spark sql读写hive的过程
Spark sql读写hive需要hive相关的配置,所以一般将hive-site.xml文件放到spark的conf目录下。代码调用都是简单的,关键是源码分析过程,spark是如何与hive交互的。
1. 代码调用
读取hive代码
SparkSession sparkSession = SparkSession.builder()
.appName("read_hive").enableHiveSupport().getOrCreate();
Dataset data = sparkSession.sql(sqlText); //select 语句即可 data就是读取的表数据集
写hive代码
SparkSession sparkSession = SparkSession.builder()
.appName("write_hive").enableHiveSupport().getOrCreate();
/*初始化要写入hive表的数据集
可以是读取文件 sparkSession.read().text/csv/parquet()
或者读取jdbc表sparkSession.read().format("jdbc").option(...).load()
*/
Dataset data = xxx;
data.createOrReplaceTempView("srcTable"); //创建临时表
sparkSession.sql("insert into tablex select c1,c2... from srcTable") //将临时表数据写入tablex表
注意如果是写parquet格式的表,要使hivesql也能访问,则需要在SparkSession上加个配置项 .config("spark.sql.parquet.writeLegacyFormat", true)。这样hivesql才能访问,不然会报错。
2. 源码相关的分析
spark sql与hive相关的源码就在以下目录:

对于spark sql的执行流程这里不再介绍,整体架构就是:
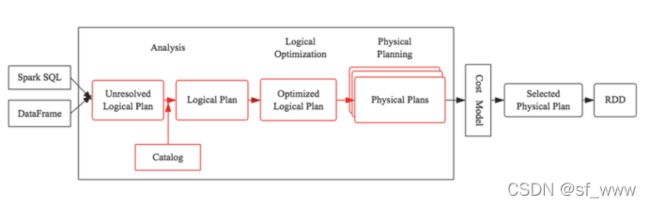
读写hive的关键操作就是enableHiveSupport()方法,在里面会首先检查是否已经加载了hive的类,然后设置配置项spark.sql.catalogImplementation值为hive。这样在Sparksession初始化SessionState对象时,根据配置获取到的就是hive相关的HiveSessionStateBuilder,然后调用build创建hive感知的SessionState。
/**
* Enables Hive support, including connectivity to a persistent Hive metastore, support for
* Hive serdes, and Hive user-defined functions.
*
* @since 2.0.0
*/
def enableHiveSupport(): Builder = synchronized {
if (hiveClassesArePresent) {
config(CATALOG_IMPLEMENTATION.key, "hive")
} else {
throw new IllegalArgumentException(
"Unable to instantiate SparkSession with Hive support because " +
"Hive classes are not found.")
}
}
/**
* State isolated across sessions, including SQL configurations, temporary tables, registered
* functions, and everything else that accepts a [[org.apache.spark.sql.internal.SQLConf]].
* If `parentSessionState` is not null, the `SessionState` will be a copy of the parent.
*
* This is internal to Spark and there is no guarantee on interface stability.
*
* @since 2.2.0
*/
@InterfaceStability.Unstable
@transient
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
val state = SparkSession.instantiateSessionState(
SparkSession.sessionStateClassName(sparkContext.conf),
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}
/**
* Helper method to create an instance of `SessionState` based on `className` from conf.
* The result is either `SessionState` or a Hive based `SessionState`.
*/
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = {
try {
// invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className)
val ctor = clazz.getConstructors.head
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build()
} catch {
case NonFatal(e) =>
throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}
private def sessionStateClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_SESSION_STATE_BUILDER_CLASS_NAME
case "in-memory" => classOf[SessionStateBuilder].getCanonicalName
}
}SessionState的创建通过BaseSessionStateBuilder.build()来创建
/**
* Build the [[SessionState]].
*/
def build(): SessionState = {
new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog,
sqlParser,
() => analyzer,
() => optimizer,
planner,
streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone)
}
}hive感知的SessionState是通过HiveSessionStateBuilder来创建的。HiveSessionStateBuilder继承BaseSessionStateBuilder,即相应的catalog/analyzer/planner等都会被HiveSessionStateBuilder重写的变量或方法代替。
下面将分析HiveSessionCatalog/Analyzer/SparkPlanner
HiveSessionCatalog
SessionCatalog只是一个代理类,只提供调用的接口,真正与底层系统交互的是ExternalCatalog。而在hive场景下,HiveSessionCatalog继承于SessionCatalog,HiveExternalCatalog继承于ExternalCatalog。
可以看以下类说明:
/**
* An internal catalog that is used by a Spark Session. This internal catalog serves as a
* proxy to the underlying metastore (e.g. Hive Metastore) and it also manages temporary
* views and functions of the Spark Session that it belongs to.
*
* This class must be thread-safe.
*/
class SessionCatalog(
val externalCatalog: ExternalCatalog,
globalTempViewManager: GlobalTempViewManager,
functionRegistry: FunctionRegistry,
conf: SQLConf,
hadoopConf: Configuration,
parser: ParserInterface,
functionResourceLoader: FunctionResourceLoader) extends Logging {
/**
* Interface for the system catalog (of functions, partitions, tables, and databases).
*
* This is only used for non-temporary items, and implementations must be thread-safe as they
* can be accessed in multiple threads. This is an external catalog because it is expected to
* interact with external systems.
*
* Implementations should throw [[NoSuchDatabaseException]] when databases don't exist.
*/
abstract class ExternalCatalog
extends ListenerBus[ExternalCatalogEventListener, ExternalCatalogEvent] {
import CatalogTypes.TablePartitionSpec在HiveExternalCatalog 中,对数据库、数据表、数据分区和注册函数等信息的读取与操作都通过 HiveClient 完成, Hive Client 是用来与 Hive 进行交互的客户端,在 Spark SQL 中是定义了各种基本操作的接口,具体实现为 HiveClientimpl 对象。然而在实际场景中,因为历史遗留的原因,往往会涉及多种Hive版本,为了有效地支持不同版本,Spark SQL HiveClient的实现由HiveShim通过适配Hive 版本号(HiveVersion)来完成。
在HiveExternalCatalog 中有创建HiveClient的操作,但是最终是调用了IsolatedClientLoader来创建。一般spark sql只会通过HiveClient来访问Hive中的类,为了更好的隔离,IsolatedClientLoader 将不同的类分成3种,不同种类的加载和访问规则各不相同:
-共享类(Shared classes):包括基本的Java、Scala Logging和Spark 中的类。这些类通过当前上下文的 ClassLoader 加载,调用 HiveClient 返回的结果对于外部来说是可见的。
-Hive类(Hive classes):通过加载 Hive 的相关 Jar 包得到的类。默认情况下,加载这些类的ClassLoader 和加载共享类的 ClassLoader 并不相同,因此,无法在外部访问这些类
-桥梁类(Barrier classes):一般包括 HiveClientlmpl和Shim 类,在共享类与 Hive 类之间起到了桥梁的作用,Spark SQL 能够通过这个类访问 Hive 中的类。每个新的 HiveClientlmpl实例都对应一个特定的 Hive 版本。
Analyzer
逻辑执行计划,有着特定于hive的分析规则。
在hive场景中,比基础的多了ResolveHiveSerdeTable、DetermineTableStats、RelationConversions、HiveAnalysis规则。
SparkPlanner
物理执行计划,有着特定于hive的策略。
在hive场景中,比基础的多了HiveTableScans, Scripts策略。
HiveTableScans最终对应的节点HiveTableScanExec,执行hive表的scan操作,分区属性和
晒筛选谓词都可以下推到这里。
Spark sql经过Catalyst的解析,最终转化成的物理执行计划,与hive相关的TreeNode主要就是HiveTableScanExec(读数据)和InsertIntoHiveTable(写数据)。下面主要介绍下这两个类的实现原理。
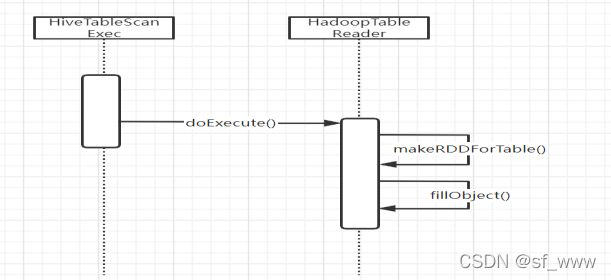
HiveTableScanExec
HiveTableScanExec的构造方法参数中比较重要的有两个,
Relation(HiveTableRelation), partitionPruningPred(Seq[Expression])
relation中有着hive表相关的信息,而partitionPruningPred中有着hive分区相关的谓词。
读取是由hadoopReader(HadoopTableReader)来进行的,不是分区表则执行
hadoopReader.makeRDDForTable,是分区表则执行hadoopReader.makeRDDForPartitionedTable。
makeRDDForTable里根据hive表的数据目录位置创建HadoopRDD,再调用
HadoopTableReader.fillObject将原始的Writables数据转化成Rows。
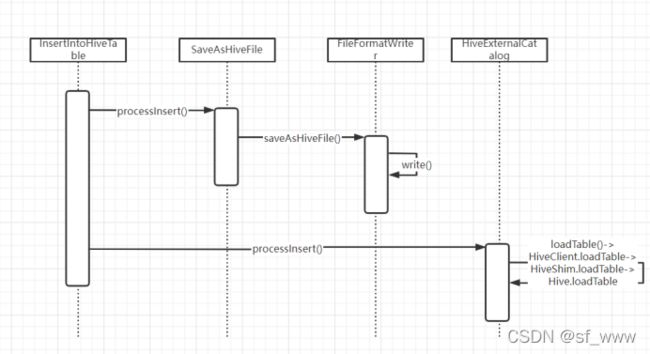
InsertIntoHiveTable
InsertIntoHiveTable的执行流程就是获取到HiveExternalCatalog、hadoop相关的配置、hive
表信息、临时写入的目录位置等,然后调用processInsert方法插入,最终再删除临时写入位
置。processInsert方法里会依次调用saveAsHiveFile将RDD写到临时目录文件中,然后再调
用HiveExternalCatalog的loadTable方法(HiveClient.loadTable -> HiveShim.loadTable -> Hive.loadTable即最终会通过反射调用Hive的loadTable方法)将临时写入目录位置的文件
加载到hive表中。
在上面读写的过程中,就会涉及到Sparksql Row与Hive数据类型的映射。该转换功能主要
就是由HiveInspectors来实现。