【C++进阶之路】继承篇
文章目录
- 前言
- 一、概念
- 二、性质
-
- 1.赋值转换
- 2.作用域——隐藏/重定义
- 3.默认成员函数
-
- ①构造函数
- ②拷贝构造
- ③析构函数
- ④赋值重载
- 4.友元函数
- 5.多继承
-
- ①单继承—— "一脉单传"
- ②多继承——"一父多子"
- ③菱形继承—— "一子多父"
- ④菱形虚拟继承
- 三、总结
前言
前面我们讲过面向对象的第一大特性——封装,接着我们要面对的就是第二大特性——继承,那继承是啥呢?从功能的角度来说,就是复用。
比如:我们都有人的特性(性别,外貌,身份证号),那在社会上,我们可能还是学生、老师、工人等具有身份意义的信息,那如果在描述学生时,我们还需要把人的特性描述一遍,那未免有点太繁琐了,因此,学生,老师,工人就可以复用人的特性信息,再此基础上再添加对应身份特有的信息即可。
一、概念
前面我们通过举例,能够简单理解继承,下面我们来说一下,具体的定义:
- 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段。
- 继承允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。
- 继承是类设计层次的复用。
接下来我们从空间的角度来谈一下继承,一个对象具体划分,可以分为:
- 成员函数——常量区
- 非静态成员变量——取决于类实例化的作用域(全局:静态区,局部:栈区)
- 静态的成员变量——静态区
如何验证空间上的继承呢?我们先讲继承的用法,之后会证明。
下面我们从权限的角度来理解,如何定义一个继承类:

- 继承方式有三种——公有继承(最常用),保护继承和私有继承(不常用)。
- 说明:如果继承方式不写,默认为私有继承。
那继承方式有什么用呢?一张表即可说明:
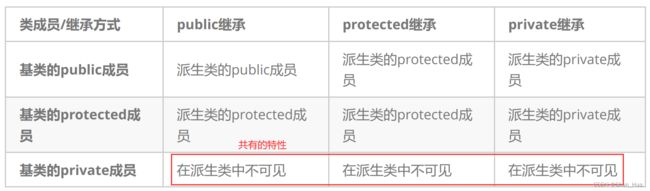
总结:
- 不管什么继承,基类的private成员在派生类中不可见。
- 继承方式,按访问权限小的进行继承,比如基类的public成员,采用protected继承,按权限小的继承,继承之后,基类的public成员是派生类的protected成员。
- 不写继承方式,默认为私有继承。
protected成员与private成员区别:基类的protect成员在继承之后还能通过派生类在类里进行使用,而private则无法访问。
此时我们再来完成上面的证明:
代码:
class A
{
public:
void func()
{
cout << "A::func()"<<endl;
}
int _a = 1;
static int _c;
};
int A::_c = -1;
class B : public A
{
public:
int _b = 0;
};
int main()
{
A a;
B b;
//成员函数
a.func();
b.func();
cout << endl;
//非静态的成员变量
cout << &a._a << endl;
cout << &b._a << endl << endl;
//静态的成员变量
cout << &a._c << endl;
cout << &b._c << endl;
return 0;
}
- 调试查看反汇编的函数地址:

结论:调用的是用一个函数,因此成员函数继承的是使用权。
再来运行代码:
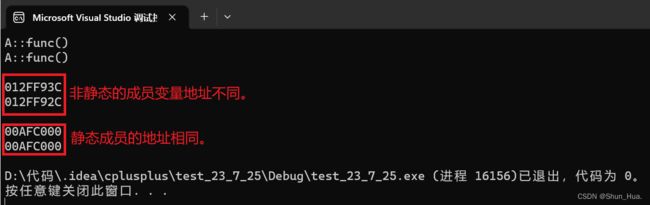
- 结论:非静态成员变量继承的是一份成员变量的拷贝。静态成员变量继承的是使用权。
总结:
成员函数和静态成员变量继承的是使用权。非静态成员变量继承的是一份成员变量的拷贝。
二、性质
1.赋值转换
在讲赋值转换之前,我们得先来搞懂,继承的引用和指针的用法。
class A
{
public:
void func()
{
cout << "A::func()"<<endl;
}
int _a = 1;
static int _c;
};
int A::_c = -1;
class B : public A
{
public:
int _b = 0;
};
int main()
{
B b;
int i = 0;
int& ri = i;
const double& di = i;
A& rb = b;
A* rptr = &b;
return 0;
}
我们之前讲过,不同类型的引用中间会生成临时变量,而临时变量具有常属性,因此这里的i转换为double中间会生成临时变量,因此需要加上const。
但是继承之后的类转换为基类,不会生成临时变量,因此没有加上const。这种现象被称之为向上转换,也就是能子类向父类进行转换。
原理:
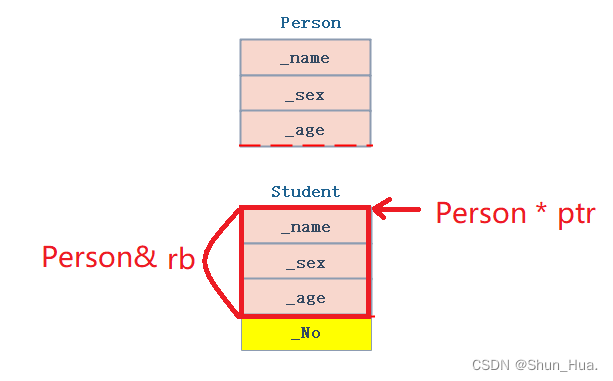
- 相当于是权限的缩小,也就是切割。
拓展:
一个指向派生类的基类指针可以通过安全转换,来转换为子类的指针,从而达成向上转换。
class A
{
public:
void func()
{
cout << "A::func()"<<endl;
}
int _a = 1;
static int _c;
};
int A::_c = -1;
class B : public A
{
public:
int _b = 0;
};
int main()
{
B b;
A* rptr = &b;
B* rrptr = static_cast <B*>(rptr);
//B* rrptr = dynamic_cast (rptr);
//这个是虚函数才能使用的(多态会将)。
return 0;
}
- 说明:能进行引用和指针进行转换的前提是public继承,否则无法转换。
明白了这些,赋值转换就不难理解了。
class A
{
public:
void func()
{
cout << "A::func()"<<endl;
}
int _a = 1;
static int _c;
};
int A::_c = -1;
class B : public A
{
public:
int _b = 0;
};
int main()
{
B b;
A a;
a = b;
//编译器生成的为 A & A::operator = (const A &);
//b = a;报错,因此引用支持向下转换,不支持向上转换。
//且无法进行强制类型转换。
return 0;
}
- 赋值转换也就是用了引用的语法,对子类进行切割。
2.作用域——隐藏/重定义
为了理解作用域的性质,我列出一段代码便于理解:
class Person
{
public:
int func(int i)
{
cout << "Person::func" << endl;
}
int _num = 0;
};
class Student : public Person
{
public:
void func()
{
cout << "Student::func" << endl;
cout << _num << endl;
}
int _num = 1;
};
int main()
{
Student stu;
stu._num = -1;
stu.func();
//stu.func(1);
return 0;
}
代码的运行结果为:

- 为啥不会报错呢?
- 结果为啥是这样呢?
- 这里的func构成重载吗?
- 将注释的代码放开,会产生什么结果?为什么?
我们首先要明白作用域是编译器查找的范围,而作用域包括局部域,全局域,命名空间域,类域,作用域限定符的作用是指定在某个域里面查找,否则就报错。
然后我们再来说明这里为啥不会报错,因为继承下来的东西,并不在一个类域里面,又因为不同类域是独立存在的,因此互相会产生屏蔽左右,那么我们一般称由命名相同产生屏蔽的现象,称为隐藏或者重定义。
明白这两个概念,我们再来分析第二个问题,首先对_num赋值-1,先在Studen的类域进行查找,如果找到就停止,很显然这里是对Student的_num进行赋值,然后调用func函数,同理,先对Student进行查找,如果找到就停止,这里找到了,调用的是Student里的func函数,最后查找_num,首先再当前局部域查找,如果没有就在当前类域进行查找,如果还没有就在基类的类域进行查找,如果还没有就在全局域进行查找,如果还找不到就报错。很显然这里是到当前类域就找到了,因此是Student的类域里的_num。
有了隐藏/重定义的概念,这里的func显然是不构成重载的,因为重载要求在同一个类域!
最后将注释的代码放开,会产生编译报错的结果,因为编译器很懒,它找到就不再找了,所以这里查找的还是Student的func。
3.默认成员函数
①构造函数
class A
{
public:
A()
:_a(1)
{}
int _a;
};
class B : public A
{
public:
B()
:_b(0)
{}
int _b;
};
int main()
{
B a;
return 0;
}
调试 f11逐语句运行:
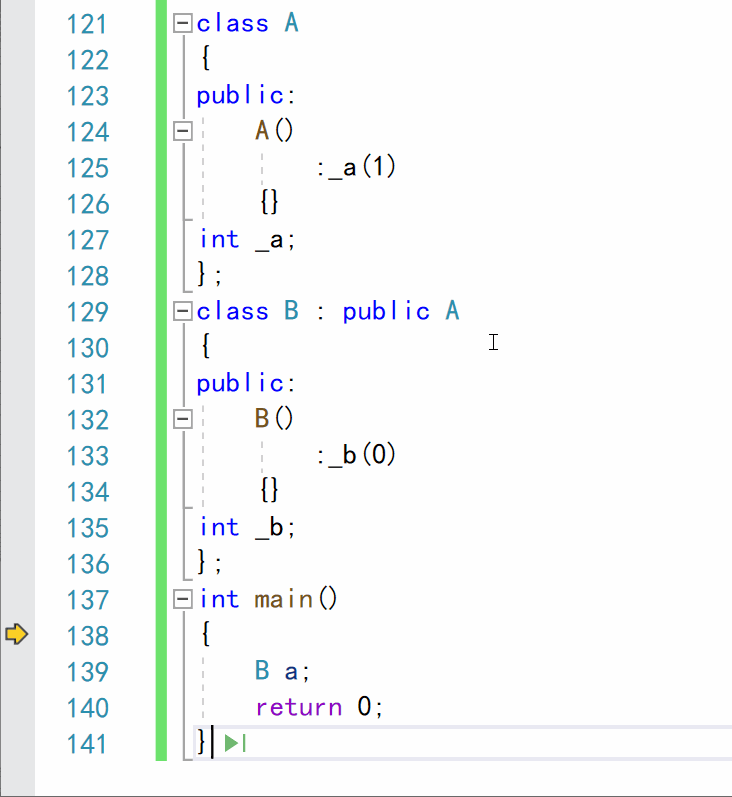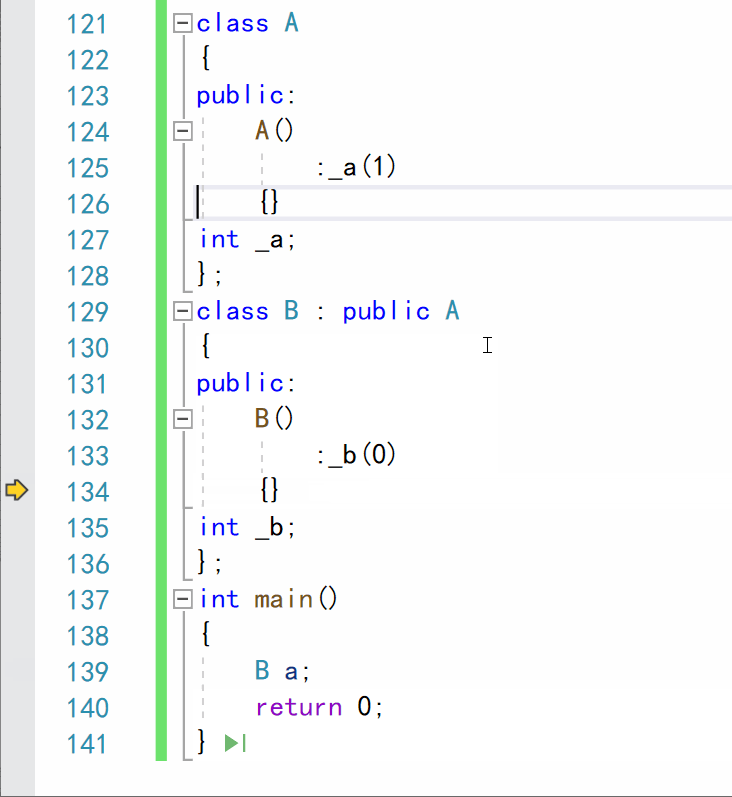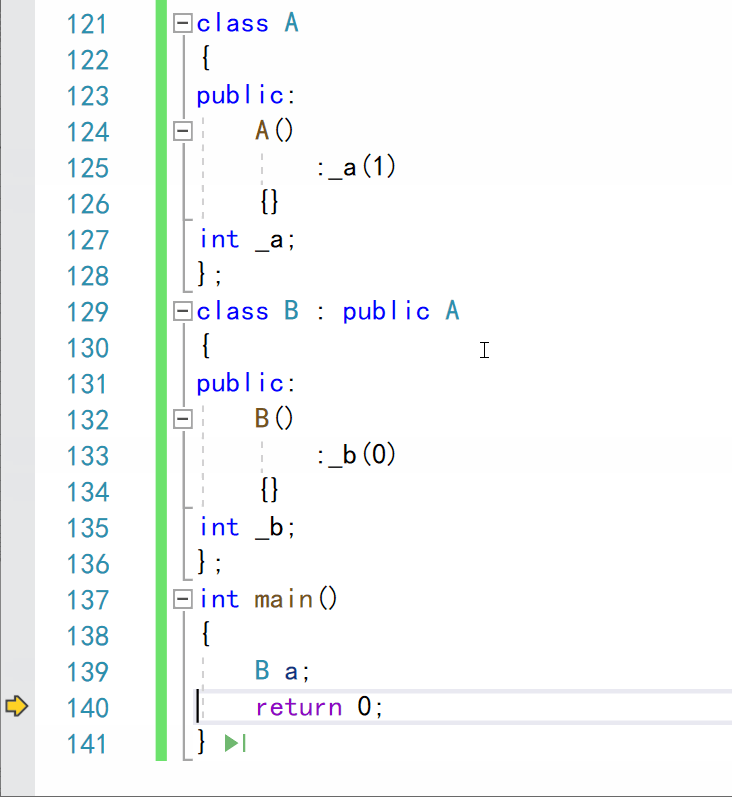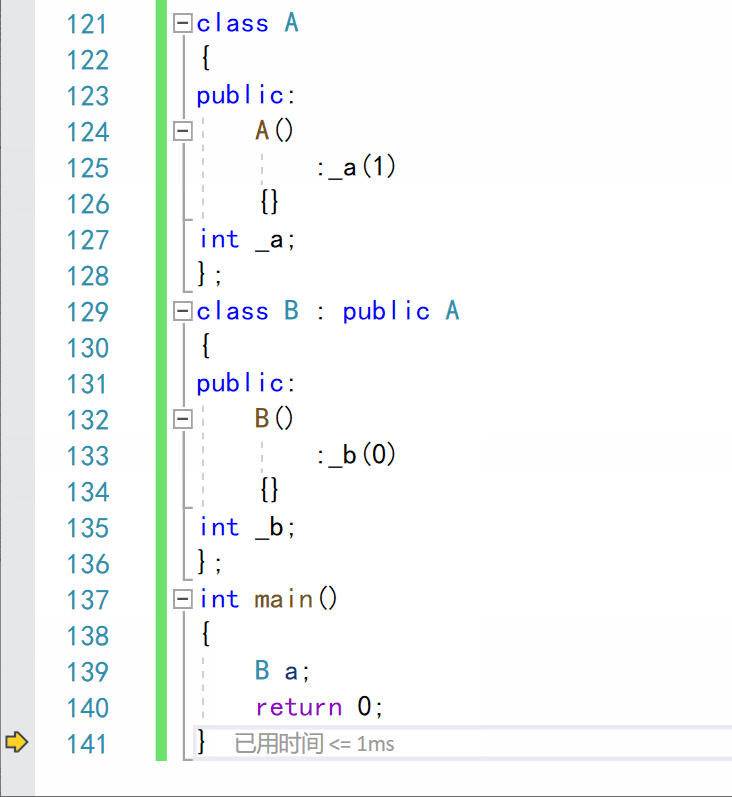
- 不难看出,在调用子类的构造函数时,先调用了父类的构造函数,构造派生类的成员,然后再调用子类的构造函数,对子类成员进行构造。
为啥要这样设计呢?
个人理解:总不能一个人干两份活吧?你干你的,我干我的,这样分工比较明确,至于先后顺序,可能是因为子类的成员可能会用父类成员的一些值初始化。
说明一点:如果子类的初始化列表,没有显示调用父类的构造函数,则调用默认构造函数,如果没有,则报错,这也说明了如果父类没有默认构造,要在子类显示的调用父类的构造函数。
举例:
class A
{
public:
A(int val)
:_a(val)
{}
int _a;
};
class B : public A
{
public:
B()
:_b(0)
,A(1)
{}
int _b;
};
int main()
{
B a;
return 0;
}
- 强调一点,初始化的顺序与初始化列表的顺序无关,这里构造函数先调用初始化列表中的A的构造函数,再走子类的初始化列表。
②拷贝构造
class Person
{
public:
Person(const char* name = "张三", int age = 18)
{
_name = name;
_age = age;
}
Person(const Person& per)
{
_name = per._name;
_age = per._age;
}
private:
string _name;
int _age;
};
class Student :public Person
{
public:
Student(const char* name = "张三", int age = 18,int id = 12345)
:Person(name,age)
,_id(id)
{
_id = id;
}
Student(const Student& stu)
:Person(stu)
{
_id = stu._id;
}
private:
int _id;
};
int main()
{
Student stu2("李四",19,8888);
Student stu1 = stu2;
return 0;
}
-
拷贝构造跟构造函数的区别不大,这里在实现过程中,尤其是子类的拷贝构造在显示地调用父类的构造函数时,会发生向下转换(引用),这里很关键!
-
另外强调一点,如果不显示调用拷贝构造,会调用默认构造函数,但这样可能不会完成拷贝的效果,如果没有默认构造会报错!
最后总结:构造函数的调用顺序先父后子。
③析构函数
class A
{
public:
~A()
{}
};
class B : public A
{
public:
~B()
{}
};
int main()
{
B b;
return 0;
}
调试运行:

- 不难看出,析构子类,先调用子类的析构函数,再调用父类的析构函数。
思考一下为啥会这样?
这就跟构造函数有点关系了,我们构造的时候,提过先构造父类的成员变量,再构造子类的成员变量,这样是为了增加子类的信息灵活度,可以让子类的成员跟父类沾上边,如果沾上边的话,析构如果先析构父类,那子类跟父类沾上边的成员的数据就失效无法使用,如果在子类的析构中再进行使用,那么可能就会产生越界等危险行为,因此先析构子类的成员,再析构父类的成员就显得必要了。
④赋值重载
- 现代写法
class A
{
public:
A(int a = 0, int b = 0)
: _a(a)
, _b(b)
{}
void swap(const A& a)
{
_a = a._a;
_b = a._b;
}
A& operator = (A a)
{
swap(a);
return *this;
}
private:
int _a;
int _b;
};
class B : public A
{
public:
B(int a = 0, int b = 0, int c = 0, int d = 0)
:A(a,b)
,_c(c)
,_d(d)
{}
void swap(const B& b)
{
A::swap(b);
_c = b._c;
_d = b._d;
}
B& operator =(B b)
{
swap(b);
return *this;
}
int _c;
int _d;
};
int main()
{
B b1(1,2,3,4);
B b2(4,3,2,1);
b1 = b2;
return 0;
}
- 普通写法
class A
{
public:
A(int a = 0, int b = 0)
:_a(a)
, _b(b)
{}
A& operator = (const A& a)
{
if (this != &a)
{
_a = a._a;
_a = a._b;
}
return *this;
}
private:
int _a;
int _b;
};
class B : public A
{
public:
B(int a = 0, int b = 0, int c = 0, int d = 0)
:A(a,b)
,_c(c)
,_d(d)
{}
B& operator =(const B& b)
{
if (this != &b)
{
//因为基类的私有成员,在派生类中不可见,所以我们需要调用基类的赋值进行拷贝。
A::operator =(b);
_c = b._c;
_d = b._d;
}
return *this;
}
int _c;
int _d;
};
- 继承多的就是重定义+向上转换
4.友元函数
C++11 标准不允许友元函数的声明有默认参数,除非友元声明是一个定义
个人理解:为了防止不合适参数,如还未被定义的类的匿名对象,可能直接报错。
class B;
class A
{
friend void func(const A& a, const B& b);
public:
private:
int _a = 1;
};
class B :public A
{
public:
private:
int _b = 2;
};
void func(const A& a, const B& b = B())
{
cout << a._a << endl;
cout << b._a << endl;
//cout << b._b << endl;
}
int main()
{
B b;
func(b,b);
return 0;
}
代码结果:

将注释的代码放开:
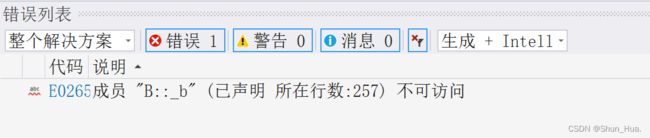
- 结论:友元类是无法被子类继承的,友元是仅限于突破父类作用域,也就是说,友元函数可以访问子类中的父类,也就是作用域在父类中,而子类的作用域则无法访问。
总结:友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员,但是子类中的基类的私有和保护成员可以通过基类的友元进行访问。
5.多继承
①单继承—— “一脉单传”
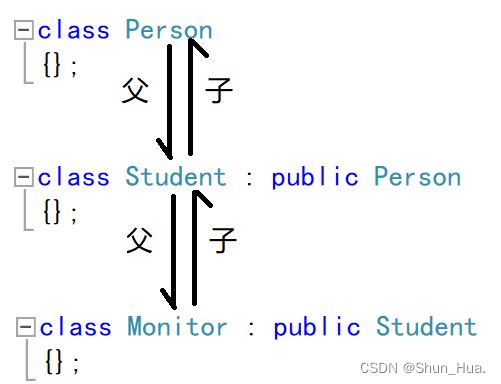
②多继承——“一父多子”
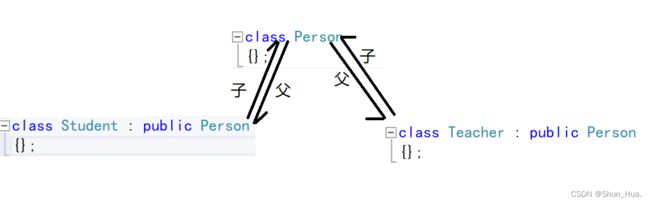
③菱形继承—— “一子多父”
- 由多继承衍生出来的问题。
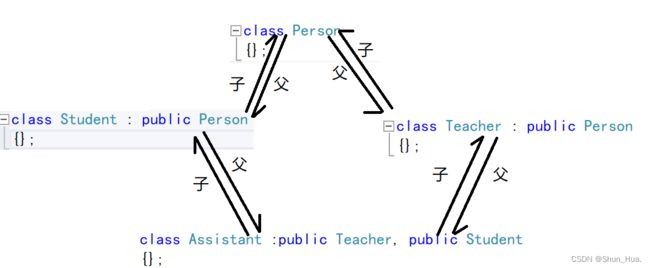
class Person
{
protected:
string _sex;
};
class Student : public Person
{
protected:
int _id;
};
class Teacher : public Person
{
protected:
string _profession;
};
class Assistant : public Student,public Teacher
{
protected:
int _age;
};
int main()
{
Assistant a;
a._sex = 1;
return 0;
}
对象模型:

说明:多继承从左往右进行继承。单继承先继承父类。也就是多继承从左往右开始,从上往下进行画对象模型,单继承从上往下,先画父类再画子类。
- 很显然,第一个问题,一个人不可能有两种性别吧?这样就导致了数据的冗余。
- 第二个问题,上述代码会报错,因为不知道访问的是哪一个_sex,必须得指定作用域,这样就导致了二义性。
那如何解决这个问题呢?
④菱形虚拟继承
如何实现呢?
class Person
{
public:
int _number = 10;
};
class Student : virtual public Person
{
public:
int _id = 6;
};
class Teacher :virtual public Person
{
protected:
int _telephone= 1;
};
class Assistant : public Student, public Teacher
{
public:
int _age = 18;
};
int main()
{
Assistant a;
return 0;
}
- 在基类衍生出来的第一代派生类的继承方式前加上virtual——虚拟继承
那其解决数据冗余和二义性的原理是什么呢?
第一步画出对象模型:

我们看出来,原来存Person的位置变了,取而代之的是类似与地址的数据。
我们再来验证一下是不是我们想的那样。
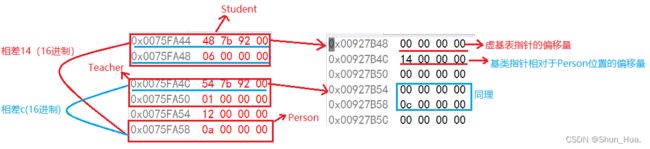
- 很显然是的。通过偏移量来进行计算Person位置,从而进行访问。
- 我们也能观察到偏移量是按照类的对象模型从上往下的规律排列的。
有人就要问了,为啥要用一张表存偏移量,而不是直接在原来的位置放上Person 的地址,答案其实很简单,想要知道Person的地址,不也得进行计算吗? 况且如果每个实例化的类都进行计算,那必然是损耗效率的,但是实例化的类都有一个特点那就是 相对位置不会发生改变!因此我们只需计算一次,然后直接根据相对位置进行计算,实例化的类共用一份即可,这样也提升了效率。
还有一点,这样在向上转换时就不容易出错。
int main()
{
Assistant a;
Student stu;
Student& stu1 = a;
stu1._number = 1;
//基类的引用,访问父类的虚基表,得到偏移量1,从而访问Person。
stu._number = 2;
//基类的对象,访问基类的虚基表,得到偏移量2,从而访问Person。(偏移量1 != 偏移量2)
return 0;
}
- 这样访问的方式相同,由于偏移量的矫正,都能够访问正确的基类!
三、总结
- 继承由于多继承引发的菱形虚拟继承而变得复杂。如java等OO语言就舍弃了多继承。
说明:OOP——Object Oriented Programming(面向对象编程)
- 继承的缺陷在于提高了耦合度。
举个例子:
1 . 黑盒测试:不知道实现,只知道其功能,那我们只需要进行功能上的测试即可。
2 . 白盒测试:实现暴露出来,也知道其功能,那我们还得理解其实现,才能进行测试。
继承,更像是一种白盒测试,我们从基类中继承的protect成员还能够进行使用,一旦基类的成员名一改,就会导致派生类的成员无法使用,这也就是耦合度提高的原因。
组合,更像是一种黑盒测试,我只用功能,你的底层细节我不关心,这样即使你的细节改了,对我没有影响,这降低了耦合度。
总结:组合更符合高内聚,低耦合的概念。因此我们更提倡使用组合。至于继承应该具体场景下分析再进行使用,尤其是多继承和菱形虚拟继承!
说明:
高内聚 ——一心只干一件事。
低耦合 ——不同功能的关联程度很小。
补充——组合与继承:
class A
{
protected:
int _a;
};
class B :public A
{
//继承
};
class C
{
class A;//组合
};
- 继承更像是一种
is_a关系,即花是植物,而组合更像是has_a的关系,即车里面有轮胎。
今天的分享就到这里了,如果觉得文章不错,点个赞鼓励一下吧!我们下篇文章再见!