MiniGPT-4(大型语言模型增强视觉语言理解)介绍、体验、部署教程
NO.1简介
MiniGPT-4使用先进的大型语言模型增强视觉语言理解,将语言能力与图像能力结合。

其利用视觉编码器BLIP-2和大语言模型Vicuna进行结合训练,共同提供了新兴视觉语言能力。
MiniGPT-4github:
https://github.com/Vision-CAIR/MiniGPT-4
工作原理翻译:
- MiniGPT-4使用一个投影层来将来自BLIP-2的冻结视觉编码器与冻结的LLMVicuna对齐。
- 我们通过两个阶段来训练MiniGPT-4。第一个传统的预训练阶段在使用4个A100大约10小时内,使用大约500万个图像-文本对进行训练。第一阶段过后,Vicuna能够理解图像。但是其生成能力受到了严重的影响。
- 为了解决这个问题和提高可用性,我们提出了一种通过模型和ChatGPT自身创建高质量图像-文本对的新方法。基于此,我们创建了一个小型(总共3500对)但是高质量的数据集。
- 第二个微调阶段在对话模板上使用该数据集进行训练,以显著提高其生成可靠性和整体可用性。令人惊讶的是,这个阶段具有计算效率,并且只需要使用单个A100大约7分钟的时间。
- MiniGPT-4能够产生许多类似于GPT-4中展示的新兴视觉语言能力
NO.2DOMO使用
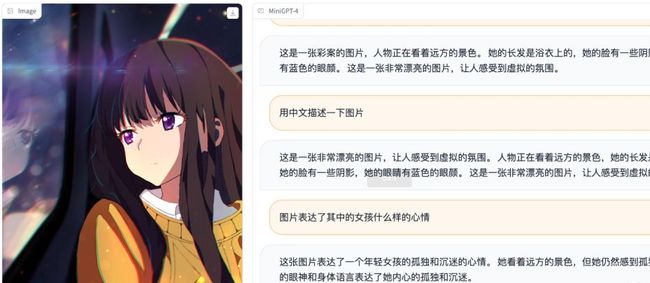
MiniGPT-4是国人开发的会中文的,只不过说法有点冷酷,不像ChatGPT那样符合人性化。

这个demo比较笨,需要先上传图片,才能进行对话,不易用,估计需要利用api来进行二次开发。
无法提取图片中的文字

没法识别文字应该

大体的图片内容是能理解,但是语言组织方面较欠缺
NO.3部署要求
安装步骤
MiniGPT4根据不同的模型选择需要不同的配置
目前解到:
Vicuna7B:
-VRAM>12GB
-RAM>16GB
-Disk>2500GB
Vicuna13B:
-VRAM>24GB
-RAM>16GB
-Disk>2500GB
在部署时转换权重时,预计需要80G的内存
在训练数据时,会下载2.3T的图片数据作为训练。
本次部署采用13B的语言模型进行部署
注:以下文件都放在/data下面,部分文件特别大,注意不要放到系统盘上
1.安装conda
wget-chttps://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.shbashMiniconda3-latest-Linux-x86_64.sh
#之后一直回车看license到最后让你同意license,
输入yes#输入安装位置/data/conda#添加官方镜像地址
condaconfig--addchannelsbiocondacondaconfig--addchannelsconda-forge
2.准备代码和安装环境
gitclone https://github.com/Vision-CAIR/MiniGPT-4.gitcdMiniGPT-4condaenvcreate-fenvironment.ymlcondaactivateminigpt4
#若后续操作中退出了bash界面
需要下次登录时再次执行来设置环境condaactivateminigpt4
3.获取原始权重
这步是最费劲的,权重非常大,下载很慢,而且第一次我还下错了,原始权重下了我两个晚上,头都大了。
第一次我去https://github.com/facebookresearch/llama/issues/149上查看到了一个原始权重,结果下载了一天,下来的文件不正确md5都对不上,跑权重转换的时候报文件错误,所以不要用这个下载(提示给自己找权重的朋友)
7B:ipfs://QmbvdJ7KgvZiyaqHw5QtQxRtUd7pCAdkWWbzuvyKusLGTw 13B:ipfs://QmPCfCEERStStjg4kfj3cmCUu1TP7pVQbxdFMwnhpuJtxk
第二次重新采用了迅雷种子的下载,这次下载下来md5和checklist里是对的。
种子地址:
https://github.com/RiseInRose/MiniGPT-4-ZH/blob/main/CDEE3052D85C697B84F4C1192F43A2276C0DAEA0.torrent
从迅雷里面下载13B的模型即可,文件夹结构如下,注意下面的文件都需要下载,最终文件夹大小25G
4.下载增量权重
下载前需先安装git-lfs,去官网下载就行https://git-lfs.com
下载安装完后执行
gitlfsinstall mkdir/data/vicuna cd/data/vicuna #建议后台运行,里面文件太大了刚开始我下了一整天一共差不多49个G,挂在bash上,如果断网了就很难受了 nohupgitclonehttps://huggingface.co/lmsys/vicuna-13b-delta-v1.1&
5.安装fastchat
gitclonehttps://github.com/lm-sys/FastChat cdFastChat gitcheckoutv0.2.3 #安装 pipinstalle. pipinstalltransformers[sentencepiece]
6.转换原始权重
下载下来的原始权重需要转换一下(注意:gitclone下来的增量权重不需要转换,只要转换原始的就行)
#存放转换后的权重 mkdir-p/data/after_conv_weights/origin mkdir/data/transformers cd/data/transformers gitclonehttps://github.com/huggingface/transformers cdtransformers #转换权重注意文件夹目录写对,input_dir只要指定到tokenizer.model平级就行 pythonsrc/transformers/models/llama/convert_llama_weights_to_hf.py--input_dir/data/LLaMa--model_size13B--output_dir/data/after_conv_weights/origin 出现: RuntimeError:Failedtoimporttransformers.models.llama.tokenization_llama_fastbecauseofthefollowing error(lookuptoseeitstraceback): tokenizers>=0.13.3isrequiredforanormalfunctioningofthismodule,butfoundtokenizers==0.13.2.
运行
pipinstall-Utokenizers
再重新执行上述脚本
完成之后直接python运行下面代码加载模型与分词器
python fromtransformersimportLlamaForCausalLM,LlamaTokenizer tokenizer=LlamaTokenizer.from_pretrained("/data/after_conv_weights/origin") model=LlamaForCausalLM.from_pretrained("/data/after_conv_weights/origin")
7.转换最终的工作权重
此处预计要80G左右的内存
mkdir-p/data/after_conv_weights/final python-mfastchat.model.apply_delta--base/data/after_conv_weights/origin/--target/data/after_conv_weights/final/--delta/data/vicuna/vicuna-13b-delta-v1.1/
最终转换出来的权重文件夹

转换之后,修改配置文件
/data/MiniGPT-4/minigpt4/configs/models/minigpt4.yaml llama_model:"/data/after_conv_weights/final/"
8.下载预训练的模型检查点
https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view
下载之后是一个pretrained_minigpt4.pth文件
放入/data/checkpoint文件夹
在/data/MiniGPT-4/eval_configs/minigpt4_eval.yaml文件中,修改ckpt指定到/data/checkpoint/pretrained_minigpt4.pth中

到这里,基础的准备工作做完了。
9.尝试启动
cd/data/MiniGPT-4pythondemo.py--cfg-patheval_configs/minigpt4_eval.yaml--gpu-id0
运行之后一般会失败
会出现如下错误
问题1:
Import Error:libX11.so.6:cannotopensharedobjectfile:Nosuchfileordirectory
解决办法:
yum installlibX11
问题2:
ImportError:libXext.so.6:cannotopensharedobjectfile:Nosuchfileordirectory
解决办法:
yum installlibXext
问题3:
RuntimeError:TheNVIDIAdriveronyoursystemistooold(foundversion10020).PleaseupdateyourGPUdriverbydownloadingandinstallinganewversionfromtheURL:http://www.nvidia.com/Download/index.aspxAlternatively,goto:https://pytorch.orgtoinstallaPyTorchversionthathasbeencompiledwithyourversionoftheCUDAdriver.
NVIDIA版本太老了,需要更新NVIDIA版本
10.更新NVIDIA版本
nvidia-smi查看当前版本,如果没找到则没有nvidia驱动
目前测试在NVIDIA-SMI515.105.01、CUDAVersion:11.7之上可以运行
在https://www.nvidia.cn/Download/index.aspx?lang=cn上下载对应机型的NVIDIA驱动,根据显卡不同,驱动也不同。
这里我是V100S的驱动

下载后先不着急安装
先安装gcc和dkms
yum-yinstallgccdkms
查看内核版本
uname-r yumlist|grepkernel-devel yumlist|grepkernel-header 这三个版本需要对应上,连一个小版本号都不要差。 我的版本号是 (minigpt4)[root@10-13-50-112cc_sbu]#uname-r 3.10.0-1062.9.1.el7.x86_64 最开始另外两个对应不上,需要更新 从https://buildlogs.centos.org/c7.1908.u.x86_64/kernel/20191206154625/3.10.0-1062.9.1.el7.x86_64/ 下载下面两个rpm包,进行更新 kernel-devel-3.10.0-1062.9.1.el7.x86_64.rpm kernel-headers-3.10.0-1062.9.1.el7.x86_64.rpm
卸载过去已经安装的NVIDIA(如果没安装则忽略)
cd/usr/bin/ ./nvidia-uninstall
安装NVIDIA驱动
cd/data/navida/ chmoda+xNVIDIA-Linux-x86_64-515.105.01.run ./NVIDIA-Linux-x86_64-515.105.01.run 之后按引导点yes就行了(操作就是左右方向键、回车) 如果报xxx/build和xxx/source没找到,则就是内核工具不对,需要重新安装内核
安装完之后,通过nvidia-smi命令查看版本
11.启动demo
还是上面的命令
cd/data/MiniGPT-4 pythondemo.py--cfg-patheval_configs/minigpt4_eval.yaml--gpu-id0
执行之后,又报一个错误
NameError:name'cuda_setup'isnotdefined
编辑
vim/data/conda/envs/minigpt4/lib/python3.9/site-packages/bitsandbytes/cuda_setup/main.py
在149行左右
添加
cuda_setup=CUDASetup.get_instance()
修改之后,再次执行,demo就启动了,启动之后会给出一个地址,可以通过这个地址来访问
https://3c70e646a6198e3ec7.gradio.live
12.两阶段训练
minigpt4在搭建完后还需要两阶段训练。
第一阶段训练直接提供了checkpoint,不需要在自己服务上进行训练
第二阶段训练需要自己进行训练
第一阶段预训练checkpoint:
https://drive.google.com/file/d/1u9FRRBB3VovP1HxCAlpD9Lw4t4P6-Yq8/view?usp=share_link
下载之后放在/data/checkpoint/目录下面
第二阶段微调:
下载数据
https://drive.google.com/file/d/1nJXhoEcy3KTExr17I7BXqY5Y9Lx_-n-9/view?usp=share_link,
放在/data/stage_2下面
并更改/data/MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml 将storage指向/data/stage_2/cc_sbu_align
进入/data/MiniGPT-4/train_configs目录下,
编辑minigpt4_stage2_finetune.yaml,将model.ckpt指向第一阶段预训练的checkout
即/data/checkpoint/pretrained_minigpt4_stage1.pth run.output_dir 设置成/data/checkpoint/
同时修改run下面的三个参数(如果用A100的话就保持原样,由于是V100GPU显存不足,需要将训练改小):
batch_size_train:1 batch_size_eval:2 num_workers:2
之后回到/data/MiniGPT-4目录下执行
torchrun--nproc-per-node1train.py--cfg-pathtrain_configs/minigpt4_stage2_finetune.yaml
训练完后,会生成/data/checkpoint/20230517153目录,里面有checkpoint_1.pth-checkpoint_4.pth四个文件
最后将
/data/MiniGPT-4/eval_configs中的ckpt 指向 /data/checkpoint/20230517153/checkpoint_4.pth
再重新运行
cd/data/MiniGPT-4 condaactivateminigpt4 pythondemo.py--cfg-patheval_configs/minigpt4_eval.yaml--gpu-id0