【arXiv2306】1M parameters are enough? A lightweight CNN-based model for medical image segmentation
1M parameters are enough? A lightweight CNN-based model for medical image segmentation
论文:https://arxiv.org/abs/2306.16103
代码:https://github.com/duong-db/U-Lite
解读:UNet家族迎来最小模型U-Lite | 800K参数实现性能极限超车 - 知乎 (zhihu.com)
摘要
卷积神经网络(CNNs)和基于Transformer的模型由于能够提取图像的高级特征和捕捉图像的重要方面而被广泛应用于医学图像分割。然而,在对高精度的需求和对低计算成本的期望之间往往存在权衡。具有更高参数的模型理论上可以获得更好的性能,但也会导致更高的计算复杂性和更高的内存使用率,因此实现起来并不实用。
本文寻找一种轻量级的基于U-Net的模型,它可以保持不变,甚至实现更好的性能,即U-Lite。基于深度可分离卷积的原理设计了U-Lite,既可以利用细胞神经网络的强度,又可以减少大量的计算参数。具体来说,提出了在编码器和解码器中都具有核7×7的轴向深度卷积,以扩大模型的感受野。为了进一步提高性能,使用了几个具有3×3的轴向空洞深度卷积作为分支之一。
总体而言,U-Lite仅包含878K参数,比传统U-Net少35倍,比其他基于Transformer的现代型号少很多倍。与其他最先进的架构相比,所提出的模型降低了大量的计算复杂性,同时在医学分割任务上获得了令人印象深刻的性能。
简介
U-Net是一种经典且高效的医学分割模型,有各种变体,如UNet++、ResUNet++、Double UNet、Attention UNet等。近年来,视觉Transformer和MLP-Like架构(MLP)得到了广泛的应用。在医学分割任务中,TransUNet可以被认为是精度和效率较高的模型之一。金字塔视觉Transformer(PVT)被用作许多高性能模型的Backbone,如MSMA-Net、Polyp PVT。
同时,MLP-Like的体系结构也是研究的重点。MLP利用传统MLP的优点来沿着其每个维度对特征进行编码。AxialAtt MLP Mixer通过应用轴向注意力力来代替MLP Mixer中的Token混合,在许多医学图像数据集上提供了非常好的性能。与神经网络不同,基于Transformer或MLP的模型主要集中于图像的全局感受野,因此计算复杂度高,训练过程过于繁重。
但由于参数数量庞大,其中大量研究可能会带来繁重的运算和缓慢的计算速度。
为此,可以提到一些轻量级架构的尝试,如Mobile UNet、DSCA-Net和MedT。本文重新思考了一种用于医学分割任务的高效轻量级架构,以进一步探索一种能够有效的高性能模型。
主要贡献有3个方面:
- 基于深度可分离卷积的概念,提出了轴向深度卷积模块的使用方法。该模块帮助模型解决每一个复杂的体系结构问题:扩大模型的感受野,同时减少沉重的计算负担。
- 提出U-Lite,一种基于CNN的轻量级、简单的架构。U-Lite是为数不多的在性能和参数数量方面超过最近高效紧凑型网络UneXt的型号之一。
- 在医学分割数据集上取得了可观的效果。
U-Lite方法
遵循U-Net的对称编码器-解码器架构,并以一种有效的方式设计U-Lite,以便该模型能够利用CNN的强度,同时保持计算参数的数量尽可能少。

为此,论文提出了一个轴向深度卷积模块,如图2所示。描述U-Lite的操作,形状为(3,H,W)的输入图像通过3个阶段被馈送到网络:编码器阶段、Bottleneck阶段和解码器阶段。U-Lite遵循分层结构,其中编码器提取输入图像中的6个不同层级的特征。
Bottleneck和解码器参与处理这些特征,并将它们放大到原始形状以获得分割Mask。在编码器和解码器之间使用跳跃连接。尽管U-Lite的设计很简单,但由于轴向深度卷积模块的贡献,该模型在分割任务上仍然表现良好。
Axial Depthwise Convolution module
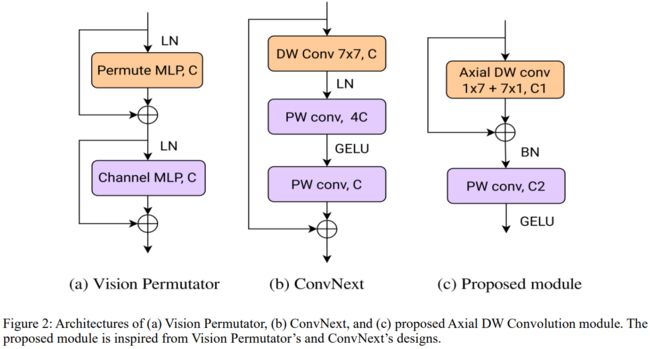
Swin-Transformer通过将自注意力计算限制在大小为7×7的非重叠局部窗口,降低了Transformer的计算复杂性。ConvNext实现了这一修改,并在CNN架构中采用了kernel大小为7×7的卷积,提高了性能。
Vision Permutator利用线性投影来沿着高度和宽度维度分别编码特征表示。
论文提及:如果用局部感受野版本取代ViT的十字形感受野,就像Swin Transformer对ViT所做的那样,会发生什么?
于是,作者提出了轴向深度卷积模块,作为Vision Permutator和卷积设计的组合。数学公式表示:




Encoder Block and Decoder Block
编码器和解码器块的设计原理如下:
- 遵循深度可分离卷积架构。这是构建轻量级模型的重要关键。深度可分离卷积在使用较少参数的同时,提供了与传统卷积相同的性能,从而降低计算复杂性,使模型更紧凑。
- 限制使用不必要的操作op。只需使用普通的MaxPooling和UpSampling层。不需要诸如转置卷积之类的高参数消耗算子。逐点卷积算子可以同时扮演两个角色:沿着特征图的深度对特征进行编码,同时灵活地改变输入通道的数量。
- 每个编码器或解码器块采用一个批量标准化层,并以GELU激活功能结束。作者对批处理规范化和层规范化进行了性能比较,但没有太大区别。应用GELU是因为与ReLU和ELU相比,在使用GELU时证明了其在准确性方面的改进。
U-Lite的编码器和解码器结构如图4所示。

![]()
Bottleneck Block
为了进一步提高U-Lite的性能,论文将kernel大小为3的轴向扩展深度卷积应用于Bottleneck块(图4)。应用的空洞率为d=1,2,3。作者使用具有大小为3的kernel的轴向扩张卷积,原因有两个:
- 大小为3的kernel更适合底层特征的空间形状,其中这些特征的高度和宽度减少了多次,
- 当使用具有不同空洞率的空洞卷积来捕获后面阶段的High-Level特征的多空间表示时,它给出了更好的性能。
为了进一步减少可学习参数的数量,在Bottleneck块的开头采用了逐点卷积层。这有助于在将最后一层特征提供给轴向扩展深度卷积机制之前缩小其通道尺寸。
实验
![]()




![]()



