推荐系统(八)分类 TAB 商品流多目标精排模型的演进
1. 概述
分类 TAB 商品流是得物 App 购买页面内除“推荐”页外的所有 TAB 内的商品推荐流,如“鞋类”、“箱包”等。当用户进入分类 TAB 中,我们可以简化为给定
2. 模型
2.1 Base ESMM
从多目标学习范式上,我们选择 ESMM 模型的范式作为我们的精排模型,关于 ESMM 的介绍在这里我们不做过多阐述,详情参考论文——《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》。从论文中,我们可知 ESMM 的架构如下:
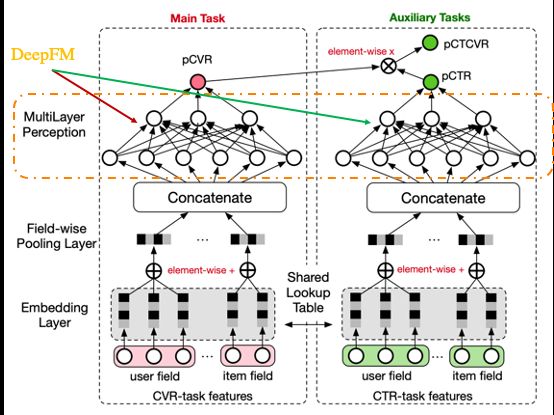
业务上的 baseline 模型,是将上图中的 MLP layer 替换为 DeepFM 模型的结构,加入 FM 结构学习交叉信息。但从整体上该模型仍然较为浅层,没有对用户的信息表征做更多的抽取,为此我们将模型结构进行了升级。
2.2 模型整体结构
我们现阶段的建模是
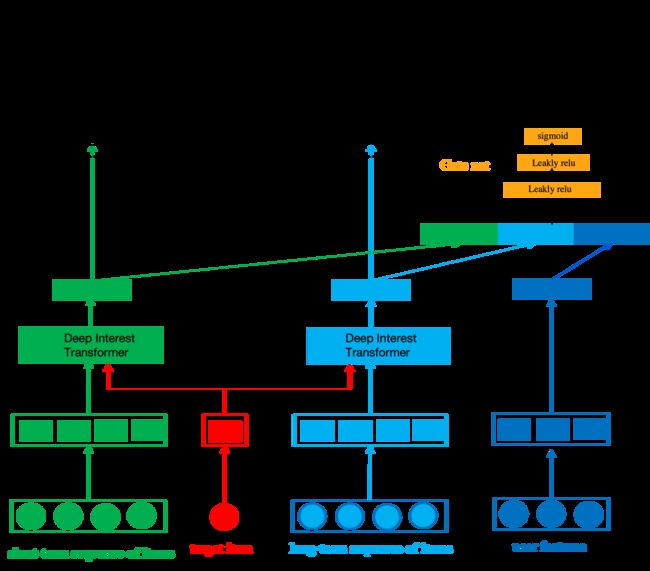
从模型的整体结构上,我们不改变 ESMM 的学习范式,我们只对生成 ctr logits、cvr logits 的结构做改进,整体模型结构如图:

其中 Deep Interest Transformer 结构如下图:
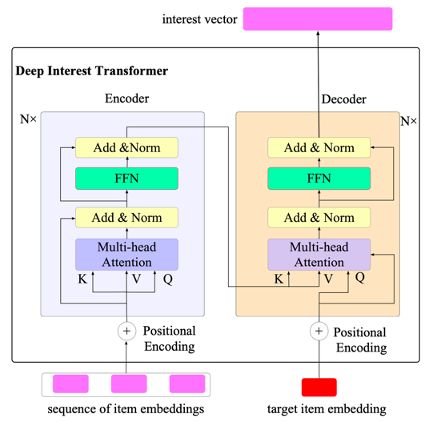
从整体上看,我们可以看出,对于 ctr 任务和 cvr 任务,每个任务都有各自的 main net 和 bias net;用户兴趣建模模块学习出的用户向量被两个任务所共享,即 interest transformer 作为一个信息抽取模块,抽取的信息与其他诸如 cross features 的表征进行 concat,共同作为底层的共享信息。
2.2.1 用户行为序列建模
我们认为用户的行为与其下一个点击的商品具有相关性,或是相同类目、品牌或系列等重要属性。为了拆解和分析用户行为序列与推荐商品的相关性对推荐效率的影响,我们以商品的三级类目为分析维度,如下:
我们以 tab 商品流线上用户的行为日志进行分析,绘出 target item 的三级类目与用户行为序列商品的三级类目的关系对推荐效率的影响,如下图:
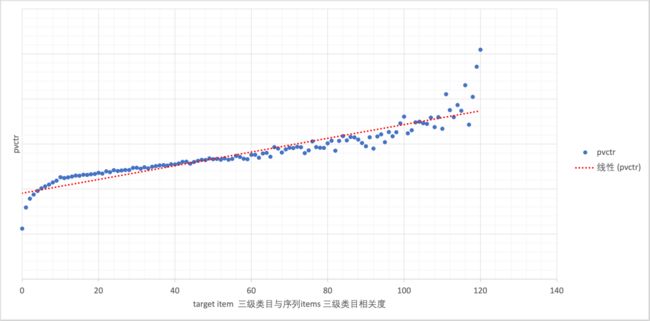
横坐标是描述推荐商品的类目与用户行为序列的商品的类目,其序列中相同三级类目的行为商品数量;纵坐标则是 pvctr;从整体趋势上来看,target item 的类目与用户行为序列中的商品类目越相关,pvctr 越高。
当然,从直觉上,点击序列越长(用户活跃度越高)是否点击率就越高,为此我们分析了序列长度与 pvctr 的关系,如下图:
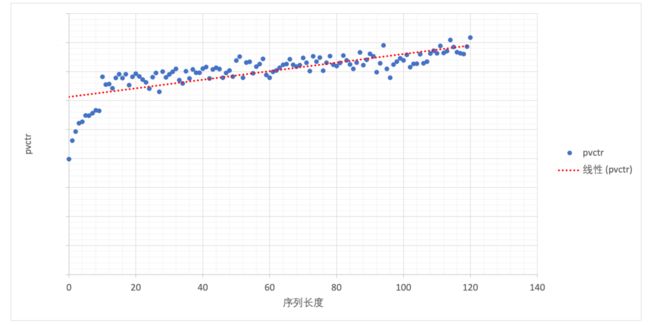
显然,用户活跃度的偏差也影响了 pvctr,但通过对比,可以明显看出,用户活跃度对 pvctr 的影响,其趋势是小的(斜率);而推荐商品的类目与用户行为序列中的商品类目相关性的趋势是相对明显的。
而如何去建模打分商品与用户行为序列的相关性,attention 显然是一种可靠的方法,self-attention 可以建模用户行为序列中的各个商品之间的相关性,而 target-attention 则是建模候选商品与用户行为序列的相关性的方法。
模型中的 Deep Interest Transformer 是学习用户表征的结构,我们选取用户的行为序列:实时购买、点击立即购买、收藏、点击商品行为,7 天内的购买、点击立即购买、收藏、点击商品行为,融合出一个长达 120 长度的用户行为序列,超出长度部分做截断,不足的长度进行默认填充。
Deep Interest Transformer 首先对用户的行为序列进行 multi-head self-attention,以此学习序列中各个元素间的相关性,此为对用户序列进行 encode;对于待打分商品,我们称其为 target item,我们进行 decode 时,是将 target item 的 embedding 表示作为 attention 中的 Q,而用户序列的 encode 表示的向量作为 attention 中的 K、V,此为 target-attention,即对于不同的打分 item,计算该 item 与用户行为序列中的元素的相关性,因此对于不同的 target item,其所激活的用户行为序列的元素有所不同,从而生成不同的用户兴趣向量,最终将有效的区分不同 target item 的打分。
2.2.2 bias 网络
推荐系统中存在各种各样的 bias,对于 tab 商品流,我们从几个维度来分析用户本身的 bias,如用户的性别、使用设备、注册地。
对比图省略,图意为——不同的用户群体存在着不同的偏差,如男性用户对酒饮、手表类目点击率较高而女性用户则在美妆和女装类目点击率较高;Android 用户对数码类目点击率较高而 iOS 用户低;我们选择国内东南西北四个具有代表性的地区(上海、广东、四川、北京)进行分析,发现诸如酒饮、潮玩、配饰等类目,具有明显的地域偏差。
为显式地建模这种 bias,我们为每个任务增加了一个 bias net,每个任务单独增加了一个网络进行建模,其输出的 logits 与主网络进行相加。bias net 在此阶段中,我们只用了用户的特征作为 bias net 的输入。这个单独的网络是用于建模用户自身的 bias,比如有些用户偏向于逛逛但不点击,有些用户却又具有较高的点击率,即活跃度的差异等等。在这种情况下,使用一个单独的 bias net 去建模这种用户自身与推荐结果无关的 bias,是一种相对于单纯增加 bias 特征在主网络中学习而言更有效的方法。
更一般的来讲,bias net 不仅仅局限于仅用 user embedding 进行输入。推荐系统有许多 bias,这些 bias 如果单纯的作为特征用以主网络输入,效果将不如单独用一个 bias net 来学习这些偏差。bias net 不仅可以建模用户对于 position 的点击偏差, 还可以建模用户对于时间特征的偏差,可以更一般的将用户向量和各种偏差特征的表示进行 concat,而后输入 bias net 进行学习。
综上,以上的模型改动是我们在分类 TAB 商品流中的第二版多目标模型,已进行长时间实验,获得不错的线上收益并已推全。
3. 用户长期行为序列建模
3.1 长期兴趣
从以上版本的迭代中,我们所使用的用户行为局限于用户的实时画像中的商品序列以及用户离线 7 天内的商品序列,从序列样本分析来看,我们以 120 的长度作为序列最大长度,其中有效的商品序列长度,平均仅 61;有效的商品长度中位数仅 65。如下表:
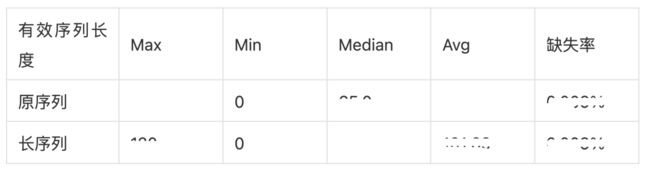
即大量的序列长度被无效的默认值所填充,在 attention 进行 mask 后,这大大的削弱了用户的兴趣表达。因此,有效扩充用户的有效行为长度,将能够更加丰富用户的行为特征,这对一些不活跃用户使其能够根据长期行为进行推荐。实际上尽管是行为十分丰富的用户,其长期购买、收藏等行为,对当前的推荐也是有益的。
在以上的分析中我们以三级类目为分析桥梁得出用户行为序列与候选商品的相关性对 pvctr 的趋势性影响;对于用户长期的序列,是否同样有这种趋势,为此我们将用户长期序列剔除 7 天以内的序列后进行分析,如下图:
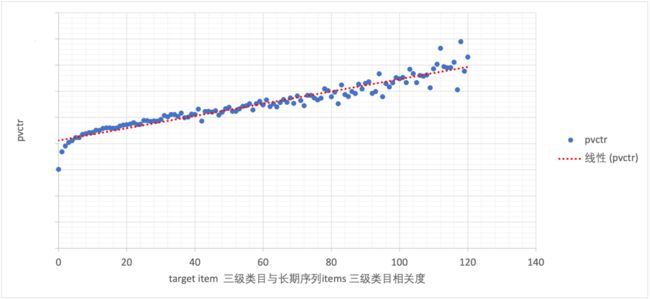
可以看出,推荐的商品类目与用户长期行为过的类目仍然存在相关性;用户的长期序列商品中的类目与候选商品类目越相关,候选商品 pvctr 越高。
因此直观的做法是我们引入了用户的长期行为,而不考虑用户行为的时间跨度。我们从用户最近行为的 160 个商品中,按照去重的方式填充到我们之前构造的序列中,并按照时间先后截断最近的 120 个行为。从上表可以看出,填充长序列后,用户的有效序列行为长度,中位数达 120,平均数达 101。这大大丰富了用户的特征表达。
从离线评估指标看,ctr auc:+0.3%,cvr auc:+0.1%。
3.2 长短期兴趣建模
在以上的版本中,我们的建模方式都是将用户的所有行为融合为一个大的序列,以此生成用户兴趣向量。实际上,用户的不同行为时间跨度所反应的兴趣有所不同,我们希望在模型中建模用户不同时间跨度的行为来描述用户不同粒度的兴趣。
而且从点击的商品进行分析,用户短期的行为中的类目与点击的商品类目相关性更高,而长期行为的类目的相关性更低。如下图:
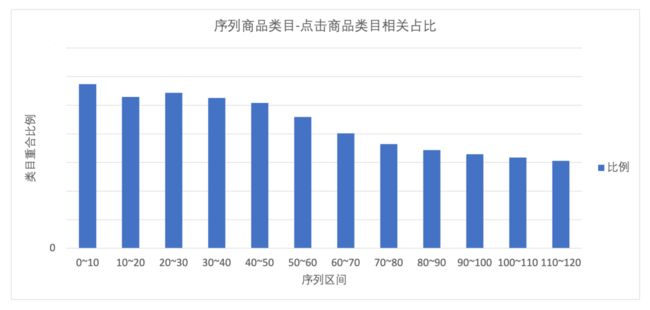
明显的,用户点击的商品与最近行为的 10 个商品的类目重合度是最高的,而与曾经行为过的第 50 个之后的商品,类目相关性逐渐明显降低。
为了考虑这种短期和长期行为序列对候选商品的影响,对此我们将用户的行为划分为短周期行为、长周期行为,在用户兴趣建模中考虑长短兴趣,长短期序列我们目前是通过实时画像、离线画像进行划分。实验上我们尝试了以下两种方法进行建模。
3.2.1 长短期兴趣分别建模
分别建模短期兴趣、长期兴趣用户向量,分别为 Sv 、Lv;然后将 [Sv,Lv] 进行 concat 得到用户兴趣向量 Uv ,由上层各自任务的网络进行学习;如图:

即 Uv = concat([Sv, Lv])
3.2.2 长短期兴趣通过 gate 网络进行融合
短期兴趣、长期兴趣用户向量,分别为 Sv 、Lv ,通过 gate 网络融合,如图:
即 Uv = aSv + (1-a)Lv
其中 gate net,输入是用户特征向量以及 attention 学习的用户长、短期兴趣向量,通过 MLP 网络以 sigmoid 函数进行激活,以此将短期向量、长期向量通过 fusion gate 进行融合,得到新的用户兴趣表达 Uv 。至于如何选择 gate 网络的特征,我们参考了 MMoE 的结构,同时我们认为能够对用户长短期兴趣进行区分的应当是用户本身的特征。
综上两种长短期兴趣建模方法,从离线评估指标看 auc:约 +0.1%,已结合上述的长期兴趣建模在分类 TAB 场景上线实验。两种建模方式对最终的效果基本相当。诚然,第一种方式,将长短期兴趣进行 concat 后交给上层任务自主学习,同时也增加了上层各个任务的 specific 网络参数。而第二种方式将取决于 gate 网络的学习。
4. 展望
如上所述,分类 TAB 的推荐场景,实际上属于
同时,item 与 TAB 本身的相关性也将是一个考量方向,TAB 从品类上看类似于搜索品类词,具有品类意图,item 与 TAB 具有强相关性和弱相关性区分,类似于搜索的类目相关性强弱相关性分档。我们认为与 TAB 强相关并且命中了用户兴趣的 item 将更有可能被点击转化。当然这有待于我们进一步分析。
5.引用
1-分类TAB商品流多目标排序模型的演进_算法_得物技术_InfoQ写作社区