Ceph集群搭建篇
环境准备
ceph官方文档:https://docs.ceph.com/en/latest/
本次搭建用到的测试机器,规划如下:
| 主机名 | IP | 数据盘 |
|---|---|---|
| ceph-node01 | 192.168.11.13 | 5块1TB容量硬盘 |
| ceph-node02 | 192.168.11.14 | 5块1TB容量硬盘 |
| ceph-node03 | 192.168.11.15 | 5块1TB容量硬盘 |
解下来在所有节点完成下面的准备工作
- 关闭防火墙、selinux、禁用swap
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
在部署 Ceph 集群时,建议将所有节点的交换分区(swap)禁用或调整到最小值。这是因为 Ceph 对于节点内存的需求较高,如果系统中开启了 swap 分区,那么当内存不足时,系统会将一些内存数据转储到 swap 中,这会导致性能下降和系统不稳定。因此,禁用或调整 swap 分区大小可以确保系统有足够的内存来支持 Ceph 的正常运行和性能。
- 配置阿里云yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum makecache
- 安装epel
yum install epel-release -y
- 安装docker
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo && yum -y install docker-ce && systemctl enable docker && systemctl start docker
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
systemctl restart docker
- 安装lvm2、python3、ntp
yum install lvm2 python3 ntpdate -y && ntpdate ntp1.aliyun.com
部署ceph集群
- 在每个节点安装Cephadm和ceph工具包
#
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
chmod +x cephadm
mv cephadm /usr/local/bin/
# 查看版本的同时会下载镜像quay.io/ceph/ceph:v15,建议在这一步提前下载好,等会部署ceph集群和加入osd的时候,都要用到这个镜像
# 在一台下载后可以导出分发到其他节点进行导入,省心省力。
[root@ceph-node01 yum.repos.d]# cephadm version
ceph version 15.2.17 (8a82819d84cf884bd39c17e3236e0632ac146dc4) octopus (stable) # 注意这个版本号octopus
[root@ceph-node01 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v15 93146564743f 7 months ago 1.2GB
# 安装对应版本号的相关软件包
cephadm add-repo --release octopus && cephadm install ceph-common
- 在第一个节点(ceph-node01)上,初始化Ceph集群和创建OSD
cephadm bootstrap --mon-ip 192.168.11.13
# 成功后的输出:
Ceph Dashboard is now available at:
URL: https://ceph-node01:8443/
User: admin
Password: 71w76yawgu
You can access the Ceph CLI with:
sudo /usr/local/bin/cephadm shell --fsid 09588bf8-ce9d-11ed-b54e-0050563ecf1e -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
在创建完成后,您将看到输出中显示的管理员账号和密码,可以使用浏览器登录到web管理页面。
查看集群状态:
[root@ceph-node01 ~]# ceph -s
cluster:
id: cf322aa0-ce9d-11ed-a072-0050563ecf1e
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-node01 (age 16m)
mgr: ceph-node01.qzkggl(active, since 15m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
可以看到ceph集群已经有一个节点ceph-node01,它担任了mon、mgr的角色,在我的规划中,也是要让ceph-node01节点作为osd角色的,它的osd数量目前为0,接下来我们在ceph-node01上创建osd
# 查看存储设备列表,它有5块盘
[root@ceph-node01 ~]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
ceph-node01 /dev/sdb hdd 1073G Unknown N/A N/A Yes
ceph-node01 /dev/sdc hdd 1073G Unknown N/A N/A Yes
ceph-node01 /dev/sdd hdd 1073G Unknown N/A N/A Yes
ceph-node01 /dev/sde hdd 1073G Unknown N/A N/A Yes
ceph-node01 /dev/sdf hdd 1073G Unknown N/A N/A Yes
# sda是系统盘,sdb-sdf计划用来做osd盘,通过查看目前的状态可以知道,这5块盘还没有交由ceph管理
[root@ceph-node01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
├─sda1 8:1 0 2G 0 part /boot
└─sda2 8:2 0 498G 0 part
├─centos-root 253:0 0 122G 0 lvm /
├─centos-swap 253:1 0 16G 0 lvm
├─centos-usr 253:2 0 60G 0 lvm /usr
├─centos-var 253:3 0 250G 0 lvm /var
├─centos-tmp 253:4 0 30G 0 lvm /tmp
└─centos-home 253:5 0 20G 0 lvm /home
sdb 8:16 0 1000G 0 disk
sdc 8:32 0 1000G 0 disk
sdd 8:48 0 1000G 0 disk
sde 8:64 0 1000G 0 disk
sdf 8:80 0 1000G 0 disk
# 接下来我们创建新的OSD,直接告诉Ceph使用任何可用和未使用的存储设备
ceph orch apply osd --all-available-devices
# 接着查看,sdb-sdf磁盘已经交由ceph管理,并作为osd盘,
[root@ceph-node01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
├─sda1 8:1 0 2G 0 part /boot
└─sda2 8:2 0 498G 0 part
├─centos-root 253:0 0 122G 0 lvm /
├─centos-swap 253:1 0 16G 0 lvm
├─centos-usr 253:2 0 60G 0 lvm /usr
├─centos-var 253:3 0 250G 0 lvm /var
├─centos-tmp 253:4 0 30G 0 lvm /tmp
└─centos-home 253:5 0 20G 0 lvm /home
sdb 8:16 0 1000G 0 disk
└─ceph--e445c08f--1564--443c--9f7c--de2772686c56-osd--block--91538bd9--a63e--4d2a--9283--8bc66f01726f 253:6 0 1000G 0 lvm
sdc 8:32 0 1000G 0 disk
└─ceph--660d76c7--6f90--422e--baa2--ce8441bd8812-osd--block--1820432c--3ee3--4fb6--9c7f--682160c3b13b 253:7 0 1000G 0 lvm
sdd 8:48 0 1000G 0 disk
└─ceph--0c0eaf4c--2b6f--45d9--a8a3--a6cac35b285d-osd--block--1f060c14--2dd7--4fdd--839f--9402616bf9fb 253:8 0 1000G 0 lvm
sde 8:64 0 1000G 0 disk
└─ceph--60fceaeb--a0c7--45e5--babe--bd714884fbea-osd--block--7eb9b03a--ea87--4ab3--97f4--2c1dcf802930 253:9 0 1000G 0 lvm
sdf 8:80 0 1000G 0 disk
└─ceph--8beea209--9020--4c91--b4a4--38b862de7cc0-osd--block--b224910e--7894--470b--8617--0b28c6a1add8 253:10 0 1000G 0 lvm
# 查看集群中的osd状态
[root@ceph-node01 ~]# ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 ceph-node01 1026M 998G 0 0 0 0 exists,up
1 ceph-node01 1026M 998G 0 0 0 0 exists,up
2 ceph-node01 1026M 998G 0 0 0 0 exists,up
3 ceph-node01 1026M 998G 0 0 0 0 exists,up
4 ceph-node01 1026M 998G 0 0 0 0 exists,up
- 将另外2个节点添加到集群和创建OSD(在ceph-node01节点上操作)
# 下发ceph集群的公钥和添加节点
ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected]
ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected]
ceph orch host add ceph-node02 192.168.11.14
ceph orch host add ceph-node03 192.168.11.15
ceph-node02和ceph-node03加入ceph集群后,会自动将任何可用和未使用的存储设备作为osd盘
当然也可以手动指定从特定主机上的特定设备创建OSD,命令如下:
ceph orch daemon add osd 192.168.11.14:/dev/sdb,/dev/sdc,/dev/sdd,/dev/sde,/dev/sdf
ceph orch daemon add osd 192.168.11.15:/dev/sdb,/dev/sdc,/dev/sdd,/dev/sde,/dev/sdf
至此,ceph集群已经搭建完成。
- 完成后,查看集群状态、osd状态、集群使用情况
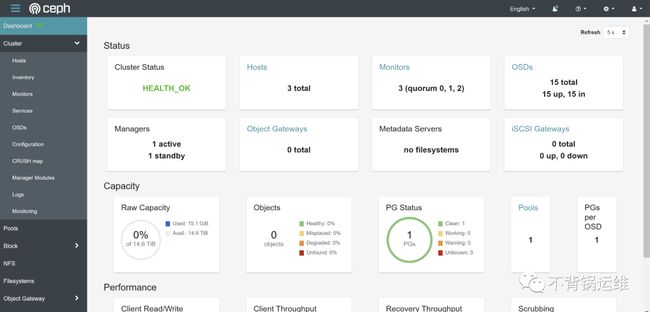
[root@ceph-node01 ~]# ceph -s
cluster:
id: cf322aa0-ce9d-11ed-a072-0050563ecf1e
health: HEALTH_OK
services:
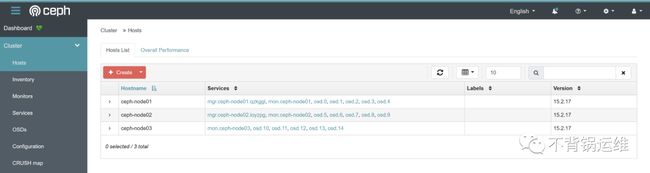
mon: 3 daemons, quorum ceph-node01,ceph-node03,ceph-node02 (age 7m)
mgr: ceph-node01.qzkggl(active, since 34m), standbys: ceph-node02.ioyzpg
osd: 15 osds: 15 up (since 6m), 15 in (since 6m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 15 GiB used, 15 TiB / 15 TiB avail
pgs: 1 active+clean
[root@ceph-node01 ~]# ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 ceph-node01 1030M 998G 0 0 0 0 exists,up
1 ceph-node01 1030M 998G 0 0 0 0 exists,up
2 ceph-node01 1030M 998G 0 0 0 0 exists,up
3 ceph-node01 1030M 998G 0 0 0 0 exists,up
4 ceph-node01 1030M 998G 0 0 0 0 exists,up
5 ceph-node02 1030M 998G 0 0 0 0 exists,up
6 ceph-node02 1030M 998G 0 0 0 0 exists,up
7 ceph-node02 1030M 998G 0 0 0 0 exists,up
8 ceph-node02 1030M 998G 0 0 0 0 exists,up
9 ceph-node02 1030M 998G 0 0 0 0 exists,up
10 ceph-node03 1030M 998G 0 0 0 0 exists,up
11 ceph-node03 1030M 998G 0 0 0 0 exists,up
12 ceph-node03 1030M 998G 0 0 0 0 exists,up
13 ceph-node03 1030M 998G 0 0 0 0 exists,up
14 ceph-node03 1030M 998G 0 0 0 0 exists,up
[root@ceph-node01 ~]#
[root@ceph-node01 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 15 TiB 15 TiB 104 MiB 15 GiB 0.10
TOTAL 15 TiB 15 TiB 104 MiB 15 GiB 0.10
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 4.6 TiB
[root@ceph-node01 ~]#
登录ceph web管理页面看看:
写在最后
- 关于时间同步 在 Ceph 集群中,每台节点的时间同步非常重要,因为 Ceph 集群的各个组件都需要严格的时间同步才能正常运行。以下是一些重要原因:
- 避免数据不一致:Ceph 集群中的数据副本分布在不同的节点上,如果节点之间的时间不同步,可能会导致写操作的数据不一致,或者无法正确地读取数据。
- 避免时钟漂移:由于硬件和软件的原因,每个节点的时钟可能会出现漂移。如果这种漂移超过了一定的阈值,可能会导致 Ceph 系统无法正常工作。
- 避免锁竞争问题:Ceph 集群中的许多组件都使用锁来控制访问资源的顺序。如果节点之间的时间差异太大,可能会导致锁竞争问题,从而影响系统的性能。
因此,确保每台节点的时间同步是 Ceph 集群稳定性和可靠性的重要保证。可以通过使用 NTP(网络时间协议)或其他时间同步工具来实现时间同步。在本次搭建中,同步的是公网阿里云的时间服务器。需要注意的是,如果在生产环境,还要配置定期能够自动同步,本次只是测试,所以就不配置了,如果是生产环境且不能出外网的机器,还要确保本地有NTP服务器。
- 关于mon节点的数量
一个典型的 Ceph 集群官方建议部署3个或5个监控守护进程(MON),分布在不同的主机上。因为 MON 负责维护 Ceph 集群的状态信息,包括存储池和 OSD 的映射关系、客户端的连接信息等,它们需要进行定期的状态信息交换和协调。如果某个 MON 发生故障,那么其他的 MON 可以协同工作来维护集群的状态信息。一般来说,部署更多的 MON 可以提高集群的可靠性和容错性,因为它们可以更好地协同工作来维护集群的状态信息。同时,部署更多的 MON 还可以提高集群的性能,因为它们可以更好地分担状态信息交换的负载。
建议在 Ceph 集群中至少部署五个或更多的 MON,以提高集群的可靠性、容错性和性能。
本文转载于WX公众号:不背锅运维(喜欢的盆友关注我们):https://mp.weixin.qq.com/s/YzuaRf2ZABFIU7Wkyro4vw