【yolov8系列】将yolov8-seg 模型部署到瑞芯微RK3566上
前言
之前记录过【yolov5系列】将模型部署到瑞芯微RK3566上,整体比较流畅,记录了onnx转rknn的相关环境配置,使用的rk版本为rknn-toolkit2-v1.4.0。当前官方库的版本已经更新为1.5,这里还是沿用1.4的版本进行记录。本篇博客是在上篇博客(yolov5的rk3566的部署)的基础上,记录下yolov8n-seg的模型在3566上的部署过程,原理得空再写。若转换后模型出现精度异常可查看官方提供文档 Rockchip_User_Guide_RKNN_Toolkit2_CN-1.4.0.pdf,写的比较详细。
【自己遇到的问题】
1) yolov8模型模型进行全量化结果异常
2) yolov8模型在PC端模拟器的运行结果正确,但板端运行结果异常
上述的问题也许不久就会被RK的工程师修复,但若其他的网络出现新的问题,我们是要有问题定位分析并解决的能力。接下来的篇章是自己逐步查找定位问题的一个过程,并在最后一章节附了完整的python相关代码,可正确导出yolov8-seg用于板端推理。
【对于yolov8的目标检测模型】
出现的问题与分割模型是一致的。从网络结构的实现上说,yolov8的实例分割任务,比目标检测任务多了一个语义的分支,且检测分支的channel通道发生变化,其他的结构基本一致。所以明白异常原因,即可同步解决yolov8其他任务的RK部署问题。
【模型量化时容易出现的问题】
1)平台有不支持的算子时,若算子没有可训练参数,可在导出模型前(不用重新训练),将其替换成其他等效功能的算子即可;若算子存在可训练参数,需要在训练前就使用其他算子替换,否则无法进行模型转换。
2)模型量化时,多多注意输出端的concat操作。当合并的数据处于不同的量级,此时该节点量化一定会出现异常。
1 RK模型在仿真器中的推理
1.1 工程代码详解
这里先给出yolov8-seg模型的onnx转rknn、已经仿真器模型的输出结果的后处理 的工程代码。这里转换的工程参考rknn中yolov5的转换,后处理参考yolov8的官方工程(RK还未提供yolov8的方案)。
其中:
- 【data文件夹】该文件夹存放着量化数据,这里使用一张图片作为示例。
- 【model文件夹】为了整齐,这里创建个文件夹用来存放需要转换的onnx模型,以及转换后的rknn模型。
- 【dataset.txt】文本内容为 量化时需要设置的量化图片路径的列表。可事先提供,可代码生成
- 【test.py】实现模型转换、仿真器推理的代码
- 【post.py】yolov8-seg模型输出的后处理代码
这里附上 test.py and post.py两个代码文件内容
## test.py import os import numpy as np import cv2 from rknn.api import RKNN import post as post import glob def makedirs(path): if not os.path.exists(path): os.makedirs(path) return path def gen_color(class_num): """随机生成掩码颜色, 用于可视化""" color_list = [] np.random.seed(1) while 1: a = list(map(int, np.random.choice(range(255),3))) if(np.sum(a)==0): continue color_list.append(a) if len(color_list)==class_num: break # for i in range(len(color_list)): # a = np.zeros((500,500,3))+color_list[i] # cv2.imwrite(f"./labelcolor/{i}_{self.index2name[i]}.png", a) return color_list def load_and_export_rknnmodel(ONNX_MODEL, RKNN_MODEL, OUT_NODE, QUANTIZE_ON, DATASET=None): """ rknn官方提供的onnx转rknn的代码, 并初始化仿真器运行环境 需要手动设置的是图片的均值mean_values 和方差std_values """ # Create RKNN object rknn = RKNN(verbose=True) # pre-process config print('--> Config model') rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]]) print('done') # Load ONNX model print('--> Loading model') ret = rknn.load_onnx(model=ONNX_MODEL, outputs=OUT_NODE) if ret != 0: print('Load model failed!') exit(ret) print('done') # Build model print('--> Building model') ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET) if ret != 0: print('Build model failed!') exit(ret) print('done') # Export RKNN model print('--> Export rknn model') ret = rknn.export_rknn(RKNN_MODEL) if ret != 0: print('Export rknn model failed!') exit(ret) print('done') # Init runtime environment print('--> Init runtime environment') ret = rknn.init_runtime() # ret = rknn.init_runtime('rk3566') if ret != 0: print('Init runtime environment failed!') exit(ret) print('done') return rknn def gene_dataset_txt(DATASET_path, savefile): """获取量化图片文件名的列表, 并保存成txt, 用于量化时设置""" file_data = glob.glob(os.path.join(DATASET_path,"*.jpg")) with open(savefile, "w") as f: for file in file_data: f.writelines(f"./{file}\n") def load_image(IMG_PATH, IMG_SIZE): """ 加载图片, 这里每个任务的预处理的规则可能不同, 只需要保证处理后的图片的尺寸和模型输入尺寸保持一致即可 return: image用于结果可视, img用于模型推理 """ image = cv2.imread(IMG_PATH) ##== # image = cv2.resize(image, (IMG_SIZE[1],IMG_SIZE[0],3)) ##== # image_ = np.zeros((IMG_SIZE[1],IMG_SIZE[0],3), dtype=image.dtype) # pad = (IMG_SIZE[1]-360)//2 # image_[pad:IMG_SIZE[1]-pad,:] = image # cv2.imwrite("data/test.jpg", image_) # image = image_ img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) return image, img def vis_result(image, results, colorlist, save_file): """将掩码信息+box信息画到原图上, 并将原图+masks图+可视化图 concat起来, 方便结果查看""" boxes, masks, shape = results vis_img = image.copy() mask_img = np.zeros_like(image) for box, mask in zip(boxes, masks): mask_img[mask!=0] = colorlist[int(box[-1])] ## cls=int(box[-1]) vis_img = vis_img*0.5 + mask_img*0.5 for box in boxes: cv2.rectangle(vis_img, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0,0,255),3,4) vis_img = np.concatenate([image, mask_img, vis_img],axis=1) cv2.imwrite(save_file, vis_img) if __name__ == '__main__': CLASSES = ["floor", "blanket","door_sill","obstacle"] ### 模型转换相关设置 ONNX_MODEL = './model/best_class4_384_640.onnx' RKNN_MODEL = './model/best_class4_384_640.rknn' DATASET = './dataset.txt' DATASET_PATH = 'data' QUANTIZE_ON = False # QUANTIZE_ON = True OUT_NODE = ["output0","output1"] ### 预测图片的设置 IMG_SIZE = [640, 384] ## 图片的wh IMG_PATH = './data/1664025163_1664064856_00164_001.jpg' ### 后处理的设置 save_PATH = makedirs('./result') OBJ_THRESH = 0.25 NMS_THRESH = 0.45 ### 开始实现==================================================== if QUANTIZE_ON: gene_dataset_txt(DATASET_PATH, DATASET) print('1---------------------------------------> export model') rknn = load_and_export_rknnmodel(ONNX_MODEL, RKNN_MODEL, OUT_NODE, QUANTIZE_ON, DATASET) print('2---------------------------------------> gene colorlist') colorlist = gen_color(len(CLASSES)) ## 获取着色时的颜色信息 print('3---------------------------------------> loading image') image, img = load_image(IMG_PATH, IMG_SIZE) print('4---------------------------------------> Running model') outputs = rknn.inference(inputs=[img]) print('5---------------------------------------> postprocess') ## ============模型输出后的后处理。从yolov8源码中摘取后用numpy库代替了pytorch库 im = np.transpose(img[np.newaxis],[0,3,1,2]) results = post.postprocess(outputs, im, img, OBJ_THRESH, NMS_THRESH, classes=len(CLASSES)) ##[box,mask,shape] results = results[0] ## batch=1,取第一个数据即可 print('6---------------------------------------> save result') save_file = os.path.join(save_PATH, os.path.basename(IMG_PATH)) vis_result(image, results, colorlist, save_file) print()## post.py import time import numpy as np import cv2 def xywh2xyxy(x): y = np.copy(x) y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y return y def clip_boxes(boxes, shape): boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2 boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2 def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None): if ratio_pad is None: # calculate from img0_shape gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding else: gain = ratio_pad[0][0] pad = ratio_pad[1] boxes[..., [0, 2]] -= pad[0] # x padding boxes[..., [1, 3]] -= pad[1] # y padding boxes[..., :4] /= gain clip_boxes(boxes, img0_shape) return boxes def crop_mask(masks, boxes): n, h, w = masks.shape x1, y1, x2, y2 = np.split(boxes[:, :, None], 4, axis=1) r = np.arange(w, dtype=np.float32)[None, None, :] # rows shape(1,w,1) c = np.arange(h, dtype=np.float32)[None, :, None] # cols shape(h,1,1) return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2)) def sigmoid(x): return 1.0/(1+np.exp(-x)) def process_mask(protos, masks_in, bboxes, shape): c, mh, mw = protos.shape # CHW ih, iw = shape masks = sigmoid(masks_in @ protos.reshape(c, -1)).reshape(-1, mh, mw) # CHW 【lulu】 downsampled_bboxes = bboxes.copy() downsampled_bboxes[:, 0] *= mw / iw downsampled_bboxes[:, 2] *= mw / iw downsampled_bboxes[:, 3] *= mh / ih downsampled_bboxes[:, 1] *= mh / ih masks = crop_mask(masks, downsampled_bboxes) # CHW masks = np.transpose(masks, [1,2,0]) # masks = cv2.resize(masks, (shape[1], shape[0]), interpolation=cv2.INTER_NEAREST) masks = cv2.resize(masks, (shape[1], shape[0]), interpolation=cv2.INTER_LINEAR) masks = np.transpose(masks, [2,0,1]) return np.where(masks>0.5,masks,0) def nms(bboxes, scores, threshold=0.5): x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 2] y2 = bboxes[:, 3] areas = (x2 - x1) * (y2 - y1) order = scores.argsort()[::-1] keep = [] while order.size > 0: i = order[0] keep.append(i) if order.size == 1: break xx1 = np.maximum(x1[i], x1[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) w = np.maximum(0.0, (xx2 - xx1)) h = np.maximum(0.0, (yy2 - yy1)) inter = w * h iou = inter / (areas[i] + areas[order[1:]] - inter) ids = np.where(iou <= threshold)[0] order = order[ids + 1] return keep def non_max_suppression( prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False, labels=(), max_det=300, nc=0, # number of classes (optional) ): # Checks assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0' assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0' #【lulu】prediction.shape[1]:box + cls + num_masks bs = prediction.shape[0] # batch size nc = nc or (prediction.shape[1] - 4) # number of classes nm = prediction.shape[1] - nc - 4 # num_masks mi = 4 + nc # mask start index xc = np.max(prediction[:, 4:mi], axis=1) > conf_thres ## 【lulu】 # Settings # min_wh = 2 # (pixels) minimum box width and height max_wh = 7680 # (pixels) maximum box width and height max_nms = 30000 # maximum number of boxes into torchvision.ops.nms() time_limit = 0.5 + 0.05 * bs # seconds to quit after redundant = True # require redundant detections multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img) merge = False # use merge-NMS t = time.time() output = [np.zeros((0,6 + nm))] * bs ## 【lulu】 for xi, x in enumerate(prediction): # image index, image inference # Apply constraints # x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height x = np.transpose(x,[1,0])[xc[xi]] ## 【lulu】 # If none remain process next image if not x.shape[0]: continue # Detections matrix nx6 (xyxy, conf, cls) box, cls, mask = np.split(x, [4, 4+nc], axis=1) ## 【lulu】 box = xywh2xyxy(box) # center_x, center_y, width, height) to (x1, y1, x2, y2) j = np.argmax(cls, axis=1) ## 【lulu】 conf = cls[np.array(range(j.shape[0])), j].reshape(-1,1) x = np.concatenate([box, conf, j.reshape(-1,1), mask], axis=1)[conf.reshape(-1,)>conf_thres] # Check shape n = x.shape[0] # number of boxes if not n: continue x = x[np.argsort(x[:, 4])[::-1][:max_nms]] # sort by confidence and remove excess boxes 【lulu】 # Batched NMS c = x[:, 5:6] * max_wh # classes ## 乘以的原因是将相同类别放置统一尺寸区间进行nms boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores i = nms(boxes, scores, iou_thres) ## 【lulu】 i = i[:max_det] # limit detections output[xi] = x[i] if (time.time() - t) > time_limit: # LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded') break # time limit exceeded return output def postprocess(preds, img, orig_img, OBJ_THRESH, NMS_THRESH, classes=None): """ len(preds)=2 preds[0].shape=(1,40,5040)。其中40=4(box)+4(cls)+32(num_masks), 32为原型系数。5040为3层输出featuremap的grid_ceil的总和。 preds[1].shape=(1, 32, 96, 160)。32为32个原型掩码。(96,160)为第三层的featuremap的尺寸。 总共需要3个步骤: 1. 对检测框, 也就是preds[0], 进行得分阈值、iou阈值筛选, 得到需要保留的框的信息, 以及对应的32为原型系数 2. 将每个检测框的原型系数乘以每个原型, 得到对应的类别的mask, 此时目标框和mask数量一一对应。然后使用每个检测框框自己对应的mask的featuremap, 框以外的有效mask删除, 得到最终的目标掩码 3. 将mask和框都恢复到原尺寸下 """ p = non_max_suppression(preds[0], OBJ_THRESH, NMS_THRESH, agnostic=False, max_det=300, nc=classes, classes=None) results = [] proto = preds[1] for i, pred in enumerate(p): shape = orig_img.shape if not len(pred): results.append([[], [], []]) # save empty boxes continue masks = process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:]) # HWC pred[:, :4] = scale_boxes(img.shape[2:], pred[:, :4], shape).round() results.append([pred[:, :6], masks, shape[:2]]) return results def make_anchors(feats_shape, strides, grid_cell_offset=0.5): """Generate anchors from features.""" anchor_points, stride_tensor = [], [] assert feats_shape is not None dtype_ = np.float for i, stride in enumerate(strides): _, _, h, w = feats_shape[i] sx = np.arange(w, dtype=dtype_) + grid_cell_offset # shift x sy = np.arange(h, dtype=dtype_) + grid_cell_offset # shift y sy, sx = np.meshgrid(sy, sx, indexing='ij') anchor_points.append(np.stack((sx, sy), -1).reshape(-1, 2)) stride_tensor.append(np.full((h * w, 1), stride, dtype=dtype_)) return np.concatenate(anchor_points), np.concatenate(stride_tensor) def dist2bbox(distance, anchor_points, xywh=True, dim=-1): """Transform distance(ltrb) to box(xywh or xyxy).""" lt, rb = np.split(distance, 2, dim) x1y1 = anchor_points - lt x2y2 = anchor_points + rb if xywh: c_xy = (x1y1 + x2y2) / 2 wh = x2y2 - x1y1 return np.concatenate((c_xy, wh), dim) # xywh bbox return np.concatenate((x1y1, x2y2), dim) # xyxy bbox
1.2 RK浮点模型在仿真器上的推理
当量化模型结果异常时,先确认浮点模型在仿真器上的运行结果是正常的。
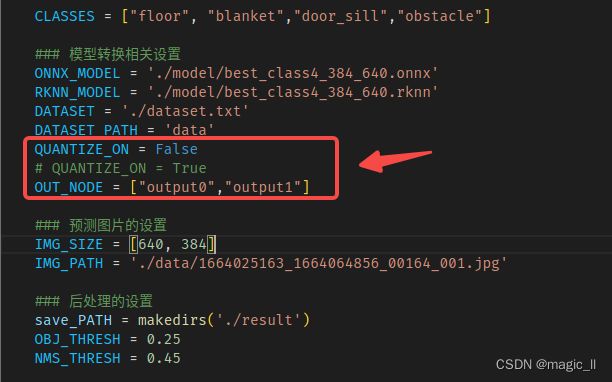
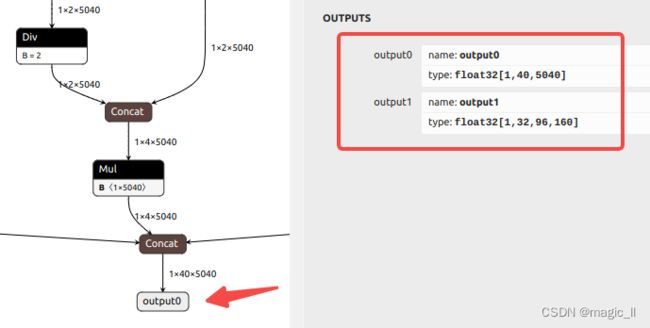
将代码中这些设置修改成与自己模型任务相一致后,将QUANTIZE_ON 设置False即可运行。输出节点的命名,可使用netron打开onnx模型。
运行python test.py后
1.3 RK量化模型在仿真器上的推理
- 将
QUANTIZE_ON = True即可- 运行
python test.py,没有任何检出结果。接下来我们要开始查找原因。
1.4 使用RK提供的精度分析脚本
接下来进行精度分析,rknn提供了精度分析的脚本accuracy_analysis。这里适配自己的工程,修改其模型路径等设置,代码实现如下
import os import sys import numpy as np import cv2 import time from rknn.api import RKNN import post as post import glob def makedirs(path): if not os.path.exists(path): os.makedirs(path) return path def show_outputs(outputs): output = outputs output_sorted = sorted(output, reverse=True) top5_str = 'resnet50v2\n-----TOP 5-----\n' for i in range(5): value = output_sorted[i] index = np.where(output == value) for j in range(len(index)): if (i + j) >= 5: break if value > 0: topi = '{}: {}\n'.format(index[j], value) else: topi = '-1: 0.0\n' top5_str += topi print(top5_str) def readable_speed(speed): speed_bytes = float(speed) speed_kbytes = speed_bytes / 1024 if speed_kbytes > 1024: speed_mbytes = speed_kbytes / 1024 if speed_mbytes > 1024: speed_gbytes = speed_mbytes / 1024 return "{:.2f} GB/s".format(speed_gbytes) else: return "{:.2f} MB/s".format(speed_mbytes) else: return "{:.2f} KB/s".format(speed_kbytes) def show_progress(blocknum, blocksize, totalsize): speed = (blocknum * blocksize) / (time.time() - start_time) speed_str = " Speed: {}".format(readable_speed(speed)) recv_size = blocknum * blocksize f = sys.stdout progress = (recv_size / totalsize) progress_str = "{:.2f}%".format(progress * 100) n = round(progress * 50) s = ('#' * n).ljust(50, '-') f.write(progress_str.ljust(8, ' ') + '[' + s + ']' + speed_str) f.flush() f.write('\r\n') def accuracy_analysis(ONNX_MODEL, OUT_NODE, QUANTIZE_ON, DATASET=None): """ rknn官方提供的onnx转rknn的代码, 并初始化仿真器运行环境 需要手动设置的是图片的均值mean_values 和方差std_values """ # Create RKNN object rknn = RKNN(verbose=True) # pre-process config print('--> Config model') rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]]) print('done') # Load ONNX model print('--> Loading model') ret = rknn.load_onnx(model=ONNX_MODEL, outputs=OUT_NODE) if ret != 0: print('Load model failed!') exit(ret) print('done') # Build model print('--> Building model') ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET) if ret != 0: print('Build model failed!') exit(ret) print('done') # Accuracy analysis print('--> Accuracy analysis') ret = rknn.accuracy_analysis(inputs=["./data/1664025163_1664064856_00164_001.jpg"], output_dir='./snapshot') if ret != 0: print('Accuracy analysis failed!') exit(ret) print('done') print('float32:') output = np.genfromtxt('./snapshot/golden/output0.txt') show_outputs(output) print('quantized:') output = np.genfromtxt('./snapshot/simulator/output0.txt') show_outputs(output) return rknn def gene_dataset_txt(DATASET_path, savefile): """获取量化图片文件名的列表, 并保存成txt, 用于量化时设置""" file_data = glob.glob(os.path.join(DATASET_path,"*.jpg")) with open(savefile, "w") as f: for file in file_data: f.writelines(f"./{file}\n") if __name__ == '__main__': CLASSES = ["floor", "blanket","door_sill","obstacle"] ### 模型转换相关设置 ONNX_MODEL = './model/best_class4_384_640.onnx' RKNN_MODEL = './model/best_class4_384_640.rknn' DATASET = './dataset.txt' DATASET_PATH = 'data' # QUANTIZE_ON = False QUANTIZE_ON = True OUT_NODE = ["output0","output1"] ### 开始实现==================================================== if QUANTIZE_ON: gene_dataset_txt(DATASET_PATH, DATASET) print('1---------------------------------------> accuracy_analysis') rknn = accuracy_analysis(ONNX_MODEL, OUT_NODE, QUANTIZE_ON, DATASET)
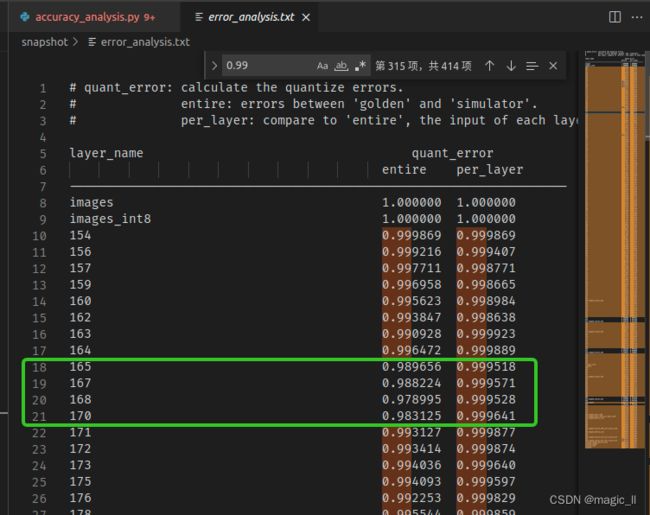
运行python accuracy_analysis.py后,在【./snapshot/error_analysis.txt】文本中保存着浮点模型和量化模型的每层结果的余弦距离。但查看结果,从一开始就存在较多的小于0.98的余弦距离,如下图。所以在yolov8的模型,不敢相信RK的精度分析方式。
然后在跟RK方工程师沟通后,逐步发现问题:对于yolov8最后那个concat,我们查看concat前的三个节点输出数据范围,发现其中一个在0 ~1之间,另外一个在0 ~600+。
- 两者相加后依然是600+,此时对比浮点模型和量化模型的该节点的输出的余弦距离,不能反应出问题。
- 但存在输入数据范围差距时,量化时就会出现异常结果。
1.5 量化模型结果异常的解决
当我们分析出最后一层concat的量化存在异常,解决方式有两种:
- 混合量化 (本篇不做延伸)
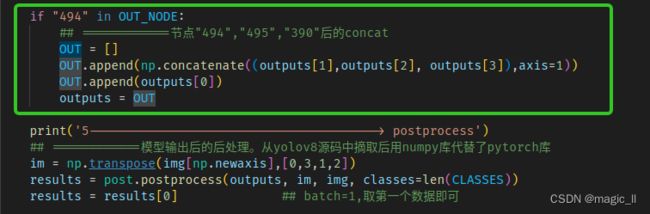
- 将输出端存在异常的节点(这里是最后一个concat),放在后处理中实现
对于第二种方式:
重新设置输出节点,并修改量化为True
这里需要主要下,对于rknn-toolkit2-v1.4.0,设置四个输出节点,量化后的节点顺序与自己设置的顺序不对齐。但在rknn-toolkit2-v1.5.0 中修复了这个问题。所以在获取模型的4个输出,后concat时的顺序要多多留意。
运行结果如下:







2 板端运行结果
rknn的C++实现还未提供yolov8的后处理工程。自己暂不能测完整的板端推理,为了验证输出是否正确,这里将端侧推理的输出直接保存成txt文本,然后使用前面的python工程读取,然后后处理看结果是否正确。
工程的来源与运行在【yolov5系列】将模型部署到瑞芯微RK3566上 中记录过。这里在这个工程中进行修改和添加。修改内容如下:
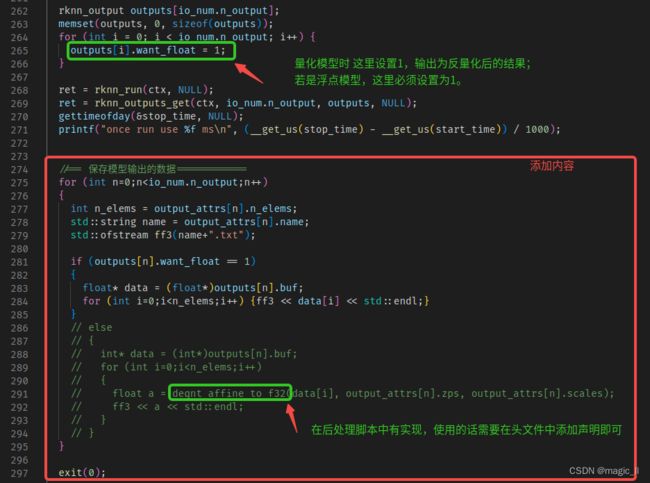
- 对于
outputs[i].want_float的设置,浮点模型必须将其设置为1;量化模型设置为1时,模型输出的反量化后的数据,设置为0时输出的是量化后的数据。- 增加保存输出数据到txt的代码实现。
2.1 浮点模型在板端运行
首先测试浮点模型在板端的推理,看输出是否正常。
转换模型时将节点为
OUT_NODE = ["output0","output1"]。
先将转换后的模型推至板端运行,得到 output0.txt、output1.txt。然后在python工程中,加载 output0.txt、output1.txt,运行得到结果。最终得到结果如下:
观察结果发现,貌似掩码信息的分布是正确的,那我们就使用仿真器的预测结果和板端的预测结果交叉组合,最终发现板端预测结果中box是有问题的,其他是正常的。
然后我们使用仿真器预测的box,使用板端预测的其他信息,然后结果如下:
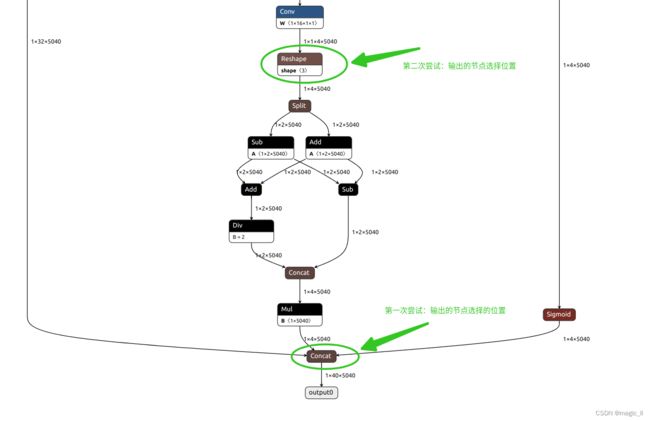
接下来就要定位出问题的节点,该节点一定在box的输出分支中
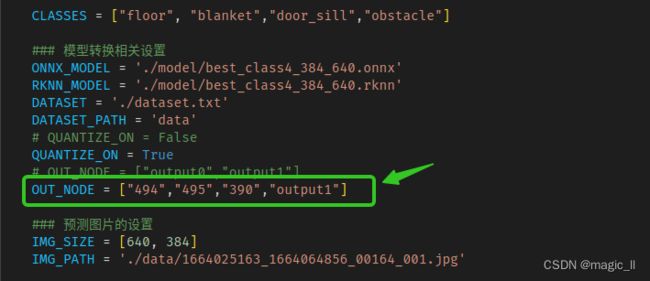
第一次尝试:OUT_NODE = ["494","495","390","output1"]
第二次尝试:OUT_NODE = ["480","495","390","output1"]
在第二次尝试的输出节点转换的模型,板端推理的结果+手动实现节点到输出的结构,最终得到正确的结果(这里不附图了,结果与python仿真器结果一致)。说明RKNN板端运行出错的问题在如下的结构中。至于为什么会有问题,已经向RKNN的工程师提出问题,后面补充原因。
2.1 量化模型在板端运行
与浮点模型的问题表现完全一致。


3 附 完整的代码
## test.py import os import numpy as np import cv2 from rknn.api import RKNN import post as post import glob def makedirs(path): if not os.path.exists(path): os.makedirs(path) return path def gen_color(class_num): """随机生成掩码颜色, 用于可视化""" color_list = [] np.random.seed(1) while 1: a = list(map(int, np.random.choice(range(255),3))) if(np.sum(a)==0): continue color_list.append(a) if len(color_list)==class_num: break # for i in range(len(color_list)): # a = np.zeros((500,500,3))+color_list[i] # cv2.imwrite(f"./labelcolor/{i}_{self.index2name[i]}.png", a) return color_list def load_and_export_rknnmodel(ONNX_MODEL, RKNN_MODEL, OUT_NODE, QUANTIZE_ON, DATASET=None): """ rknn官方提供的onnx转rknn的代码, 并初始化仿真器运行环境 需要手动设置的是图片的均值mean_values 和方差std_values """ # Create RKNN object rknn = RKNN(verbose=True) # pre-process config print('--> Config model') rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]]) print('done') # Load ONNX model print('--> Loading model') ret = rknn.load_onnx(model=ONNX_MODEL, outputs=OUT_NODE) if ret != 0: print('Load model failed!') exit(ret) print('done') # Build model print('--> Building model') ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET) if ret != 0: print('Build model failed!') exit(ret) print('done') # Export RKNN model print('--> Export rknn model') ret = rknn.export_rknn(RKNN_MODEL) if ret != 0: print('Export rknn model failed!') exit(ret) print('done') # Init runtime environment print('--> Init runtime environment') ret = rknn.init_runtime() # ret = rknn.init_runtime('rk3566') if ret != 0: print('Init runtime environment failed!') exit(ret) print('done') return rknn def gene_dataset_txt(DATASET_path, savefile): """获取量化图片文件名的列表, 并保存成txt, 用于量化时设置""" file_data = glob.glob(os.path.join(DATASET_path,"*.jpg")) with open(savefile, "w") as f: for file in file_data: f.writelines(f"./{file}\n") def load_image(IMG_PATH, IMG_SIZE): """ 加载图片, 这里每个任务的预处理的规则可能不同, 只需要保证处理后的图片的尺寸和模型输入尺寸保持一致即可 return: image用于结果可视, img用于模型推理 """ image = cv2.imread(IMG_PATH) ##== # image = cv2.resize(image, (IMG_SIZE[1],IMG_SIZE[0],3)) ##== # image_ = np.zeros((IMG_SIZE[1],IMG_SIZE[0],3), dtype=image.dtype) # pad = (IMG_SIZE[1]-360)//2 # image_[pad:IMG_SIZE[1]-pad,:] = image # cv2.imwrite("data/test.jpg", image_) # image = image_ img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) return image, img def run_model_cut(outputs, OUT_NODE): """480节点后的python的实现""" if "480" in OUT_NODE: ## ============节点480-->494中间的解析 a0 = outputs[1] stride = [8,16,32] x_shape = [] for i in stride: x_shape.append([1,68,384//i,640//i]) anchors, strides = (np.transpose(x, (1,0)) for x in post.make_anchors(x_shape, stride, 0.5)) dbox = post.dist2bbox(a0, anchors[np.newaxis], xywh=True, dim=1) * strides outputs[1] = dbox ## ============节点"494","495","390"后的concat OUT = [] OUT.append(np.concatenate((outputs[1],outputs[2], outputs[3]),axis=1)) OUT.append(outputs[0]) outputs = OUT if "494" in OUT_NODE: ## ============节点"494","495","390"后的concat OUT = [] OUT.append(np.concatenate((outputs[1],outputs[2], outputs[3]),axis=1)) OUT.append(outputs[0]) outputs = OUT return outputs def vis_result(image, results, colorlist, save_file): """将掩码信息+box信息画到原图上, 并将原图+masks图+可视化图 concat起来, 方便结果查看""" boxes, masks, shape = results vis_img = image.copy() mask_img = np.zeros_like(image) for box, mask in zip(boxes, masks): mask_img[mask!=0] = colorlist[int(box[-1])] ## cls=int(box[-1]) vis_img = vis_img*0.5 + mask_img*0.5 for box in boxes: cv2.rectangle(vis_img, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0,0,255),3,4) vis_img = np.concatenate([image, mask_img, vis_img],axis=1) cv2.imwrite(save_file, vis_img) def load_RK3566_output(path, OUT_NODE): if "output0" in OUT_NODE: output0 = np.loadtxt(os.path.join(path, "output0.txt")).reshape((1, 40, 5040)) output1 = np.loadtxt(os.path.join(path, "output1.txt")).reshape((1, 32, 96, 160)) return (output0, output1) if "480" in OUT_NODE: node_480 = np.loadtxt(os.path.join(path, "480.txt")).reshape((1, 4, 5040)) node_495 = np.loadtxt(os.path.join(path, "495.txt")).reshape((1, 4, 5040)) node_390 = np.loadtxt(os.path.join(path, "390.txt")).reshape((1, 32, 5040)) output1 = np.loadtxt(os.path.join(path, "output1.txt")).reshape((1, 32, 96, 160)) return (node_480, node_495, node_390, output1) if "494" in OUT_NODE: node_494 = np.loadtxt(os.path.join(path, "494.txt")).reshape((1, 4, 5040)) node_495 = np.loadtxt(os.path.join(path, "495.txt")).reshape((1, 4, 5040)) node_390 = np.loadtxt(os.path.join(path, "390.txt")).reshape((1, 32, 5040)) output1 = np.loadtxt(os.path.join(path, "output1.txt")).reshape((1, 32, 96, 160)) return (node_494, node_495, node_390, output1) if __name__ == '__main__': CLASSES = ["floor", "blanket","door_sill","obstacle"] ### 模型转换相关设置 ONNX_MODEL = './model/best_class4_384_640.onnx' RKNN_MODEL = './model/best_class4_384_640.rknn' DATASET = './dataset.txt' DATASET_PATH = 'data' # QUANTIZE_ON = False QUANTIZE_ON = True # OUT_NODE = ["output0","output1"] # OUT_NODE = ["494","495","390","output1"] OUT_NODE = ["480","495","390","output1"] ### 预测图片的设置 IMG_SIZE = [640, 384] IMG_PATH = './data/1664025163_1664064856_00164_001.jpg' ### 后处理的设置 save_PATH = makedirs('./result') OBJ_THRESH = 0.25 NMS_THRESH = 0.45 ### 开始实现==================================================== if QUANTIZE_ON: gene_dataset_txt(DATASET_PATH, DATASET) print('1---------------------------------------> export model') rknn = load_and_export_rknnmodel(ONNX_MODEL, RKNN_MODEL, OUT_NODE, QUANTIZE_ON, DATASET) print('2---------------------------------------> gene colorlist') colorlist = gen_color(len(CLASSES)) ## 获取着色时的颜色信息 print('3---------------------------------------> loading image') image, img = load_image(IMG_PATH, IMG_SIZE) print('4---------------------------------------> Running model') outputs = rknn.inference(inputs=[img]) # outputs_rk3566 = load_RK3566_output("./RK3566", OUT_NODE) outputs = run_model_cut(outputs, OUT_NODE) print('5---------------------------------------> postprocess') ## ============模型输出后的后处理。从yolov8源码中摘取后用numpy库代替了pytorch库 im = np.transpose(img[np.newaxis],[0,3,1,2]) results = post.postprocess(outputs, im, img, OBJ_THRESH, NMS_THRESH, classes=len(CLASSES)) results = results[0] ## batch=1,取第一个数据即可 print('6---------------------------------------> save result') save_file = os.path.join(save_PATH, os.path.basename(IMG_PATH)) vis_result(image, results, colorlist, save_file) print()## post.py import time import numpy as np import cv2 def xywh2xyxy(x): y = np.copy(x) y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y return y def clip_boxes(boxes, shape): boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2 boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2 def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None): if ratio_pad is None: # calculate from img0_shape gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding else: gain = ratio_pad[0][0] pad = ratio_pad[1] boxes[..., [0, 2]] -= pad[0] # x padding boxes[..., [1, 3]] -= pad[1] # y padding boxes[..., :4] /= gain clip_boxes(boxes, img0_shape) return boxes def crop_mask(masks, boxes): n, h, w = masks.shape x1, y1, x2, y2 = np.split(boxes[:, :, None], 4, axis=1) r = np.arange(w, dtype=np.float32)[None, None, :] # rows shape(1,w,1) c = np.arange(h, dtype=np.float32)[None, :, None] # cols shape(h,1,1) return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2)) def sigmoid(x): return 1.0/(1+np.exp(-x)) def process_mask(protos, masks_in, bboxes, shape): c, mh, mw = protos.shape # CHW ih, iw = shape masks = sigmoid(masks_in @ protos.reshape(c, -1)).reshape(-1, mh, mw) # CHW 【lulu】 downsampled_bboxes = bboxes.copy() downsampled_bboxes[:, 0] *= mw / iw downsampled_bboxes[:, 2] *= mw / iw downsampled_bboxes[:, 3] *= mh / ih downsampled_bboxes[:, 1] *= mh / ih masks = crop_mask(masks, downsampled_bboxes) # CHW masks = np.transpose(masks, [1,2,0]) # masks = cv2.resize(masks, (shape[1], shape[0]), interpolation=cv2.INTER_NEAREST) masks = cv2.resize(masks, (shape[1], shape[0]), interpolation=cv2.INTER_LINEAR) masks = np.transpose(masks, [2,0,1]) return np.where(masks>0.5,masks,0) def nms(bboxes, scores, threshold=0.5): x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 2] y2 = bboxes[:, 3] areas = (x2 - x1) * (y2 - y1) order = scores.argsort()[::-1] keep = [] while order.size > 0: i = order[0] keep.append(i) if order.size == 1: break xx1 = np.maximum(x1[i], x1[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) w = np.maximum(0.0, (xx2 - xx1)) h = np.maximum(0.0, (yy2 - yy1)) inter = w * h iou = inter / (areas[i] + areas[order[1:]] - inter) ids = np.where(iou <= threshold)[0] order = order[ids + 1] return keep def non_max_suppression( prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False, labels=(), max_det=300, nc=0, # number of classes (optional) ): # Checks assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0' assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0' #【lulu】prediction.shape[1]:box + cls + num_masks bs = prediction.shape[0] # batch size nc = nc or (prediction.shape[1] - 4) # number of classes nm = prediction.shape[1] - nc - 4 # num_masks mi = 4 + nc # mask start index xc = np.max(prediction[:, 4:mi], axis=1) > conf_thres ## 【lulu】 # Settings # min_wh = 2 # (pixels) minimum box width and height max_wh = 7680 # (pixels) maximum box width and height max_nms = 30000 # maximum number of boxes into torchvision.ops.nms() time_limit = 0.5 + 0.05 * bs # seconds to quit after redundant = True # require redundant detections multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img) merge = False # use merge-NMS t = time.time() output = [np.zeros((0,6 + nm))] * bs ## 【lulu】 for xi, x in enumerate(prediction): # image index, image inference # Apply constraints # x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height x = np.transpose(x,[1,0])[xc[xi]] ## 【lulu】 # If none remain process next image if not x.shape[0]: continue # Detections matrix nx6 (xyxy, conf, cls) box, cls, mask = np.split(x, [4, 4+nc], axis=1) ## 【lulu】 box = xywh2xyxy(box) # center_x, center_y, width, height) to (x1, y1, x2, y2) j = np.argmax(cls, axis=1) ## 【lulu】 conf = cls[np.array(range(j.shape[0])), j].reshape(-1,1) x = np.concatenate([box, conf, j.reshape(-1,1), mask], axis=1)[conf.reshape(-1,)>conf_thres] # Check shape n = x.shape[0] # number of boxes if not n: continue x = x[np.argsort(x[:, 4])[::-1][:max_nms]] # sort by confidence and remove excess boxes 【lulu】 # Batched NMS c = x[:, 5:6] * max_wh # classes ## 乘以的原因是将相同类别放置统一尺寸区间进行nms boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores i = nms(boxes, scores, iou_thres) ## 【lulu】 i = i[:max_det] # limit detections output[xi] = x[i] if (time.time() - t) > time_limit: # LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded') break # time limit exceeded return output def postprocess(preds, img, orig_img, OBJ_THRESH, NMS_THRESH, classes=None): """ len(preds)=2 preds[0].shape=(1,40,5040)。其中40=4(box)+4(cls)+32(num_masks), 32为原型系数。5040为3层输出featuremap的grid_ceil的总和。 preds[1].shape=(1, 32, 96, 160)。32为32个原型掩码。(96,160)为第三层的featuremap的尺寸。 总共需要3个步骤: 1. 对检测框, 也就是preds[0], 进行得分阈值、iou阈值筛选, 得到需要保留的框的信息, 以及对应的32为原型系数 2. 将每个检测框的原型系数乘以每个原型, 得到对应的类别的mask, 此时目标框和mask数量一一对应。然后使用每个检测框框自己对应的mask的featuremap, 框以外的有效mask删除, 得到最终的目标掩码 3. 将mask和框都恢复到原尺寸下 """ p = non_max_suppression(preds[0], OBJ_THRESH, NMS_THRESH, agnostic=False, max_det=300, nc=classes, classes=None) results = [] proto = preds[1] for i, pred in enumerate(p): shape = orig_img.shape if not len(pred): results.append([[], [], []]) # save empty boxes continue masks = process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:]) # HWC pred[:, :4] = scale_boxes(img.shape[2:], pred[:, :4], shape).round() results.append([pred[:, :6], masks, shape[:2]]) return results def make_anchors(feats_shape, strides, grid_cell_offset=0.5): """Generate anchors from features.""" anchor_points, stride_tensor = [], [] assert feats_shape is not None dtype_ = np.float for i, stride in enumerate(strides): _, _, h, w = feats_shape[i] sx = np.arange(w, dtype=dtype_) + grid_cell_offset # shift x sy = np.arange(h, dtype=dtype_) + grid_cell_offset # shift y sy, sx = np.meshgrid(sy, sx, indexing='ij') anchor_points.append(np.stack((sx, sy), -1).reshape(-1, 2)) stride_tensor.append(np.full((h * w, 1), stride, dtype=dtype_)) return np.concatenate(anchor_points), np.concatenate(stride_tensor) def dist2bbox(distance, anchor_points, xywh=True, dim=-1): """Transform distance(ltrb) to box(xywh or xyxy).""" lt, rb = np.split(distance, 2, dim) x1y1 = anchor_points - lt x2y2 = anchor_points + rb if xywh: c_xy = (x1y1 + x2y2) / 2 wh = x2y2 - x1y1 return np.concatenate((c_xy, wh), dim) # xywh bbox return np.concatenate((x1y1, x2y2), dim) # xyxy bbox