SpringBoot——数据层三组件之间的关系
简单介绍
在之前的文章中,我们介绍了一下SpringBoot中内置的几种数据层的解决方案,在数据层由三部分组成,分别是数据库,持久化技术以及数据源,但是我今天写着写着,突然就想不起来这三部分到底是干什么的了,所以特意作文回忆一下我们这一路到底是用到现在的数据层模式的,以及我们一开始的数据模式是什么,主要还是想理一下这个三个组成部分的关系。
一切的开始
第一次接触数据库编程,基础的是MySQL,作为一款市场最广,最好上手的一款开源数据库,使用MySQL开局确实不错,但是第一次看到MySQL,他是这个样子的:
很好,很符合我对程序员的想象,就是一个朴实无华的黑框,没有任何的花里胡哨的作用,就是单纯的执行SQL语句,甚至有时候你换个行都会导致语句报错。
后来接触到了第一个数据可视化软件,这个因人而异,我第一次接触是NaiCat,有一些人是SQLyog,但是无论哪一个,猛地从小黑框换成一个可编程的界面多少还是有一点小惊喜的:
到了后来,除了MySQL,开始深入其他的编程语言,我第一个接触的编程语言是Java,然后在很长的一段时间,我用的都是这个: 直到现在我依然觉得这个很好用,能在代码和SQL界面之间切换,还是很不错的。
直到现在我依然觉得这个很好用,能在代码和SQL界面之间切换,还是很不错的。
说回编程
对于SQL的编程,之前学习的SQL语言自然不用多说,这是肯定都会的,然后就是Java连接数据库。既然是Java连接SQL数据库编程,肯定离不开的就是JDBC:
package com.example.springbootsum.pojo;
import java.sql.*;
import java.util.HashMap;
public class JDBC {
public static void main(String[] args) throws Exception {
// 数据源
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/jdbc";
String username = "root";
String password = "数据库密码";
Connection connection = DriverManager.getConnection(url, username, password);
Statement statement = connection.createStatement();
// 持久化
String sql = "select * from user";
ResultSet resultSet = statement.executeQuery(sql);
HashMap user = new HashMap();
while (resultSet.next()){
user.put(resultSet.getInt("id"), resultSet.getString("name"));
}
System.out.println(user);
}
}
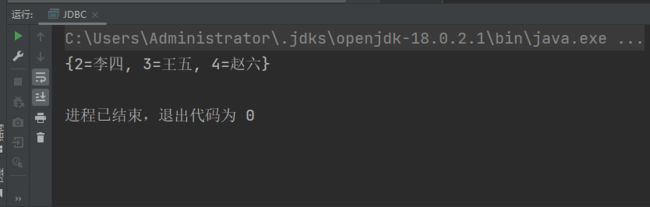
有点简陋,但是道理是一样的。
我们在使用JDBC的时候就说过,首先你的数据库账号和密码都在代码里,不安全。你的SQL也在代码里,不安全。而且你要说更换自己的SQL就得从代码里找自己的SQL写在哪里,如果你要是编码习惯好点,你把SQL都写在统一的地方,还好说,你要是跟我一样写的像是Shift一样,自己看了都给自己气笑了了的程度那我劝你善良。
这是第一阶段,这个时候对于Java操作数据库仅仅是做了解,那时候我还是学的JavaWeb,比起数据库,更吸引我的还是炫酷的前端动画和框架,以及动态网页,至于数据库,那都是后话。得到了对于JDBC熟悉了之后,就开始接触另一个东西叫做JavaEE,然后就开始接触成熟的框架,那个时候才对数据源,持久化技术这种东西。
我在JDBC的代码中也表明了数据源和持久化技术的底层代码都是什么,数据源就是数据库连接对象,之前是你把数据库连接信息写在代码里自己手动生成数据源连接对象,然后操作SQL语句,数据源说你写的代码不严谨,我来帮你吧。
然后数据源这个东西就出现了,第一个接触的数据源就是Druid,然后顺便也开始使用框架去进行规范的开发流程,只不过那时候的框架还是原生的Spring,需要写的代码和配置文件还是不少。
从一开始的XML方式开发,到后来的纯注解式开发,数据源需要写的基本就只剩下用户名和密码以及url,直接就能获取一个现成的,完整的数据库连接对象,岂不美哉。
那么说回来,数据源的标准定义如下:
数据源,简单理解为数据源头,提供了应用程序所需要数据的位置。数据源保证了应用程序与目标数据之间交互的规范和协议,它可以是数据库,文件系统等等。其中数据源定义了位置信息,用户验证信息和交互时所需的一些特性的配置,同时它封装了如何建立与数据源的连接,向外暴露获取连接的接口。
当然是百度的,这么长一段我可记不住。
我用到现在也还停留在数据源就是我给他一组数据库连接信息他给我一个完美的数据库连接对象的程度,我承认,我不是一个好的程序员。
后来一个数据源不够用,当你的服务对外开放之后,你的数据库会被很多人访问,这时候单个的数据源肯定是不够用的,这时候就出现了数据库连接池,可以一次创建多个数据源供人使用,节省资源,这就是后话了。
持久化技术
持久化技术就是在JDBC中的后半部分,也就是我们在Java中执行SQL代码将数据写入数据库中或者说将数据库中的数据读取出来的过程。一开始的持久化技术非常的繁琐,你需要自己写SQL,自己写结果集的处理,自己将结果集的单个字段于Java对象建立连接,那时候做个开发很难,写这些SQL展示到自己的网页里就非常的麻烦,后来开始解除了另一种简单一些的持久化技术,JdbcTemplate。
这种技术之前已经演示过了,确实是节省了处理结果集的步骤,但是依然没有解决SQL的硬编码问题,在这个阶段开发舒服了一些,最直观的就是可以直接将数据集与Java对象关联起来。
后来开始接触Spring框架,然后是MyBatis,这时候的后端开发就很方便了,可以将SQL语句写在配置文件中,或者是直接以注释参数的方式写在接口中,然后直接通过方法返回一个对象,在Java里操作对象会方便很多。
后来进化到了MyBatis-Plus,更快更方便的制作数据层的持久化,与数据库的交互就更容易了。
关于持久化技术,他的官方定义是这样的:
将内存中的瞬时数据保存到存储设备中。
这个我努努力能记得住,但是讲真的,我用到现在的持久化基础除了写道数据库里就是写在文件里,其他的使用场景,还真的挺少,果然,我是一个FW程序员。
尽管现在的开发速度越来越快,开发流程越来越成熟,但是偶尔我还是会写一些JDBC的东西,去体验一下最底层,最单纯的美好。