存储到一个列表中
在经过正则表达式匹配后,所有查询的内容被存储到列表里,数据如下:

可以发现,正则表达式除了提取出我们想要的类别名称,也把标签属性和标签符号部分提取了出来。这是因为我还没有学会更好地正则表达式,来更精准的匹配信息特征。所以,在这里我可能还需要遍历列表中每一个字符,对他们进行字符提取操作,最终得到自己想要的信息。
实例——对B站某关键词视频搜索页的信息爬取
基于上面的信息提取步骤,我们便能够对一个html页面进行简单地爬取了。在这里我将附上一个对B站视频信息的爬取程序,它分别由多个模块化函数组成,并最终以DataFrame结构返回数据。
import requests
from bs4 import BeautifulSoup
import re
def gethtmltext(url,title):
'''
Describe:
用来获得B站视频搜索页某一title关键词的html文档
:url:B站视频搜索网页的url地址,str类型
:title:向url网页访问时,给定的搜索关键词,str类型
'''
try:
r = requests.get(url,
{"keyword":title})
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('fail connect')
def videoinfospider(keyword,page):
titlelist = []
datelist = []
timeslist = []
classlist = []
uplist = []
'''
Describe:
在B站视频页html文档中,构造标签树并从中寻找标题、发布日期、观看次数、视频类型、up名称五种信息。最终返回多个信息列表组成的元组
:keyword:搜索关键词,str类型
:page:搜索的页数,即在第page页进行搜索,int类型
'''
html = gethtmltext('https://search.bilibili.com/all?'+'keyword=' + keyword + 'page=' +str(page))
soup = BeautifulSoup(html,'html.parser')
title_tags = soup.find_all('a',{'class':'title'})
date_tags = soup.find_all('span',{'class':'so-icon time'})
times_tags = soup.find_all('span',{'class':'so-icon watch-num'})
class_tags = soup.find_all('span',{'class':'type hide'})
up_tags = soup.find_all('a',{'class':'up-name'})
for title in title_tags:
titlelist.append(title.get('title'))
for date in date_tags:
datei = re.findall(r'\d{4}-\d{2}-\d{2}',date.text)
datelist.append(datei[0])
for times in times_tags:
timeslist.append(re.findall(r'\d+',times.text)[0])
for class_ in class_tags:
classlist.append(class_.string)
for upname in up_tags:
uplist.append(upname.string)
return titlelist, datelist,timeslist,classlist,uplist #直接将列表做为列元素返回给dataframe中的某一列
def Bilibilivideospyder(keyword,page):
video_info = pd.DataFrame(columns = ['title','date','watch times','video type','up'])
'''
Describe:
是一个主函数,是对上面模块化函数的调用。不过,该函数顺带完成了元组中列表信息向DataFrame数据结构的转换。
:keyword:搜索关键词
:page:搜索的页数,即在第page页进行搜索,int类型
'''
for i in range(page):
infolist = videoinfospider(keyword,i)
data1 = pd.DataFrame()
data1.loc[:,['title']] = infolist[0]
data1.loc[:,['date']] = infolist[1]
data1.loc[:,['watch times']] = infolist[2]
data1.loc[:,['video type']] = infolist[3]
data1.loc[:,['up']] = infolist[4]
video_info = video_info.append(data1, ignore_index=True)
return video_info
下面对函数简单实用,比如我想查询关于“碟中谍”系列电影的视频,直接搜索关键词“碟中谍”,返回的数据结果如下:
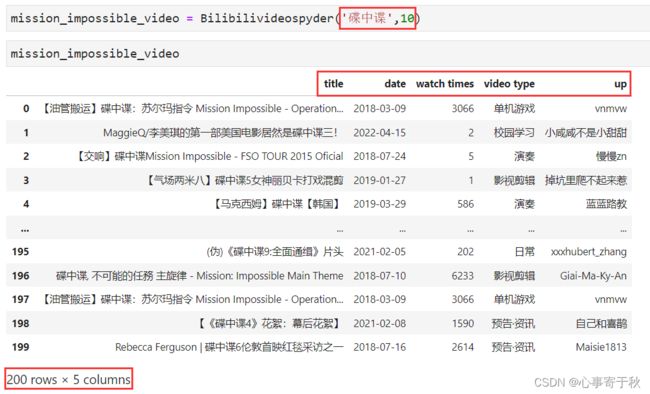
可以发现在DataFrame中,我们已经抓取了响应关键词下共200个视频的五类信息。后续,我们可以将DataFrame导入excel或者其他任意格式,进行简单的数据存储。
后记
文中有不少内容和方法没有提及或详细解释,但是也很重要,它们分别是:
1.B站视频搜索网页的关键词搜索和翻页接口
2.正则表达式对某一类特征字符的表示方法
3.bs4库中ResultSet对象的使用
4.可能用到的,对bs4下不同级别Tag的节点查找
5.pandas库中对DataFrame进行构造和增加数据条的方法