kaggle,球员接触检测

比赛链接
比赛目标
检测球员在NFL橄榄球比赛中所经历的外部接触。你将使用视频和球员跟踪数据来识别与接触的时刻,以帮助提高球员的安全。
评价指标
马修斯相关系数(Matthews Correlation Coefficient,简称MCC)是一种常用的二分类评价指标,用于衡量预测与实际接触事件之间的关联程度。
换句话说,对于每个contact_id,您需要预测在那个特定的时刻,两位球员是否发生接触。contact_id由以下格式组成:game_play_step_player1_player2。其中,player1是较低ID的球员,player2可以是另一位球员或地面(player G)。您的任务是根据这些contact_id,预测其中涉及的球员是否在接触状态。
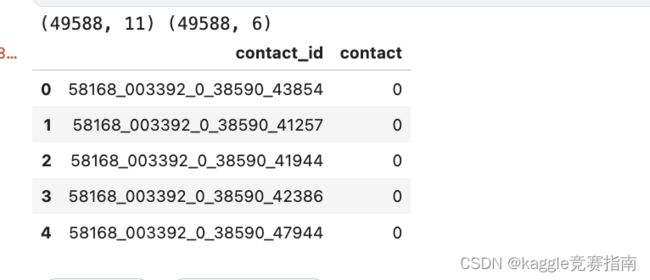
sample_submission.csv文件提供了所有可行contact_id的详细列表,您需要在相应的行中提供相应的预测结果。文件应包含一个标题行,并采用以下格式:
contact_id,contact
58168_003392_0_38590_43854,0
58168_003392_0_38590_41257,1
58168_003392_0_38590_41944,0
数据描述
你的任务是预测球员之间的接触时刻,以及球员使用比赛录像和跟踪数据进行非足部接触地面的时刻。每个剧本有四个相关的视频。两个视频,显示一个边线和端区视图,是时间同步和对齐彼此。此外,还提供了All29视图,但不能保证时间同步。训练集视频在train_labels.csv中有相应的标签,而你必须预测的视频在test/文件夹中。
今年,我们还为训练和测试集提供了基线头盔检测和分配盒。csv是去年获胜球员分配模型的输出。
train_player_tracking.csv在提供的比赛中为每个球员提供10hz的跟踪数据。
csv包含与每个边线和Endzone视图相关联的时间戳,用于与球员跟踪数据同步。
相关的test_baseline_helmet .csv、test_player_tracking.csv和test_video_metadata.csv在提交模型时是可用的。
还为训练和测试集提供了基线头盔检测和分配盒。
- train_baseline_helmets.csv 是去年获胜球员分配模型的输出。
- train_player_tracking.csv 在提供的比赛中为每个球员提供10hz的跟踪数据
- csv包含与每个边线和Endzone视图相关联的时间戳,用于与球员跟踪数据同步。
相关的test_baseline_helmet .csv、test_player_tracking.csv和test_video_metadata.csv在提交模型时是可用的。
Files
[train/test] mp4 每部有三个视频。这两种主要的视角分别是从底线和边线拍摄的。Sideline和Endzone视频对是逐帧匹配的,但是在每个视图中可以看到不同的玩家。今年,提供了一个额外的视图,All29,它应该包括每个球员参与比赛的视图。所有29视频不保证与边线和底线时间同步。
这些视频的帧率都是59.94 HZ。抓拍的瞬间发生在视频开始的第5秒。
这些数据包含以下内容:
- train_labels.csv:该文件包含了每个组合的球员以及每个播放时刻(每0.1秒)的接触情况。
- contact_id:由game_play、player_ids和step列组成的组合。
- game_play:游戏和播放的唯一ID。
- nfl_player_id_1:接触配对中编号较低的球员ID。如果是与地面接触,这个字段将只包含球员ID。
- nfl_player_id_2:接触配对中编号较高的球员ID。如果是与地面接触,这个字段将包含大写字母"G"。
- step:表示每个播放的每个时间步长,从播放开始的时刻为0,每0.1秒递增1。
- datetime:接触的时间戳,以10Hz的频率。
- contact:接触发生与否的标签,1表示发生接触,0表示未接触。
- sample_submission.csv:一个有效的样本提交文件。
- contact_id:由game_key、play_id、nfl_player_ids和step组成的组合(如上所述)。
- contact:二进制值,预测接触情况。1表示接触,0表示未接触。
- [train/test]_baseline_helmets.csv:包含Sideline和Endzone视频视角下头盔框和球员分配的不完美基线预测。
- game_play:游戏的唯一键和播放ID的组合。
- game_key:游戏的ID代码。
- play_id:播放的ID代码。
- view:视频视角,可以是Sideline或Endzone。
- video:相关视频的文件名。
- frame:视频中的帧编号。
- nfl_player_id:不完美的预测球员ID。
- player_label:球员标签,由V/H(主场或客场队伍)和球员背号组成。
- [left/width/top/height]:预测边界框的规格。
- [train/test]_player_tracking.csv:每个球员都佩戴传感器,可以在场上定位,并且该信息记录在这两个文件中。
- game_play:游戏的唯一键和播放ID的组合。
- game_key:游戏的ID代码。
- play_id:播放的ID代码。
- nfl_player_id:球员的ID代码。
- datetime:10Hz的时间戳。
- step:相对于播放开始的时间步长。
- position:球员的足球位置。
- team:球员所在的队伍,主场或客场。
- jersey_number:球员的球衣号码。
- x_position:球员在场地长轴上的位置。
- y_position:球员在场地短轴上的位置。
- speed:每秒移动的速度(码)。
- distance:与上一个时间点的距离(码)。
- orientation:球员的方向(度)。
- direction:球员运动的角度(度)。
- acceleration:总加速度的大小(码/秒²)。
- sa:球员沿着移动方向的有符号加速度(码/秒²)。
这些数据提供了关于比赛中球员接触、球员位置和运动的信息,可以用于预测球员之间的接触事件。
baseline
数据读取
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
from sklearn.metrics import matthews_corrcoef
# Read in data files
BASE_DIR = "../input/nfl-player-contact-detection"
# Labels and sample submission
labels = pd.read_csv(f"{BASE_DIR}/train_labels.csv", parse_dates=["datetime"])
ss = pd.read_csv(f"{BASE_DIR}/sample_submission.csv")
# Player tracking data
tr_tracking = pd.read_csv(
f"{BASE_DIR}/train_player_tracking.csv", parse_dates=["datetime"]
)
te_tracking = pd.read_csv(
f"{BASE_DIR}/test_player_tracking.csv", parse_dates=["datetime"]
)
# Baseline helmet detection labels
tr_helmets = pd.read_csv(f"{BASE_DIR}/train_baseline_helmets.csv")
te_helmets = pd.read_csv(f"{BASE_DIR}/test_baseline_helmets.csv")
# Video metadata with start/stop timestamps
tr_video_metadata = pd.read_csv(
"../input/nfl-player-contact-detection/train_video_metadata.csv",
parse_dates=["start_time", "end_time", "snap_time"],
)
比赛目标:预测是否有接触
两个球员之间。在球员和地面之间。
注:当球员用手或脚以外的任何东西接触地面时,被认为是与地面接触。
提交的内容应包括对22名球员的所有可能组合的预测,以及每个球员在比赛中每个时间步的情况。每个预测对只需要一行,较低玩家的nfl_player_id为nfl_player_id_1,较大玩家的nfl_player_id_2。
import os
import cv2
import subprocess
from IPython.display import Video, display
import pandas as pd
def video_with_helmets(
video_path: str, baseline_boxes: pd.DataFrame, verbose=True
) -> str:
"""
Annotates a video with baseline model boxes and labels.
"""
VIDEO_CODEC = "MP4V"
HELMET_COLOR = (0, 0, 0) # Black
video_name = os.path.basename(video_path)
if verbose:
print(f"Running for {video_name}")
baseline_boxes = baseline_boxes.copy()
vidcap = cv2.VideoCapture(video_path)
fps = vidcap.get(cv2.CAP_PROP_FPS)
width = int(vidcap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vidcap.get(cv2.CAP_PROP_FRAME_HEIGHT))
output_path = "labeled_" + video_name
tmp_output_path = "tmp_" + output_path
output_video = cv2.VideoWriter(
tmp_output_path, cv2.VideoWriter_fourcc(*VIDEO_CODEC), fps, (width, height)
)
frame = 0
while True:
it_worked, img = vidcap.read()
if not it_worked:
break
# We need to add 1 to the frame count to match the label frame index
# that starts at 1
frame += 1
# Let's add a frame index to the video so we can track where we are
img_name = video_name.replace(".mp4", "")
cv2.putText(
img,
img_name,
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
1,
HELMET_COLOR,
thickness=1,
)
cv2.putText(
img,
str(frame),
(1280 - 90, 720 - 20),
cv2.FONT_HERSHEY_SIMPLEX,
1,
HELMET_COLOR,
thickness=1,
)
# Now, add the boxes
boxes = baseline_boxes.query("video == @video_name and frame == @frame")
for box in boxes.itertuples(index=False):
cv2.rectangle(
img,
(box.left, box.top),
(box.left + box.width, box.top + box.height),
HELMET_COLOR,
thickness=1,
)
cv2.putText(
img,
box.player_label,
(box.left + 1, max(0, box.top - 20)),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
HELMET_COLOR,
thickness=1,
)
output_video.write(img)
output_video.release()
# Not all browsers support the codec, we will re-load the file at tmp_output_path
# and convert to a codec that is more broadly readable using ffmpeg
if os.path.exists(output_path):
os.remove(output_path)
subprocess.run(
[
"ffmpeg",
"-i",
tmp_output_path,
"-crf",
"18",
"-preset",
"veryfast",
"-hide_banner",
"-loglevel",
"error",
"-vcodec",
"libx264",
output_path,
]
)
os.remove(tmp_output_path)
return output_path
这段代码的作用是将基线模型的盔甲框和标签添加到给定视频中,并生成带有盔甲框和标签的新视频。
函数video_with_helmets()接受以下参数:
video_path:视频文件的路径,即要进行标注的原始视频。baseline_boxes:包含基线模型盔甲框和标签的DataFrame数据,其中每一行表示一个盔甲框的位置和相关信息。verbose(可选):布尔值,用于控制是否显示进度和输出。
函数的主要步骤如下:
- 初始化视频的一些参数,如帧率、宽度和高度。
- 创建输出视频的文件路径和临时文件路径。
- 使用OpenCV中的
VideoCapture读取原始视频。 - 循环遍历视频的每一帧:
- 读取当前帧的图像。
- 在视频中添加帧索引和视频名称的标签。
- 从
baseline_boxes中获取与当前帧对应的盔甲框信息。 - 对于每个盔甲框,使用OpenCV中的函数在图像上绘制矩形框和标签。
- 将标注后的图像写入输出视频文件。
- 释放视频写入器,完成输出视频的生成。
- 使用FFmpeg将临时输出视频文件转换为更广泛支持的编解码器格式。
- 删除临时输出视频文件,并返回输出视频的文件路径。
这段代码的目的是为了将基线模型的盔甲框和标签添加到原始视频中,以便进行可视化和分析。通过在每个帧上绘制盔甲框和标签,可以更直观地观察和评估模型对球员的检测和跟踪效果。
example_video = "../input/nfl-player-contact-detection/train/58168_003392_Sideline.mp4"
output_video = video_with_helmets(example_video, tr_helmets)
frac = 0.65 # scaling factor for display
display(
Video(data=output_video, embed=True, height=int(720 * frac), width=int(1280 * frac))
)
NFL接触视频
NGS(Next Gen Stats)跟踪数据对于正确标记视频非常重要。以下是一些需要注意的事项:
-
NGS数据的采样率为10赫兹(Hz),而视频的采样率大约为59.94赫兹。
- 这意味着NGS数据每秒钟记录10个数据点,而视频每秒钟显示约60个帧。
- 由于两者的采样率不同,需要进行适当的同步以将NGS数据与视频对应起来。
-
可以使用训练元数据对跟踪数据和视频进行大致的同步。
- 训练元数据可能包含有关视频和NGS数据的时间信息,可以使用这些信息将它们对齐。
-
NGS数据包含一个步长(step)列,可以将其与标签和样本提交文件进行合并。
- 步长列用于表示每个时间点的时间步长,可以与标签和样本提交文件中的时间步长进行匹配,以确定对应关系。
-
NGS数据还包含其他特征,如速度、加速度、朝向等。
- 这些特征可以为模型提供关于球员运动和状态的信息。
- 对于完整的特征列表,可以参考数据描述页面或相关文档。
总之,NGS跟踪数据提供了关于球员运动、位置和状态的信息,可以与视频进行关联和比对,以确保正确标记视频数据。通过将NGS数据与视频时间对齐,并结合其他特征,可以更准确地分析和理解视频中的球员行为。
game_play = "58168_003392"
example_tracks = tr_tracking.query("game_play == @game_play and step == 0")
ax = create_football_field()
for team, d in example_tracks.groupby("team"):
ax.scatter(
d["x_position"],
d["y_position"],
label=team,
s=65,
lw=1,
edgecolors="black",
zorder=5,
)
ax.legend().remove()
ax.set_title(f"Tracking data for {game_play}: at step 0", fontsize=15)
plt.show()
这段代码的作用是在橄榄球场地上绘制指定比赛中球员的位置轨迹。
首先,通过查询tr_tracking数据集,选择了指定game_play和step的轨迹数据,存储在example_tracks变量中。
接下来,使用create_football_field()函数创建了一个橄榄球场地的图像,存储在ax变量中。
然后,根据球队将轨迹数据分组,并循环迭代每个球队的轨迹数据。对于每个球队,使用ax.scatter()函数在图像上绘制球员的位置点。具体地,传递了球员的x和y坐标作为散点图的数据,设置了标签、大小、边界线宽度、边界颜色等属性来突出显示球员位置。
最后,通过移除图例(使用ax.legend().remove())和设置标题(使用ax.set_title())来美化图像。
最后,使用plt.show()函数显示生成的橄榄球场地图像。
这段代码的目的是在橄榄球场地上可视化指定比赛和特定时间步长的球员位置轨迹,以帮助分析球员的移动和行为。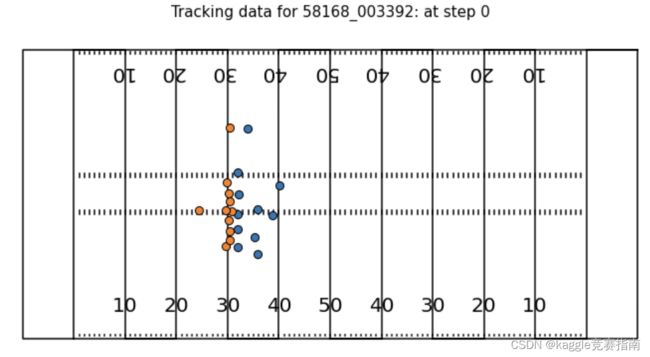
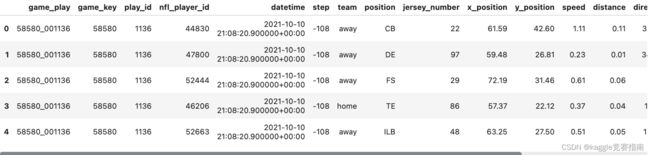
tr_tracking.head()
Video Metadata
These files provide information that can be used to sync the video files with the NGS tracking data
tr_video_metadata.head()

Contact Labels
这段说明提供了有关接触标签(Contact Labels)的信息。
接触标签用于标识两名球员之间或与地面接触的时刻。以下是关于标签的一些要注意的事项:
- 标签以10赫兹的频率提供,与NGS跟踪数据同步。
- 标签从
step == 0(比赛开始)开始,并在与最短视频(Sideline或Endzone)相关的步长结束。 - 每个标签(和提交结果)对应于以下情况的单行数据:
- 球员配对,其中
nfl_player_id_1 < nfl_player_id_2。 - 球员与地面接触,其中
nfl_player_id == "G"。
- 球员配对,其中
contact_id列是一个唯一标识符,它是game_play、step、nfl_player_id_1和nfl_player_id_2列的组合。contact列是一个二进制值,其中0表示未接触,1表示接触。
尽管标签和视频以不同的频率采样,但我们可以近似地将它们连接起来,以便可以将它们与视频一起进行可视化。下面提供了一个用于连接标签和视频的示例函数。
这段说明的目的是解释了接触标签的特点和如何将它们与视频数据进行关联,以便在视频上进行可视化。
labels.head()

def join_helmets_contact(game_play, labels, helmets, meta, view="Sideline", fps=59.94):
"""
Joins helmets and labels for a given game_play. Results can be used for visualizing labels.
Returns a dataframe with the joint dataframe, duplicating rows if multiple contacts occur.
"""
# 从labels数据中选择指定game_play的标签数据
gp_labs = labels.query("game_play == @game_play").copy()
# 从helmets数据中选择指定game_play的头盔数据
gp_helms = helmets.query("game_play == @game_play").copy()
# 获取指定game_play和视角的起始时间
start_time = meta.query("game_play == @game_play and view == @view")["start_time"].values[0]
# 将头盔数据的帧时间转换为具体的日期时间
gp_helms["datetime"] = pd.to_timedelta(gp_helms["frame"] * (1 / fps), unit="s") + start_time
gp_helms["datetime"] = pd.to_datetime(gp_helms["datetime"], utc=True)
# 将头盔数据的日期时间与NGS跟踪数据的时间进行对齐
gp_helms["datetime_ngs"] = (
pd.DatetimeIndex(gp_helms["datetime"] + pd.to_timedelta(50, "ms"))
.floor("100ms")
.values
)
gp_helms["datetime_ngs"] = pd.to_datetime(gp_helms["datetime_ngs"], utc=True)
# 将标签数据的日期时间转换为具体的日期时间
gp_labs["datetime_ngs"] = pd.to_datetime(gp_labs["datetime"], utc=True)
# 将头盔数据和标签数据进行合并,通过日期时间和球员ID进行匹配
gp = gp_helms.merge(
gp_labs.query("contact == 1")[
["datetime_ngs", "nfl_player_id_1", "nfl_player_id_2", "contact_id"]
],
left_on=["datetime_ngs", "nfl_player_id"],
right_on=["datetime_ngs", "nfl_player_id_1"],
how="left",
)
return gp
该函数的作用是将头盔数据和标签数据进行合并,以便可视化标签。函数返回一个数据框,其中包含合并后的数据,如果发生多个接触事件,会将行复制。
函数的参数解释如下:
game_play:指定的game_play,用于选择相应的头盔和标签数据。
labels:包含标签数据的DataFrame。
helmets:包含头盔数据的DataFrame。
meta:包含游戏元数据的DataFrame。
view(可选):指定视角,默认为"Sideline"。
fps(可选):视频的帧率,默认为59.94。
函数的主要步骤如下:
从标签数据中选择指定game_play的标签数据和头盔数据。
获取指定game_play和视角的起始时间。
将头盔数据的帧时间转换为具体的日期时间,并与NGS跟踪数据的时间进行对齐。
将标签数据的日期时间转换为具体的日期时间。
将头盔数据和标签数据通过日期时间和球员ID进行合并。
import os
import cv2
import subprocess
from IPython.display import Video, display
import pandas as pd
def video_with_contact(
video_path: str, baseline_boxes: pd.DataFrame, verbose=True
) -> str:
"""
给视频添加基线模型的方框,并根据接触标签给头盔方框上色。
"""
VIDEO_CODEC = "MP4V"
HELMET_COLOR = (0, 0, 0) # 黑色
video_name = os.path.basename(video_path)
if verbose:
print(f"运行中: {video_name}")
baseline_boxes = baseline_boxes.copy()
vidcap = cv2.VideoCapture(video_path)
fps = vidcap.get(cv2.CAP_PROP_FPS)
width = int(vidcap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vidcap.get(cv2.CAP_PROP_FRAME_HEIGHT))
output_path = "contact_" + video_name
tmp_output_path = "tmp_" + output_path
output_video = cv2.VideoWriter(
tmp_output_path, cv2.VideoWriter_fourcc(*VIDEO_CODEC), fps, (width, height)
)
frame = 0
while True:
it_worked, img = vidcap.read()
if not it_worked:
break
# 需要将帧计数加1以匹配从1开始的标签帧索引
frame += 1
# 在视频上添加帧索引以便追踪位置
img_name = video_name.replace('.mp4','')
cv2.putText(
img,
img_name,
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
1,
HELMET_COLOR,
thickness=1,
)
cv2.putText(
img,
str(frame),
(1280 - 90, 720 - 20),
cv2.FONT_HERSHEY_SIMPLEX,
1,
HELMET_COLOR,
thickness=1,
)
# 添加方框
boxes = baseline_boxes.query("video == @video_name and frame == @frame")
contact_players = boxes.dropna(subset=["nfl_player_id_2"]).query(
'nfl_player_id_2 != "G"'
)
contact_ids = (
contact_players["nfl_player_id_1"].astype("int").values.tolist()
+ contact_players["nfl_player_id_2"].astype("int").values.tolist()
)
for box in boxes.itertuples(index=False):
if box.nfl_player_id_2 == "G":
box_color = (0, 0, 255) # 红色,代表与地面接触
box_thickness = 2
elif int(box.nfl_player_id) in contact_ids:
box_color = (0, 255, 0) # 绿色,代表球员之间的接触
box_thickness = 2
# 添加球员之间的连线
if not np.isnan(float(box.nfl_player_id_2)):
player2 = int(box.nfl_player_id_2)
player2_row = boxes.query("nfl_player_id == @player2")
if len(player2_row) == 0:
# 球员2不在视野范围内
continue
cv2.line(
img,
(box.left + int(box.width / 2), box.top + int(box.height / 2)),
(
player2_row.left.values[0]
+ int(player2_row.width.values[0] / 2),
player2_row.top.values[0]
+ int(player2_row.height.values[0] / 2),
),
color=(255, 0, 0),
thickness=2,
)
else:
box_color = HELMET_COLOR
box_thickness = 1
# 绘制方框和标签
cv2.rectangle(
img,
(box.left, box.top),
(box.left + box.width, box.top + box.height),
box_color,
thickness=box_thickness,
)
cv2.putText(
img,
box.player_label,
(box.left + 1, max(0, box.top - 20)),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
HELMET_COLOR,
thickness=1,
)
output_video.write(img)
output_video.release()
# 不是所有的浏览器都支持指定的编解码器,因此我们将重新加载位于tmp_output_path的文件
# 并使用ffmpeg将其转换为更广泛可读取的编解码器
if os.path.exists(output_path):
os.remove(output_path)
subprocess.run(
[
"ffmpeg",
"-i",
tmp_output_path,
"-crf",
"18",
"-preset",
"veryfast",
"-hide_banner",
"-loglevel",
"error",
"-vcodec",
"libx264",
output_path,
]
)
os.remove(tmp_output_path)
return output_path
该函数的作用是将基线模型的方框添加到视频中。头盔方框的颜色基于接触标签。
函数的参数解释如下:
video_path:视频文件的路径。baseline_boxes:包含基线模型方框的DataFrame。verbose(可选):是否显示详细信息,默认为True。
函数的主要步骤如下:
- 设置视频编解码器、头盔颜色和输出路径。
- 打开视频文件,并获取帧率、宽度和高度信息。
- 循环读取视频的每一帧。
- 在每一帧上添加视频名称和帧索引的文本。
- 根据帧索引从基线模型方框中选择相应的方框数据。
- 根据方框数据中的接触标签进行颜色分类,并添加相应的方框和连线。
- 将处理后的帧写入输出视频。
- 最后,将输出视频进行编码转换以保证广泛可读性,并删除临时文件。
函数返回输出视频的路径。
该函数的目的是给视频添加基线模型的方框,并根据接触标签给头盔方框上色,以便更好地可视化接触情况。
带有标签的视频示例
在这个视频中,你可以看到这个游戏的标签,大约与视频中相关的头盔相连。
视频中的注意事项:
黑色头盔框表示玩家没有接触。一个独特的数字(主场/客场与球衣号码相结合)显示在他们的头盔旁边。
绿色头盔框表示玩家与一个或多个玩家接触。
红色头盔框表示玩家与地面接触(可能还有另一名玩家)。
蓝线表示玩家之间的联系。
game_play = "58168_003392"
gp = join_helmets_contact(game_play, labels, tr_helmets, tr_video_metadata)
example_video = f"../input/nfl-player-contact-detection/train/{game_play}_Sideline.mp4"
output_video = video_with_contact(example_video, gp)
frac = 0.65 # scaling factor for display
display(
Video(data=output_video, embed=True, height=int(720 * frac), width=int(1280 * frac))
)
NFL代码讲解视频2
准备代码提交
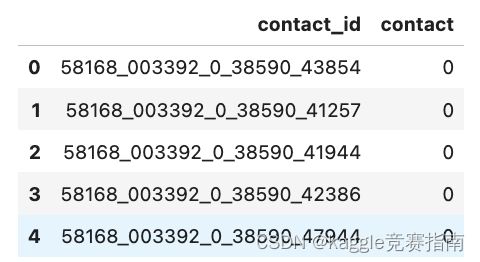
ss = pd.read_csv(f'{BASE_DIR}/sample_submission.csv')
ss.head()
基线方法
我们可以使用跟踪数据创建一个简单的解决方案,并根据竞赛指标的训练数据识别出一个最佳阈值。
这个基线提交不考虑球员与地面的接触,将每个球员与地面的行预测为非接触。
具体步骤如下:
对于每个contact_id,我们计算球员之间的距离。
我们将球员与地面的行的距离填充为99,以便将其视为非接触。
我们在0到5码之间循环阈值,并计算每个阈值下的竞赛指标。
我们选择在测试提交上产生最佳分数的阈值。
def compute_distance(df, tr_tracking, merge_col="datetime"):
"""
将跟踪数据合并在球员1和2上,并计算距离。
"""
df_combo = (
df.astype({"nfl_player_id_1": "str"})
.merge(
tr_tracking.astype({"nfl_player_id": "str"})[
["game_play", merge_col, "nfl_player_id", "x_position", "y_position"]
],
left_on=["game_play", merge_col, "nfl_player_id_1"],
right_on=["game_play", merge_col, "nfl_player_id"],
how="left",
)
.rename(columns={"x_position": "x_position_1", "y_position": "y_position_1"})
.drop("nfl_player_id", axis=1)
.merge(
tr_tracking.astype({"nfl_player_id": "str"})[
["game_play", merge_col, "nfl_player_id", "x_position", "y_position"]
],
left_on=["game_play", merge_col, "nfl_player_id_2"],
right_on=["game_play", merge_col, "nfl_player_id"],
how="left",
)
.drop("nfl_player_id", axis=1)
.rename(columns={"x_position": "x_position_2", "y_position": "y_position_2"})
.copy()
)
df_combo["distance"] = np.sqrt(
np.square(df_combo["x_position_1"] - df_combo["x_position_2"])
+ np.square(df_combo["y_position_1"] - df_combo["y_position_2"])
)
return df_combo
该函数用于将跟踪数据(tr_tracking)与给定DataFrame(df)根据指定的合并列(merge_col)进行合并,并计算球员之间的距离。返回合并后的DataFrame,其中包括了距离信息。
def add_contact_id(df):
# 创建联系ID
df["contact_id"] = (
df["game_play"]
+ "_"
+ df["step"].astype("str")
+ "_"
+ df["nfl_player_id_1"].astype("str")
+ "_"
+ df["nfl_player_id_2"].astype("str")
)
return df
该函数用于给DataFrame(df)添加联系ID列(contact_id)。联系ID由游戏、步骤、球员1和球员2的ID组成。
def expand_contact_id(df):
"""
将联系ID拆分为单独的列。
"""
df["game_play"] = df["contact_id"].str[:12]
df["step"] = df["contact_id"].str.split("_").str[-3].astype("int")
df["nfl_player_id_1"] = df["contact_id"].str.split("_").str[-2]
df["nfl_player_id_2"] = df["contact_id"].str.split("_").str[-1]
return df
该函数用于将联系ID列(contact_id)拆分为游戏、步骤、球员1和球员2的单独列,并更新DataFrame(df)的相应列。
# 计算距离并合并数据
df_combo = compute_distance(labels, tr_tracking)
# 打印合并后的数据形状
print(df_combo.shape, labels.shape)
# 合并跟踪数据和游戏时间数据
df_dist = df_combo.merge(
tr_tracking[["game_play", "datetime", "step"]].drop_duplicates()
)
# 将缺失值填充为99,表示球员与地面之间的距离
df_dist["distance"] = df_dist["distance"].fillna(99)

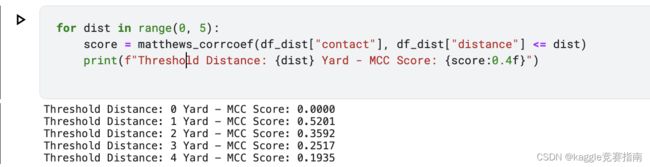
for dist in range(0, 5):
score = matthews_corrcoef(df_dist["contact"], df_dist["distance"] <= dist)
print(f"Threshold Distance: {dist} Yard - MCC Score: {score:0.4f}")
ss = pd.read_csv(f"{BASE_DIR}/sample_submission.csv")
THRES = 1
# 拆分contact_id列
ss = expand_contact_id(ss)
# 计算距离并合并数据
ss_dist = compute_distance(ss, te_tracking, merge_col="step")
# 打印合并后的数据形状
print(ss_dist.shape, ss.shape)
# 创建提交文件
submission = ss_dist[["contact_id", "distance"]].copy()
# 根据距离阈值进行二分类,判断是否为接触事件
submission["contact"] = (submission["distance"] <= THRES).astype("int")
# 删除距离列
submission = submission.drop('distance', axis=1)
# 将结果保存为CSV文件
submission[["contact_id", "contact"]].to_csv("submission.csv", index=False)
# 打印提交文件的前几行
submission.head()