经验总结 | 重构让你的代码更优美和简洁
前言
最近有幸对订单Push项目进行了重构,向大家分享一下代码重构相关的工作经验,希望对大家有所启发。
有时候,我们在做某个功能需求时,需要花掉大量的时间,才能找到和需求有关联的代码。或者我们在阅读别人写的代码、接手别人的项目时,总是“头皮发麻”,当你面对结构混乱、毫无章法的代码结构,词不达意的变量名、方法名时,我相信你根本没有读下去的心情。这不是你的问题,而是你手中的代码需要进行重构了。
代码质量的唯一有效度量是:WTFs(what the fuck)/minute

何为重构
每个人对重构都有自己的定义,我这里引用的是“Martin Fowler”的定义,他从两个维度对重构进行了定义。
作为名词:重构是对软件内部结构的一种调整,目的是在不改变软件可观察行为前提下,提高其可理解性,降低其修改成本。
作为动词:重构是使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
我在本文提到的代码重构,更偏向它作为动词的定义,而根据重构的规模程度、时间长短,我们可以将代码重构分为小型重构和大型重构。
小型重构:是对代码的细节进行重构,主要是针对类、函数、变量等代码级别的重构。比如我们常见的规范命名(针对词不达意的变量再命名),消除超大函数,消除重复代码等。一般这类重构修改的地方比较集中,相对简单,影响比较小、时间较短。所以难度就相对比较低一些,我们完全可以在日常的随版开发中进行这类重构。
大型重构:是对代码顶层进行重构,包括对系统结构、模块结构、代码结构、类关系的重构。我们一般采取的手段是进行服务分层、业务模块化、组件化、代码抽象复用等。这类重构我们可能需要进行原则再定义、模式再定义甚至业务再定义。涉及到的代码调整和修改比较多,所以影响比较大、耗时较长、带来的风险比较大(项目叫停风险、代码Bug风险、业务漏洞风险)。这就需要我们具备大型项目重构的经验,否则我们很容易在重构中犯错,最后得不偿失。
其实大多数人都是不喜欢重构工作的,就像没有人愿意给别人“擦屁股”一样,主要可能有以下几个方面的担忧:
- 不知道怎么重构、缺乏重构的经验和方法论,容易在重构中犯错。
- 很难看到短期收益,如果这些利益是长远的,何必现在就付出这些努力呢?长远看来,说不定当项目收获这些利益时,你已经不负责这块工作了。
- 重构会破坏现有程序,带来意想不到的Bug,不想去承受这些意料之外的Bug。
- 重构需要你付出额外的工作,何况可能需要重构的代码并不是你编写的。
为何重构
如果我纯粹为今天工作,明天我将完全无法工作
程序有两面价值:“今天可以为你做什么” 和 “明天可以为你做什么”。大多数时候,我们都只关注自己今天想要程序做什么。不论是修复错误或是添加特性,我们都是为了让程序力更强,让它在今天更有价值。但是我为什么还是提倡大家要在合适的时机做代码重构,多想想明天可以为你做什么,原因主要有以下几点:
1、让软件架构始终保持良好的设计。改进我们的软件设计,让我们的软件架构总是向有利的方向发展,能够始终对外提供稳定的服务、从容的面对各种突发的问题。
2、增加可维护性,降低维护成本,对团队和个人都是正向的良性循环,让软件更容易理解。不管是后人在阅读前人写的代码,还是事后回顾自己的代码,都能够快速的了解整个逻辑,明确业务,轻松的对系统进行维护。
3、提高研发速度、缩短人力成本。大家可能深有体会,一个系统在上线初期,向系统中增加功能时,完成速度非常快,但是如果不注重代码质量,后期向系统中添加一个很小的功能可能就需要花上一周或更长的时间。而代码重构是一种有效的保证代码质量的手段,良好设计是维护软件开发速度的根本。重构可以帮助你更快速的开发软件,因为它阻止系统腐烂变质,甚至还可以提高设计质量。
如何重构
小型重构
小型重构大部分都是在日常开发中进行的,一般参考的标准即是我们的开发规范和准则,目的是为了解决我们代码中的坏味道,我们来看一下常见的坏味道都有哪些?
泛型擦除
//{"param1":"v1", "param2":"v2", "param3":30, ……}
Map map = JSON.parseObject(msg); //【1】
……
// 将map作为参数传递给底层接口
xxxService.handle(map); //【2】
//看一下底层接口定义
void handle(Map map); //【3】 【2】处将已经泛型擦除的map传递给底层已经泛型限定的接口中,相信在接口实现中都是使用“String value = map.get(XXX)”这种方式获取值的,这样一旦map中有非String类型的值时,这里就会出现类型转换异常。读者肯定和我一样好奇,为什么该业务系统中未抛出类型转换异常,原因是业务系统取值的方式并未转换成String类型。可想而知,一但有人使用标准的方式获取值时,就会踩雷。
// 文本1${param1}文本2${param2}文本3${param3}
String[] terms = ["文本1","$param1", "文本2", "$param2", "文本3", "$param3"];
StringBuilder builder = new StringBuilder();
for(String term: terms){
if(term.startsWith("$")){
builder.append(map.get(term.substring(1)));
}else{
builder.append(term);
}
}无病呻吟
Config config = new Config();
// 设置name和md5
config.setName(item.getName());
config.setMd5(item.getMd5());
// 设置值
config.setTypeMap(map);
// 打印日志
LOGGER.info("update done ({},{}), start replace", getName(), getMd5());
......
ExpiredConfig expireConfig = ConfigManager.getExpiredConfig();
// 为空初始化
if (Objects.isNull(expireConfig)) {
expireConfig = new ExpiredConfig();
}
......
Map> typeMap = ……;
Map>>>> jsonMap = new HashMap<>();
// 循环一级map
jsonMap.forEach((k1, v1) -> {
// 循环里面的二级map
v1.forEach((k2, v2) -> {
// 循环里面的三级map
v2.forEach((k3, v3) -> {
// 循环最里面的list,哎!
v3.forEach(e -> {
// 生成key
String ck = getKey(k1, k2, k3);
// 为空处理
List types = typeMap.get(ck);
if (CollectionUtils.isEmpty(types)) {
types = new ArrayList<>();
typeMap.put(ck, types);
}
// 设置类型
}
}
}
} 代码本身一眼就能看明白是在干什么,写代码的人非要在这个地方加一个不关痛痒的注释,这个注释完全是口水话,毫无价值可言。
if-else过多
try {
if (StringUtils.isEmpty(id)) {
if (StringUtils.isNotEmpty(cacheValue)) {
if (StringUtils.isNotEmpty(idPair)) {
if (cacheValue.equals(idPair)) {
// xxx
} else {
// xxx
}
}
} else {
if (StringUtils.isNotEmpty(idPair)) {
// xxx
}
}
if(xxxx(xxxx){
// xxx
}else{
if(StringUtils.isNotEmpty(idPair)){
// xxx
}
// xxx
}
}else if(!check(id, param)){
// xxx
}
} catch (Exception e) {
log.error("error:", e);
}这样的代码,让代码阅读性大大降低,让很多人望而却步。被逼到迫不得已估计开发人员是不会动这样的代码的,因为你不知道你动的一小点,可能会让整个业务系统瘫痪。
注:本漫画来自网络(原作者 @我的邻居全是猫)
其他坏味道

这里就不再罗列叙述相关案例了,相信大家在日常中也经常看到很多代码书写不合理,让人不适应的地方,总结一下代码中常见的坏味道和解决办法:
1、重复代码
代码坏味道最多的恐怕就是重复代码,如果你在一个以上的地方看到相同的代码结构,那么可以肯定:设法将它们合而为一,程序会变得更好。
最常见的一种重复场景就是在“同一个类的两个函数含有相同的表达式”,这种形式的重复代码可以在当前类提取公用方法,以便在两处复用。还有一种和这类场景相似就是在“两个互为兄弟的子类含有相同的表达式”,这种形式可以将相同的代码提取到共同父类中,针对有差异化的部分,使用抽象方法延迟到子类实现,这就是常见的模板方法设计模式。如果两个毫不相干的类出现了重复代码,这个时候应该考虑将重复代码提炼到一个新类中,然后在这两个类中调用这个新类的方法。
2、函数过长
一个好的函数必须满足单一职责原则,短小精悍、只做一件事,浓缩精华。过长的函数体和身兼数职的方法都不利于阅读,也不利于进行代码复用。
3、命名规范
一个好的命名需要能做到“名副其实、见名知意”,直接了当,不存在歧义。
4、不合理的注释
注释是一把双刃剑,好的注释能够给我们好的指导,不好的注释只会将我们误导。针对注释,我们需要做到在整合代码时,也需要把注释一并进行修改,否则就会出现注释和逻辑不一致。另外如果代码清晰的表达了自己的意图,那么注释反而是多余的。
5、无用代码
无用代码有两种方式,一种是没有使用场景,如果这类代码不是工具方法或工具类,而是一些无用的业务代码,那么就需要及时进行删除清理。另外一种是用注释符包裹的代码块,这些代码在被打上注释符号的时候就应该被删除。
6、过大的类
一个类做太多事情,维护了太多功能,可读性变差,性能也会下降。举个例子,订单相关的功能你放到一个类A里面,商品库存相关的也放在类A里面,积分相关的还放在类A里面……试想一下,乱七八糟的代码块都往一个类里面塞,还谈啥可读性。应该按单一职责,使用不同的类把代码划分开。
这些都是比较常见的代码“坏味道”,实际开发中当然还会存在其他的一些“坏味道”,比如代码混乱,逻辑不清晰,类关系错综复杂,当闻到这些不同的“坏味道”时,都应该尝试去解决掉,而不是放纵不管不顾。
大型重构
相对小型重构,大型重构需要考虑的事情比较多,需要我们定好节奏,按部就班执行,因为在大型重构中,情况多变。
将大象装进冰箱的步骤一般可以分成三步:1、把冰箱门打开(事前)2、把大象推进去(事中)3、把冰箱门关上(事后),日常所有的事情都可以采用三步法进行解决,重构也不例外。
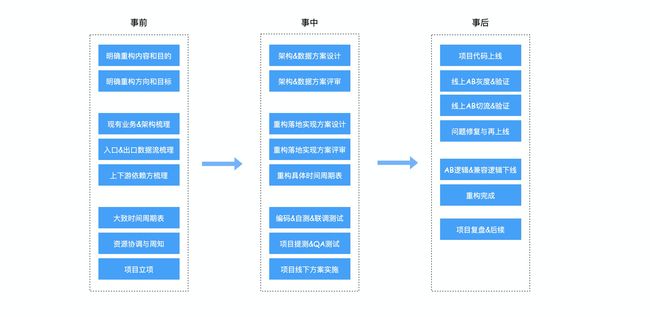
事前
事前准备作为重构的第一步,这一部分涉及到的事情比较杂,但是也是最重要的,如果之前准备不充足,很有可能导致在事中执行时或重构上线后产生的结果和预期不一致的现象。
在这个阶段大致可分为三步:
1、明确重构的内容、目的以及重构的方向、目标
在这一步里面,最重要的是把方向明确清楚,而且这个方向是经得起大家的质疑,能够至少满足未来三到五年的方向。另外一个就是这次重构的目标,由于技术限制、历史包袱等原因,这个目标可能不是最终的目标,那么需要明确最终目标是怎么样的,从这次重构的这个目标到最终的目标还有哪些事情要做,最好都能够明确下来。
2、整理数据
这一步需要对涉及重构部分的现有业务、现有架构进行梳理,明确我们重构的内容在系统的哪个服务层级、属于哪个业务模块,依赖方和被依赖方有哪些,有哪些业务场景,每个场景的数据输入输出是怎样的。这个阶段就会有产出物了,一般这一步会沉淀项目部署、项目业务架构、技术架构、服务上下游依赖、强弱依赖、项目内部服务分层模型、项目内容功能依赖模型、项目输入输出数据流等相关的设计图和文档。
3、项目立项
项目立项一般是通过会议进行,对所有参与重构的部门或小组进行重构工作的宣讲,周知大概的时间计划表(这个时间计划表只是一个粗略的大致的时间),明确各组主要负责的人。另外还需要周知重构涉及到哪些业务和场景、大概的重构方式、业务影响可能有哪些。难点及可能在哪些步骤出现瓶颈。
事中
事中执行这一步骤的事情和任务相对来说比较繁重一些,时间付出会相对来说比较多。
1、架构设计与评审
架构设计评审主要是对标准的业务架构、技术架构、数据架构进行设计与评审。通过评审去发现架构和业务上的问题,这个评审一般是团队内评审,如果在一次评审后,发现架构设计并不能被确定,那就需要再调整,直到团队内对方案架构设计都达成一致,才可以进行下一步,评审结果也需要再评审通过后进行邮件周知参与人。该阶段产出物:重构后的服务部署、系统架构、业务架构、标准数据流、服务分层模式、功能模块UML图等。
2、详细落地设计方案与评审
这个落地的设计方案是事中执行最重要的一个方案,关系到后面的研发编码、自测与联调、依赖方对接、QA测试、线下发布与实施预案、线上发布与实施预案,具体的工作量、工作难度、工作瓶颈等。这个详细落地方案需要深入到整个研发、线下测试、上线过程、灰度场景细节处包括AB灰度程序、AB验证程序。
在方案设计中最重要一环是AB验证程序和AB验证开关,这是评估和检验我们是否重构完成的标准依据。一般的AB验证程序大致如下:
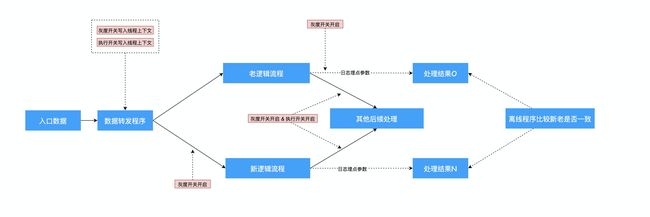
在数据的入口处,使用相同的数据,分别向新老流程都发起处理请求。在处理结束之后,将处理结果分别打印到日志中。最后通过离线程序比较新老流程处理的结果是否一致。我们遵循的原则就是在相同入参的情况下,响应的结果也应该一致。
在整个AB程序中,会涉及到两个开关。灰度开关(只有这个开关开启了,请求才会被发送到新的流程中进行代码执行),执行开关(如果新流程中涉及到写操作,这里需要用开关控制在新流程写还是在老流程中写)。转发之前需要将灰度开关和执行开关(开关一般都配置到配置中心,能随时调整)写入到线程上下文中。以免出现在修改配置中心开关时,多处获取开关结果不一致。
3、代码的编写、测试、线下实施
这一步就是按照详细设计的方案,进行编码、单测、联调测试、功能测试、业务测试、QA测试。通过后,在线下模拟上线流程和线上开关实施过程,校验AB程序,检查是否符合预期,新流程代码覆盖度是否达到上线要求,如果由于线下数据样本比较少,不能覆盖全部场景,需要通过构造流量覆盖所有的场景,保证所有的场景都能符合预期。当线下覆盖度达到预期,并且AB验证程序没有校验出任何异常时,才能执行上线操作。
事后
这个阶段需要在线上按照线下模拟的实施流程进行线上实施,这个阶段分为上线、放量、修复、下线老逻辑、复盘这样几个阶段。其中最重要最耗费精力的就是放量流程了。
1、灰度开关流程
逐步放量到新的流程中进行观察,可以按照1%、5%、10%、20%、40%、80%、100%的进度进行放量,让新流程逐步的进行代码逻辑覆盖,注意这个阶段不会打开真实执行写操作的开关。当新流程逻辑覆盖度达到要求后、并且AB验证的结果都符合预期后,才可以逐步打开执行写操作开关,进行真实业务的执行操作。
2、业务执行开关流程
在灰度新流程的过程中符合预期后,可以逐步打开业务执行写操作开关流程,仍然可以按照一定的比例进行逐步放量,打开写操作后,只有新逻辑执行写操作,老逻辑将关闭写操作。这个阶段需要观察线上错误、指标异常、用户反馈等问题,确保我们的新流程没有任何问题。
当放量工作结束后,在稳定一定版本后,就可以将老逻辑和AB验证程序进行下线,重构工作结束。如果有条件可以开一个重构复盘会,检查每个参与方是否都达到了重构要求的标准,复盘重构期间遇到的问题、以及这些问题的解决方案是什么样的,沉淀方法论避免后续的工作出现类似的问题。
总结
代码技巧
- 写代码的时候遵循一些基本原则,比如单一原则、依赖接口/抽象而不是依赖具体实现。
- 严格遵循编码规范、特殊注释使用 TODO、FIXME、XXX 进行注释。
- 单元测试、功能测试、接口测试、集成测试是写代码必不可少的工具。
- 我们是代码的作者、后人是代码的读者。写代码要时刻审视,做前人栽树后人乘凉、不做前人挖坑后人陪葬的事情。
- 不做破窗效应的第一人,不要觉得现在代码已经很烂了,觉得没有必要再改,直接继续堆代码,如果是这样,总有一天自己会被别人的代码恶心到,“出来混迟早是要还的”。
重构技巧
- 从上至下,由外到内进行建模分析、理清各种关系,是我们重构的重中之重。
- 提炼类,复用函数、下沉核心能力,让模块职责清晰明了。
- 依赖接口优于依赖抽象、依赖抽象优于依赖实现,类关系能用组合就不要继承。
- 类、接口、抽象接口设计时考虑范围限定符,哪些可以重写、哪些不能重写,泛型限定是否准确。
- 大型重构做好各种设计和计划、线下模拟好各种场景,上线一定需要AB验证程序,能够随时进行新老切换。