Clickhouse表连接
背景
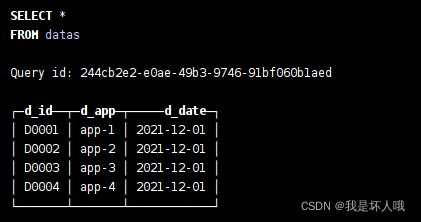
datas表是原始数据表(见下图),现在要对datas表中的app类型进行分析。于是需要建立一张app名称与app类型关系表,对两张表进行连接查询。
方案一
简单粗暴,直接建立关联表,直接进行join关联。
--建立关联表
create table app_type_mapping(
`m_app` String,
`m_type` String
)ENGINE = TinyLog
--插入数据
insert into app_type_mapping values('app-1','system app'),('app-2','core app')('app-3','3th-party app')
--查询
select d_id,d_app,if(m_type='','other',m_type) as app_type
from datas left join app_type_mapping on d_app=m_app结果:
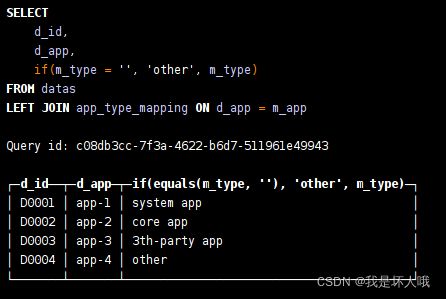
看起来并没什么问题。但是clickhouse对于普通join内部的实现原理是利用右表构建一个hash table并加载到内存中,于是会存在2个问题:
1. 内存溢出问题:右边数据量超过机器可用内存空间的限制,则JOIN操作无法完成
2. 效率问题:每次join都需要从磁盘中读取整个右表数据加载到内存 
针对问题一,一般将数据量小的表作为右边。如果两张表数据量都特别大怎么办,没办法,那就只能从源头解决,建立大宽表把所有需要的字段都放进去。
方案二
使用Join表引擎。本文仅作简单的介绍,正式环境使用Join表还需要考虑数据同步问题,详细操作可参考这篇文章:https://guides.tinybird.co/guide/faster-joins-with-the-join-engine https://guides.tinybird.co/guide/faster-joins-with-the-join-engine
https://guides.tinybird.co/guide/faster-joins-with-the-join-engine
--删除前面建立的关联表
drop table app_type_mapping;
--新建关联表,采用Join表引擎
create table app_type_mapping(
`m_app` String,
`m_type` String
)ENGINE = Join(ALL, LEFT, m_app)
--重新插入数据
insert into app_type_mapping values('app-1','system app'),('app-2','core app')('app-3','3th-party app')
--查询
SELECT d_id,d_app,if(m_type='','other',m_type) as app_type
FROM datas
ANY LEFT JOIN app_type_mapping USING (d_app)结果:
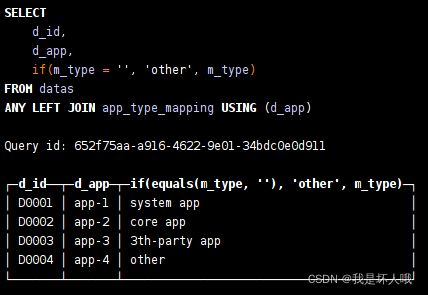
使用Join表引擎的表数据会一直保存在内存中,当新的数据插入的时候,Clickhouse会写入磁盘以便故障时数据恢复。由于数据直接就可以从内存中获取,不需要先从磁盘加载到内存,减少了IO,从而提交了查询效率。

方案三(推荐)
使用dictionary 字典。在方案一的基础上建立dictionary。
--新建dictionary
CREATE DICTIONARY app_type_dict(
`m_app` String,
`m_type` String
)
PRIMARY KEY m_app
SOURCE(CLICKHOUSE(HOST '172.**.**.***' PORT 9000 USER 'default' TABLE 'app_type_mapping' PASSWORD '***'))
LAYOUT(COMPLEX_KEY_HASHED())
LIFETIME(30)
--查询
select d_id,d_app,dictGetStringOrDefault('app_type_dict','m_type',tuple(d_app),'other') as app_type
from datas
结果:
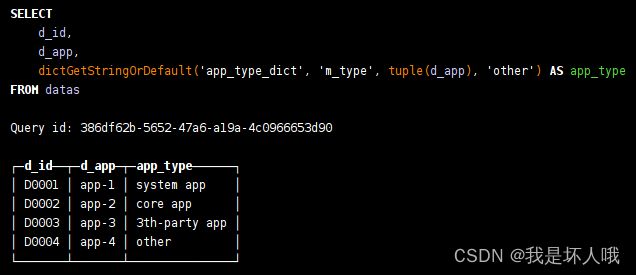
dictionary天生就很适合用于这种关联表或者中间表的场景,它跟Join表引擎一样将数据存在内存中,并且比join更加简单和高效。dictionary的强大之处在于它不仅支持将内部表加载到字典中(内部字典),还支持外部字典,可以将其他数据源(如Mysql,Redis等)的数据通过HTTP加载到字典中。无论是内部字典还是外部字典,数据表中的数据一旦发生更新,字典中的数据随后也会更新。

总结
1. Clickhouse进行表连接时,表数据量小且不追求效率直接用join语句,需要遵循“小表在右”原则
2. Join表引擎和dcitionary都会将数据保存到内存中,以提高查询效率,更推荐使用dcitionary
3. dcitionary也不是万金油,由于内存限制,当连接表超过1百万条数据,就不要使用字典了,需要从其他方向考虑优化