Redis 主从同步原理
一、什么是主从同步?
主从同步,就是将数据冗余备份,主库(Master)将自己库中的数据,同步给从库(Slave)。
从库可以一个,也可以多个,如图所示:

二、为什么需要主从同步?
Redis 虽然有 RDB 和 AOF 持久化技术,可以在服务器重启的情况下保证内存中的数据不会丢失(但不意味着数据不丢,重启的时候还是会有不可用的情况)。
但是如果服务器关闭后,再也起不来了(比如硬件故障),那意味着数据是完全丢失的!会对业务产生重大影响。
所以,主从同步的必要性,在于数据的高可用。它可以保证机器故障时,还有其他的服务器可以进行故障转移。
问题来了,多台服务器冗余同一份数据,Redis 是如何保证数据的一致性的?
三、Redis 是如何做到主从同步的?
简单概括,有两点:
- 一切修改只在主库进行:即主库可读可写,从库只读不可写;
- 写操作从主库同步到从库:全量同步、增量同步。
(一)全量同步
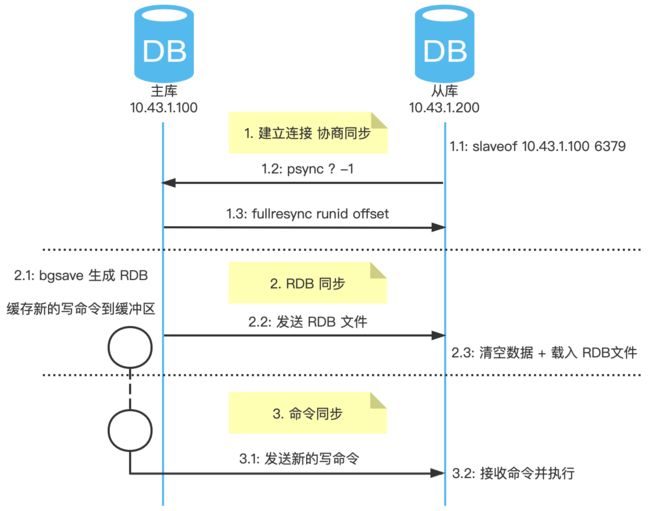
1. 建立连接 协商同步
1.1 使用客户端 redis-cli 连接从库,执行 replicaof 命令,指定主库 IP 和端口;
1.2 从库响应后,执行 psync 命令,它包含 主库 runid 和 复制偏移量 offset 两个参数:
- runid:启动时自动生成随机唯一 ID。首次同步时,主库 runid 未知,所以为
?; - offset:表示复制的进度,第一次同步时,其值为
-1。
1.3 主库收到 psync 命令后,使用 FULLRESYNC 命令响应从库,同时也包含 主库 runid 和 复制偏移量 offset 两个参数,从库会记录这两个参数。
注:replicaof 命令等同于 slaveof 命令,Redis 5.0 之前使用 slaveof 命令。
2. RDB 同步
2.1 主库执行 bgsave 命令,此时将 fork 出子进程生成 RDB 文件,新命令会写入到缓冲区;
2.2 发送 RDB 文件到从库;
2.3 从库清空数据后,载入 RDB 文件。
注一:为保证数据一致性,
bgsave执行后,主库会持续写入新命令到缓冲区,直到从库加载 RDB 完成;注二:bgsave 创建了子进程,子进程独立负责 RDB 生成的工作,生成 RDB 的过程中,不会阻塞 Redis 主库,主库依然可以正常处理命令。
3. 命令同步
3.1 完成 RDB 载入后,从库会回复确认消息给主库,主库会将缓冲区的写命令发送给从库;
3.2 从库接收主库的写命令并执行,使得主从数据一致。
注:命令执行后,长连接会一直保持,写操作命令也会一直同步,保证主从数据的一致性;
这个过程也称为「基于长连接的命令传播」。
(二)增量同步
命令传播的过程中,如果出现 网络故障 导致连接断开,此时新的写命令将无法同步到从库。
即便是抖动后断开又恢复网络连接,但此时 TCP 连接已经断开,数据肯定是需要重新同步了。
- 在 Redis 2.8 之前,从库只能和主库重新发起全量同步,对于较大的 RDB 文件,网络恢复时间较长;
- 从 Redis 2.8 开始,从库已支持增量同步,只会把断开的时候没有发生的写命令,同步给从库。

详细过程如下:
- 网络恢复后,从库发生 psync 命令给主库,并携带之前主库返回的 runid,还有复制的偏移量 offset;
- 主库收到命令后,核查 runid 和 offset,确认没问题将响应
CONTINUE命令; - 主库发送网络断开期间的写命令,从库接收命令并执行。
实际上,主库在进行命令传播的过程中,做了两个事情:
- 发送写命令给从库;
- 写命令写入
repl_backlog_buffer复制积压缓冲区,保存最近传播的写命令。
复制积压缓冲区,是一个环形缓冲区。主库除了拥有 repl_backlog_buffer,还存在复制点位 master_repl_offset;
同理,从库,也有复制点位 slave_repl_offset;
如果从库的 psync 命令指定的 offset,数据还存在 repl_backlog_buffer 缓冲区里,也就是:
master_repl_offset - size < slave_repl_offset,即主库最小的偏移量,小于从库的偏移量,说明数据还在环形缓冲区里。
所以,只要主库的缓冲区足够大,足以容纳最近的写命令(Redis 协议),就可以在网络中断后使用增量同步了。
默认 repl_backlog_buffer = 1M,如果写入数据量较大,比如 1M/s,显然,网络故障 1秒后,复制积压缓冲区数据无效,所以应该增大它的值。
具体大小,需要根据实际情况确定。建议设置 10M 以上,大概就是 10s 以内的中断,因为 Redis 服务器启动也需要一定时间。
文章来源于本人博客,发布于 2022-05-28,原文链接:https://imlht.com/archives/259/