Python内置函数系统学习(1)——数据转换与计算 (详细语法参考+参数说明+应用场景示例) 对象--->>字符串、字符--->>ASACII码 综合应用
世界上最重要的东西就是纸,重至承载文明的崛起,轻至承载一个饱满厚实的人生。

作者主页: 追光者♂
个人简介:
[1] 计算机专业硕士研究生
[2] 2022年度博客之星人工智能领域TOP4
[3] 阿里云社区特邀专家博主
[4] CSDN-人工智能领域优质创作者
[5] 预期2023年10月份 · 准CSDN博客专家
- 无限进步,一起追光!!!
感谢大家 点赞 收藏⭐ 留言!!!
本篇分享Python内置的数据转换与计算函数,本篇内容较多,这是Python常用的内置函数中基础内容,希望初次看的小伙伴儿可以耐着性子看下去,建议最好跟随练习哦!这也是关于数据转换与计算/人工智能基础/机器学习基础(Python内置函数)的一篇文章,虽然较为基础,但是综合起来对于后面理解和学习机器学习&深度学习来说是很重要的!让我们一起学习吧!祝大家学习顺利!
目录
- 一、整数 ---->> 八进制
-
- 1.1 语法参考 & 参数说明
- 1.2 示例
-
- 1.2.1 将整数转换为八进制字符串形式
- 1.2.2 输出十进制数字的八进制字符串形式
- 1.3 应用场景:实现键盘字符八进制对照表
- 1.4 补充(快速理解)
- 二、字符 ---->> ASCII码
-
- 2.1 语法参考、参数说明
- 2.2 示例
-
- 2.2.1 将字符转换为相应的整数
- 2.2.2 大小写字母转换
- 2.3 应用:判断用户输入的字符是否为数字
- 三、对象 ---->> 字符串
-
- 3.1 语法参考 & 参数说明
- 3.2 示例
-
- 3.2.1 将数值型数据转换为字符串
- 3.2.2 将列表转换为字符串
- 3.2.3 将元组转换为字符串并去掉特殊符号
- 3.2.4 将字典转换为字符串
- 3.2.5 将集合转换为字符串
- 3.2.6 将字节类型(bytes对象)转换为字符串
- 3.2.7 字符串与数值型数据混合输出
- 四、求绝对值
-
- 4.1 语法参考 and 参数说明、
- 4.2 示例
-
- 4.2.1 获取整数与浮点数的绝对值
- 4.2.2 获取复数的模
- 4.2.3 获取可迭代对象中数字的绝对值
- 五、求商和余数
-
- 5.1 语法参考 & 参数说明
- 5.2 示例
-
- 5.2.1 获取商和余数的元组
- 5.3 小案例——循环获取 递减被除数的商和余数
- 5.4 应用场景:诗句分段计算
- 六、求最大值
-
- 6.1 语法参考 and 参数说明
- 6.2 示例
-
- 6.2.1 在字符、数字、标点及汉字中 取最大值
- 6.2.2 几个补充示例
- 6.2.3 在列表中使用max
一、整数 ---->> 八进制
1.1 语法参考 & 参数说明
语法参考:
oct()函数用于将整数转换为前缀以0o开头的八进制字符串形式,oct()函数的语法格式如下:
oct(x)
参数说明:
- x:要转换的整数;
- 返回值:返回前缀以0o开头的八进制字符串形式。
1.2 示例
1.2.1 将整数转换为八进制字符串形式
# 昵 称:XieXu
# 时 间: 2023/3/21/0021 20:13
# 将整数转换为八进制字符串形式
# 输出对应的八进制字符串形式
print(oct(55)) # 0o67
print(oct(77)) # 0o115
print(oct(-21)) # -0o25
1.2.2 输出十进制数字的八进制字符串形式
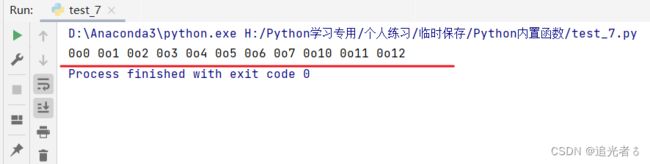
输出0~10的八进制字符串形式:
# 输出十进制数字的八进制字符串形式
i = 0 # 变量i初始化为0
while i < 11: # while循环条件
print(oct(i), end=" ") # 使用cot()函数将变量i转换为八进制输出
i += 1 # 变量i自增
运行后,可以看到如下结果:
1.3 应用场景:实现键盘字符八进制对照表
实现的代码如下:
# 实现键盘字符八进制对照表
import binascii # 导入binascii模块
def contrast8(mystr):
val16 = binascii.hexlify(mystr.encode('gbk'))
val10 = int(val16.upper(), 16)
val8 = oct(val10)
return val8
# 接收用户输入的字符,返回该字符对应的八进制形式
while 1:
mystr1 = input("请输入一个有效的字符:") # 提示输入一个有效的字符
print(contrast8(mystr1))
来看测试:

大家也可以自己试试哦~
1.4 补充(快速理解)
在Python中,我们可以使用oct()函数将整数转换为八进制。oct()函数接受一个整数作为参数,并返回其对应的八进制表示形式的字符串。
下面是一个简单的示例:
num = 42
oct_num = oct(num)
print(oct_num) # 输出:0o52
在上面的代码中,我们将整数42转换为八进制表示形式。oct()函数返回的结果是一个字符串,以0o开头,表示这是一个八进制数。在本例中,输出结果为0o52。
如果你希望去除前缀的0o,可以使用字符串的切片操作:
num = 42
oct_num = oct(num)[2:] # 去除前缀的0o
print(oct_num) # 输出:52
这样,我们就可以得到一个没有前缀的八进制数。
二、字符 ---->> ASCII码
2.1 语法参考、参数说明
语法参考:
ord()函数用于把一个字符串表示的Unicode字符转换为该字符相对应的整数。如ord(‘a’)返回整数97,ord(‘√’)返回整数8730。该函数与chr()函数的功能正好相反,ord()函数的语法格式如下:
ord(c )
参数说明:
- c:要转换的字符;
- 返回值:返回Unicode字符对应的整数数值。
2.2 示例
2.2.1 将字符转换为相应的整数
# 昵 称:XieXu
# 时 间: 2023/3/22/0022 9:55
# 将字符转换为相应的整数
# 返回相应的整数值
print(ord('A')) # 65
print(ord('z')) # 122
print(ord('我')) # 25105
print(ord('9')) # 57
print(ord('*')) # 42
print(ord('0')) # 48
print(ord('√')) # 8730
print(ord('②')) # 9313
2.2.2 大小写字母转换
首先通过ord()函数将输入的字母转换成ASCII码,然后其值减去32从小写变成大写,其值加上32从大写变成小写。
# 大小写字母转换
str = input("请输入字母:")
if str.islower() == True: # 判断该字母是否为小写
print(chr(ord(str) - 32)) # 先通过ord()函数转换成ASCII码,然后-32通过chr()函数将小写变成大写
else:
print(chr(ord(str) + 32)) # 先ord()函数转换成ASCII码,然后+32通过chr()函数将大写变成小写
下面来看几个测试:

由此可见:
- 当用户输入大写字母,该程序可将其转换为小写字母;
- 当用户输入小写字母,程序可将其转换为大写字母。
其中,
islower()函数可判断字符串的字符是否全为小写,若全为小写,则返回True。
关于Python字符串的更多详细方法,可参阅这篇文章:
【Python基础】字符串的基础操作:定义 || 统计 || 判断 || 查找和替换 || 大小写转换 || 文本对齐 || 去除空白字符 || 拆分和连接 || 字符串切片
2.3 应用:判断用户输入的字符是否为数字
来看具体code:
# 判断用户输入的字符是否为数字
def Validate_Is_Number(val): # 定义一个判断是否为数字的函数
getASCII = ord(val) # 将字符转换为对应的字符
if getASCII >= 48 and getASCII <= 57: # 判断是否为数字
return True
else:
return False
# 接收用户输入,判断是否为整型数字
while 1:
getnum = input("请输入一个有效的数字(0~9):")
Is_Number = Validate_Is_Number(getnum)
if Is_Number:
print("您输入的是数字:", getnum)
else:
print("您输入了非法字符,这里只能输入数字!")
先来看正确的几个测试:
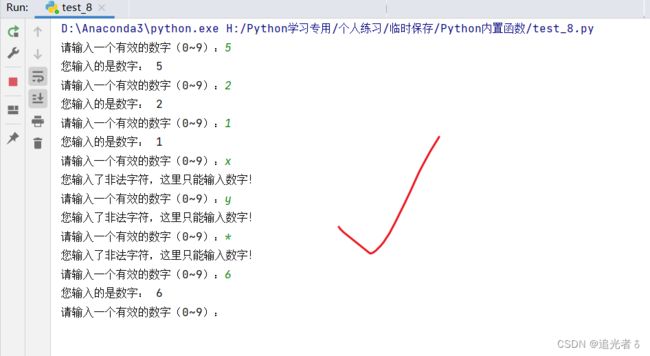
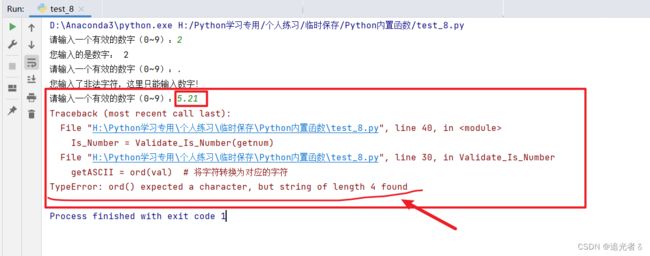
错误的测试(1),当输入多个数字时:TypeError: ord() expected a character, but string of length 2 found,即 TypeError: ord() 预计是一个字符,但发现长度为2的字符串

错误的测试(2),也是因为输入的长度多于1:
三、对象 ---->> 字符串
3.1 语法参考 & 参数说明
语法参考:
str()函数用于将整数、浮点数、列表、元组、字典和集合转换为字符串类型。str()函数的语法格式如下:
str(object)
参数说明:
- object:表示被转换成字符串的参数,该参数可以省略;
- 返回值:返回一个object(对象)的字符串形式。
注:当str()函数的
参数都省略时,该函数将返回空字符串,这种情况常用来创建空字符串或者初始化字符串变量。
此外,str()函数还可以将字节类型转换为字符串类型,语法格式略有不同。其语法格式如下:
str(object=b’', encoding=‘utf-8’, errors=‘strict’)
关于上述的参数说明:
-
object=b’':表示要进行转换的字节型(bytes)数据;
-
encoding:表示进行转换时所采用的编码方式,默认为utf-8;
-
errors:表示错误处理方式(报错级别)。常见的报错级别有:
-
[1]
?'strict':严格级别,字符编码有报错即抛出异常,默认级别,errors参数值传入None即按此级别处理。 -
[2]
?'ignore':忽略级别,字符编码有错,忽略掉。 -
[3]
?'replace':替换级别,字符编码有错的,替换成?。
补充说明:
str()函数返回一个字符串对象。若object不提供,则默认返回空字符串,否则,str()函数的行为依赖于encoding参数或者errors参数是否提供:
- (1)encoding参数和errors参数都不提供,str()函数返回object的字符串描述,就是它本身。
- (2)encoding参数和errors参数其中有一个被提供,str()函数返回object的字符串形式。
3.2 示例
3.2.1 将数值型数据转换为字符串
使用str()函数将如下数值型数据转换为字符串的形式,代码如下:
# 昵 称:XieXu
# 时 间: 2023/3/30/0030 18:24
# 使用str()函数将如下数值型数据转换为字符串的形式
print(str(88)) # 整型
print(str(-31415926)) # 整型
print(str(521.1314)) # 浮点型
print(str(3456E78)) # 浮点型
print(str(-2.3568875E36)) # 浮点型
print(str(11 / 3)) # 表达式
在PyCharm中运行后,我们可以看到如下输出结果:

3.2.2 将列表转换为字符串
# 使用str()函数将图书列表转换为字符串的形式
list1 = ['Python从入门到人工智能', 'Python人工智能开发', 'Python and AI']
print(list1) # 输出列表
print(type(list1)) # 列表类型
print(str(list1)) # 将列表转换为字符串
print(type(str(list1))) # 字符串类型
可以得到结果:
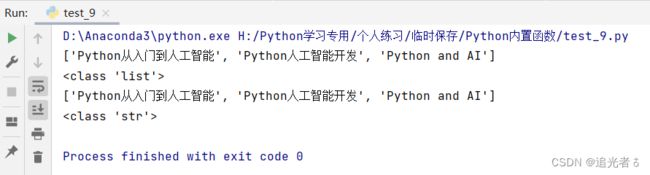
从上述结果中我们可以看出来,列表虽然转换为字符串了,但其中仍然包括列表中的’[‘、’]‘。因此我们可以知道,str()函数将列表、元组、字典和集合转换为字符串后,列表、元组、字典和集合中的’[‘、’]‘,’(‘、’)‘,’{‘、’}‘,以及列表、元组、字典和集合中的元素分隔符’,‘,和字典中键值对’:'也都跟着转换成了字符串,成为转换后字符串中的一部分。
3.2.3 将元组转换为字符串并去掉特殊符号
在使用str()函数将元组转换为字符串过程中,元组中的’(‘、’)'和分隔符等也都跟着转换成了字符串,那么我们可以通过多次使用replace()方法将这些字符去除,示例code如下:
先来看一个简易的例子:
n = '123,456,789'
n1 = n.replace(',', '')
print(n1)
输出如下:

如果字符串的“内容”多一些的话:
# 将元组转换为字符串并去掉特殊符号
tuple_1 = (('孙悟空', '孙行者'), ('猪八戒', '猪悟能'), ('沙僧', '沙悟净'))
a = str(tuple_1) # 元组转换为字符串
# 多次使用replace去除字符串中的标点符号
a1 = a.replace('(','').replace(')','').replace("'",'').replace(",",'')
print(a1)
下面将上述步骤分解,来看一下每一步的效果是怎样的:
我们首先来看最开始的元组内容:
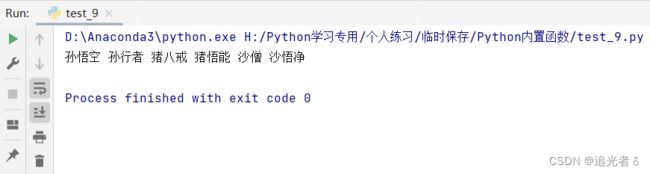
tuple_1 = (('孙悟空', '孙行者'), ('猪八戒', '猪悟能'), ('沙僧', '沙悟净'))
print(tuple_1)
a = str(tuple_1)
print(a)
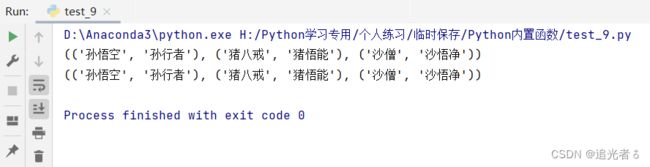
然后,只有一个replace时,来看前后的效果:
tuple_1 = (('孙悟空', '孙行者'), ('猪八戒', '猪悟能'), ('沙僧', '沙悟净'))
a = str(tuple_1)
print(a)
print("\n")
a1 = a.replace('(','')
print(a1)
可以看到,所有左侧小括号都被去掉了:

有两个replace时:
tuple_1 = (('孙悟空', '孙行者'), ('猪八戒', '猪悟能'), ('沙僧', '沙悟净'))
a = str(tuple_1)
print(a)
print("\n")
a1 = a.replace('(', '').replace(')', '')
print(a1)
可以看到,小括号都被去掉了:

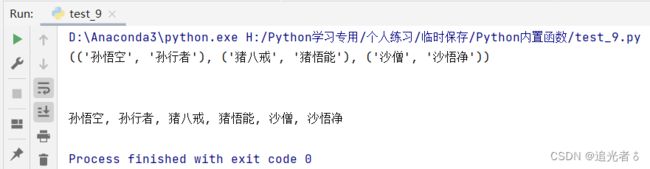
三个replace时:
tuple_1 = (('孙悟空', '孙行者'), ('猪八戒', '猪悟能'), ('沙僧', '沙悟净'))
a = str(tuple_1)
print(a)
print("\n")
a1 = a.replace('(', '').replace(')', '').replace("'",'')
print(a1)
效果可想而知,在上一步去掉小括号的基础上,单引号都去掉了:
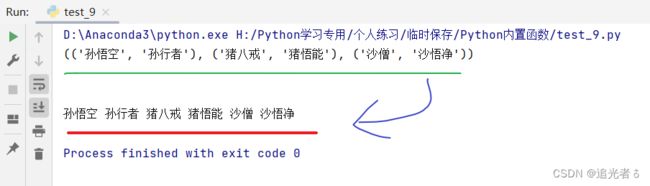
那么,四个replace时,这时候再去掉逗号即可:
tuple_1 = (('孙悟空', '孙行者'), ('猪八戒', '猪悟能'), ('沙僧', '沙悟净'))
a = str(tuple_1)
print(a)
print("\n")
a1 = a.replace('(', '').replace(')', '').replace("'",'').replace(',','')
print(a1)
就是最开始看到的效果咯:
经过上述分析,相比各位对replace()会有更深的印象,可以自己尝试一下哦~
3.2.4 将字典转换为字符串
请看示例code:
# 将字典转换为字符串
mydic = {'AI图书': {'0': 'Python从入门到人工智能', '1': 'CSDN@追光者♂人工智能教学', '2': 'Python@追光者♂'}}
print("type(mydic):",type(mydic))
print(mydic)
print('\n')
mystr = str(mydic)
print(mystr)
print("type(mystr):",type(mystr))
在PyCharm中运行后,效果如下:

3.2.5 将集合转换为字符串
示例code:
# 将集合转换为字符串
set = {'Python从入门到人工智能', 'CSDN@追光者♂人工智能教学', '学Python入门人工智能就找CSDN@追光者'}
print("type(set):",type(set))
print(set)
print('\n')
mystr = str(set)
print("type(mystr):",type(mystr))
print(mystr)

3.2.6 将字节类型(bytes对象)转换为字符串
接下来使用str()函数将字节类型转换为字符串的形式,首先使用encode()方法对“
CSDN@追光者♂”进行编码,输出字节类型,然后使用str()函数进行转换,code如下:
# 将字节类型(bytes对象)转换为字符串
s1 = 'CSDN@追光者♂' # 定义字符串
s2 = s1.encode(encoding='utf-8') # 采用utf-8编码
print(s2) # 输出字节类型
print('\n')
print(str(s2, encoding='utf-8')) # 将字节类型转换为字符串
运行后,结果如下:
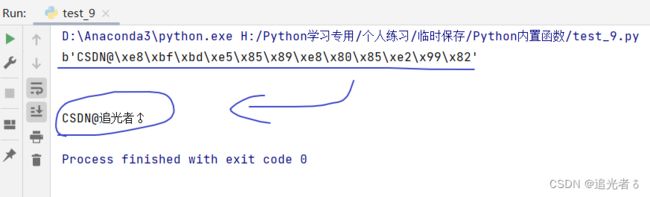
注意: 若不指定
encoding参数或者errors参数,对bytes对象使用str()函数相当于返回该对象的描述信息。
3.2.7 字符串与数值型数据混合输出
我们在编写程度的过程中,经过会遇到字符串与数值型数据混合输出的情况,例如下面的code:
# 定义字符串
str1 = "追光者"
str2 = '专注于人工智能领域'
# 定义一个整型数据
number = 23
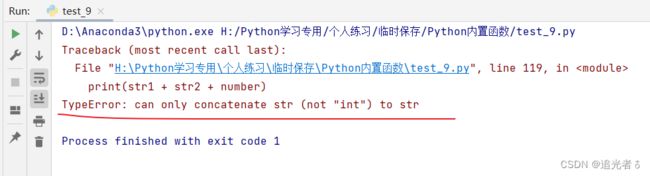
# 对字符串和整数直接进行拼接
print(str1 + str2 + number)
此时运行后,我们会遇到如下错误:TypeError: can only concatenate str (not "int") to str。(类型错误:只能将str(而不是 “int”)与str相连接)
事实上,这是许多初学Python的朋友会犯的错误。
遇到这种情况,应首先使用str()函数将数值型数据转换为字符串,然后再进行混合输出,因此上述代码可改写为:
# 定义字符串
str1 = "CSDN@追光者♂"
str2 = ' 专注于人工智能领域'
# 定义一个整型数据
number = 23
# 对字符串和整数直接进行拼接
print(str1 + str2 + str(number) + "年!")
可以得到输出结果如下:
CSDN@追光者♂ 专注于人工智能领域23年!
四、求绝对值
4.1 语法参考 and 参数说明、
语法参考:
abs()函数用于获取数字的绝对值,其语法格式如下:
abs(x)
参数说明:
- x:表示数值,参数可以是整数、浮点数或者复数;
- 返回值:返回数字的绝对值。
若参数是一个复数,则返回复数的模。
4.2 示例
4.2.1 获取整数与浮点数的绝对值
众所周知,在获取绝对值时,比较常见的数值就是整数与浮点数,使用abs()函数获取整数与浮点数绝对值的示例code如下:
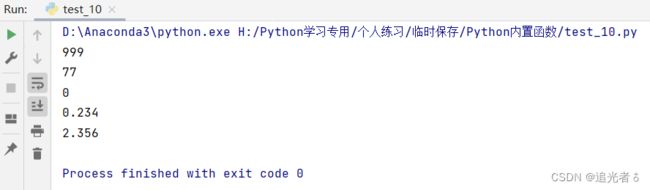
# 获取整数与浮点数的绝对值
print(abs(999)) # 求整数绝对值
print(abs(-77)) # 求负数绝对值
print(abs(0)) # 0的绝对值依然是0
print(abs(0.234)) # 浮点数绝对值
print(abs((-2.356))) # 负浮点数绝对值
结果如大家所想:
4.2.2 获取复数的模
除了使用abs()函数获取整数与浮点数的绝对值以外,还可以通过abs()函数获取复数的模,示例code如下:
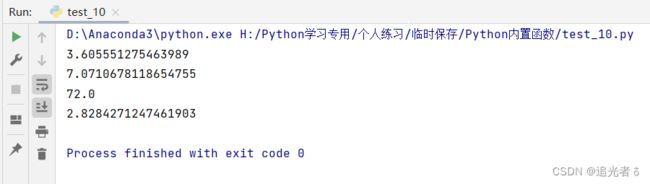
# 获取复数的模
print(abs(2-3j)) # 获取复数2-3j的模
print(abs(1+7j)) # 获取复数1+7j的模
print(abs(8*9j)) # 获取复数8*9j的模
print(abs(-2-2j)) # 获取复数-2-2j的模
输出结果如下:
4.2.3 获取可迭代对象中数字的绝对值
循环输出列表中定义的数字的绝对值,示例code如下:
# 获取可迭代对象中数字的绝对值
list = [12.34, 0.123, 0, 96, -363]
for i in list:
print(abs(i))

五、求商和余数
5.1 语法参考 & 参数说明
语法参考:
divmod()函数用于返回两个数值(非复数)相除得到的商和余数组成的元组。其语法格式如下:
divmod(x,y)
参数说明:
- x:被除数;
- y:除数;
- 返回值:返回由商和余数组成的元组。
5.2 示例
5.2.1 获取商和余数的元组
使用divmod()函数获取商和余数的元组,示例code如下:
# 获取商和余数的元组
print(divmod(11, 2)) # 被除数为11,除数为2。商为5 余数为1
print(divmod(100, 5)) # 同理,商为20,余数为0
print(divmod(15.5, 2)) # 被除数为15.5,除数为2
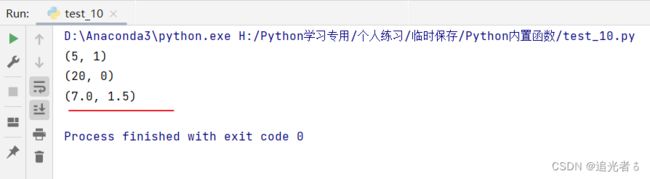
从上面的示例,我们可以看出来,通过divmod()函数获取商和余数的元组时,元组中的第一个元素为商,第二个元素为余数。
注:
- 若参数x和y都是整数,这相当于 (
a//b,a%b) - 若参数x或y是浮点数,那么这相当于
math.floor(a/b,a%b)
此处,我们解释下:
math.floor()函数用来返回数字的下舍整数,即它总是将数值向下舍入为最接近的整数。(在英文中,我们知道floor是“地板”的意思嘛~,故可以引申理解为 向下取整 ~)
import math
print(math.floor(2.8)) # 2
print(math.floor(-1.2)) # -2
print(math.floor(0.56)) # 0
因此,对于 divmod(15.5, 2),在浮点数中,若15.5/2,结果为7.75。
7.75 向下取整即为7,而print(15.5%2) 的值为1.5,一次就得到了(7.0,1.5)的结果。
此外,math.ceil()方法可将数字向上舍入到最接近的整数,即 向上取整。
5.3 小案例——循环获取 递减被除数的商和余数
要求:计算出从参数N开始,向下递减的每一个数字和参数A的除数 及 余数的结果值。
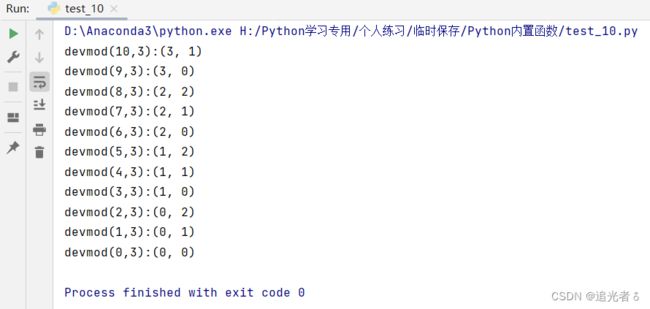
# 循环获取 递减被除数的商和余数
def getDivmod(N, A):
while N >= 0:
sn = str(N) # 传入的被除数
sa = str(A) # 传入的除数
# 使用divmod()函数进行计算
result = ['devmod({0},{1}):'.format(sn, sa), str(divmod(N, A))]
print(''.join(result)) # 打印结果
N = N - 1 # 实现被除数递减1
# 调用getDivmod()函数并传入参数
getDivmod(10, 3)
运行上述code,我们可以得到如下结果:
5.4 应用场景:诗句分段计算
在不同的古诗中,每段古诗的文字数量是不确定的。这里我们将通过divmod()函数实现诗句的分段计算。
以下为源代码:
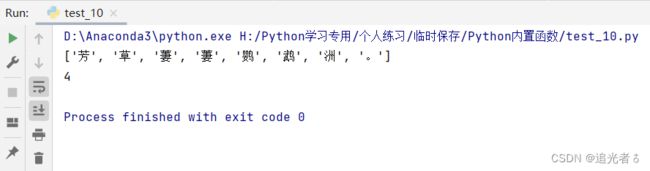
# 应用场景:诗句分段计算
def getSegment(curIndex, getSize):
# 诗句数据
poem = ['晴', '川', '历', '历', '汉', '阳', '树', ',', '芳', '草', '萋', '萋', '鹦', '鹉', '洲', '。',
'黑', '发', '不', '知', '勤', '学', '早', ',', '白', '首', '方', '悔', '读', '书', '迟', '。'
]
# 获取诗句起始位置
startGet = (curIndex - 1) * getSize
getData = poem[startGet:curIndex * getSize] # 获取某段的诗句内容
# 诗句数据的长度为被除数,几字为一段 作为除数
totalIndexTuple = divmod(len(poem), getSize) # 计算诗句数据的商和余数
totalIndex = totalIndexTuple[0] + totalIndexTuple[1] # 计算诗句可以分为几段
return (getData, totalIndex) # 返回指定段落的诗句 与 诗句共可以分为几段。
# 调用getSegment()函数,第一个参数为获取第几段诗句内容,第二个参数为每段诗句设置为几个字
result = getSegment(2, 8)
print(result[0]) # 打印诗句指定段的内容
print(result[1]) # 打印诗句总段落数
结合注释内容,相信是比较好理解的哈~
来看输出:
六、求最大值
6.1 语法参考 and 参数说明
语法参考:
ma()函数是Python开发中使用较多的函数,主要功能为获取传入的多个参数的最大值,或者传入的可迭代对象(或之中的元素)的最大值。其语法格式如下:
- max(iterable,*[,key,default])
- max(arg1,arg2,*args[,key])
- max(tuplename)
参数说明:
- iterable:可迭代对象,如字符串、列表、元组、字典等。
- default:命名参数,用来指定最大值不存在时返回的默认值。
- key:命名参数,其中一个函数,用来指定获取最大值的方法。
- arg:指定数值。
- tuplename:表述元组的名称。
- 返回值:返回给定参数的最大值。
补充说明:
使用max()函数,如果是
数值型参数,则取数值大者;如果是字符型参数,取字母表排序靠后者。当max()函数中存在多个相同的最大值时,返回的是最先出现的那个最大值。
注意:
用max获取元素中的最大值,本质是获取元素的编码值大小,谁的编码值大,谁就最大。如果是数字和英文字母、标点,看谁的ASCII码值大就可以了。汉字的编码值大于数字、英文字母和英文标点符号,常用数字、字母和标点的ASCII码值对照表如下图所示:
常用字符的ASCII码值:

说明:
字符串按位比较,两个字符串第一位字符的ASCII码谁大,字符串就大,不再比较后面的;第一个字符相同就比第二个字符串,以此类推。
6.2 示例
6.2.1 在字符、数字、标点及汉字中 取最大值
Max函数是根据元素的编码 码值大小 来取得最大值的。我们通常使用的字符的编码值可以通过其对应的ASCII码表或相应编码表获得。max对数字、字符等常用应用如下:
# 昵 称:XieXu
# 时 间: 2023/4/4/0004 19:20
# 在字符、数字、标点及汉字中 取最大值
# 数字的ASCII码范围 49-57之间
# !' # % & () * + ,-./的ASCII码范围33-47之间
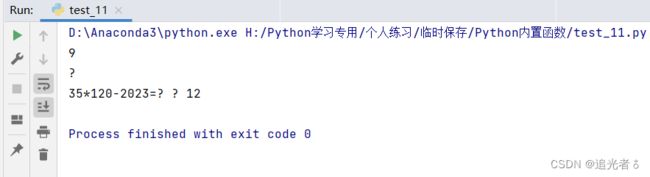
num_1 = '123456789'
print(max(num_1)) # 9 1-9的ASCII码值分别为49-57, 9的ASCII码值 为57,故输出9
# * - = ? 的ASCII码值分别是 35 42 45 61 63
num_2 = '35*120-2023=?'
print(max(num_2)) # ? ?的ASCII码值是63,其他标点符号和数字的ASCII码值 都小于63,故输出?
# 输出数字num_2、、num_1的最大值和最大值的索引
print(num_2, max(num_2), num_2.index(max(num_2))) # 35*120-2023=? ? 12
请注意注释中的解释。执行以后,
6.2.2 几个补充示例
当max()函数值给定一个可迭代对象 且 可迭代对象为空时,则必须指定命名参数 default,用来指定最大值不存在时,函数返回的默认值。例如:
# 参数是一个空的可迭代对象时,必须指定命名参数default
print(max((), default=99)) # 99
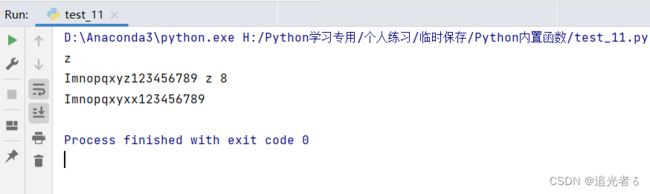
ch2 = 'Imnopqxyz123456789' # 小写字母的ASCII码值比数字的ASCII码值要大
print(max(ch2)) # z z的ASCII码值是122,在这些元素中最大
# 输出ch2、ch2的最大值和最大值对应的索引
print(ch2, max(ch2), ch2.index(max(ch2))) # Imnopqxyz123456789 z 8
# 将ch2的最大值替换为xx
print(ch2.replace(max(ch2), 'xx')) # Imnopqxyxx123456789
输出结果为:
# 用max函数获取字母、数字和标点最大值,就是求它们谁的ASCII码值最大
ch3 = 'xiexu,1999,1998,10.24'
print(max(ch3[6:])) # 9 从字符串第6个元素开始获取最大的元素
print(max(ch3),min(ch3)) # x , 输出ch3的最大值和最小值

# 字母的ASCII码值 > 数字的ASCII码值,标点符号的ASCII码值 范围较大
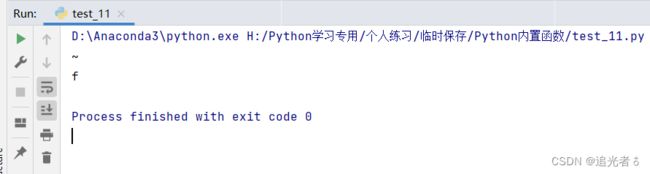
ch4 = '.,*56789ABCdeabcefh~{'
print(max(ch4)) # ~
print(max(ch4[-8:-2:2])) # f 从字符串的最后一位开始倒数第8个字符串,步长为2 获取最大元素
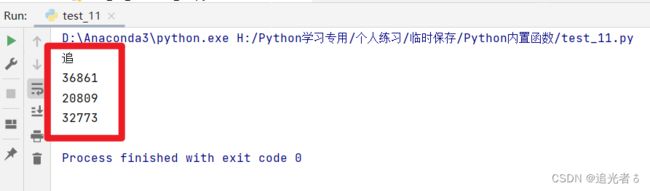
ch5 = '追光者310zhuiguangzhe' # 汉字的编码值比数字、字母和英文标点的值都大
print(max(ch5)) # 追
print(ord('追')) # 36861
print(ord('光')) # 20809
print(ord('者')) # 32773
# 生成10以内的数字并获取最大值输出
print(max(x for x in range(10))) # 9
6.2.3 在列表中使用max
我们知道,在列表中有多种方法可以求最大值,max()是最方便、简单的方法。使用max()函数获取列表最大值时,函数内部将对列表中的元素进行循环比较,然后返回列表元素最大的值,当存在多个相同的最大值时,返回的是最先出现的那个最大值。max()函数在列表中的常见应用如下:
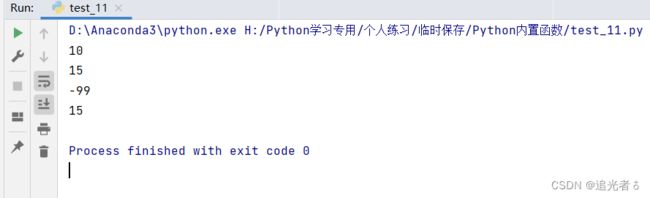
list_1 = [2, 4, 6, 8, 10]
list_2 = [-11, -6, -2, 0, 3, 10, 15, -23, -26, -99]
print(max(list_1)) # 10
print(max(list_2)) # 15
# 获取list_2列表中元素绝对值的最大值
print(max(list_2, key=lambda x: abs(x))) # -99
# 在列表第2项 到第8项(不含)求最大值
print(max(list_2[2:8])) # 15
list_3 = ['a','-2','b','v','6','3','c'] # 创建包含数字、字母的列表
print(max(list_3)) # v 小写字母的ASCII码值大于数字,且按照字母排序递增
print(max(list_3[1:8])) # v 在列表第1项到第8项(不含)求最大值
说明:我们可以通过设置命名参数key来指定取最大值的方法,key参数的另一个作用是,通过设置适当的key函数,可以对不同类型的对象进行比较获取最大值。
list_4 = ['23', 5, 15] # 元素为混合类型的列表
print(max(list_4, key=int)) # 23 指定key为int()函数后 再取最大值
篇幅所限,目前分享的内容暂时到此,后面会继续补充记录该部分内容,可以期待一下哦!
热门专栏推荐:
- Python&AI专栏:【Python从入门到人工智能】
- 前端专栏:【前端之梦~代码之美(H5+CSS3+JS.】
- 文献精读&项目专栏:【小小的项目 (实战+案例)】
- C语言/C++专栏:【C语言、C++ 百宝书】(实例+解析)
- Java系列(Java基础/进阶/Spring系列/Java软件设计模式等)
- 问题解决专栏:【工具、技巧、解决办法】
- 加入Community 一起追光:追光者♂社区
持续创作优质好文ing…✍✍✍
记得一键三连哦!!!
求关注!求点赞!求个收藏啦!
