SDN系统方法 | 8. 网络虚拟化
随着互联网和数据中心流量的爆炸式增长,SDN已经逐步取代静态路由交换设备成为构建网络的主流方式,本系列是免费电子书《Software-Defined Networks: A Systems Approach》的中文版,完整介绍了SDN的概念、原理、架构和实现方式。原文: Software-Defined Networks: A Systems Approach[1]

第8章 网络虚拟化
如第2章所述,网络虚拟化和本书介绍的其他部分有所不同,这是SDN第一个成功的商业用例。网络虚拟化可以在服务器上实现,通常不需要物理网络中的交换机提供任何帮助。网络虚拟化可以实现为现有网络的overlay,这在部署方面有很大的帮助。与此同时,易于部署也意味着不影响物理网络,因此不会真正改变物理网络的创新水平。然而,正如本章所阐述的那样,其确实大大简化了物理网络的管理。
虚拟化可以追溯到几十年前,是计算机科学中的既定概念,当然也适用于网络虚拟化。例如,虚拟私有网络(VPN)在20世纪90年代使用帧中继和ATM网络实现,而VLAN在20世纪90年代后期成为以太网标准的一部分。这些技术与SDN没有太多共同之处,而是使用传统网络技术来实现的。重要的是,他们没有提供被认为是SDN基础的分离控制平面和数据平面的方式。
SDN在创建虚拟网络方面的应用通常要归功于Nicira团队,正如在第二章中所讨论的,2014年Koponen等人发表了一篇论文,阐述了基于SDN的系统架构,以实现网络虚拟化。
延伸阅读:
T. Koponen et al. Network Virtualization in Multi-tenant Datacenters. NSDI, April, 2014.
以下章节将展示一组特殊的技术挑战,通过结合SDN提供的新功能,从而将网络虚拟化作为软件定义网络的成功用例。
8.1 挑战
正如今天所理解的那样,网络虚拟化与现代数据中心的发展密切相关,在这些数据中心中,大量的商业服务器相互通信以解决计算任务。这些数据中心对于大型云提供商(如AWS、Azure、谷歌)以及许多企业组织来说都很常见。早在2009年,微软研究院的VL2论文就提出了为这样的数据中心构建网络所面临的一些挑战。
延伸阅读:
Greenberg et al. VL2: a scalable and flexible data center network. SIGCOMM, August, 2009.
在这样的数据中心中,有大量的"东西"向通信,即服务器到服务器的通信,以区别于进入或离开数据中心的"南北"向通信。为了有效支持数据中心任意一对服务器之间的大量通信,第7章中描述的叶脊结构由于其高横向带宽以及可伸缩L3转发而流行起来。
与此同时,服务器虚拟化成为主流,这对数据中心运维也有影响。与安装和配置物理服务器相比,虚拟机的配置完全可以通过软件进行,而安装和配置物理服务器则是比较耗时且只能手动。由于可以轻松部署虚拟机,获得计算资源的时间从几天缩短到几分钟或几秒,这暴露出一个事实: 网络配置现在是"短板",是用户能够将基础设施投入工作之前需要完成的最慢的任务。因此人们认识到,网络配置和部署需要转向更类似于计算虚拟化的模型,从而为网络虚拟化奠定了基础。
服务器虚拟化的第二个效果是支持虚拟机迁移,这给数据中心网络带来了真正的挑战。在没有网络虚拟化的情况下,虚拟机的IP地址是从所在的物理网络中获取的,并且必须特定于连接到承载虚拟机的服务器子网[1]。因此,如果虚拟机要迁移到另一台服务器上,要么需要迁移到同样存在该子网的服务器,要么需要配置新的IP地址。第一种选择限制了其在数据中心中的移动位置,会影响资源使用的效率。第二种选择具有相当的破坏性: 无法保持TCP连接,应用程序可能需要重新启动。此外,一些应用程序依赖和通信对端之间的二层连接,因此,即使在数据中心内移动,也依赖于驻留在给定子网中的一组虚拟机。
[1] 从技术上来说,多个子网可以连接到一台给定服务器,在这种情况下,虚拟机IP地址需要从其中一个子网中获取。
针对这个问题提出的一种解决方案是使物理网络中的L2子网变得更大,但这并不是一个真正可伸缩的解决方案。大型数据中心总是使用L3网络来连接服务器机架。
Greenberg等人提出的方法可以被认为是网络虚拟化的第一步。他们创建了一个虚拟二层(VL2, Virtual Layer 2) 网络,使虚拟机使用的地址与物理网络中使用的地址分离,从而解决了上面提出的与迁移相关的问题。虚拟机从VL2网络获取IP地址,VL2构建适当的overlay,将虚拟网络扩展到需要到达的任何地方,甚至在虚拟机跨物理网络迁移时也是如此。
解决网络配置问题有点复杂。网络不仅仅是连接服务器的简单子网,还有许多需要配置的特性,包括VLAN(或其他等价的网络分段结构)、防火墙规则、网络地址转换(NAT)规则,等等。正是这些任务的复杂性使得网络配置成为数据中心配置灵活性的障碍。
为了解决这些配置和部署问题,人们最终认识到,SDN可以提供一种方法来简化虚拟网络的创建和管理,就像简化物理网络的操作一样。关键洞见在于SDN控制器的中心化API提供了指定虚拟网络期望行为的理想方式,然后由中心化控制器负责确定如何使用可用资源(如数据中心服务器管理程序中的虚拟交换机)实现网络。SDN的核心原理是数据平面与控制平面的分离,以及通过控制器的集中化来管理众多交换组件,从而为这种方法提供了基础。接下来的章节将深入探讨这是如何工作的。
8.2 架构
图42显示了可能的最简单的网络虚拟化系统。虚拟交换机位于终端主机上,虚拟机连接到这些虚拟交换机。网络虚拟化控制器公开北向API,接收描述虚拟网络预期状态的输入。例如,一个API请求可以指定"VM1和VM2应该位于同一个VL2子网network X"。控制器的职责是确定这些虚拟机的位置,然后向适当的虚拟交换机发送控制命令,以创建所需的虚拟抽象网络。下面我们仔细看看这个抽象。
 图42. 基本网络虚拟化系统。
图42. 基本网络虚拟化系统。
由于虚拟机可以在数据中心内自由迁移,因此它们的IP地址需要独立于物理网络拓扑(如图中底层网络所示),特别是我们不希望特定虚拟机被底层物理网络的子网地址限制在某个位置上。由于这个原因,网络虚拟化系统总是采用如VXLAN或NVGRE这样的overlay封装。封装是一种底层机制,解决了一个重要问题: 将虚拟网络的地址空间与物理网络的地址空间解耦。然而值得注意的是,它们只是一个构建块,而不是完整的网络虚拟化解决方案。我们将在8.3.1节中更详细介绍网络虚拟化overlay封装。
 图43. 封装将虚拟网络地址与物理网络解耦。
图43. 封装将虚拟网络地址与物理网络解耦。
关于虚拟网络封装需要注意的一点是,如图43所示,物理网络使用一组外部(outer) 头域向适当的终端主机发送数据包,而一组内部(inner) 头域仅在特定的虚拟网络上下文中有意义,这就是封装将虚拟网络寻址与物理寻址解耦的方式。
这个简单的示例还显示了网络虚拟化控制器必须实现的任务之一。当虚拟机希望与虚拟网络中的一个对等体通信时,需要应用适当的外部头,这是虚拟机当前服务器位置的功能。提供从目标虚拟机到外部报头的映射自然是集中式控制器的任务,在VL2中,这被称为*目录服务(directory service)*。
为了更好的理解网络虚拟化控制器的功能,我们需要更仔细的研究虚拟网络的定义。
8.2.1 虚拟网络定义(Virtual Networks Defined)
如上所述,虚拟网络的概念可以追溯到很久以前。例如,VLAN允许多个LAN段在一个物理LAN上共存,有点类似于虚拟内存允许进程共享物理内存的方式。然而,正如Nicira团队在NSDI论文中所阐述的那样,虚拟网络的愿景更接近于虚拟机。
虚拟机忠实再现了物理服务器的特性,包括处理器、内存、外设等,一个未经修改的操作系统可以在虚拟机上运行,就像运行在物理机器上一样。
通过类比,虚拟网络必须再现物理网络的全部特性集。这意味着虚拟网络包括路由、交换、寻址以及NAT、防火墙和负载均衡等更高层特性。未经修改的操作系统可以在虚拟机上运行,就像在物理机器上一样,未经修改的分布式应用也应该能够在虚拟网络上运行,就像在物理网络上运行一样。这显然是一个比VLAN更复杂的命题。
重要的是,即使虚拟机四处迁移,虚拟网络也需要保持正常运行。因此,我们可以开始看到,网络虚拟化控制器的角色是接受所需虚拟网络的规范,然后随着条件的变化和虚拟机的迁移,确保该网络在适当的资源上正确的实现。在下一节中,我们将对控制器的这个角色进行形式化介绍。
8.2.2 管理平面、控制平面和数据平面
现在我们可以更仔细的研究网络虚拟化系统的基本架构。与早期虚拟网络(如VLAN和VPN)相比,现代网络虚拟化系统公开了用于创建和管理虚拟网络的北向API。通过对API的调用,可以由用户或者另一个软件(如云自动化平台)指定虚拟网络的拓扑结构和服务。通常,API请求可能会说"创建一个二层子网"、"将虚拟机A绑定到子网X"或"对进入虚拟机B的流量应用防火墙策略P"。如图44所示,这些API请求将创建所需网络状态。通常将系统中接收API请求并将其存储在状态数据库中的部分称为管理平面。
 图44. 网络虚拟化系统的三个平面。
图44. 网络虚拟化系统的三个平面。
图44最下面是数据平面,通常是在hypervisor或容器主机中运行的一组虚拟交换机(vSwitches)。数据平面是实现虚拟网络的地方,正如示例所示,虚拟交换机在虚拟机和物理网络之间转发数据包,为此需要对应用适当的报头。数据平面还包含有关系统当前状态的信息,例如虚拟机位置等,这些信息需要网络虚拟化系统的更高层次加以考虑,由发现状态(discovered state) 表示。
系统的核心是控制平面,位于系统的期望状态和实际状态之间。当控制平面从数据平面接收到discovered state信息时,将其与期望状态进行比较。如果期望状态与实际状态不匹配,控制平面会计算出必要的更改,并推送到数据平面,如控制指令箭头所示。这种持续协调实际状态和期望状态的范式在分布式系统中很常见。
该体系架构(图44)与第3章中图15和16中描述的体系架构之间具有直接的映射关系。该架构的基础是一个分布式数据平面,由裸金属交换机或软件交换机组合而成,在其上有一个集中化控制器收集运行状态并发布控制指令。当以一种通用的、用例无关的方式实现时,这个控制器被称为网络操作系统。Nicira团队建立了一个早期的网络操作系统,叫做Onix,可以被认为是ONOS的前身。最上层是管理平面,服务于API请求,并理解虚拟网络抽象,可以将其看作是运行在网络操作系统上的应用程序。简言之,本章介绍的架构是专门为支持虚拟网络而构建的,而第三章中概述的架构是通用的,事实上,曾经有一个基于ONOS的虚拟网络应用,称为虚拟租户网络(VTN, Virtual Tenant Network) ,与OpenStack集成。VTN如今不再被维护,部分原因是与Kubernetes等容器管理系统集成的其他网络虚拟化子系统已经具备了很好的可用性。
接下来考虑一个简单的例子。我们希望创建一个虚拟网络,将两个虚拟机A和B连接到一个L2子网。我们可以通过一组API请求来表达这个意图,例如创建子网、接入A到子网、接入B到子网。这些API请求被管理平面接受,并按所需状态存储。控制平面观察期望状态的变化,但这些变化还没有反映在实际状态中,因此需要确定A和B的位置,以及相关hypervisor的IP地址。有了这些信息,就可以确定如果A和B要相互通信,应该怎样实现包的封装。由此计算出一组需要配置到相应vSwitches的控制指令并被推送到vSwitch(比方说表示为一组OpenFlow规则)。
如果在今后的某一时刻,其中一个虚拟机迁移到了不同的hypervisor上,则将此信息传递给控制平面,控制平面检测到实际状态不再与期望状态相匹配,将触发一次新的计算,以确定需要推送到数据平面的更新(例如将新的转发规则推送到适当的vSwitch集合,以及从不再承载虚拟机的hypervisor中删除数据平面状态)。
通过这种体系架构,可以实现丰富的虚拟网络功能集。如果数据平面足够丰富,可以实现防火墙、负载均衡器等的转发规则,那么现在就可以构建一个网络虚拟化系统,在软件中精确再现物理网络特性。
8.2.3 分布式服务
网络功能(如防火墙、负载均衡和路由)的软件实现是网络虚拟化的基本方面。然而,并不是简单的在软件中实现传统的网络设备。考虑防火墙的例子,传统防火墙是作为一个阻塞点(choke point) 来实现的,网络的设置方式是这样的: 流量必须通过防火墙才能从网络的一个部分到达另一个部分。
 图45. 常规防火墙(非分布式)。
图45. 常规防火墙(非分布式)。
考虑图45中的示例。在一个常规网络中,如果从VM A到VM C的流量需要通过防火墙,则必须设置通过防火墙的路由,这条路由不一定是从A到C的最短路径。极端情况下,两台虚拟机在相同的主机上,但仍然需要将流量发送到防火墙,然后再返回,这显然不是有效的方式,消耗了额外的网络资源以及网卡带宽。此外,由于所有需要处理的流量都必须通过集中式设备,因此防火墙本身也有可能成为瓶颈。
 图46. 分布式防火墙。
图46. 分布式防火墙。
现在考虑图46,演示了一个分布式防火墙实现。在这种情况下,从VM A发送到VM C的流量可以被所经过的虚拟交换机中的一个(或两个)防火墙处理,并且仍然可以通过两个主机之间的网络底层的最短路径发送,不需要通过外部防火墙。此外,从VM A到VM B的通信甚至不需要离开这两个VM所在的主机,只需要通过该主机上的虚拟交换机进行必要的防火墙处理。
以这种方式分发服务的一个额外好处是不再有瓶颈。每当添加一个服务器来承载更多虚拟机时,就会有新的虚拟交换机,具有执行分布式服务处理的能力。这意味着可以通过这种方式简单扩展防火墙(或任何其他正在交付的服务)数量。
同样的方法也适用于许多以前可能在专用机器中执行的其他服务: 路由、负载均衡、入侵检测,等等。并不是说在所有情况下以分布式方式实现这些服务都很简单,但通过集中控制平面,我们能够通过统一的API(或GUI)提供和配置这些服务,并以分布式的方式实现,从而获得效率和性能优势。
8.3 构件块
现在我们已经理解了网络虚拟化系统的体系架构,让我们看看用于构建这样一个系统的一些构建块。
8.3.1 虚拟网络封装(Virtual Network Encapsulation)
正如上面提到的,网络虚拟化需要某种封装,这样虚拟网络地址才能与物理网络地址解耦。发明新的封装方法似乎在网络架构师和工程师中很流行,当网络虚拟化出现时,已经有一些潜在候选方法可用,然而没有一个完全符合要求,而且在过去十年中又出现了一些新方案。
虽然2012年首次引入VXLAN时引起了相当大的关注,但这绝不是网络虚拟化封装的终结。在软件和硬件供应商以及其他IETF参与者之间进行了多年的试验和协作之后,开发出了一种结合了大多数所需特性的封装并进行了标准化。下面的RFC描述了GENEVE及其满足的一组需求。
延伸阅读:
J. Gross, I. Ganga and T. Sridhar (Eds.), Geneve: Generic Network Virtualization Encapsulation (RFC 8926).
可扩展性是GENEVE的显著特性,这代表了基于软件构建的系统(比如Nicira的系统)和用于支持网络虚拟化的硬件端点(我们将在本章后面讨论)之间的某种妥协。固定头部使硬件实现更容易,但限制了未来扩展的灵活性。最后,GENEVE包含了一个可被硬件有效处理(或忽略)的选项方案,同时仍然提供所需的可扩展性。
 图47. GENEVE头结构。
图47. GENEVE头结构。
如图47所示,GENEVE看起来与VXLAN非常相似,显著区别是存在一组可变长度的可选头域(options)。options的存在是建立在早期系统经验基础上的一个关键特性,在早期系统中,人们认识到VXLAN头中的有限空间不足以将与虚拟网络相关的元数据从隧道的一端传递到另一端。使用这种元数据的一个例子是传递数据包的逻辑源端口,以便对数据包的后续处理可以考虑其源端口。这里有一个普遍的观点,由于虚拟网络随着时间的推移而演变,软件中实现的功能越来越复杂,所以不要使用过于严格的包封装来限制可以在虚拟网络中传递的信息,这一点很重要。
8.3.2 虚拟交换机
显然,虚拟交换机在网络虚拟化中扮演着至关重要的角色。它是数据平面的主要组成部分,其特征集的丰富程度决定了网络虚拟化系统准确再现物理网络特征的能力。目前应用最广泛的虚拟交换机是Open vSwitch(OVS) 。
延伸阅读:
B. Pfaff, et al, The Design and Implementation of Open vSwitch, USENIX NSDI 2015.
Open vSwitch已经用于专有系统,如Nicira的网络虚拟化平台和VMware NSX,以及如8.4节中描述的开放虚拟网络(OVN, Open Virtual Network) 这样的开源系统。它被设计为具有必要的灵活性,以满足网络虚拟化的要求,同时还提供高性能。
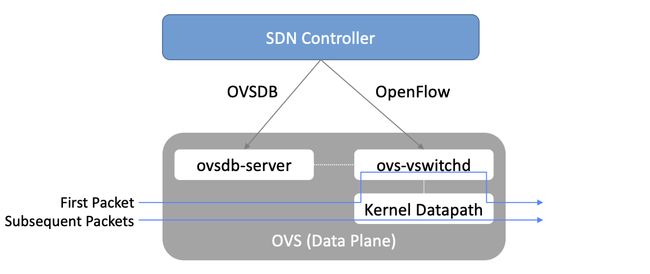 图48. Open vSwitch功能块。
图48. Open vSwitch功能块。
如图48所示,就像前面章节描述的许多硬件交换机一样,控制平面可以使用OpenFlow对OVS编程。OVS还可以在独立通道上通过Open vSwitch Database(OVSDB) 协议接收配置信息,也就是说,OVSDB在基于硬件的数据平面上有效发挥了与gNMI/gNOI相同的作用。同时,这些构建块和前面章节中描述的组件之间有直接的映射关系,术语和细节上的差异很大程度上是因为网络虚拟化作为一种专门构建的解决方案还处于发展阶段。
如图所示,OVSDB指的是用于访问数据库的RPC协议(称为ovsdb-server),但一般情况下,OVSDB既可以指协议,也可以指数据库。作为数据库,OVSDB有模式定义,可以认为它是OVS在5.3节中描述的OpenConfig模式的对应部分。作为一种协议,OVSDB使用基于json的消息格式,类似于gNMI使用的protobufs。 值得注意的是,除了图48所示作用之外,OVSDB已经发展出了自己的体系,是一种表示网络转发状态的一般方法。我们将在第8.4节中看到这一角色的更广泛的例子。
对于OVS数据平面,性能是通过Pfaff论文中描述的一系列优化来实现的,尤其是内核fastpath,它利用流缓存转发第一个包之后的所有数据包。流中的第一个包被传递给用户空间守护进程ovs-vswitchd,然后在一组表中查找流。在软件中实现的这组表可以有效支持无限数量的数据流,这是相对硬件实现OpenFlow交换的明显优势,从而实现了网络虚拟化所需的高度灵活性。与此同时,使用P4作为编写包转发器的通用语言,统一软件和硬件转发组件的努力还在进行中,这也使P4Runtime成为了控制数据平面的接口自动生成解决方案。
值得注意的是,OVS不仅可用于虚拟机与外界之间的报文转发,还可用于容器环境中,包括在同一主机或不同主机的容器之间转发报文。因此,容器的网络虚拟化系统可以由许多与虚拟机相同的组件构建,也可以支持混合环境(容器和虚拟机在单个虚拟网络中通信)。
8.3.3 性能优化
由于虚拟交换机位于虚拟网络中所有进入、离开虚拟机和容器的流量的数据路径中,因此虚拟交换机的性能非常关键。2015年的OVS论文讨论了多年来进行的一些性能优化,但改进vSwitch性能的方法值得进一步讨论。
第一个是DPDK(Data Path Development Kit) ,这是一套针对Intel x86平台开发的库,用于提高包括虚拟交换在内的数据转发操作的性能。其中许多概念都很简单(例如,批量处理数据包,避免上下文切换),但优化范围很大,如果应用得当,会很有效。DPDK已经成功用于实现OVS,可以显著提高性能,具体提高多少取决于实际环境。
其中一个环境是使用OVS在虚拟网络和非虚拟网络之间转发数据包,通常发生在虚拟机需要与虚拟网络之外的节点通信时。例如未虚拟化的服务器,如大型机或数据库,或公共互联网上的某些设备。这种场景被称为虚拟到物理网关,是DPDK的一个很好的候选对象,因为除了转发数据包之外没有什么事情要做(也就是说,不涉及其他CPU绑定的处理)。在这种配置下,RedHat开发者报告的实验表明,OVS-DPDK能够在高端英特尔处理器上实现超过16Mpps的转发性能(与此相比,仅使用OVS的转发速率接近1Mpps)。
延伸阅读:
RedHat Developer. Measuring and Comparing Open vSwitch Performance, June 2017.
第二个是SR-IOV(Single Root IO Virtualization) ,这是一种硬件特性,旨在提高虚拟机和外部系统之间的IO性能。其基本思想是单个物理网卡将自己作为一组虚拟网卡呈现给管理程序,每个虚拟网卡都有一组自己的资源。然后,每个虚拟机可以拥有自己的虚拟网卡,并完全绕过hypervisor,这在原则上可以提高性能。但是,对于网络虚拟化来说,这并不是一个真正有用的方法,因为也绕过了虚拟交换机。网络虚拟化的大部分价值来自可编程虚拟交换机的灵活性,因此绕过它与网络虚拟化的方向背道而驰。
另一方面,要认识到网卡在端到端场景中扮演的角色是有价值的。将某些功能从服务器卸载到网卡的传统由来已久,TCP分段卸载(TCP Segmentation Offload, TSO) 就是一个著名的例子。近年来,随着智能网卡的崛起,网卡获得了更多的能力,有可能将更多vSwitch能力转移到网卡上,从而获得潜在的性能提升。挑战在于如何以灵活性换取性能,因为智能网卡的资源仍然比通用CPU更有限。最新一代智能网卡达到了可以有效卸载部分或全部vSwitch功能的复杂程度[2]。
[2] 顺便说一句,P4作为编程智能网卡的方法越来越受欢迎,这表明有可能可以通过统一的方式将数据平面(无论是vSwitch、SmartNIC还是裸金属交换机)功能开放给控制平面。
最后,值得注意的是,与专用交换硬件相比,即使在通用硬件上实现良好的软件交换机的性能也会相对较差,因此也有利用裸金属交换机的网关实现。Davie等人在一篇论文中描述了一个例子,利用了许多ToR交换机上的VXLAN实现。
延伸阅读:
B. Davie, et al. A Database Approach to SDN Control Plane Design. Computer Communications Review, January 2017.
与许多其他网络环境一样,在设备完全可编程的灵活性和较不灵活的专用硬件的性能之间存在一个权衡。在大多数网络虚拟化的商业部署中,更灵活的通用硬件方法一直是首选。随着时间的推移,关键将是确定能够提供最大性能优势的相对固定(但普遍适用)的硬件功能子集。
8.4 示例系统
网络虚拟化系统已经有了几种成功的实现,我们已经提到了其中几种。本节将介绍开放虚拟网络(OVN, Open Virtual Network) ,作为网络虚拟化系统的一个示例,这是一个提供了良好文档的开源项目。
OVN是对OVS的一组增强,利用OVS数据平面和一组用于控制和管理平面的数据库(构建在OVSDB上),OVN的高层架构如图49所示。
 图49. OVN高层架构。
图49. OVN高层架构。
OVN的一个重要方面是它使用两个数据库(称为Northbound和Southbound)来存储状态。这些数据库使用OVSDB实现,创建OVSDB最初是为了存储OVS的配置状态,如8.3.2节所述。在OVN中,OVSDB的作用更大,可以同时用于配置状态和控制状态。
OVN运行在某个由云管理系统(CMS, Cloud Management System) 负责创建虚拟网络的环境中,比方说OpenStack,这是第一个被OVN支持的CMS。OVN/CMS插件负责将与CMS匹配的抽象映射到通用虚拟网络抽象中,这些抽象可以存储在北向数据库中,OVN使用ovsdb-server的一个实例实现这个数据库。我们可以把插件看作是管理平面,而北向数据库则是理想的状态存储库。
与图44的通用架构相比,OVN控制平面展示了一个显著的新特性。其要点在于,它被分解为集中式组件(称为ovn-northd)和运行在每个hypervisor上的分布式组件(称为OVN controller)。回想一下,在第1.2.2节中,我们讨论了SDN集中式控制和分布式控制之间的权衡,OVN采用了混合模型。OVN团队在早期系统中工作时,集中式控制器对所有流都提供了完整视图,这对扩展性带来了挑战,因此做出了拆分的决定。OVN保留逻辑上的集中控制,因此可以使用单一API入口点创建网络、查询状态等,但将与物理信息(如特定服务器中虚拟机位置)相关的控制功能分发给每个hypervisor,从而大大提高了系统的可伸缩性。
集中式组件ovn-northd将逻辑网络配置(用交换和路由等传统网络概念表示)转换为逻辑数据路径流,并将其存储在OVN南向数据库中。通过图50所示示例,可以看到逻辑流是如何工作的。
 图50. OVN中的逻辑和物理流。
图50. OVN中的逻辑和物理流。
逻辑数据路径流提供了数据平面中配置的转发规则的抽象表示,其指定方式与虚拟机的物理位置无关。本例中,我们创建了一个逻辑交换机LS1,有LP1和LP2两个端口,每个端口连接一台虚拟机,虚拟机的MAC地址如表Logical_Port所示为AA和BB。
根据Logical_Switch和Logical_Port表中的信息构建的Logical_Flows表显示了如何实现逻辑交换机来转发数据包。例如,第一行表示去往AA的MAC地址的报文需要发送到LP1端口。但是没有足够的信息在基于该流实际转发数据包,因为这取决于当前哪些hypervisor托管这些虚拟机,将物理hypervisor节点绑定到虚拟机是运行在适当的hypervisor上的OVN控制器执行的任务。这是一个discovered state的示例,即hypervisor发现虚拟机的位置并将其报告给数据库。因此,我们看到HV1(hypervisor 1)上的控制器已经报告到Chassis表中,基于IP地址10.0.0.10的Geneva封装就可以到达。同一个hypervisor也已经向Port_Binding表报告它托管了具有LP1的VM。
为了对数据平面进行编程,每个hypervisor的OVN controller查询OVN南向数据库,根据其当前托管的虚拟机识别与之相关的逻辑流,结合其他hypervisor提供的关于其他虚拟机位置的信息,就能够构造需要编程到相关hypervisor本地运行的OVS实例中的规则。(请注意,图49中显示的OVS实例包括图48中显示为OVS数据平面的所有组件。) 继续上面的示例,hypervisor 2需要在OVS中使用流规则将报文从LP2转发到LP1。通过查看OVN南向数据库中的Logical_Flows就能够做到这一点,并且能够确定如何封装数据包并使用Port_Binding和Chassis表中的信息将它们转发到正确的目标服务器的细节。在最下面的表中可以看到这两个hypervisor的结果,它不是南向数据库的一部分,而是在两个hypervisor上计算的流的整合。
OVN在线文档中可以找到更多关于OVN的详细信息,包括对北向和南向数据库结构的描述。
延伸阅读:
Open Virtual Network. OVN Reference Guide.
目前为止讨论的所有内容都假定我们的讨论是以虚拟机作为虚拟网络的端点,但是适用于虚拟机的所有内容也适用于容器(忽略某些实现细节)。我们可以将一组容器主机连接到OVN南向数据库,可以为它们的OVS实例创建流规则,为托管的容器构建虚拟网络。在这种情况下,OVN集成的"云管理系统"很可能是一个容器管理系统,比如Kubernetes。
8.5 微分段(Microsegmentation)
自Nicira的第一个产品问世以来,虚拟化无疑对网络产生了重要影响,尤其是在数据中心。思科和VMware都定期报告网络虚拟化的采用率,该技术现在在电信公司和大型企业数据中心中广泛应用。在大型云计算公司的数据中心中,它也无处不在,是将基础设施作为服务交付的重要组件。
网络虚拟化改变了数据中心实现安全性的方式,这是一个有趣的副作用。如上所述,网络虚拟化使安全特性能够在软件中以分布式的方式实现。与手工配置VLAN的传统方法相比,它还使创建大量隔离的网络变得相对简单。这两个因素结合起来就产生了微分段(microsegmentation) 的想法。
微分段与传统的网络隔离方法形成了鲜明对比,在传统方法中,相对规模较大的机器集将连接到一个"区域(zone)",然后通过防火墙过滤区域之间的流量。虽然这使得网络配置相对简单,但意味着许多机器将处于同一区域,即使它们之间并不需要通信。此外,随着时间的推移,需要添加越来越多的规则来描述怎样将流量从一个区域传输到另一个区域,防火墙规则的复杂性将会越来越高。
相比之下,网络虚拟化允许创建微分段,从而定义小范围虚拟网络,决定哪些机器可以彼此通信以及如何通信。例如,一个三层应用程序可以有自己的微分段策略,即应用程序面向web层的机器可以在一些指定的端口上与应用程序层的机器进行通信,但面向web层的机器可能不会相互通信。这是一个在过去很难实现的策略,因为所有面向网络的机器都位于同一网段上。
在微分段之前,配置段的复杂性使得许多应用程序的机器可能位于同一段上,从而为攻击从一个应用程序传播到另一个应用程序创造了机会。多年来,数据中心内的横向移动攻击一直被证明是成功的网络攻击的关键策略。
考虑图45中虚拟机和防火墙的配置。假设在没有网络虚拟化的情况下,我们想将VM A和VM B放在不同的段中,并对从VM A到VM B的流量应用防火墙规则,必须在物理网络中配置两个VLAN,将A连接到其中一个,将B连接到另一个,然后配置路由,使从第一个VLAN到第二个VLAN的路径通过防火墙。如果在某个时刻VM A被移动到另一个服务器,我们必须确保适当的VLAN到达该服务器,保持VM A和VLAN的连接,并确保路由配置仍然使流量通过防火墙。虽然这种情况有点做作,但说明了为什么在网络虚拟化到来之前,微分段实际上是不可能的。
微分段已经成为数据中心网络公认的最佳实践,为"零信任"网络提供了一个起点,说明了网络虚拟化的深远影响。
8.6 网络虚拟化是否是SDN?
在本章开始,我们观察到网络虚拟化是SDN最成功的早期应用。但它真的是SDN吗?关于这个话题有相当多的讨论,反映了关于SDN到底是什么存在大量争论。
反对将网络虚拟化纳入SDN的主要论点是,它没有改变构建物理网络的方式。它只是作为标准的L2/L3网络的overlay运行,后者可能运行分布式路由协议,并一次配置一个硬件。随着网络虚拟化变得如此普遍,这种观点似乎不那么流行了,但其实这种观点没有抓住重点。
简单来说,网络虚拟化遵循SDN发明者提出的核心架构原则(在第1.3节中进行了总结)。明确分离控制平面和数据平面,集中控制器负责一组分布式转发元素,甚至可以使用OpenFlow作为可能的控制接口,不过这只是实现细节,不是SDN的基础。最后,网络虚拟化使用完全可编程的转发平面(如OVS)这一事实也将其直接置于SDN领域中。
网络虚拟化和本书描述的其他用例之间的区别都可以被描述为实现选择,关键在于依赖于软件交换机而不是硬件交换机。这种基于软件交换机的实现加速了新技术的应用和部署,并为提供更强大的转发功能打开了大门(尽管代价是能够证明这些功能在运行时的性能和行为)。同样,这些基于软件的实现以一种为网络虚拟化优化的方式发展,而不是追求在第三章介绍的SDN软件栈中体现的通用的、与用例无关的方法。
这一切都不应该让人感到意外。SDN一直是一种构建和运维网络的方法,在特定领域内提供价值,并没有普遍性的要求。(请参阅第1章的控制域Domain of Control介绍。) 数据中心底层,例如叶脊交换网络就是这样一个领域,虚拟网络overlay是另一个这样的领域。甚至可以同时把两者都部署在相同的数据中心,而互相不会意识到对方的存在。展望未来,我们将会看到这两个领域会共享越来越多的机制(例如,公共的Network OS,公共的编写转发函数的语言,公共的生成控制接口的工具链)。观察两个域的分界线是否开始模糊也是一件有趣的事情,当overlay-aware underlay和underlay-aware overlay开始提供价值时,这种界限就会开始变得模糊。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
[1]Software-Defined Networks: A Systems Approach: https://sdn.systemsapproach.org/index.html
- END -本文由 mdnice 多平台发布