知识梳理(一)
HTTPS握手过程
https的核心的技术:使用非对称加密传输对称加密的密钥,然后用对称加密通信
TLS
http--超文本传输协议,是以前并且沿用至今的网页协议。
缺点:http属于明文传输
HTTP的明文传输带来的问题是无法防止中间人截获、盗取和篡改信息,从你的路由器、运营商到对方服务器,中间每一步都是明文。
数据无价,所以为了实现保证数据的安全,在http的基础上,发展出了https。
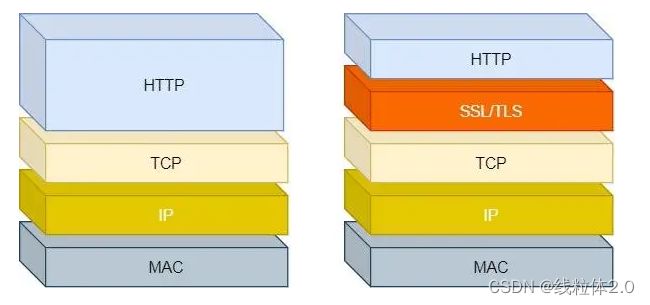
http属于应用层,基于TCP/IP参考模型,为了实现传输数据的安全,在应用程和传输层之间添加了一层SSL/TLS,实现数据的加密
样式大概是这样。
TLS解决http的风险分为三步:信息加密、校验机制以及身份验证
TLS的交互过程,见下图。
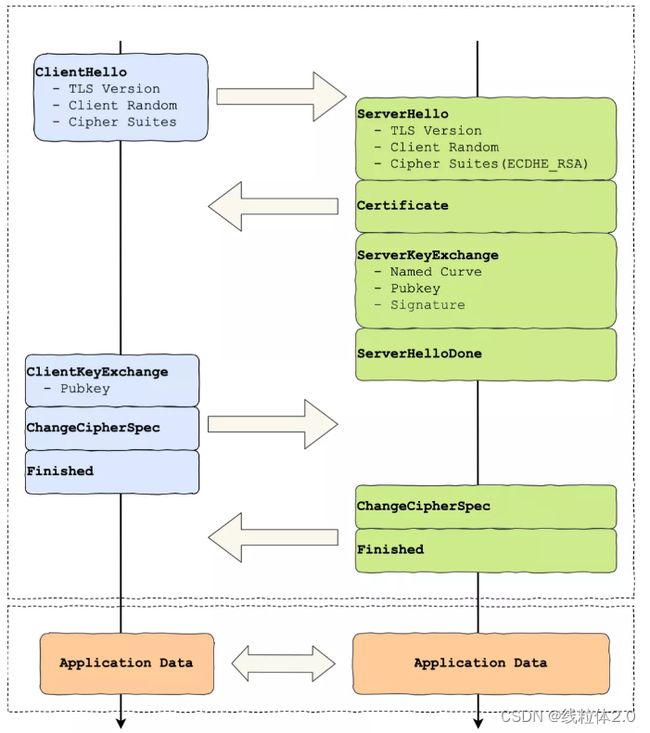
RSA密钥协商握手过程
第一次握手
先是客户端发出连接请求,即client hello包。
这个包里面主要包含了三个内容:TLS version(TLS版本)、Client Random(客户端随机数)、Cipher Suites(密码套件)
版本就是我客户端方面所支持的版本号,用于和服务端协商的,旨在相互适应。
随机数这个是客户端的,用于后面的加密。
密码套件这个是客户端想要使用的加密方法,也是用于协商的,这里是RSA。
第二次握手
服务端收到了客户端的hello包,会先回应一个Server hello包回去。
里面记录的内容和客户端发来的内容不尽相同,也是版本、随机数和密码套件,版本和套件协商,随机数用于加密。
然后服务端将会再发出下一个包Server Certificate
这个包里面包含一个数字证书,旨在证明自己服务端的身份
然后再发送Server Hello Done,告诉客户端hello结束,可以下一步了。
第三次握手
收到消息的客户端就开始忙活起来了,先是协商内容,没问题,看证书。
证书里面存在两个Hash值,第一个Hash值是 CA(证书签发机构) 把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算得出的。
第二个hash值是CA 使用自己的私钥将该值加密,生成 Certificate Signature,也就是 CA 对证书做了签名。
拿到两个值,客户端就需要使用同样的 Hash 算法获取该证书的 第一个Hash 值 ,到到一个结果,
然后,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到第二个 Hash 值,再得到一个结果。
最后两个结果一对比,没问题则开始第三步。
客户端发个Change Cipher Key Exchange给服务端。
包里面有一个新的随机数。
再发一个包Change Cipher Spec
这个包里面则是会话密钥,会话密钥由三个随机数组成,两个hello包里的,一个刚刚发送的,这里使用的是对称密钥
然后再发一个包Encrypted Handshake Message(Finishd),这个包使用了上面的加密内容,需要密钥才可解开
第四次握手
收到了上面的三个包,拆开第一个包获得随机数,然后自己加密一下。
然后Change Cipher Spec,也发Encrypted Handshake Message。
最后双方自行验证,没有问题,连接就建立了。使用会话密钥进行通话。
正则表达式
正则表达式(regular expression)是一种表达文本模式(即字符串结构)的方法,有点像字符串的模板,常常用来按照“给定模式”匹配文本
这里使用js代码来掩饰。
js正则一般表示
ler a = /abc/; --方法一
let b = new RegExp('abc') -- 方法二
匹配规则
字面量字符和元字符
| 符号 | 含义 |
| .(点字符) | 匹配除了回车、换行、行分隔符和段分隔符以外的字符 |
| ^ | 表示字符串的开始位置 |
| $ | 表示字符串的结束位置 |
| |(选择符) | 用来表示“或”的意思 |
点字符
/a.b/.test('acb') //true
/a.b/.test('adb') //true
/a.b/.test('a-b') //true
/a.b/.test('a:b') //true
/a.b/.test('accb') //false
/a.b/.test('a b') //true/XXX/:表示正则表达式,test输出布尔值,判断内部内容是否符合。
由上面可知,点字符的匹配只能匹配一次
位置符
/^a/.test('acb') //true
/ab$/.test('acb') //false
/^ab$/.test('acb') //false
/^acb$/.test('acb') //true
/^acb$/.test('acb acb') //false^:表示以什么字符开头,$:则表示以什么字符结尾。两者同时使用则是获取单词,但匹配是整段内容,所以需要注意。
选择符
/a|b/.test('b') //true
/(a|b)c/.test('ac') //true
/acd|bcc/.test('acd') //true|:表示或,这里的或不仅仅是单个单词也可以是一段字符,即将“|”两端看作整体,以此来取。
特殊字符
-
\cX表示Ctrl-[X],其中的X是A-Z之中任一个英文字母,用来匹配控制字符。 -
[\b]匹配退格键(U+0008),不要与\b混淆。 -
\n匹配换行键。 -
\r匹配回车键。 -
\t匹配制表符 tab(U+0009)。 -
\v匹配垂直制表符(U+000B)。 -
\f匹配换页符(U+000C)。 -
\0匹配null字符(U+0000)。 -
\xhh匹配一个以两位十六进制数(\x00-\xFF)表示的字符。 -
\uhhhh匹配一个以四位十六进制数(\u0000-\uFFFF)表示的 Unicode 字符。
预定义模式
| 符号 | 含义 |
| \d | 匹配0-9的任意数字 |
| \D | 匹配除了数字的字符 |
| \s | 匹配空格,即不显示内容的符号,像制表符、换行符 |
| \S | 匹配除了空格以外的字符 |
| \w | 匹配任意数字、字母和下划线 |
| \W | 匹配除了数字、字母和下划线的字符 |
| \b | 匹配单词边界 |
| \B | 匹配非单词边界 |
小写和大写可以说互为补集,小写不包含的大写包含,反之亦然
/\d*/.test('123') //true
/\d*/.test('123a') //false
/\d*/.test('123_') //false
/\D*/.test('123') //false
/\D*/.test('abc') //true
/\D*/.test('\n\r') //true
/\s*/.test('\n\r\v\f') //true
/\s*/.test('123') //false
/\S*/.test('123') //true
/\w*/.test('123') //true
/\w*/.test('123abc') //true
/\w*/.test('1a2b3c_') //true
/\W*/.test(' :') //true
/\W*/.test('123:abc') //false
/\bab/.test('ab cd') //true
/\bcd/.test('ab cd') //true
/\bab/.test('ab-cd') //true
/\bab/.test('abcd') //false
/\Dab/.test('abcd') //true
根据上面的大写和小写的特性,可得:\s\S,\d\D,\b\B,\w\W,这四组任何一组均可表示所有字符
量词符
| 符号 | 含义 |
| ? | 表示匹配0次或者是1次 |
| * | 表示匹配0次或者无数次 |
| + | 表示匹配一次或者无数次 |
| {} | 表示范围,视真实情况而定,第一个数字表示至少,第二个是指至多 |
/a*b/.test('ab') //true
/a*b/.test('b') //true
/a*b/.test('aaaaab') //true
/a+b/.test('ab') //true
/a+b/.test('b') //false
/a+b/.test('aaab') //true
/a?b/.test('ab') //true
/a?b/.test('b') //true
/a{1,3}b/.test('ab') //true
/a{2}b/.test('ab') //false
/a{,2}b/.test('ab') //true
/a{3,8}b/.test('aaaaab') //true量词符比较常用
括号字符
{}:表示上一个符号出现范围,第一个数字表示至少,第二个数字表示至多。
():表示一个组,将里面内容看作整体
[]:也像选择符一样,里面的字母为“或”关系,但如果在里面加入了^表示非,-表示一定范围
/lo{3,5}k/.test('loook') //true
'hello world'.replace(/(\w+)\s(\w+)/, '$2 $1')
// "world hello"
这里的()有了标号,1表示第一个内容,2表示后面的内容
第一个()选取的是hello,第二个是word,replace将它们进行了调换
/[abc]/.test('kjhgfds') //false
/[abc]/.test('kajhgfds') //true
/[^abc]/.test('qwerty') //true
/[a-z]/.test('v') //true
/[A-Z]/.test('a') //false
/[0-9]/.test('2') //true
/[0-9a-zA-Z]/.test('asdfgh245') //true[]的里面如果使用连字符-则表示一个范围,但这个范围是根据ASCII码来的,需要注意范围。^在里面起到去反作用,这里是需要保留空位的,需要注意。
贪婪匹配
贪婪匹配是针对量词的,像*一旦匹配到前方的内容,使用最多匹配原则,将合适的全部匹配出来。
'abbbbb'.match(/ab*/) //["abbbbb"]
'abbbbb'.match(/ab+/) //["abbbbb"]
'abbbbb'.match(/ab?/) //["ab"]抑制贪婪匹配则在量词符后添加一个?
'abbbbb'.match(/ab*?/) //["a"]
'abbbbb'.match(/ab+?/) //["ab"]
'abbbbb'.match(/ab??/) //["a"]修饰符
·i:无视字母大小写
·g:全局匹配
·m:多行匹配
断言
断言有先行断言和先行否定断言之分
先行断言:x(?=y),x只有在y前面才匹配,y不会被计入返回结果。
先行否定断言:x(?!y),x只有不在y前面才匹配,y不会被计入返回结果。
var m = 'abc'.match(/b(?=c)/); --匹配在c前面的内容
m // ["b"]
/\d+(?!\.)/.exec('3.14') --不匹配.前面的数字
// ["14"]
this关键字
this指向的几种情况
this都有一个共同点:它总是返回一个对象。
在js中this的指向非常重要。
var person = {
name: '张三',
describe: function () {
return '姓名:'+ this.name;
}
};
person.describe()
// "姓名:张三"这里的describe是对象person的一个方法,this.name表示name属性所在的那个对象。由于this.name是在describe方法中调用,而describe方法所在的当前对象是person,因此this指向person,this.name就是person.name。
这种的调用比较容易理解,调用对象自身的方法,this的指向依然是对象本身。
var A = {
name: '张三',
describe: function () {
return '姓名:'+ this.name;
}
};
var B = {
name: '李四'
};
B.describe = A.describe;
B.describe()
// "姓名:李四"和上面略有不同,同样是this,但是因为赋值语句的出现,B.describe = A.describe;A的describe方法赋值给了B的方法,所以调用之后就和上面相同,输出对象B的name。
下面这种情况则不相同
var A = {
name: '张三',
describe: function () {
return '姓名:'+ this.name;
}
};
var name = '李四';
var f = A.describe;
f() // "姓名:李四"上面内容大同小异,但是赋值是将方法进行了赋值,赋值给了一个变量,但后调用方法,即调用了匿名函数,匿名函数的运行是在全局对象下的,所以此时的this指向全局对象window,window下也存在变量name,所以输出了全局的name。这种情况,将相当于在全局下写了一个匿名函数,然后直接调用的结果。
var f = function () {
console.log(this.x);
}
var x = 1;
var obj = {
f: f,
x: 2,
};
// 单独执行
f() // 1
// obj 环境执行
obj.f() // 2第一个调用,是调用在全局之下的函数,this的指向是全局,即变量x的值,第二个调用,则是在对象obj下的方法的调用,this指向也就是obj。
所以,在全局下调用全局函数,this的指向就是全局window,但是如果是在全局调用对象的方法,this指向就是对象。但如果在构造函数中,this则指向实例对象。
var Obj = function (p) {
this.p = p;
};但一下几种情况会影响this指向
// 情况一
(obj.foo = obj.foo)() // window
// 情况二
(false || obj.foo)() // window
// 情况三
(1, obj.foo)() // window这里使用的都是立即执行函数。
第一种情况:赋值调用,将方法赋值给了另一个,并直接调用,此时指向window
第二种情况:此时前面为false,执行后面,后面虽然是方法,但是因为立即执行函数,相当于在全局下执行了函数,执行全局
第三种情况:和上面相似,属于直接在全局调用方法,指向window
var a = {
p: 'Hello',
b: {
m: function() {
console.log(this.p);
}
}
};
a.b.m() // undefined这里是嵌套,对象a里面嵌套了另一个,此时的this指向的应该是a.b,即和方法m同一层的p但是没有所以输出undefined。
this的多层指向
var o = {
f1: function () {
console.log(this);
var f2 = function () {
console.log(this);
}();
}
}
o.f1()
// Object
// Windowthis
this的指向不明确,所以,应该避免多层
var o = {
f1: function () {
console.log(this);
var f2 = function () {
console.log(this);
}();
}
}
o.f1()
// Object
// Window首先是第一个this,属于对象0里面的方法,随意this就指向对象,但第二个给this在函数嵌套里面,不在指向对象,而是指向全局对象。
解决方案
1、that
var o = {
f1: function() {
console.log(this);
var that = this;
var f2 = function() {
console.log(that);
}();
}
}
o.f1()
// Object
// Object这里呢就是将第一个this的指向赋值给了一个变量that,that保存着this的指向,即使里面再嵌套that依然不变。
2、严格模式,相当于监控,如果this指向全局就会报错。
var counter = {
count: 0
};
counter.inc = function () {
'use strict';
this.count++
};
var f = counter.inc;
f()
// TypeError: Cannot read property 'count' of undefined这种,与其说是解决方案,不如说是一种预警,提示编程人员this指飞了。
绑定this
call
var obj = {};
var f = function () {
return this;
};
f() === window // true
f.call(obj) === obj // true分明显全局调用,this就指向全局,但是call指定this的指向是obj,所以指向改变。
call还有一个特点:
call方法的参数,应该是一个对象。如果参数为空、null和undefined,则默认传入全局对象。
var n = 123;
var obj = { n: 456 };
function a() {
console.log(this.n);
}
a.call() // 123
a.call(null) // 123
a.call(undefined) // 123
a.call(window) // 123
a.call(obj) // 456apply
apply和call相似,call如果传参只能传两个,而apply可以传多个
var obj = {};
var f = function () {
return this;
};
f() === window // true
f.apply(obj) === obj // truebind
var counter = {
count: 0,
inc: function () {
this.count++;
}
};
var func = counter.inc.bind(counter);
func();
counter.count // 1counter.inc()方法被赋值给变量func。这时必须用bind()方法将inc()内部的this,绑定到counter,否则就会出错。
var counter = {
count: 0,
inc: function () {
this.count++;
}
};
var obj = {
count: 100
};
var func = counter.inc.bind(obj);
func();
obj.count // 101这里是将它,绑在其他的对象,也是可以的。
箭头函数中的this
箭头函数在普通对象中
var code = 404;
let obj = {
code: 200,
getCode: () => {
console.log(this.code);
}
}
obj.getCode(); // 404
箭头函数是在定义函数时,就已经指明了this,而不是在调用时。此时的箭头函数指向外面的全局作用域,而不是对象。
箭头函数在函数中
var code = 404;
function F() {
this.code = 200;
let getCode = () => {
console.log(this.code);
};
getCode();
}
var f = new F() //200
var f = F() //构造函数没有new调用,就成为了一个普通函数
console.log(f)
console.log(code)第一个调用,已经明确指明在对象中了,而第二个构造函数,和前面的普通函数无异。
箭头函数在类中
var code = 404;
class Status {
constructor(code) {
this.code = code;
}
getCode = () => {
console.log(this.code);
};
}
let status = new Status(200);
status.getCode(); // 200
同样的已经指明了类,this的指向就是这个类。
let本身就是一个块级作用域,this已经被限定了
综上:this的注意点
-
this始终指向调用该函数的对象;
-
若没有指明调用的对象,则顺着作用域链向上查找,最顶层为global(window)对象;
-
箭头函数中的this是定义函数时绑定的,与执行上下文有关
-
简单对象(非函数、非类)没有执行上下文;
-
类中的this,始终指向该实例对象;
-
箭头函数体内的this对象,就是定义该函数时所在的作用域指向的对象,而不是使用时所在的作用域指向的对象。
js的同步和异步
js的执行顺序
js 是一种单线程语言,简单的说就是:只有一条通道,那么在任务多的情况下,就会出现拥挤的情况,这种情况下就产生了 ‘多线程’ ,但是这种“多线程”是通过单线程模仿的,也就是假的。那么就产生了同步任务和异步任务。
所以js为了提高效率,首先会将任务进行分类,分为同步和异步任务。除此自外,异步任务还进行了细分:宏任务和微任务。
宏任务:script、setTimeout、setInterval、postMessage
微任务:Promise.then ES6
所以js是先执行同步任务,同步执行完再执行异步任务,在异步任务中又是先执行微任务再执行宏任务。
案例
setTimeout(function(){
console.log(1);
});
new Promise(function(resolve){
console.log(2);
resolve();
}).then(function(){
console.log(3);
}).then(function(){
console.log(4)
});
console.log(5);
// 2 5 3 4 1自上而下执行,setTimeout宏任务队列,new Promise同步任务,promise.then微任务队列,console.log同步任务队列。
按照先同步再异步,所以先是Promise,输出2,再console.log输出5.然后异步,先微任务,promise.then,输出3,4,最后宏任务输出1.
function doFoo(fn) {
this.code = 404;
fn();
}
function f() {
setTimeout(() => {
console.log(">>>" + this); // >>>[object window],语句2
this.code = 401;
}, 0)
console.log( this.code ); // 404,语句1
}
let obj = {
code: 200,
foo: f
};
var code = 500;
doFoo( obj.foo );
setTimeout(()=>{console.log(obj.code)}, 0); // 200,语句3
setTimeout(()=>{console.log(window.code)}, 0); // 401,语句4
和上面一样,先是对语句进行划分,先同步,函数中的console.log进行打印,此时的this指向的是f()的上一层,也就是输出404,没有微任务,宏任务顺序执行,第一个计数器输出,这里的this指向计时器的上一层,也就是全局,同时计时器修改了全局里面的this.code值,然后后面两个计时器依次执行,输出obj和window的code值。