《机器学习公式推导与代码实现》chapter22-EM算法
《机器学习公式推导与代码实现》学习笔记,记录一下自己的学习过程,详细的内容请大家购买作者的书籍查阅。
EM算法
作为一种迭代算法,EM算法(expectation maximization,期望极大值算法)用于包含隐变量的概率模型参数的极大似然估计。
EM算法包括两个步骤:E步,求期望(expectation);M步,求极大(maximization)。
1 极大似然估计
极大似然估计(maximum likelihood estimation,MLE)是统计学领域中一种经典的参数估计方法。对于某个随机样本满足某种概率分布,但其中的统计参数未知的情况,极大似然估计可以让我通过若干次试验的结果来估计参数的值。
以一个经典的例子进行说明,比如我们想了解某高校学生的身高分布。我们假设该校学生的身高分布服从一个正态分布 N ( μ , σ 2 ) N(\mu,\sigma^{2}) N(μ,σ2),其中分布参数 μ \mu μ和 σ 2 \sigma^{2} σ2未知。全校有数万名学生,要一个一个实测肯定不现实,所以我们决定采用统计抽样的方法,随机选取100名学生测得其身高。
要通过100人的身高估算全校学生的身高,需要明确以下问题。第一个问题是抽到这100人的概率是多少。因为每个人的选取都是独立的,所以抽到这100人的概率可以表示为单个概率的乘积:
L ( θ ) = L ( x 1 , x 2 , ⋯ , x n ; θ ) = ∏ i = 1 n p ( x i ∣ θ ) L(\theta )=L(x_{1},x_{2},\cdots,x_{n};\theta)=\prod_{i=1}^{n}p(x_{i}\mid \theta) L(θ)=L(x1,x2,⋯,xn;θ)=i=1∏np(xi∣θ)
上式为似然函数,为了计算方便,我们会对似然函数取对数:
H ( θ ) = ln L ( θ ) = ln ∏ i = 1 n p ( x i ∣ θ ) = ∑ i = 1 n ln p ( x i ∣ θ ) H(\theta )=\ln_{}{L(\theta )}=\ln_{}{\prod_{i=1}^{n}p(x_{i}\mid \theta)}=\sum_{i=1}^{n} \ln_{}{p(x_{i}\mid \theta)} H(θ)=lnL(θ)=lni=1∏np(xi∣θ)=i=1∑nlnp(xi∣θ)
第二个问题是为什么刚好抽到这100人。按照极大似然估计理论,在学校这么多学生中,我们恰好抽到这100人而不是另外100人,正是因为这100人出现的概率极大,即其对应的似然函数极大:
θ ^ = a r g m a x L ( θ ) \hat{\theta} = argmax L(\theta ) θ^=argmaxL(θ)
最后一个问题是如何求解,直接对 L ( θ ) L(\theta) L(θ)求导并使其为0。
所以极大似然估计法可以看作由抽样结果对条件的反推,即已知某个参数能使得这些样本出现的概率极大,我们就直接把该参数作为参数估计的真实值。
2 EM算法
假设全校学生的身高付出一个分布的假设过于笼统,实际上男女分布不同,假设其中男生身高服从分布 N ( μ 1 , σ 1 2 ) N(\mu^{}_{1},\sigma^{2}_{1}) N(μ1,σ12),女生身高分布为 N ( μ 2 , σ 2 2 ) N(\mu^{}_{2},\sigma^{2}_{2}) N(μ2,σ22)。现在估计该校学生身高,就不能简单地使用一个分布的假设了。
假设分别抽取50个男生和50个女生,对他们分开进行估计。假设我们并不知道抽样得到的这样样本来自男生还是女生。
学生的身高是观测变量(observable variable),样本的性别是一种隐变量(hidden variable)。
现在我们需要估计两个问题:一是这个样本是男生的还是女生的,而是男生和女生对应的身高的正态分布参数分别是多少。这种情况极大似然估计就不太适用了,要估计男女生身高分布,就必须先估计该学生是男是女。反过来要估计该学生是男还是女,又得从身高来判断。但二者相互依赖,直接用极大似然估计无法计算。
针对这种包含隐变量的参数估计问题,一般使用EM(expectation maximization)算法,即期望极大化算法来进行求解。针对上述身高估计问题,EM算法的求解思路是:既然两个问题相互依赖,这肯定是一个动态求解过程。不如直接给定男女身高的分布初始值,根据初始值估计哪个样本是男/女生的概率(E步),然后据此使用极大似然估计男女生的身高分布参数(M步),之后动态迭代调整到满足终止条件为止。
EM算法的应用场景就是解决包含隐变量的概率模型参数估计问题。给定观测变量数据Y,隐变量数据Z,联合概率分布 P ( Y , Z ∣ θ ) P(Y,Z|\theta) P(Y,Z∣θ),以及关于隐变量的条件分布 P ( Z ∣ Y , θ ) P(Z|Y,\theta) P(Z∣Y,θ),使用EM算法对模型参数 θ \theta θ进行估计的流程如下:
(1)初始化模型参数 θ ( 0 ) \theta^{(0)} θ(0),开始迭代。
(2)E步:记 θ ( i ) \theta^{(i)} θ(i)为第 i i i次迭代参数 θ \theta θ的估计值,在第 i + 1 i+1 i+1次迭代的E步,计算Q函数:
Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] = ∑ Z log P ( Y , Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) Q(\theta,\theta^{(i)})=E_{Z}\left [ \log_{}{P(Y,Z\mid\theta)}\mid Y,\theta^{(i)} \right ] =\sum_{Z}^{}\log_{}{P(Y,Z\mid\theta)}P(Z|Y,\theta^{(i)}) Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑logP(Y,Z∣θ)P(Z∣Y,θ(i))
其中 P ( Z ∣ Y , θ ( i ) ) P(Z|Y,\theta^{(i)}) P(Z∣Y,θ(i))为给定观测数据 Y Y Y和当前参数估计 θ ( i ) \theta^{(i)} θ(i)的情况下隐变量数据 Z Z Z的条件概率分布。E步的关键是这个Q函数,Q函数定义为完全数据的对数似然函数 log P ( Y , Z ∣ θ ) \log_{}{P(Y,Z\mid\theta)} logP(Y,Z∣θ)关于在给定观测数据 Y Y Y和当前参数 θ ( i ) \theta^{(i)} θ(i)的情况下未观测数据 Z Z Z的条件概率分布。
(3)M步:求使得Q函数最大化的参数 θ \theta θ,确定第 i + 1 i+1 i+1次迭代的参数估计值 θ ( i + 1 ) \theta^{(i+1)} θ(i+1):
θ ( i + 1 ) = a r g m a x θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=\underset{\theta}{argmax}Q(\theta,\theta^{(i)}) θ(i+1)=θargmaxQ(θ,θ(i))
(4)重复迭代E步和M步直至收敛。
由EM算法过程可知,其关键在于E步要确定Q函数。E步在固定模型参数的情况下估计隐状态变量分布,而M步则是固定隐变量来估计模型参数。二者交互进行,直至算法收敛条件。
EM算法动态迭代过程:
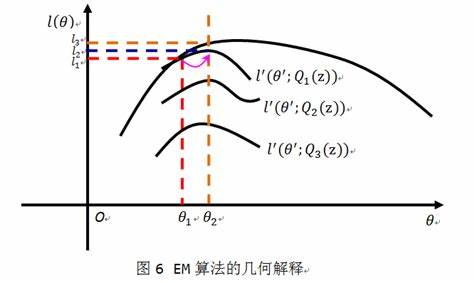
3 三硬币模型



4 基于numpy实现三硬币模型
import numpy as np
## EM算法过程定义
def em(data, thetas, max_iter=50, eps=1e-3): # data观测数据,thetas初始化的估计参数值,eps收敛阈值
ll_old = 0 # 初始化似然函数值
for i in range(max_iter):
# E步:求隐变量分布
log_like = np.array([np.sum(data*np.log(theta), axis=1) for theta in thetas]) # 对数似然 2*5
like = np.exp(log_like) # 似然 2*5
ws = like/like.sum(0) # 隐变量分布 2*5
ll_new = np.sum([w*l for w, l in zip(ws, log_like)]) # 期望
# M步:更新参数值
vs = np.array([w[:, None] * data for w in ws]) # 概率加权 2*5*2
thetas = np.array([v.sum(0)/v.sum() for v in vs]) # 2*2
# 打印结果
print(f'Iteration:{i+1}')
print(f'theta_B = {thetas[0,0]:.2}, theta_C = {thetas[1,0]:.2}, {ll_new}')
# 满足条件退出迭代
if np.abs(ll_new - ll_old) < eps:
break
ll_old = ll_new
return thetas
EM算法求解三硬币问题:
# 观测数据,5次独立实验,每次试验10次抛掷的正反面次数
observed_data = np.array([(5, 5), (9, 1), (8, 2), (4, 6), (7, 3)]) # 比如第一次试验为5次正面5次反面
# 初始化参数值,硬币B出现正面的概率0.6,硬币C出现正面的概率为0.5
thetas = np.array([[0.6, 0.4], [0.5, 0.5]])
# EM算法寻优
thetas = em(observed_data, thetas, max_iter=30)
thetas
Iteration:1
theta_B = 0.71, theta_C = 0.58, -32.68721052517165
Iteration:2
theta_B = 0.75, theta_C = 0.57, -31.258877917413145
Iteration:3
theta_B = 0.77, theta_C = 0.55, -30.760072598843628
Iteration:4
theta_B = 0.78, theta_C = 0.53, -30.33053606687176
Iteration:5
theta_B = 0.79, theta_C = 0.53, -30.071062062760774
Iteration:6
theta_B = 0.79, theta_C = 0.52, -29.95042921516964
Iteration:7
theta_B = 0.8, theta_C = 0.52, -29.90079955867412
Iteration:8
theta_B = 0.8, theta_C = 0.52, -29.881202814860167
Iteration:9
theta_B = 0.8, theta_C = 0.52, -29.873553692091832
Iteration:10
theta_B = 0.8, theta_C = 0.52, -29.870576075992844
Iteration:11
theta_B = 0.8, theta_C = 0.52, -29.86941691676721
Iteration:12
theta_B = 0.8, theta_C = 0.52, -29.868965223428773
array([[0.7967829 , 0.2032171 ],
[0.51959543, 0.48040457]])
算法在第7次迭代时收敛,最后硬币B和硬币C出现正面的概率分别为0.80和0.52。
笔记本_Github地址